godot dodo
1.0.0

Godot-Dodo项目提出了一条管道,以从Github检索到的人类创建的,特定于语言的代码上的芬日开源语言模型。
在这种情况下,有针对性的语言是GDScript,但是可以将相同的方法应用于其他语言。
该存储库包括以下内容:
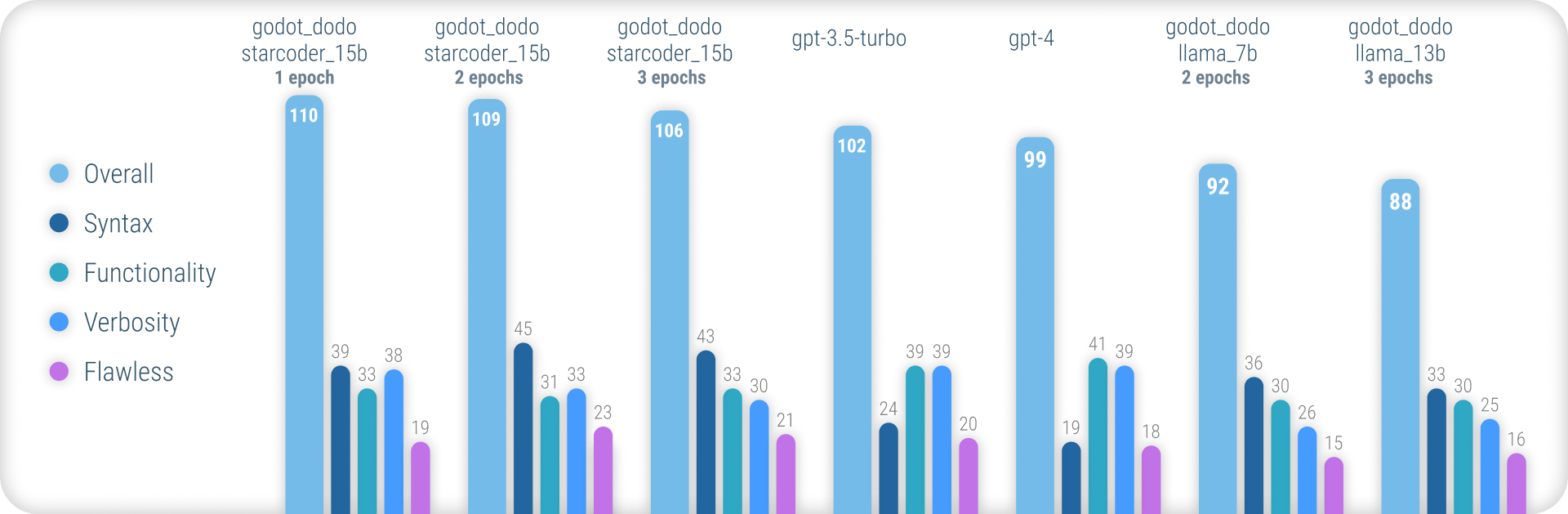
有关说明所使用方法的全面结果和所有结果的完整列表,请参阅此处的完整绩效报告。
总而言之,在生成准确的GDScript语法时, godot_dodo模型的一致性明显高于gpt-4 / GPT-4 / gpt-3.5-turbo ,并且在代码特定的基础模型上训练的变体可以在复杂的指令上胜过它们。
这种方法的主要剩余弱点是编写方法时适当的冗长损失。由于人写的样本通常会引用对样本方法范围之外初始化的对象的引用,因此该模型学会执行相同的操作,从而在假定已经实现的功能相关的功能。更复杂的数据集很可能会大大改善这一点。
与其他类似的方法与斯坦福·阿尔帕卡(Stanford-Alpaca)这样的固定模型的类似方法不同,这种方法并未将现有的,较大的语言模型用于FineTuning-Dataset的输出值。所有使用的代码都是人类创建的。相反,语言模型仅用于标记每个代码段。
因此,我们可以以CodesearchNet的样式组装comment:code数据对,利用强大的现有模型来注释高质量的人类创建的代码。
一些现有的语言模型(例如gpt-4是出色的编码器。但是,他们的许多能力仅集中在最受欢迎的语言中,例如Python或JavaScript。
在培训数据中,使用较少的语言的代表性不足并体验到大量的性能下降,在这种情况下,模型通常会误认为语法或不存在的幻觉语言功能。
这旨在提供更强大的语言特定模型,这些模型可用于可靠地生成首次尝试编译的代码。
To try out the pre-trained models, you can use the inference_demo.ipynb notebook.
为了在Google Colab上使用该笔记本,请点击此链接。
由于这种方法依赖于人类创建的数据,因此我们使用GitHub搜索API刮擦GitHub存储库。
使用language:gdscript搜索词,我们检索包括GDScript代码在内的存储库列表。
我们还使用license:mit将数据集限制为合适的存储库。仅使用MIT许可的代码进行培训!
然后,我们克隆每个人并应用以下逻辑:
project.godot文件3.x或4.x Godot发动机版本进行了项目.gd文件gpt-3.5-turbo ),以详细说明功能目的instruction:response数据对到数据集请注意,位于代码块上方的现有的,人写的评论未用于instruction值。我们对评论的一致细节感兴趣,而不是试图保留一些潜在的更高质量的人工编写的人。
但是,保留了代码块中的人类评论。
要自己组装数据集,请按照以下说明:
python data/generate_unlabeled_dataset.pypython data/label_dataset.py请注意,您需要GitHub和OpenAI API键才能使用这些脚本。
此存储库中包含的预组装数据集:
4.x Godot项目组装-〜60k行将来可能会添加更多数据集(尤其是关于3.x数据)
微调过程与Stanford_alpaca引入的过程紧密反映了过程。
要复制骆驼的微调版本,请按照以下步骤操作。
为了有效地捕获llama-7b或llama-13b型号,强烈建议使用至少两个A100 80GB GPU。否则,您可能会遇到内存错误或经历非常长的训练时间,并且需要调整培训参数。
对于Finetuning godot_dodo_4x_60k_llama_13b ,使用了八个A100 80GB GPU。
另一个重要的考虑因素是用于GPU通信的协议。建议使用NVLink设置而不是PCIe 。
如果您只能访问PCIe设置,请在torchrun命令中用shard_grad_op替换full-shard 。这可能会严重加快您的培训的速度,而可能会以更高的内存使用费用。
填充之前,请确保使用以下方式安装所有要求:
pip install -r requirements.txt对于用于登录模型的精确命令,请参阅各个模型页面:
为了测试您的固定模型,您可以使用eval.py脚本。只需运行:
python finetune/eval.py --model_name_or_path PATH_TO_FINETUNED_MODEL/要轻松将填充模型上传到拥抱面,您可以使用:
python finetune/push_to_hub.py --model_name_or_path PATH_TO_FINETUNED_MODEL/ --push_name HF_MODEL_NAME --auth_token HF_ACCESS_TOKEN相应的模型页面提供了在拥抱面上托管的模型权重的链接:
在组装每个可用数据集并为每种型号填充的填充的美元以下。
30$ ( gpt-3.5-turbo API成本)24$ (8x A100 80GB实例成本)84$ (8x A100 80GB实例成本) 使用Godot-Copilot的填充模型用于编辑中,将来可能会支持全部本地代码生成。
感谢所有获得MIT许可的Godot项目!没有你,这是不可能的。
在数据集中的数据集文件夹中列出了包含填充数据期间刮擦的所有项目。
另一个感谢您感谢FluidStack.io的可靠,便宜的GPU实例,用于对这些型号进行填充。
如果您想引用此项目,请使用:
@misc{godot-dodo,
author = {Markus Sobkowski},
title = {Godot-Dodo: Finetuned language models for GDScript generation},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/minosvasilias/godot-dodo}},
}
您还应该引用原始的骆驼纸以及斯坦福·阿尔帕卡(Stanford-Alpaca)。


