SkyText Chinese GPT3
1.0.0
SkyText-это китайская предварительно обученная большая модель GPT3, выпущенная Singularity Zhiyuan, которая может выполнять различные задачи, такие как CHAT, Q & A и китайско-английский перевод. В дополнение к внедрению базового чата, диалога, вопросов и ответов, эта модель также может поддерживать перевод китайского и английского языка, продолжение контента, куплеты, написание древних стихов, генерирование рецептов, репосты от третьего лица, создание вопросов интервью и других функций.

Сто четыре модели параметров [временно закрыли источник, скоро будет выпущена новая модель параметров десяти миллиардов, так что следите за обновлениями! 】 Https://huggingface.co/skywork/skytext
Модель параметров трех миллиардов https://huggingface.co/skywork/skytexttiny
Опыт и испытания, пожалуйста, посетите Singularity Intelligent API испытания
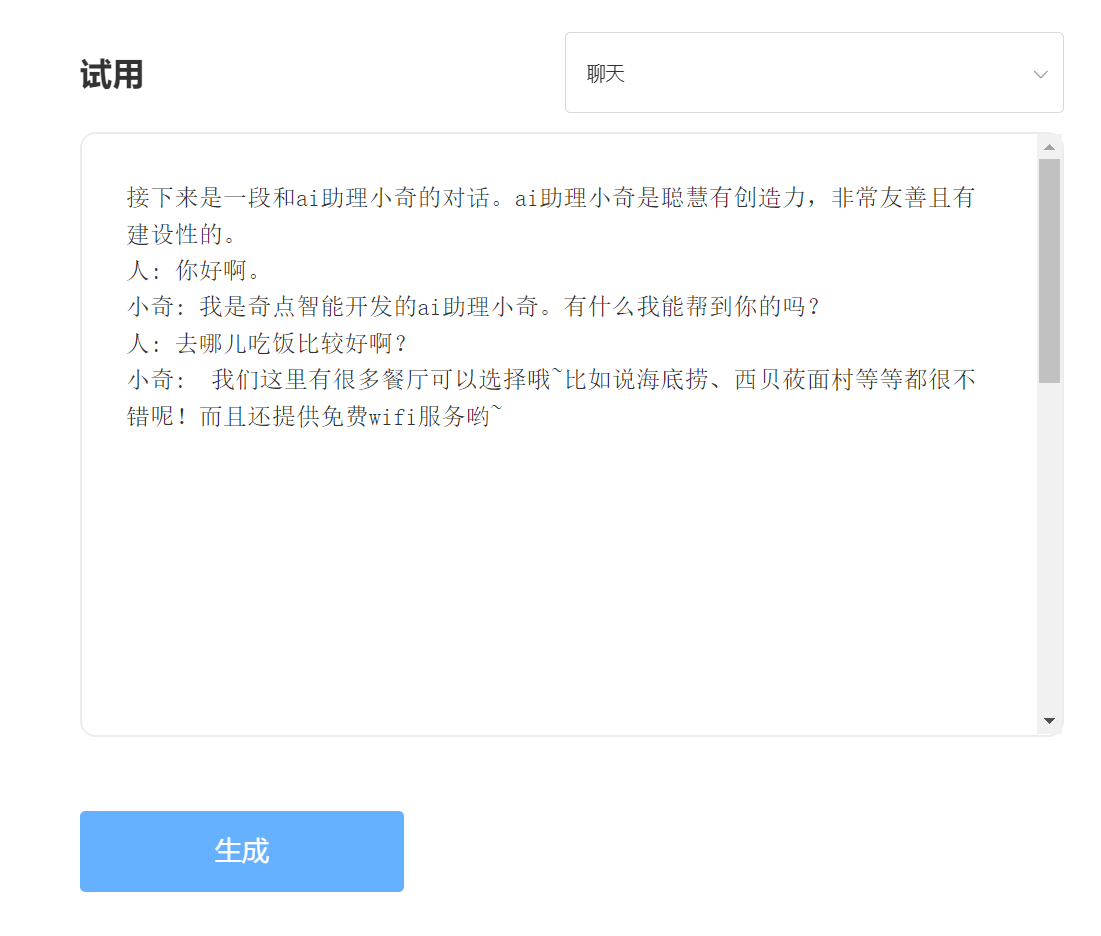
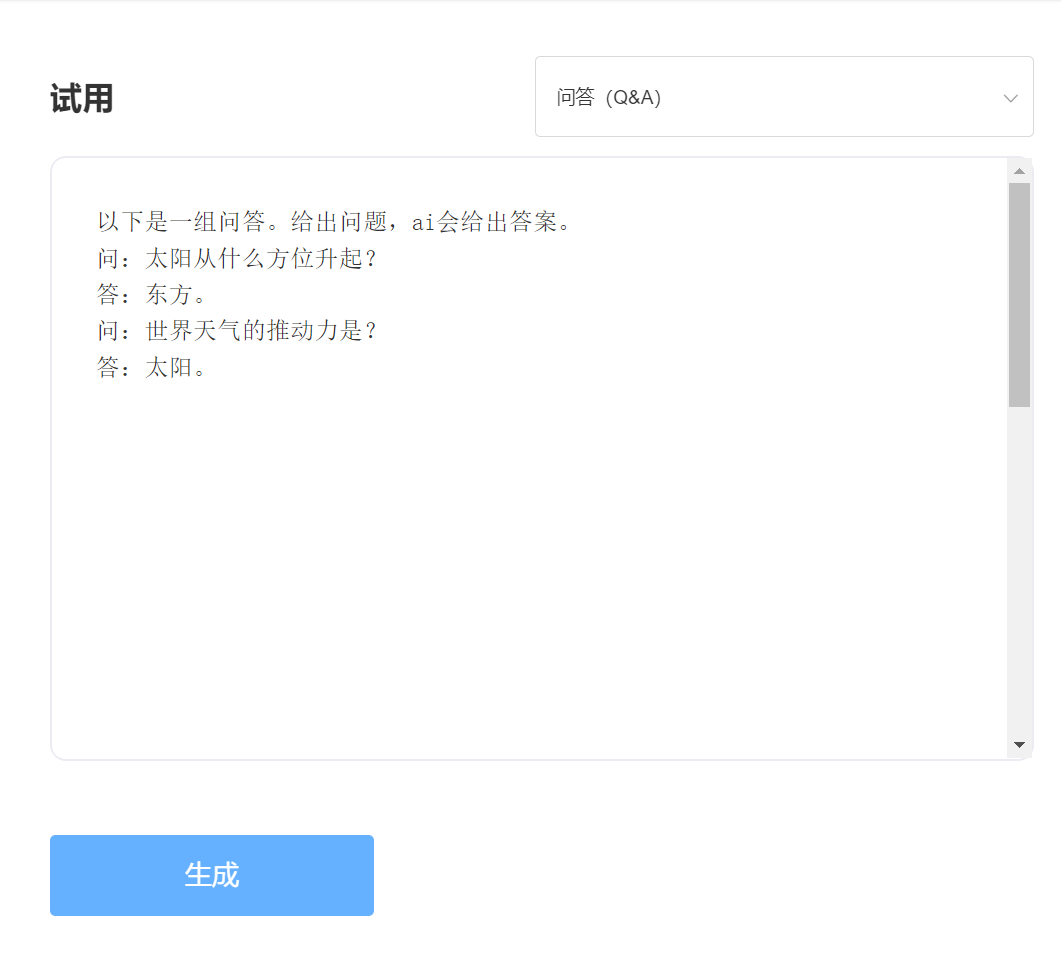
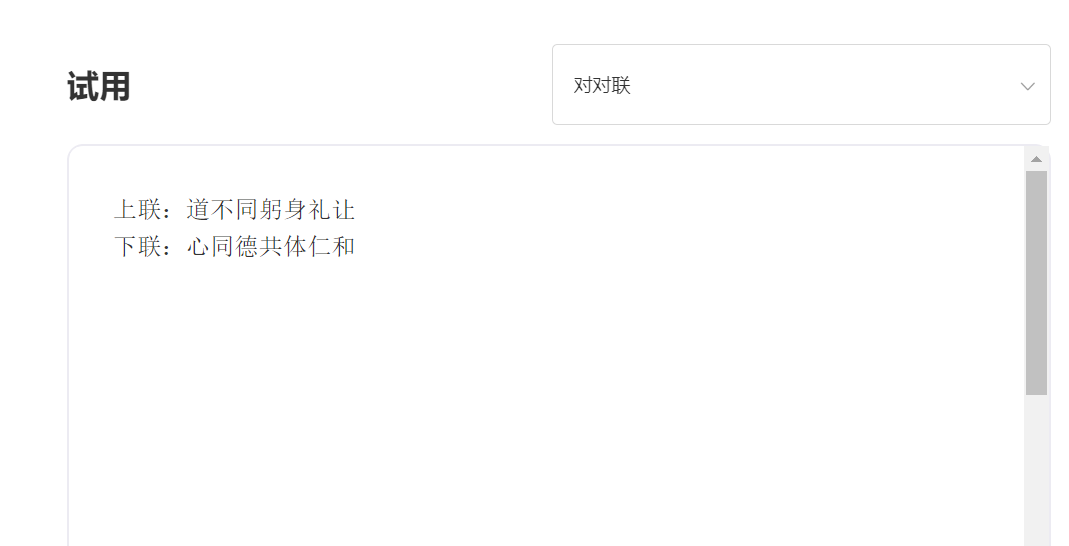
входить: 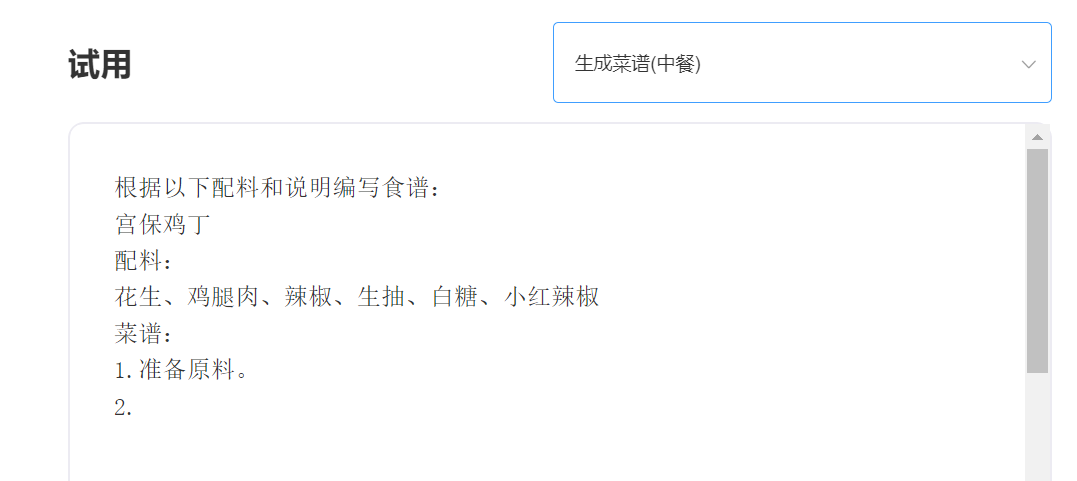
Выход: 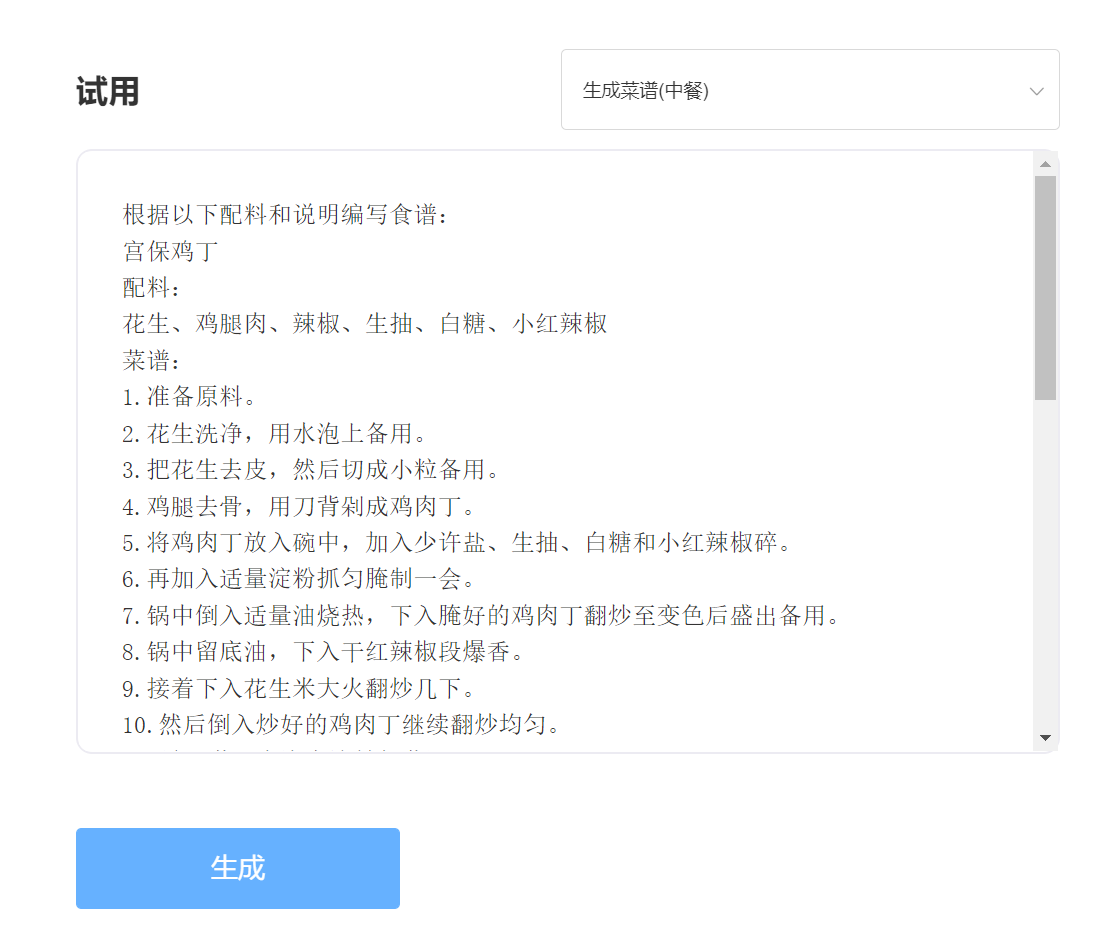
Техническое преимущество 1: очистка данных с более чем 30 процессами
С разработкой технологии НЛП предварительно обученные крупные модели постепенно становятся одной из основных технологий искусственного интеллекта. Предварительно обученные большие модели обычно требуют обучения масштабному тексту, и онлайн-текст, естественно, становится наиболее важным источником корпуса. Качество учебного корпуса, несомненно, напрямую влияет на эффективность модели. Чтобы обучить модель с выдающимися возможностями, Intelligence Singularity использовал более 30 процессов очистки при очистке данных. Изысканные детали создали отличные модели.
Техническое преимущество 2: Методы кодирования китайцев, которые оптимизируют и инновации китайцы
В области больших моделей перед тренировкой всегда доминировало английское сообщество, и важность предварительных тренировок крупных моделей на китайском языке является самоочевидной. В отличие от текста пиньина на английском языке, метод ввода китайского ввода китайских моделей, очевидно, должен отличаться. Интеллект сингулярности использует уникальные методы кодирования китайцев, основанные на характеристиках китайского языка, который в большей степени соответствует привычкам китайского языка и реконструирует китайский словарь, который более способствует пониманию модели.
——————————————————————————
推荐
transformers>=4.18.0
# -*- coding: utf-8 -*-
from transformers import GPT2LMHeadModel
from transformers import AutoTokenizer
from transformers import TextGenerationPipeline
# 以 SkyWork/SkyText(13billions) 为例,还有 SkyWork/SkyTextTiny(2.6billions) 可用, 期待使用
model = GPT2LMHeadModel . from_pretrained ( "SkyWork/SkyText" )
tokenizer = AutoTokenizer . from_pretrained ( "SkyWork/SkyText" , trust_remote_code = True )
text_generator = TextGenerationPipeline ( model , tokenizer , device = 0 )
input_str = "今天是个好天气"
max_new_tokens = 20
print ( text_generator ( input_str , max_new_tokens = max_new_tokens , do_sample = True )) MIT Лицензия