godot dodo
1.0.0

O projeto Godot-Dodo apresenta um pipeline para os modelos de linguagem de código aberto FineTune em código específico para linguagem, criado pelo homem, recuperado do GitHub.
Nesse caso, o idioma direcionado é GDScript, mas a mesma metodologia pode ser aplicada a outros idiomas.
Este repositório inclui o seguinte:
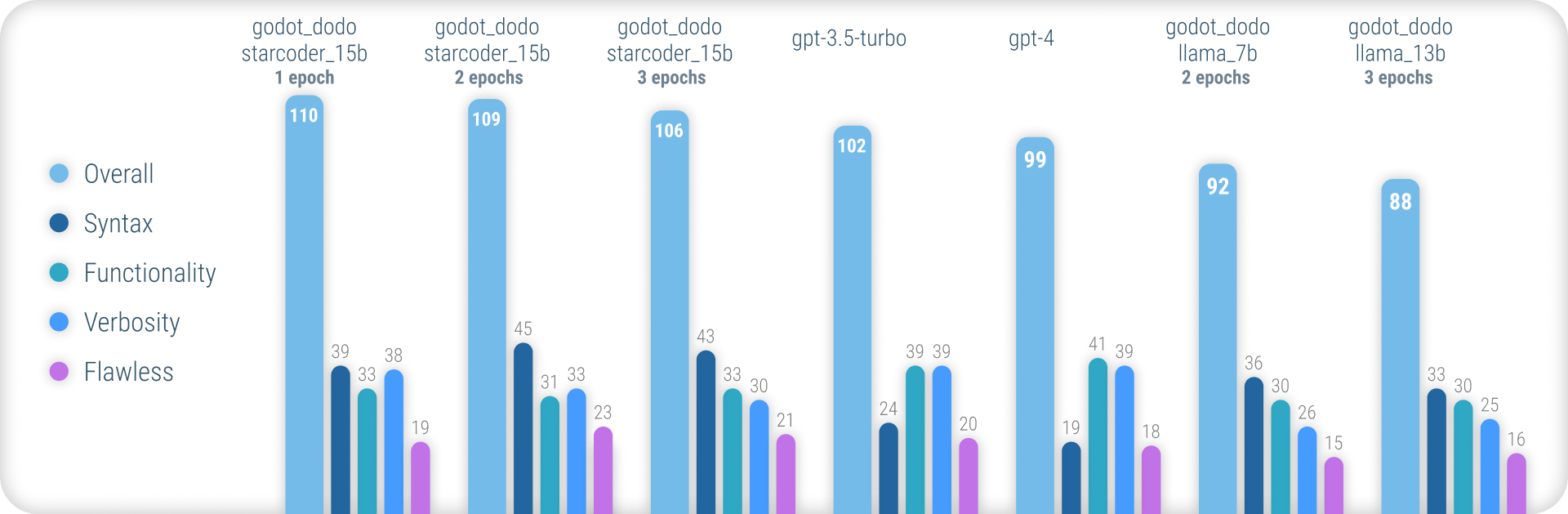
Para obter resultados abrangentes explicando a metodologia usada e uma lista completa de todos os resultados, consulte o relatório de desempenho completo aqui.
Em resumo, os modelos godot_dodo alcançam uma consistência significativamente maior que gpt-4 / gpt-3.5-turbo quando se trata de gerar uma sintaxe GDScript precisa, e as variantes treinadas em modelos de base específicos de código podem até superar as instruções complexas.
O principal ponto fraco restante dessa abordagem é a perda na verbosidade apropriada ao escrever métodos. Como as amostras escritas em humanos geralmente incluem referências a objetos inicializados fora do escopo do método da amostra, o modelo aprende a fazer o mesmo, resultando em casos em que a funcionalidade relevante para a instrução é assumida como já implementada. Provavelmente, isso pode ser melhorado significativamente por um conjunto de dados mais sofisticado.
Ao contrário de outras abordagens semelhantes aos modelos de Finetuning, como Stanford-Alpaca, essa abordagem não usa modelos de linguagem maiores existentes para os valores de saída do finonetuning-Dataset. Todo o código usado é criado pelo homem. Os modelos de idiomas são usados apenas para rotular cada trecho de código.
Como tal, podemos montar comment:code pares de dados no estilo do Codesearchnet, usando modelos poderosos existentes para anotar o código criado pelo homem de alta qualidade.
Alguns modelos de idiomas existentes, como gpt-4 são excelentes codificadores. No entanto, grande parte de sua capacidade está concentrada apenas nos idiomas mais populares, como Python ou JavaScript.
Os idiomas menos usados são sub-representados nos dados de treinamento e experimentam uma queda de desempenho maciça, onde os modelos confundem rotineiramente a sintaxe ou os recursos de linguagem alucinados que não existem.
Isso visa fornecer modelos muito mais robustos específicos de linguagem que podem ser usados para gerar código de forma confiável que compila na primeira tentativa.
Para experimentar os modelos pré-treinados, você pode usar o notebook inferencie_demo.ipynb.
Para usar esse notebook no Google Colab, siga este link.
Devido a essa abordagem, contando com dados criados pelo homem, rasparmos os repositórios do GitHub usando a API de pesquisa do GitHub.
Usando o termo de pesquisa language:gdscript , recuperamos uma lista de repositórios, incluindo o código GDScript.
Também usamos license:mit para limitar o conjunto de dados a repositórios adequados. Somente o código licenciado pelo MIT é usado para treinamento!
Em seguida, clonamos cada um e aplicamos a seguinte lógica:
project.godot3.x ou 4.x GODOT.gd encontrados no repositóriogpt-3.5-turbo ) para um comentário detalhado que descreve o objetivo de funçõesinstruction:response ao conjunto de dados Observe que os comentários existentes e escritos por humanos localizados acima do bloco de código não são usados para o valor instruction . Estamos interessados em detalhes consistentes para comentários, em vez de tentar preservar alguns de qualidade humana potencialmente de alta qualidade.
Os comentários humanos no bloco de código, no entanto, são preservados.
Para montar um conjunto de dados, siga estas instruções:
python data/generate_unlabeled_dataset.pypython data/label_dataset.pyObserve que você precisará de teclas de API GitHub e OpenAI para usar esses scripts.
Conjuntos de dados pré-montados incluídos neste repositório:
4.x Godot Projects - ~ 60k linhas Outros conjuntos de dados podem ser adicionados no futuro (particularmente em relação aos dados 3.x )
O processo de ajuste fino reflete de perto o introduzido por Stanford_alpaca.
Para reproduzir uma versão ajustada da llama, siga as etapas abaixo.
Para efetivamente financiar um modelo llama-7b ou llama-13b , é altamente recomendável usar pelo menos duas GPUs A100 80GB . Caso contrário, você pode encontrar erros fora da memória ou experimentar tempos de treinamento extremamente longos e precisará ajustar os parâmetros de treinamento.
Para finetuning godot_dodo_4x_60k_llama_13b , foram utilizados oito GPUs A100 80GB .
Outra consideração importante é o protocolo usado para a comunicação da GPU. Recomenda -se usar as configurações NVLink em vez do PCIe .
Se você tiver apenas acesso às configurações PCIe , substitua full-shard pelo shard_grad_op no comando torchrun . Isso pode acelerar severamente o seu treinamento com o custo de uso potencialmente mais alto de memória.
Antes da Finetuning, certifique -se de instalar todos os requisitos usando:
pip install -r requirements.txtPara comandos exatos usados para modelos de Finetuning, consulte as páginas modelo individuais:
Para testar seu modelo FinetUned, você pode usar o script eval.py Basta correr:
python finetune/eval.py --model_name_or_path PATH_TO_FINETUNED_MODEL/Para fazer upload facilmente de um modelo FinetUned para Huggingface, você pode usar:
python finetune/push_to_hub.py --model_name_or_path PATH_TO_FINETUNED_MODEL/ --push_name HF_MODEL_NAME --auth_token HF_ACCESS_TOKENOs links para o modelo de pesos hospedados no Huggingface são fornecidos nas respectivas páginas modelo:
Abaixo do custo em dólares de montagem de cada conjunto de dados disponível e fino.
30$ ( gpt-3.5-turbo API Custos)24$ (8X A100 80 GB de custos)84$ (8X A100 80 GB de custos de instância) Uso de modelos FinetUned com GODOT-COPILOT para o editor, a geração totalmente local de código pode ser apoiada no futuro.
Obrigado a todos os projetos de Godot licenciados pelo MIT! Isso não seria possível sem você.
Todos os projetos que foram raspados durante a montagem dos dados do Finetuning incluídos estão listados nas respectivas pastas de dados nos dados.
Outro obrigado a FluidStack.io por suas instâncias de GPU confiáveis e baratas que foram usadas para o Finetuning desses modelos.
Se você deseja citar este projeto, use:
@misc{godot-dodo,
author = {Markus Sobkowski},
title = {Godot-Dodo: Finetuned language models for GDScript generation},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/minosvasilias/godot-dodo}},
}
Você também deve citar o artigo de llama original e Stanford-Alpaca.


