SkyText Chinese GPT3
1.0.0
SkyText es un gran modelo chino GPT3 pretratado lanzado por Singularity Zhiyuan, que puede realizar diferentes tareas como el chat, las preguntas y respuestas y la traducción china-inglés. Además de implementar el chat básico, el diálogo, las preguntas y las respuestas, este modelo también puede apoyar la traducción al chino e inglés, la continuación del contenido, los pareados, la redacción de poemas antiguos, la generación de recetas, las repeticiones en tercera persona, la creación de preguntas de la entrevista y otras funciones.

Ciento cuatro millones de parámetros del modelo [cerrado temporalmente la fuente, pronto se lanzará un nuevo modelo de parámetros de diez mil millones, ¡así que estad atentos! 】 Https://huggingface.co/skywork/skytext
Modelo de parámetros de tres mil millones https://huggingface.co/skywork/skytexttiny
Experiencia y prueba, visite la prueba de API inteligente de singularidad
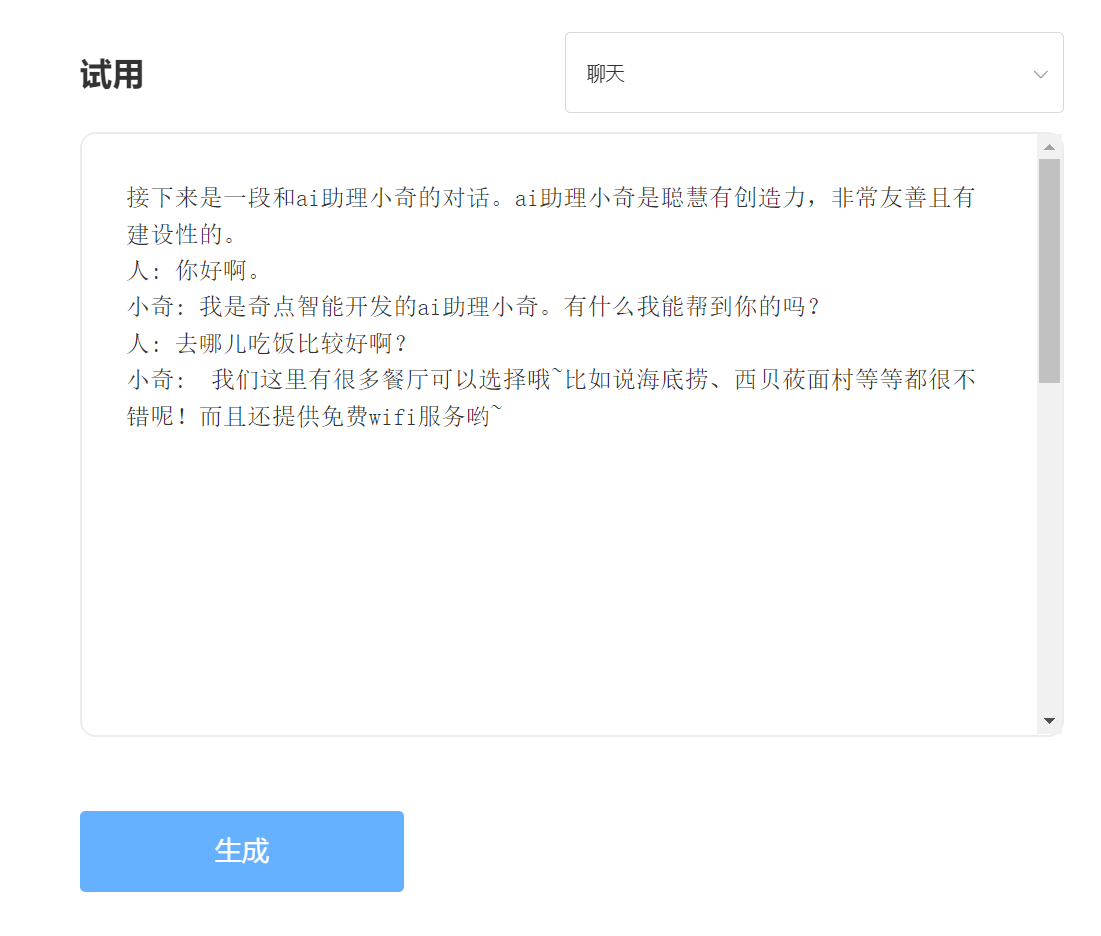
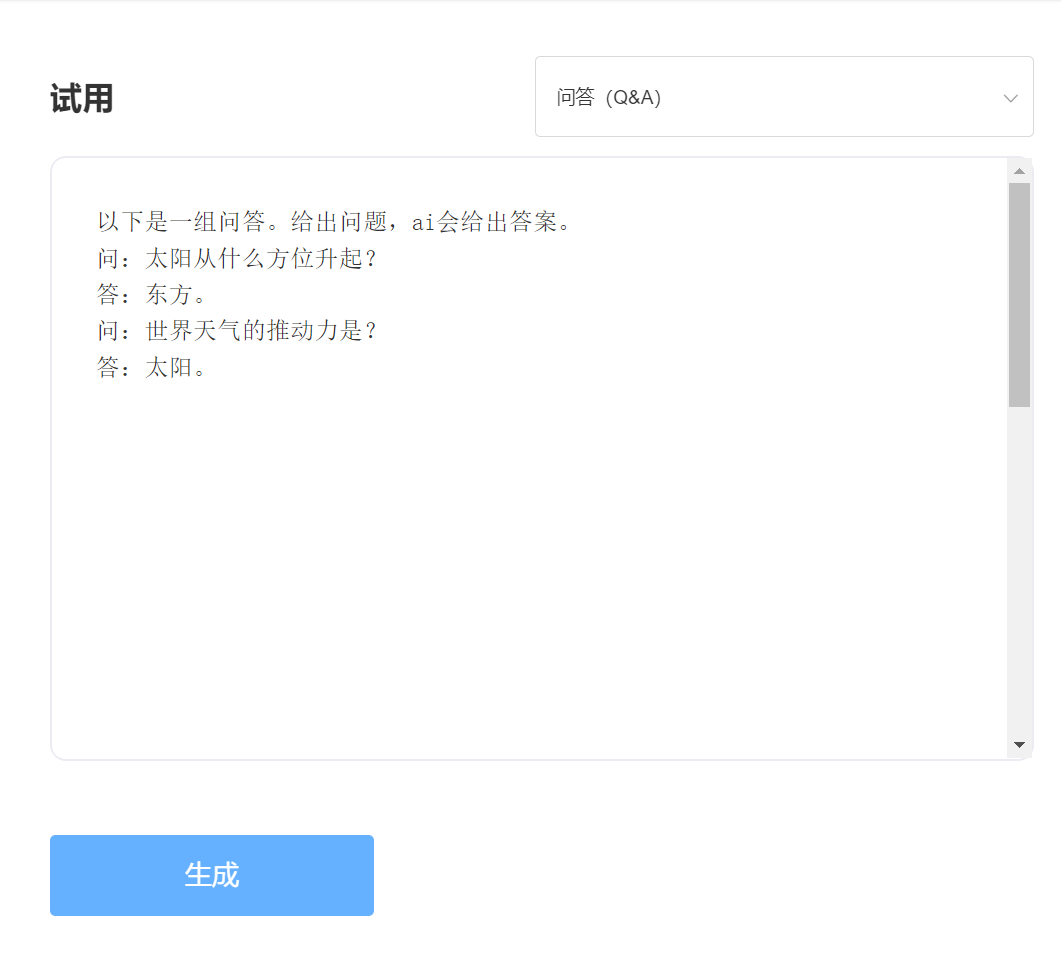
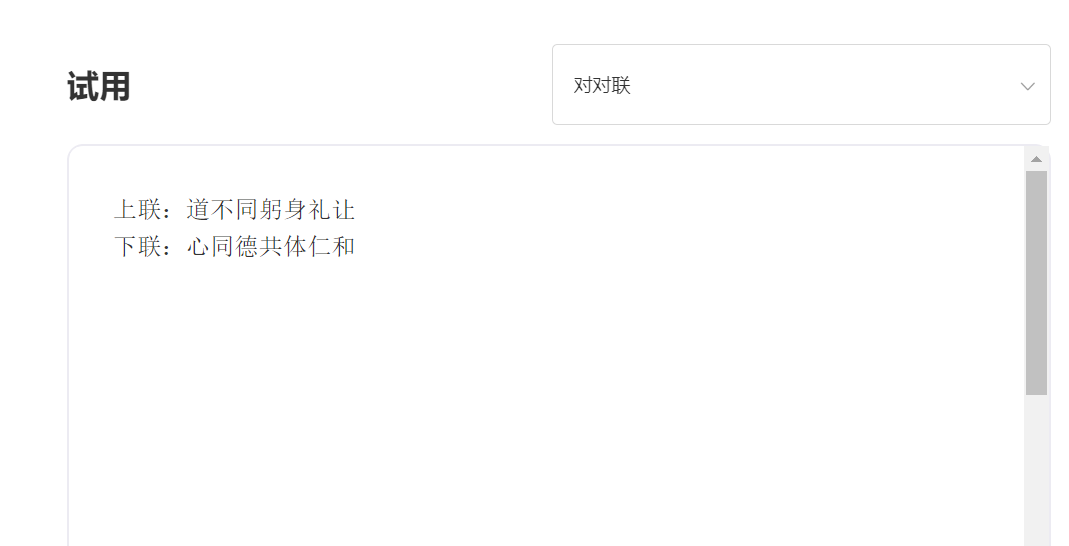
ingresar: 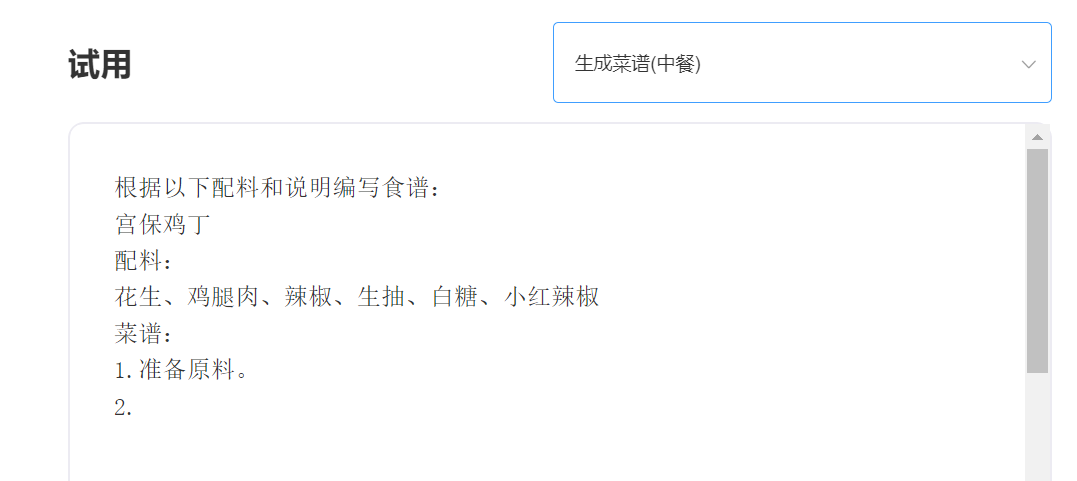
Producción: 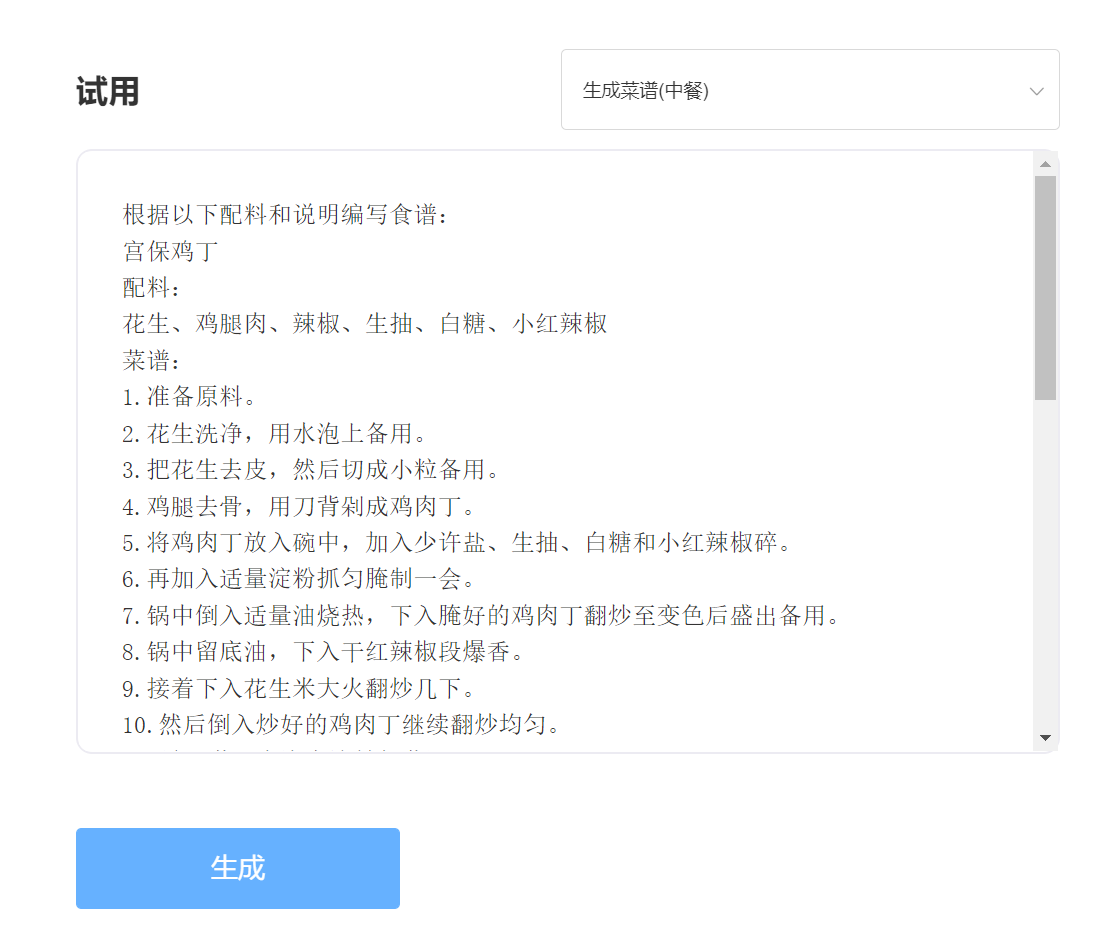
Ventaja técnica 1: limpieza de datos con más de 30 procesos
Con el desarrollo de la tecnología PNL, los modelos grandes previamente capacitados se han convertido gradualmente en una de las tecnologías centrales de la inteligencia artificial. Los modelos grandes previamente capacitados generalmente requieren un texto masivo para ser entrenado, y el texto en línea se convierte naturalmente en la fuente más importante de corpus. La calidad del corpus de capacitación indudablemente afecta directamente la efectividad del modelo. Para capacitar a un modelo con capacidades sobresalientes, la inteligencia de singularidad utilizó más de 30 procesos de limpieza al limpiar los datos. Los detalles exquisitos han creado excelentes efectos de modelo.
Ventaja técnica 2: métodos de codificación chinos que optimizan e innovan chinos
En el campo de los grandes modelos de pre-entrenamiento, siempre ha sido dominado por la comunidad inglesa, y la importancia de la capacitación de grandes modelos en chino es evidente. A diferencia del texto de pinyin en inglés, el método de entrada chino de los modelos chinos previamente capacitados obviamente debería ser diferente. La inteligencia de singularidad utiliza métodos de codificación chinos únicos basados en las características del idioma chino, que está más en línea con los hábitos del idioma chino y reconstruye un diccionario chino que es más propicio para modelar la comprensión.
————————————————————————————————————
推荐
transformers>=4.18.0
# -*- coding: utf-8 -*-
from transformers import GPT2LMHeadModel
from transformers import AutoTokenizer
from transformers import TextGenerationPipeline
# 以 SkyWork/SkyText(13billions) 为例,还有 SkyWork/SkyTextTiny(2.6billions) 可用, 期待使用
model = GPT2LMHeadModel . from_pretrained ( "SkyWork/SkyText" )
tokenizer = AutoTokenizer . from_pretrained ( "SkyWork/SkyText" , trust_remote_code = True )
text_generator = TextGenerationPipeline ( model , tokenizer , device = 0 )
input_str = "今天是个好天气"
max_new_tokens = 20
print ( text_generator ( input_str , max_new_tokens = max_new_tokens , do_sample = True )) Licencia de MIT