godot dodo
1.0.0

Godot-Dodo 프로젝트는 파이프 라인을 제시합니다. 파이프 라인은 Github에서 검색된 인간이 만든 언어 별 코드에 대한 오픈 소스 언어 모델을 미세한 파이프 라인을 제시합니다.
이 경우 대상 언어는 GDScript이지만 동일한 방법론은 다른 언어에 적용될 수 있습니다.
이 저장소에는 다음이 포함됩니다.
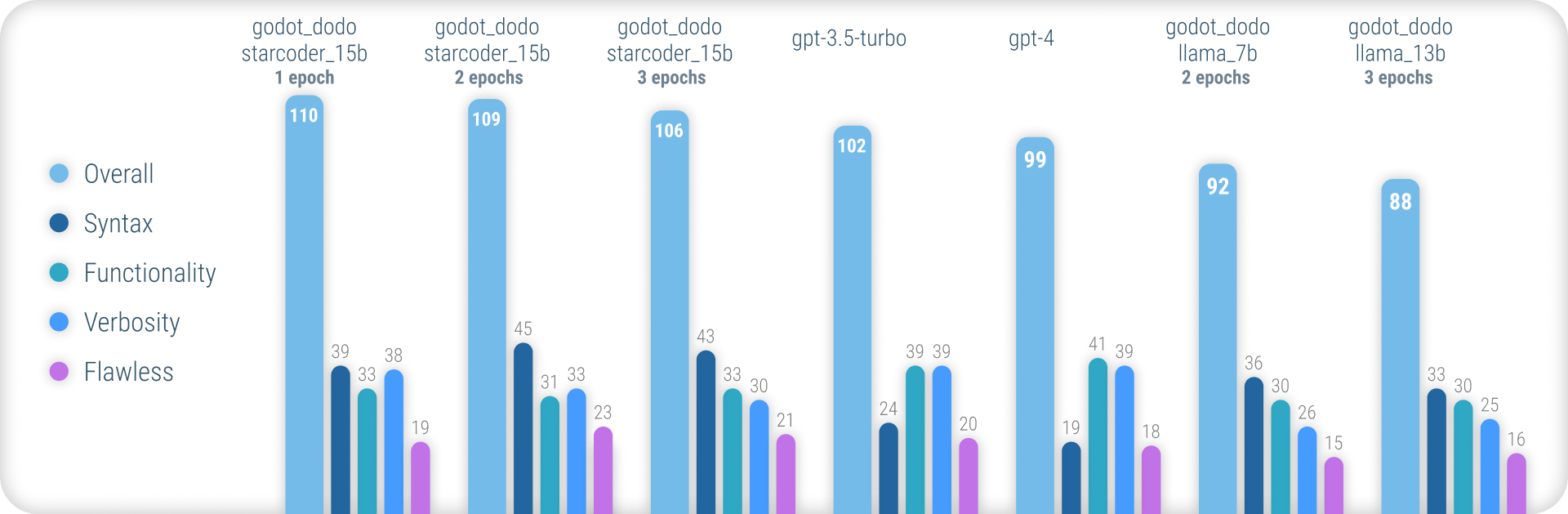
사용 된 방법론과 모든 결과의 전체 목록을 설명하는 포괄적 인 결과는 여기를 참조하십시오.
요약하면, godot_dodo 모델은 정확한 GDSCRIPT 구문을 생성 할 때 gpt-4 / gpt-3.5-turbo 보다 상당히 더 큰 일관성을 달성하며, 코드 별 기본 모델로 훈련 된 변형은 복잡한 지시 사항보다 성능이 우수 할 수 있습니다.
이 접근법의 주요 약점은 방법을 작성할 때 적절한 구두의 손실입니다. 인간이 작성한 샘플에는 종종 샘플 방법의 범위 외부에서 초기화 된 객체에 대한 참조가 포함되므로 모델은 동일하게 수행하는 법을 배웁니다.이 결과는 명령어와 관련된 기능이 이미 구현 된 것으로 가정됩니다. 이는보다 정교한 데이터 세트에 의해 크게 향상 될 수 있습니다.
스탠포드-알파카 (Stanford-Alpaca)와 같은 미세 조정 모델에 대한 유사한 접근 방식과 달리,이 접근법은 Finetuning-Dataset의 출력 값에 기존의 더 큰 언어 모델을 사용하지 않습니다. 사용 된 모든 코드는 인간으로 만들어졌습니다. 언어 모델은 대신 각 코드 스 니펫을 레이블링하는 데만 사용됩니다.
따라서 Codesearchnet 스타일의 comment:code 데이터 페어를 작성하여 강력한 기존 모델을 사용하여 고품질의 인간이 만든 코드를 주석을 달아주는 코드 데이터 페어를 조립할 수 있습니다.
gpt-4 와 같은 일부 기존 언어 모델은 우수한 코더입니다. 그러나 많은 능력은 Python 또는 JavaScript와 같은 가장 인기있는 언어에만 집중됩니다.
널리 사용되는 언어는 교육 데이터에서 저조하고 대규모 성능 하락을 경험하며, 모델은 일상적으로 구문 또는 환각이없는 언어 기능을 실수합니다.
이는 첫 번째 시도에서 컴파일하는 코드를 안정적으로 생성하는 데 사용될 수있는 훨씬 더 강력한 언어 별 모델을 제공하는 것을 목표로합니다.
미리 훈련 된 모델을 시험해 보려면 inference_demo.ipynb 노트북을 사용할 수 있습니다.
Google Colab에서 해당 노트북을 사용하려면이 링크를 따르십시오.
이 접근법으로 인간이 만든 데이터에 의존하기 때문에 GitHub 검색 API를 사용하여 GitHub 리포지토리를 긁어냅니다.
language:gdscript 검색 용어를 사용하면 GDSCRIPT 코드를 포함한 저장소 목록을 검색합니다.
또한 license:mit 사용하여 데이터 세트를 적합한 저장소로 제한합니다. MIT 라이센스 코드 만 훈련에 사용됩니다!
그런 다음 각각을 복제하고 다음 논리를 적용합니다.
project.godot 파일을 찾으십시오3.x 또는 4.x Godot 엔진 버전에 대한 프로젝트 감지.gd 파일을 반복하십시오gpt-3.5-turbo )에게 문의하십시오.instruction:response 데이터 쌍을 데이터 세트에 추가하십시오 코드 블록 위에 위치한 기존의 인간이 작성한 주석은 instruction 값에 사용되지 않습니다. 우리는 잠재적으로 고품질의 인간이 작성한 사람들을 보존하려고 노력하기보다는 의견에 대한 일관된 세부 사항에 관심이 있습니다.
그러나 코드 블록 내의 인간 의견은 보존됩니다.
데이터 세트를 직접 조립하려면 다음과 같은 지침을 따르십시오.
python data/generate_unlabeled_dataset.py 실행하십시오python data/label_dataset.py 실행하십시오이 스크립트를 사용하려면 Github 및 OpenAI API 키가 필요합니다.
이 저장소에 포함 된 사전 조립 된 데이터 세트 :
4.x Godot 프로젝트 - ~ 60k 행을 사용하여 조립 향후 추가 데이터 세트가 추가 될 수 있습니다 (특히 3.x 데이터와 관련하여)
미세 조정 과정은 Stanford_alpaca가 도입 한 과정을 밀접하게 반영합니다.
미세 조정 된 라마 버전을 재현하려면 아래 단계를 따르십시오.
llama-7b 또는 llama-13b 모델을 효과적으로 미선급하려면 적어도 2 개의 A100 80GB GPU를 사용하는 것이 좋습니다. 그렇지 않으면 메모리 오류가 발생하거나 매우 긴 교육 시간을 경험할 수 있으며 교육 매개 변수를 조정해야합니다.
godot_dodo_4x_60k_llama_13b 찾기 위해서는 8 개의 A100 80GB GPU가 사용되었습니다.
또 다른 중요한 고려 사항은 GPU 통신에 사용되는 프로토콜입니다. PCIe 대신 NVLink 설정을 사용하는 것이 좋습니다.
PCIe 설정에만 액세스 할 수있는 경우 torchrun 명령에서 full-shard shard_grad_op 로 교체하십시오. 이것은 잠재적으로 더 높은 메모리 사용량의 비용으로 훈련 실행 속도를 심각하게 높일 수 있습니다.
미세 조정하기 전에 다음을 사용하여 모든 요구 사항을 설치하십시오.
pip install -r requirements.txt결합 모델에 사용되는 정확한 명령은 개별 모델 페이지를 참조하십시오.
Finetuned 모델을 테스트하려면 eval.py 스크립트를 사용할 수 있습니다. 단순히 실행 :
python finetune/eval.py --model_name_or_path PATH_TO_FINETUNED_MODEL/Finetuned 모델을 HuggingFace에 쉽게 업로드하려면 다음을 사용할 수 있습니다.
python finetune/push_to_hub.py --model_name_or_path PATH_TO_FINETUNED_MODEL/ --push_name HF_MODEL_NAME --auth_token HF_ACCESS_TOKENHuggingface에서 호스팅 된 모델 가중치에 대한 링크는 각 모델 페이지에 제공됩니다.
사용 가능한 각 데이터 세트를 조립하고 각 모델을 미세 조정하는 달러 코스트 아래.
30$ ( gpt-3.5-turbo API 비용)24$ (8x A100 80GB 인스턴스 비용)84$ (8x A100 80GB 인스턴스 비용) 편집자를위한 Godot-Copilot을 사용한 Finetuned 모델 사용은 미래에 완전한 로컬 코드 생성이 지원 될 수 있습니다.
모든 Mit-Licensed Godot 프로젝트에 감사드립니다! 이것은 당신 없이는 불가능할 것입니다.
포함 된 양조 데이터를 조립하는 동안 긁힌 모든 프로젝트는 데이터의 각 데이터 세트 폴더에 나열됩니다.
또 다른 감사는 이러한 모델을 미세 조정하는 데 사용 된 신뢰할 수 있고 저렴한 GPU 인스턴스를 위해 Fluidstack.io를 방문하십시오.
이 프로젝트를 인용하려면 다음을 사용하십시오.
@misc{godot-dodo,
author = {Markus Sobkowski},
title = {Godot-Dodo: Finetuned language models for GDScript generation},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/minosvasilias/godot-dodo}},
}
또한 스탠포드-알파카뿐만 아니라 오리지널 라마 페이퍼를 인용해야합니다.


