godot dodo
1.0.0

Le projet Godot-Dodo présente un pipeline pour les modèles de langue open source Finetune sur le code spécifique à la langue créé par l'homme récupéré à partir de GitHub.
Dans ce cas, le langage ciblé est GDScript, mais la même méthodologie peut être appliquée à d'autres langues.
Ce référentiel comprend les éléments suivants:
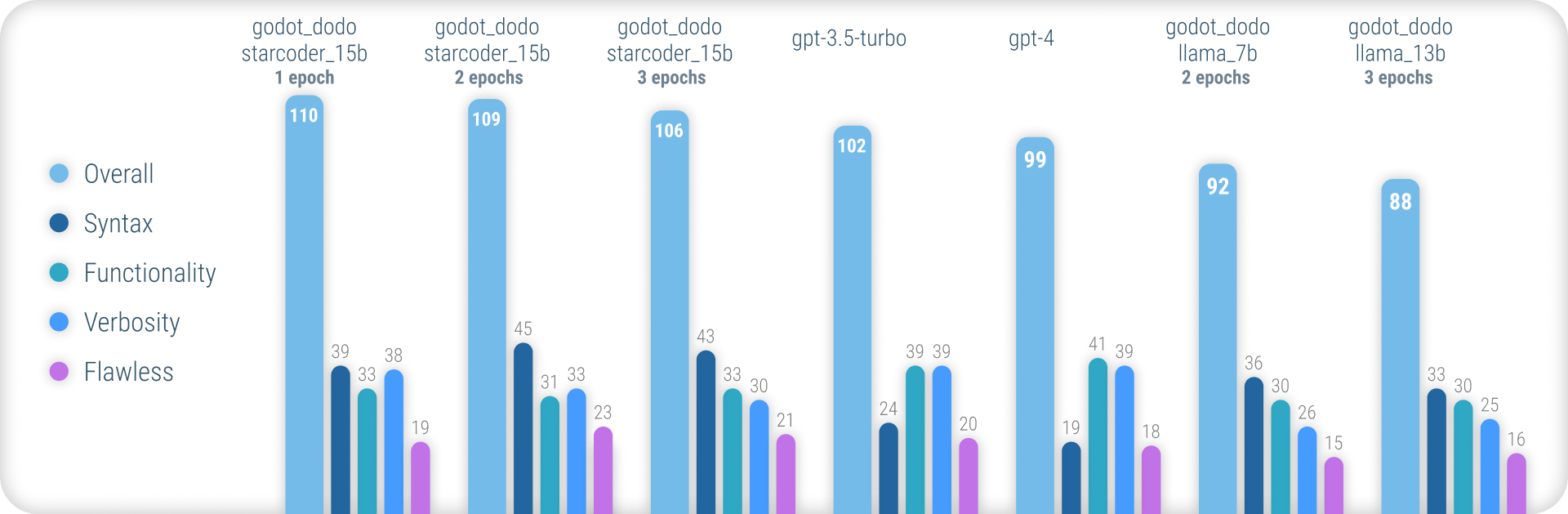
Pour des résultats complets expliquant la méthodologie utilisée et une liste complète de tous les résultats, veuillez vous référer au rapport de performance complet ici.
En résumé, les modèles godot_dodo atteignent une cohérence nettement plus grande que gpt-4 / gpt-3.5-turbo lorsqu'il s'agit de générer une syntaxe GDScript précise, et des variantes formées sur des modèles de base spécifiques au code peuvent même les surpasser sur des instructions complexes.
Le principal point faible restant de cette approche est la perte de verbosité appropriée lors de l'écriture de méthodes. Étant donné que les échantillons rédigés par l'homme comprendront souvent des références aux objets initialisés en dehors de la portée de la méthode de l'échantillon, le modèle apprend à faire de même, entraînant des cas où la fonctionnalité pertinente pour l'instruction est supposée être déjà mise en œuvre. Cela peut très probablement être considérablement amélioré par un ensemble de données plus sophistiqué.
Contrairement à d'autres approches similaires pour les modèles de finetuning tels que Stanford-Alpaca, cette approche n'utilise pas de modèles de langage plus grands existants pour les valeurs de sortie du Dataset Finetuning. Tout le code utilisé est créé par l'homme. Les modèles de langue ne sont plutôt utilisés que pour étiqueter chaque extrait de code.
En tant que tel, nous pouvons assembler comment:code de données dans le style de CodesearchNet, en utilisant des modèles existants puissants pour annoter le code créé par l'homme de haute qualité.
Certains modèles de langue existants tels que gpt-4 sont d'excellents codeurs. Cependant, une grande partie de leur capacité n'est concentrée que dans les langues les plus populaires, comme Python ou JavaScript.
Les langues moins largement utilisées sont sous-représentées dans les données de formation et connaissent une baisse massive de performances, où les modèles confondent régulièrement la syntaxe ou les fonctionnalités linguistiques hallucinées qui n'existent pas.
Cela vise à fournir des modèles spécifiques au langage beaucoup plus robustes qui peuvent être utilisés pour générer de manière fiable du code qui compile le premier essai.
Pour essayer les modèles pré-formés, vous pouvez utiliser le cahier Inference_demo.ipynb.
Pour utiliser ce cahier sur Google Colab, suivez ce lien.
En raison de cette approche qui reposait sur des données créées par l'homme, nous gratons les référentiels GitHub à l'aide de l'API de recherche GitHub.
En utilisant le terme de recherche language:gdscript , nous récupérons une liste de référentiels, y compris le code GDScript.
Nous utilisons également license:mit pour limiter l'ensemble de données aux référentiels appropriés. Seul le code sous licence MIT est utilisé pour la formation!
Nous clonons ensuite chacun et appliquons la logique suivante:
project.godot Fichier3.x ou 4.x Godot.gd trouvés dans le référentielgpt-3.5-turbo ) un commentaire détaillé décrivant l'objectif des fonctionsinstruction:response à l'ensemble de données Notez que les commentaires existants et écrits humains situés au-dessus du bloc de code ne sont pas utilisés pour la valeur instruction . Nous sommes intéressés par des détails cohérents pour les commentaires, plutôt que d'essayer de préserver des détails potentiellement de plus haute qualité écrits par l'homme.
Les commentaires humains dans le bloc de code sont cependant préservés.
Pour assembler un ensemble de données vous-même, suivez ces instructions:
python data/generate_unlabeled_dataset.pypython data/label_dataset.pyVeuillez noter que vous aurez besoin de clés API GitHub et OpenAI afin d'utiliser ces scripts.
Ensembles de données pré-assemblés inclus dans ce référentiel:
4.x projets Godot - ~ 60k lignes D'autres ensembles de données peuvent être ajoutés à l'avenir (en particulier concernant les données 3.x )
Le processus de réglage fin reflète de près celui introduit par Stanford_alpaca.
Pour reproduire une version affinée de Llama, veuillez suivre les étapes ci-dessous.
Afin de finertune A llama-7b ou llama-13b , il est fortement recommandé d'utiliser au moins deux GPU A100 80GB . Vous pourriez autrement rencontrer des erreurs de mémoire ou ressentir des temps de formation extrêmement longs, et vous devrez ajuster les paramètres de formation.
Pour Finetuning godot_dodo_4x_60k_llama_13b , huit GPU A100 80GB ont été utilisés.
Une autre considération importante est le protocole utilisé pour la communication GPU. Il est recommandé d'utiliser des configurations NVLink plutôt que PCIe .
Si vous n'avez accès qu'aux configurations PCIe , veuillez remplacer full-shard par shard_grad_op dans la commande torchrun . Cela peut accélérer gravement vos courses d'entraînement au prix d'une utilisation potentiellement plus élevée de la mémoire.
Avant la finetuning, assurez-vous d'installer toutes les exigences en utilisant:
pip install -r requirements.txtPour les commandes exactes utilisées pour les modèles de finetuning, veuillez vous référer aux pages de modèle individuelles:
Pour tester votre modèle à finet, vous pouvez utiliser le script eval.py Courez simplement:
python finetune/eval.py --model_name_or_path PATH_TO_FINETUNED_MODEL/Pour télécharger facilement un modèle Finetuned sur HuggingFace, vous pouvez utiliser:
python finetune/push_to_hub.py --model_name_or_path PATH_TO_FINETUNED_MODEL/ --push_name HF_MODEL_NAME --auth_token HF_ACCESS_TOKENLes liens vers les poids des modèles hébergés sur HuggingFace sont fournis dans les pages du modèle respectives:
Sous le coût en dollars de l'assemblage de chaque ensemble de données disponible et de la fin de chaque modèle.
30$ (coûts API gpt-3.5-turbo )24$ (8x A100 80 Go d'instance coûte)84$ (8x A100 80 Go d'instance coûte) L'utilisation de modèles finetuned avec Godot-Copilot pour l'éditeur en éditeur, la génération de code entièrement locale peut être soutenue à l'avenir.
Merci à tous les projets Godot sous licence MIT! Ce ne serait pas possible sans vous.
Tous les projets qui ont été grattés lors de l'assemblage des données de finetuning inclus sont répertoriés dans les dossiers de données respectifs dans les données.
Un autre merci à FluidStack.io pour leurs instances de GPU fiables et bon marché qui ont été utilisées pour la fin de ces modèles.
Si vous souhaitez citer ce projet, veuillez utiliser:
@misc{godot-dodo,
author = {Markus Sobkowski},
title = {Godot-Dodo: Finetuned language models for GDScript generation},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/minosvasilias/godot-dodo}},
}
Vous devez également citer le papier lama d'origine ainsi que Stanford-Alpaca.


