godot dodo
1.0.0

Das Godot-Dodo-Projekt präsentiert eine Pipeline, um Open-Source-Sprachmodelle für vom Menschen geschaffene, sprachspezifische Code aus GitHub zu finanzieren.
In diesem Fall ist die gezielte Sprache GdScript, die gleiche Methodik kann jedoch auf andere Sprachen angewendet werden.
Dieses Repository enthält Folgendes:
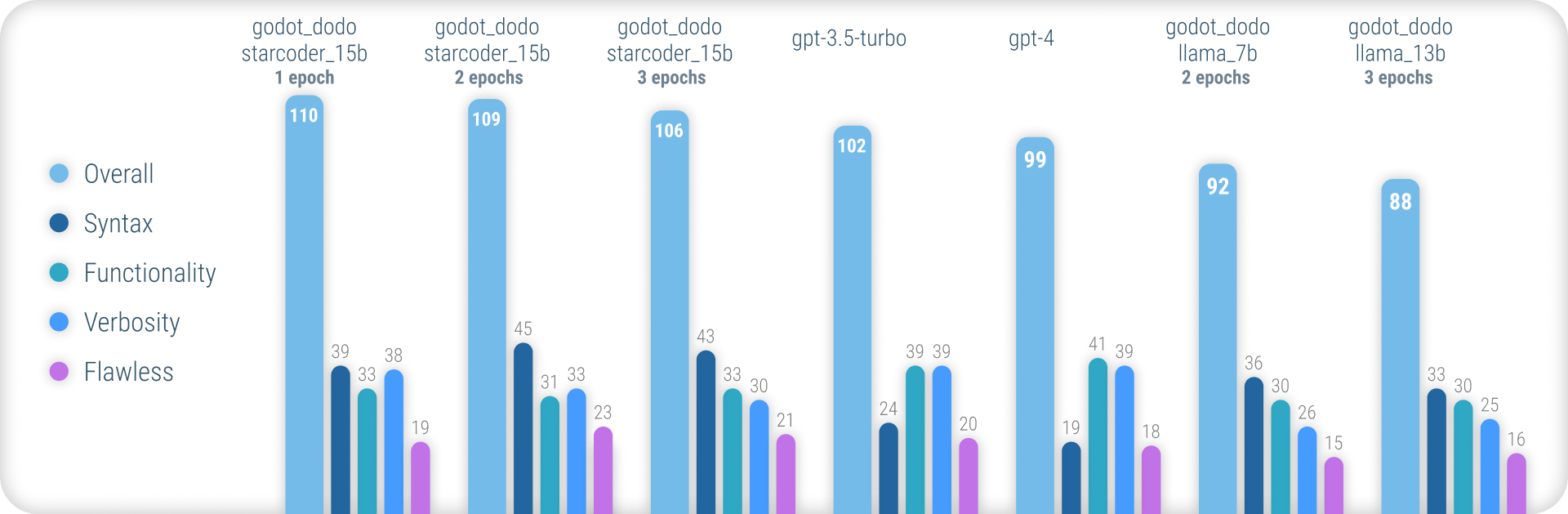
Für umfassende Ergebnisse, die die verwendete Methodik und eine vollständige Liste aller Ergebnisse erläutern, finden Sie hier den vollständigen Leistungsbericht.
Zusammenfassend erreichen godot_dodo -Modelle eine signifikant größere Konsistenz als gpt-4 / gpt-3.5-turbo wenn es darum geht, eine genaue GDS-Syntax zu generieren, und Varianten, die auf codesspezifischen Basismodellen trainiert werden, können sie auf komplexen Anweisungen sogar übertreffen.
Der wesentliche verbleibende Schwachpunkt dieses Ansatzes ist der Verlust an geeigneten Ausführern beim Schreiben von Methoden. Da von Menschen geschriebene Stichproben häufig Verweise auf Objekte enthalten, die außerhalb des Umfangs der Stichprobenmethode initialisiert wurden, lernt das Modell, dasselbe zu tun, was zu Fällen führt, in denen die für die Anweisung relevante Funktionalität bereits implementiert wird. Dies kann höchstwahrscheinlich durch einen ausgefeilteren Datensatz erheblich verbessert werden.
Im Gegensatz zu anderen, ähnlichen Ansätzen bei Figuning-Modellen wie Stanford-Alpaca verwendet dieser Ansatz keine vorhandenen, größeren Sprachmodelle für die Ausgabewerte des Flossendatensatzes. Alle verwendeten Code sind menschlich geschaffen. Sprachmodelle werden stattdessen nur verwendet, um jeden Code -Snippet zu kennzeichnen .
Daher können wir comment:code Codedatenpaare im Stil von CodesarchNet, wobei leistungsstarke Modelle verwendet werden, um qualitativ hochwertige Codes mit Menschen zu kommentieren.
Einige vorhandene Sprachmodelle wie gpt-4 sind ausgezeichnete Codierer. Ein Großteil ihrer Fähigkeiten konzentriert sich jedoch nur in den beliebtesten Sprachen wie Python oder JavaScript.
Weniger weit verbreitete Sprachen sind in den Trainingsdaten unterrepräsentiert und erleben einen massiven Leistungsabfall, bei dem Modelle syntax oder halluzinieren Sprachmerkmale, die nicht existieren, routinemäßig verwechseln.
Dies zielt darauf ab, viel robustere sprachspezifische Modelle zu bieten, mit denen zuverlässig Code generiert werden kann, der beim ersten Versuch kompiliert.
Um die vorgeborenen Modelle auszuprobieren, können Sie das Notebook inference_demo.ipynb verwenden.
Um dieses Notebook in Google Colab zu verwenden, folgen Sie diesem Link.
Aufgrund dieses Ansatzes, der sich auf menschlich geschaffene Daten stützt, kratzen wir mit der Github-Such-API Github-Repositorys ab.
Mithilfe der language:gdscript -Suchbegriff rufen wir eine Liste von Repositorys einschließlich GDSScript -Code ab.
Wir verwenden auch license:mit , um den Datensatz auf geeignete Repositorys zu beschränken. Für das Training wird nur MIT-lizenziertes Code verwendet!
Wir klonen dann jeweils und wenden die folgende Logik an:
project.godot -Datei3.x oder 4.x Godot Engine -Versionen durchgeführt wird.gd -Dateien iterierengpt-3.5-turbo ) nach einem detaillierten Kommentar, in dem der Zweck der Funktionen beschrieben wirdinstruction:response zum Datensatz Beachten Sie, dass vorhandene, von Menschen geschriebene Kommentare über dem Code-Block nicht für den instruction verwendet werden. Wir sind an konsequenten Details für Kommentare interessiert, anstatt zu versuchen, einige potenziell qualitativ hochwertige von Menschen geschriebene zu bewahren.
Menschliche Kommentare innerhalb des Codeblocks bleiben jedoch erhalten.
Um einen Datensatz selbst zusammenzustellen, folgen Sie folgenden Anweisungen:
python data/generate_unlabeled_dataset.pypython data/label_dataset.py ausBitte beachten Sie, dass Sie GitHub- und OpenAI -API -Schlüssel benötigen, um diese Skripte zu verwenden.
In diesem Repository enthaltene Datensätze:
4.x Godot -Projekten - ~ 60k Zeilen Weitere Datensätze können in Zukunft hinzugefügt werden (insbesondere in Bezug auf 3.x -Daten)
Der Feinabstimmungsprozess spiegelt genau den von Stanford_alpaca eingeführten.
Um eine fein abgestimmte Version von Lama zu reproduzieren, befolgen Sie bitte die folgenden Schritte.
Um ein llama-7b oder llama-13b -Modell effektiv zu finanzieren, wird dringend empfohlen, mindestens zwei A100 80GB -GPUs zu verwenden. Sie können sonst aus Speicherfehlern begegnen oder extrem lange Trainingszeiten erleben und müssen die Trainingsparameter anpassen.
Für die Finetuning godot_dodo_4x_60k_llama_13b wurden acht A100 80GB GPUs verwendet.
Eine weitere wichtige Überlegung ist das Protokoll für die GPU -Kommunikation. Es wird empfohlen, NVLink -Setups und nicht PCIe zu verwenden.
Sollten Sie nur Zugriff auf PCIe -Setups haben, ersetzen Sie full-shard durch shard_grad_op im Befehl torchrun . Dies kann Ihre Trainingsläufe auf Kosten für potenziell höhere Speicherverwendung erheblich beschleunigen.
Stellen Sie vor dem Finetuning alle Anforderungen mit: Installieren Sie mit:
pip install -r requirements.txtFür genaue Befehle, die für Finetuning -Modelle verwendet werden, finden Sie auf den einzelnen Modellseiten:
Um Ihr Geldfunkmodell zu testen, können Sie das Skript eval.py verwenden. Einfach rennen:
python finetune/eval.py --model_name_or_path PATH_TO_FINETUNED_MODEL/Um ein finetuniertes Modell auf das UmarmungsFace zu laden, können Sie:
python finetune/push_to_hub.py --model_name_or_path PATH_TO_FINETUNED_MODEL/ --push_name HF_MODEL_NAME --auth_token HF_ACCESS_TOKENAuf den jeweiligen Modellseiten finden Sie Links zu Modellgewichten, die auf Huggingface gehostet werden:
Unterhalb des Dollar-Cost der Zusammenstellung jedes verfügbaren Datensatzes und der Finetuning jedes Modells.
30$ ( gpt-3.5-turbo API-Kosten)24$ (8x A100 80 GB Instanzkosten)84$ (8x A100 80 GB Instanzkosten) Die Verwendung von Finetuned-Modellen mit Godot-Copilot für In-Editor kann in Zukunft eine vollständige lokale Codegenerierung unterstützt werden.
Vielen Dank an alle MIT-lizenzierten Godot-Projekte! Dies wäre ohne Sie nicht möglich.
Alle Projekte, die während der Montage der eingeschlossenen Finetuning -Daten abgekratzt wurden, sind in den jeweiligen Datensatzordnern in Daten aufgeführt.
Ein weiteres Dankeschön geht an fluidstack.io für ihre zuverlässigen, billigen GPU -Instanzen, die für die Fülle dieser Modelle verwendet wurden.
Wenn Sie dieses Projekt zitieren möchten, verwenden Sie bitte:
@misc{godot-dodo,
author = {Markus Sobkowski},
title = {Godot-Dodo: Finetuned language models for GDScript generation},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/minosvasilias/godot-dodo}},
}
Sie sollten auch das ursprüngliche Lama-Papier sowie Stanford-Alpaca zitieren.


