godot dodo
1.0.0

Godot-Dodo項目提出了一條管道,以從Github檢索到的人類創建的,特定於語言的代碼上的芬日開源語言模型。
在這種情況下,有針對性的語言是GDScript,但是可以將相同的方法應用於其他語言。
該存儲庫包括以下內容:
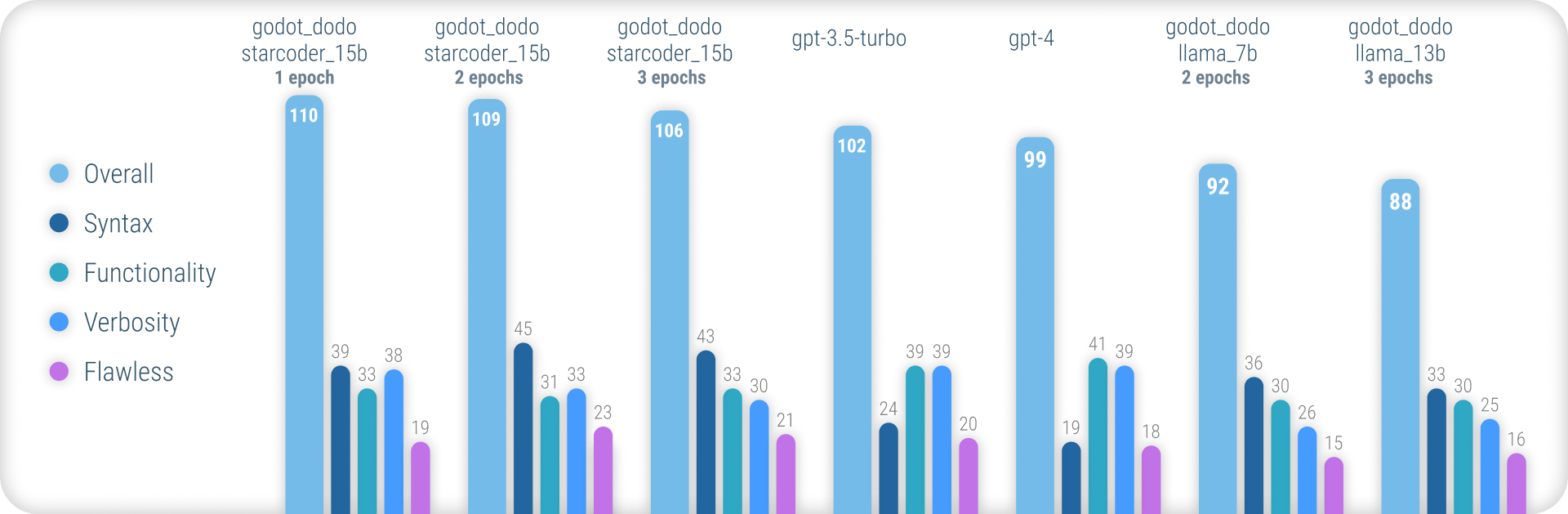
有關說明所使用方法的全面結果和所有結果的完整列表,請參閱此處的完整績效報告。
總而言之,在生成準確的GDScript語法時, godot_dodo模型的一致性明顯高於gpt-4 / GPT-4 / gpt-3.5-turbo ,並且在代碼特定的基礎模型上訓練的變體可以在復雜的指令上勝過它們。
這種方法的主要剩餘弱點是編寫方法時適當的冗長損失。由於人寫的樣本通常會引用對樣本方法範圍之外初始化的對象的引用,因此該模型學會執行相同的操作,從而在假定已經實現的功能相關的功能。更複雜的數據集很可能會大大改善這一點。
與其他類似的方法與斯坦福·阿爾帕卡(Stanford-Alpaca)這樣的固定模型的類似方法不同,這種方法並未將現有的,較大的語言模型用於FineTuning-Dataset的輸出值。所有使用的代碼都是人類創建的。相反,語言模型僅用於標記每個代碼段。
因此,我們可以以CodesearchNet的樣式組裝comment:code數據對,利用強大的現有模型來註釋高質量的人類創建的代碼。
一些現有的語言模型(例如gpt-4是出色的編碼器。但是,他們的許多能力僅集中在最受歡迎的語言中,例如Python或JavaScript。
在培訓數據中,使用較少的語言的代表性不足並體驗到大量的性能下降,在這種情況下,模型通常會誤認為語法或不存在的幻覺語言功能。
這旨在提供更強大的語言特定模型,這些模型可用於可靠地生成首次嘗試編譯的代碼。
To try out the pre-trained models, you can use the inference_demo.ipynb notebook.
為了在Google Colab上使用該筆記本,請點擊此鏈接。
由於這種方法依賴於人類創建的數據,因此我們使用GitHub搜索API刮擦GitHub存儲庫。
使用language:gdscript搜索詞,我們檢索包括GDScript代碼在內的存儲庫列表。
我們還使用license:mit將數據集限制為合適的存儲庫。僅使用MIT許可的代碼進行培訓!
然後,我們克隆每個人並應用以下邏輯:
project.godot文件3.x或4.x Godot發動機版本進行了項目.gd文件gpt-3.5-turbo ),以詳細說明功能目的instruction:response數據對到數據集請注意,位於代碼塊上方的現有的,人寫的評論未用於instruction值。我們對評論的一致細節感興趣,而不是試圖保留一些潛在的更高質量的人工編寫的人。
但是,保留了代碼塊中的人類評論。
要自己組裝數據集,請按照以下說明:
python data/generate_unlabeled_dataset.pypython data/label_dataset.py請注意,您需要GitHub和OpenAI API鍵才能使用這些腳本。
此存儲庫中包含的預組裝數據集:
4.x Godot項目組裝-〜60k行將來可能會添加更多數據集(尤其是關於3.x數據)
微調過程與Stanford_alpaca引入的過程緊密反映了過程。
要復制駱駝的微調版本,請按照以下步驟操作。
為了有效地捕獲llama-7b或llama-13b型號,強烈建議使用至少兩個A100 80GB GPU。否則,您可能會遇到內存錯誤或經歷非常長的訓練時間,並且需要調整培訓參數。
對於Finetuning godot_dodo_4x_60k_llama_13b ,使用了八個A100 80GB GPU。
另一個重要的考慮因素是用於GPU通信的協議。建議使用NVLink設置而不是PCIe 。
如果您只能訪問PCIe設置,請在torchrun命令中用shard_grad_op替換full-shard 。這可能會嚴重加快您的培訓的速度,而可能會以更高的內存使用費用。
填充之前,請確保使用以下方式安裝所有要求:
pip install -r requirements.txt對於用於登錄模型的精確命令,請參閱各個模型頁面:
為了測試您的固定模型,您可以使用eval.py腳本。只需運行:
python finetune/eval.py --model_name_or_path PATH_TO_FINETUNED_MODEL/要輕鬆將填充模型上傳到擁抱面,您可以使用:
python finetune/push_to_hub.py --model_name_or_path PATH_TO_FINETUNED_MODEL/ --push_name HF_MODEL_NAME --auth_token HF_ACCESS_TOKEN相應的模型頁面提供了在擁抱面上託管的模型權重的鏈接:
在組裝每個可用數據集並為每種型號填充的填充的美元以下。
30$ ( gpt-3.5-turbo API成本)24$ (8x A100 80GB實例成本)84$ (8x A100 80GB實例成本) 使用Godot-Copilot的填充模型用於編輯中,將來可能會支持全部本地代碼生成。
感謝所有獲得MIT許可的Godot項目!沒有你,這是不可能的。
在數據集中的數據集文件夾中列出了包含填充數據期間刮擦的所有項目。
另一個感謝您感謝FluidStack.io的可靠,便宜的GPU實例,用於對這些型號進行填充。
如果您想引用此項目,請使用:
@misc{godot-dodo,
author = {Markus Sobkowski},
title = {Godot-Dodo: Finetuned language models for GDScript generation},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/minosvasilias/godot-dodo}},
}
您還應該引用原始的駱駝紙以及斯坦福·阿爾帕卡(Stanford-Alpaca)。


