godot dodo
1.0.0

El Proyecto Godot-Dodo presenta una tubería para Finetune Modelos de lenguaje de código abierto en código de lenguaje creado por humanos y específico de lenguaje recuperado de GitHub.
En este caso, el lenguaje dirigido es GDScript, pero la misma metodología se puede aplicar a otros idiomas.
Este repositorio incluye lo siguiente:
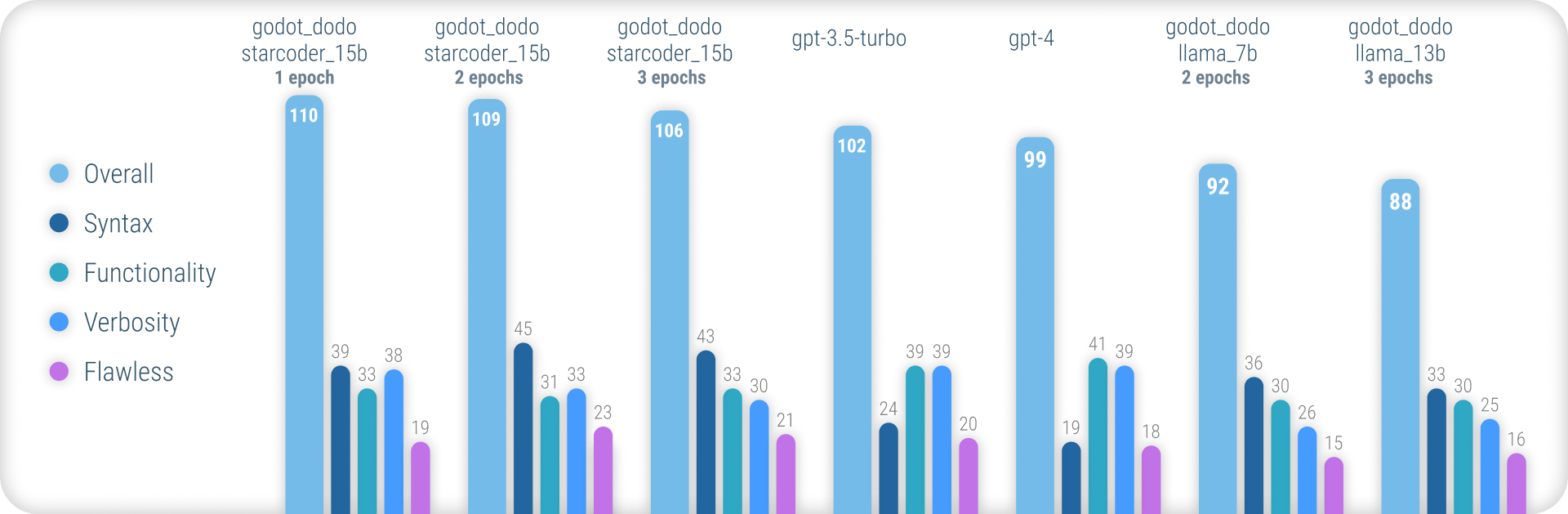
Para obtener resultados completos que explicen la metodología utilizada y una lista completa de todos los resultados, consulte el informe de rendimiento completo aquí.
En resumen, los modelos godot_dodo logran una consistencia significativamente mayor que gpt-4 / gpt-3.5-turbo cuando se trata de generar una sintaxis GDScript precisa, y las variantes entrenadas en modelos base específicos de código pueden incluso superarlos en instrucciones complejas.
El principal punto débil restante de este enfoque es la pérdida en la verbosidad apropiada al escribir métodos. Dado que las muestras escritas por humanos a menudo incluirán referencias a objetos inicializados fuera del alcance del método de muestra, el modelo aprende a hacer lo mismo, lo que resulta en los casos en que se supone que la funcionalidad relevante para la instrucción ya está implementada. Lo más probable es que esto pueda mejorarse significativamente mediante un conjunto de datos más sofisticado.
A diferencia de otros, enfoques similares para los modelos de Finetuning como Stanford-Alpaca, este enfoque no utiliza modelos de lenguaje existentes y más grandes para los valores de salida de la DataSet Finetuning. Todo el código utilizado es creado por humanos. En cambio, los modelos de lenguaje solo se usan para etiquetar cada fragmento de código.
Como tal, podemos ensamblar comment:code en el estilo de CodeSearchnet, haciendo uso de modelos existentes potentes para anotar el código creado por humanos de alta calidad.
Algunos modelos de idiomas existentes como gpt-4 son excelentes codificadores. Sin embargo, gran parte de su habilidad se concentra solo en los idiomas más populares, como Python o JavaScript.
Los idiomas menos utilizados están subrepresentados en los datos de capacitación y experimentan una caída masiva de rendimiento, donde los modelos confunden rutinariamente la sintaxis o alucinan las características del lenguaje que no existen.
Esto tiene como objetivo proporcionar modelos mucho más robustos específicos del lenguaje que se puedan utilizar para generar un código de manera confiable que se compila por primera prueba.
Para probar los modelos previamente capacitados, puede usar el cuaderno Inference_Demo.ipynb.
Para usar ese cuaderno en Google Colab, siga este enlace.
Debido a que este enfoque se basa en datos creados por humanos, raspamos los repositorios de GitHub utilizando la API de búsqueda de GitHub.
Usando el término de búsqueda language:gdscript , recuperamos una lista de repositorios, incluido el código GDSCRIPT.
También usamos license:mit para limitar el conjunto de datos a repositorios adecuados. ¡Solo se usa el código con licencia del MIT para el entrenamiento!
Luego clonamos cada uno y aplicamos la siguiente lógica:
project.godot3.x o 4.x GOOTOT.gd encontrados en el repositoriogpt-3.5-turbo ) para un comentario detallado que describe el propósito de las funcionesinstruction:response al conjunto de datos Tenga en cuenta que los comentarios existentes y escritos por humanos ubicados sobre el bloque de código no se utilizan para el valor instruction . Estamos interesados en detalles consistentes para los comentarios, en lugar de tratar de preservar algunos de una calidad potencialmente escrita humana.
Sin embargo, se conservan comentarios humanos dentro del bloque de código.
Para ensamblar un conjunto de datos usted mismo, siga estas instrucciones:
python data/generate_unlabeled_dataset.pypython data/label_dataset.pyTenga en cuenta que necesitará teclas API GitHub y OpenAI para usar estos scripts.
Conjuntos de datos previamente ensamblados incluidos en este repositorio:
4.x proyectos de Godot - ~ 60k filas Se pueden agregar más conjuntos de datos en el futuro (particularmente con respecto a 3.x datos)
El proceso de ajuste fino refleja el que introducido por Stanford_Alpaca.
Para reproducir una versión ajustada de Llama, siga los pasos a continuación.
Para Finetune efectivamente un modelo llama-7b o llama-13b , se recomienda usar al menos dos GPU A100 80GB . De lo contrario, puede encontrar errores de memoria o experimentar tiempos de entrenamiento extremadamente largos, y deberá ajustar los parámetros de entrenamiento.
Para Finetuning godot_dodo_4x_60k_llama_13b , se usaron ocho GPU A100 80GB .
Otra consideración importante es el protocolo utilizado para la comunicación de GPU. Se recomienda usar configuraciones NVLink en lugar de PCIe .
Si solo tiene acceso a las configuraciones PCIe , reemplace full-shard con shard_grad_op en el comando torchrun . Esto puede acelerar severamente sus ejecuciones de entrenamiento a costa del uso de memoria potencialmente más alto.
Antes de Finetuning, asegúrese de instalar todos los requisitos utilizando:
pip install -r requirements.txtPara los comandos exactos utilizados para los modelos Finetuning, consulte las páginas de modelos individuales:
Para probar su modelo Finetuned, puede usar el script eval.py Simplemente ejecute:
python finetune/eval.py --model_name_or_path PATH_TO_FINETUNED_MODEL/Para cargar fácilmente un modelo Finetuned a Huggingface, puede usar:
python finetune/push_to_hub.py --model_name_or_path PATH_TO_FINETUNED_MODEL/ --push_name HF_MODEL_NAME --auth_token HF_ACCESS_TOKENLos enlaces a los pesos de modelos alojados en Huggingface se proporcionan en las páginas modelo respectivas:
Debajo del costo en dólares de ensamblar cada conjunto de datos disponible y Finetuning cada modelo.
30$ ( gpt-3.5-turbo API Costos)24$ (8x A100 Costos de instancia de 80 GB)84$ (8x A100 Costos de instancia de 80 GB) El uso de modelos Finetuned con Godot-Copilot para la generación de código en el editor, completamente local, puede ser compatible con el futuro.
¡Gracias a todos los proyectos de Godot con licencia del MIT! Esto no sería posible sin ti.
Todos los proyectos que fueron raspados durante el ensamblaje de los datos de Finetuning incluidos se enumeran en las respectivas carpetas del conjunto de datos en los datos.
Otro agradecimiento a FluidStack.io por sus instancias de GPU confiables y baratas que se usaron para sintonizar estos modelos.
Si desea citar este proyecto, use:
@misc{godot-dodo,
author = {Markus Sobkowski},
title = {Godot-Dodo: Finetuned language models for GDScript generation},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/minosvasilias/godot-dodo}},
}
También debe citar el papel de llamas original, así como Stanford-Alpaca.


