godot dodo
1.0.0

Godot-Dodoプロジェクトは、Githubから取得された人間が作成した言語固有のコードに関するパイプラインからオープンソース言語モデルを微調整することを提示します。
この場合、ターゲット言語はGDScriptですが、同じ方法論を他の言語に適用できます。
このリポジトリには次のものが含まれています。
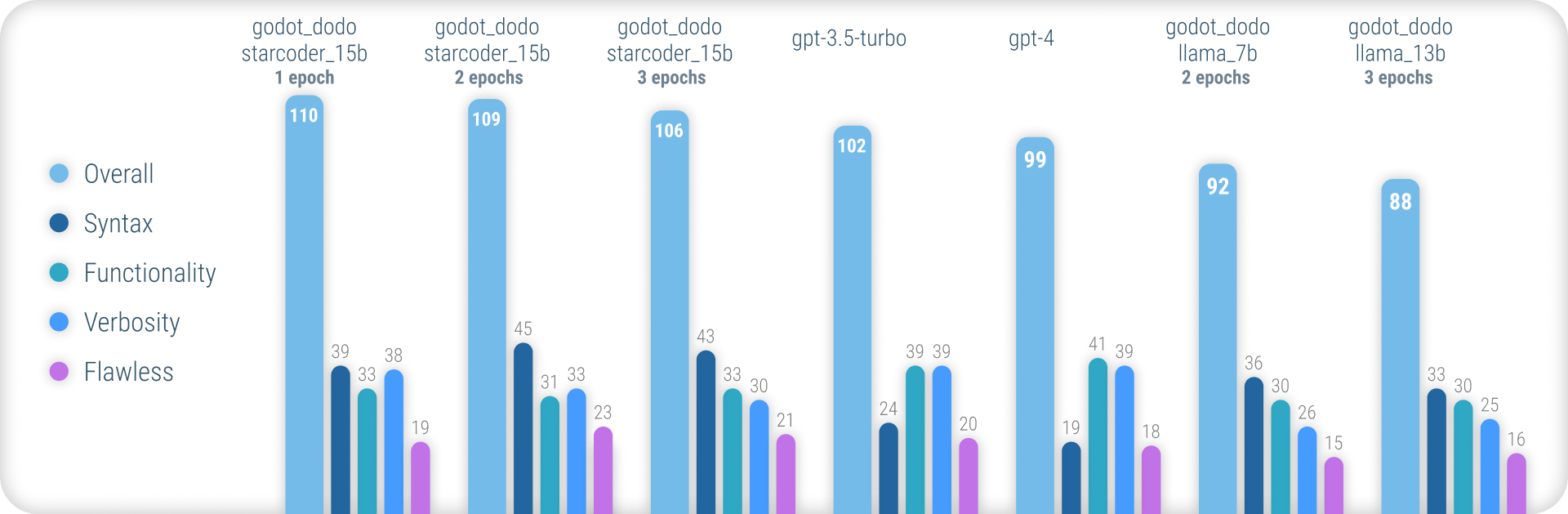
使用された方法論を説明する包括的な結果とすべての結果の完全なリストについては、こちらの完全なパフォーマンスレポートを参照してください。
要約すると、 godot_dodoモデルは、正確なGDScriptの構文を生成することに関して、 gpt-4 / gpt-3.5-turboよりも大幅に大きな一貫性を達成し、コード固有のベースモデルでトレーニングされたバリアントは、複雑な命令でそれらを上回ることさえできます。
このアプローチの主要な残りの弱点は、方法を作成する際の適切な冗長性の損失です。人間が作成したサンプルには、サンプルメソッドの範囲外で初期化されたオブジェクトへの参照が含まれることが多いため、モデルは同じことを行うことを学び、命令に関連する機能がすでに実装されていると想定される場合になります。これは、より洗練されたデータセットによって大幅に改善される可能性が高いです。
Stanford-AlpacaなどのFinetuningモデルに対する他の同様のアプローチとは異なり、このアプローチでは、Finetuning-Datasetの出力値に既存の大きな言語モデルを使用しません。使用されるすべてのコードは人間が作成しています。代わりに、言語モデルは各コードスニペットにラベルを付けるためにのみ使用されます。
そのため、 comment:codeデータペア。強力な既存のモデルを利用して、高品質の人間が作成したコードに注釈を付けます。
gpt-4などの一部の既存の言語モデルは優れたコーダーです。ただし、その能力の多くは、PythonやJavaScriptなどの最も人気のある言語のみに集中しています。
あまり広く使用されていない言語は、トレーニングデータで過小評価されており、モデルが存在しない構文や幻覚言語の機能を日常的に間違えるという大規模なパフォーマンスのドロップオフを経験します。
これは、最初のトライでコンパイルするコードを確実に生成するために使用できる、はるかに堅牢な言語固有のモデルを提供することを目的としています。
事前に訓練されたモデルを試すには、Inference_demo.ipynbノートブックを使用できます。
Google Colabでそのノートブックを使用するには、このリンクに従ってください。
このアプローチが人間が作成したデータに依存しているため、GitHub検索APIを使用してGitHubリポジトリをスクレイします。
language:gdscript検索用語では、GDScriptコードを含むリポジトリのリストを取得します。
また、 license:mitを使用して、データセットを適切なリポジトリに制限します。トレーニングにはMITライセンスコードのみが使用されます!
次に、それぞれをクローンして、次のロジックを適用します。
project.godotファイルを見つけます3.xまたは4.x Godotエンジンバージョン用にプロジェクトが作成されているかどうかを検出します.gdファイルを繰り返しますgpt-3.5-turbo )に尋ねますinstruction:responseデータペアコードブロックの上にある既存の人間が作成したコメントは、 instruction値には使用されていないことに注意してください。私たちは、潜在的に高品質の人間が書いたものを維持しようとするのではなく、コメントの一貫した詳細に興味があります。
ただし、コードブロック内の人間のコメントは保持されています。
自分でデータセットを組み立てるには、次の手順に従ってください。
python data/generate_unlabeled_dataset.pyを実行しますpython data/label_dataset.pyを実行しますこれらのスクリプトを使用するには、GitHubとOpenai APIキーが必要であることに注意してください。
このリポジトリに含まれる事前に組み立てられたデータセット:
4.x Godotプロジェクトを使用して組み立てられました - 〜60k行将来、さらにデータセットが追加される可能性があります(特に3.xデータに関して)
微調整プロセスは、Stanford_alpacaによって導入されたプロセスを密接に反映しています。
ラマの微調整バージョンを再現するには、以下の手順に従ってください。
llama-7bまたはllama-13bモデルを効果的に微調整するには、少なくとも2つのA100 80GB GPUを使用することを強くお勧めします。それ以外の場合は、メモリエラーから遭遇したり、非常に長いトレーニング時間を経験したりする可能性があり、トレーニングパラメーターを調整する必要があります。
Finetuning godot_dodo_4x_60k_llama_13bには、8つのA100 80GB GPUが使用されました。
もう1つの重要な考慮事項は、GPU通信に使用されるプロトコルです。 PCIeではなくNVLinkセットアップを使用することをお勧めします。
PCIeセットアップのみにアクセスできる場合は、 torchrunコマンドのshard_grad_opにfull-shardを置き換えてください。これにより、メモリの使用量が高い可能性があるため、トレーニングの実行が大幅に高速化される場合があります。
Finetuningの前に、以下を使用してすべての要件をインストールしてください。
pip install -r requirements.txt微調整モデルに使用される正確なコマンドについては、個々のモデルページを参照してください。
Finetunedモデルをテストするには、 eval.pyスクリプトを使用できます。単純に実行:
python finetune/eval.py --model_name_or_path PATH_TO_FINETUNED_MODEL/FINETUNEDモデルをハグFaceに簡単にアップロードするには、以下を使用できます。
python finetune/push_to_hub.py --model_name_or_path PATH_TO_FINETUNED_MODEL/ --push_name HF_MODEL_NAME --auth_token HF_ACCESS_TOKENHuggingfaceでホストされているモデル重量へのリンクは、それぞれのモデルページで提供されています。
利用可能な各データセットを組み立て、各モデルを獲得するドルコストの下。
30$ ( gpt-3.5-turbo APIコスト)24$ (8x A100 80GBインスタンスコスト)84$ (8x A100 80GBインスタンスコスト) 編集者のためのGodot-Copilotを使用したFinetunedモデルの使用、完全にローカルコード生成が将来サポートされる場合があります。
すべてのMITライセンスのGodotプロジェクトに感謝します!これはあなたなしでは不可能です。
含まれているFinetuningデータのアセンブリ中に削られたすべてのプロジェクトは、データのそれぞれのデータセットフォルダーにリストされています。
これらのモデルを微調整するために使用された信頼できる安価なGPUインスタンスについて、fluidstack.ioに感謝します。
このプロジェクトを引用したい場合は、以下を使用してください。
@misc{godot-dodo,
author = {Markus Sobkowski},
title = {Godot-Dodo: Finetuned language models for GDScript generation},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/minosvasilias/godot-dodo}},
}
また、オリジナルのLlama PaperとStanford-Alpacaを引用する必要があります。


