godot dodo
1.0.0

يقدم مشروع Godot-Dodo خط أنابيب إلى نماذج لغة المصدر المفتوح في Finetune على رمز تم إنشاؤه من الإنسان ، والذي تم استرداده من GitHub.
في هذه الحالة ، فإن اللغة المستهدفة هي gdscript ، ولكن يمكن تطبيق نفس المنهجية على لغات أخرى.
يتضمن هذا المستودع ما يلي:
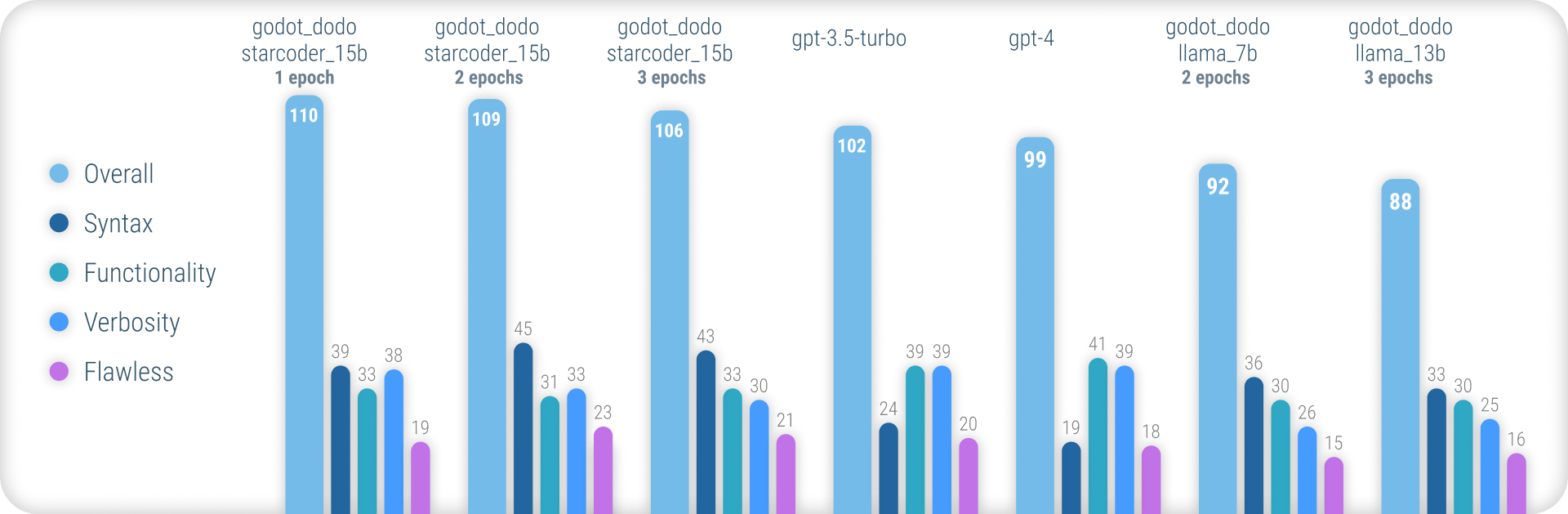
للحصول على نتائج شاملة في شرح المنهجية المستخدمة وقائمة كاملة لجميع النتائج ، يرجى الرجوع إلى تقرير الأداء الكامل هنا.
باختصار ، تحقق نماذج godot_dodo تناسقًا أكبر بكثير من gpt-4 / gpt-3.5-turbo عندما يتعلق الأمر بإنشاء بناء جملة GDSCRIP دقيقة ، ويمكن أن تتفوق المتغيرات التي تم تدريبها على نموذجات قاعدة خاصة بالشفرة على تعليمات معقدة.
نقطة الضعف الرئيسية المتبقية في هذا النهج هي الخسارة في الفعل المناسب عند كتابة أساليب. نظرًا لأن العينات المكتوبة بالبشر غالبًا ما تتضمن إشارات إلى الكائنات التي تمت تهيئتها خارج نطاق طريقة العينة ، يتعلم النموذج أن يفعل الشيء نفسه ، مما يؤدي إلى الحالات التي يُفترض فيها تنفيذ الوظائف ذات الصلة بالتعليمات بالفعل. من المرجح أن يتم تحسين هذا بشكل كبير من خلال مجموعة بيانات أكثر تطوراً.
على عكس الأساليب الأخرى المماثلة في النماذج اللاصقة مثل Stanford-ALPACA ، لا يستخدم هذا النهج نماذج لغوية أكبر وأكبر لقيمة الإخراج الخاصة بالمساحة المحلية. كل الكود المستخدمة هو إنشاء الإنسان. يتم استخدام نماذج اللغة بدلاً من ذلك فقط لتسمية كل مقتطف رمز.
على هذا النحو ، يمكننا تجميع comment:code بيانات بيانات في نمط CodeSearchNet ، والاستفادة من النماذج القوية الحالية لتوضيح التعليمات البرمجية عالية الجودة التي تم إنشاؤها.
بعض نماذج اللغة الحالية مثل gpt-4 هي المبرمجون الممتازون. ومع ذلك ، يتركز الكثير من قدرتهم على اللغات الأكثر شعبية فقط ، مثل Python أو JavaScript.
تم تمثيل اللغات الأقل استخدامًا على نطاق واسع في بيانات التدريب وتجربة انخفاض أداء هائل ، حيث تخطئ النماذج بشكل روتيني في بناء الجملة أو ميزات لغة الهلوسة غير موجودة.
يهدف هذا إلى توفير نماذج أكثر قوة لغوية يمكن استخدامها لإنشاء التعليمات البرمجية التي تجمعها في المحاولة الأولى.
لتجربة النماذج التي تم تدريبها مسبقًا ، يمكنك استخدام دفتر الملاحظات interference_demo.ipynb.
من أجل استخدام هذا الكمبيوتر الدفتري على Google Colab ، اتبع هذا الرابط.
نظرًا لهذا النهج ، بالاعتماد على البيانات التي تم إنشاؤها من قبل الإنسان ، نستكشف مستودعات GitHub باستخدام واجهة برمجة تطبيقات Search Github.
باستخدام language:gdscript ، نقوم باسترداد قائمة من المستودعات بما في ذلك رمز GDSCRIPT.
نستخدم أيضًا license:mit للحد من مجموعة البيانات على المستودعات المناسبة. يتم استخدام رمز مرخص فقط معهد ماساتشوستس للتكنولوجيا للتدريب!
ثم نستنسخ كل واحد ونطبق المنطق التالي:
project.godot3.x أو 4.x.gd الموجودة في المستودعgpt-3.5-turbo ) للحصول على تعليق مفصل يصف الغرض من الوظائفinstruction:response إلى مجموعة البيانات لاحظ أن التعليقات الحالية المكتوبة على الإنسان الموجودة فوق كتلة الكود لا تستخدم لقيمة instruction . نحن مهتمون بالتفاصيل المتسقة للتعليقات ، بدلاً من محاولة الحفاظ على بعض الجودة العالية التي اكتسبتها الإنسان.
ومع ذلك ، يتم الحفاظ على التعليقات البشرية داخل كتلة الكود.
لتجميع مجموعة بيانات بنفسك ، اتبع هذه التعليمات:
python data/generate_unlabeled_dataset.pypython data/label_dataset.pyيرجى ملاحظة أنك ستحتاج إلى مفاتيح GitHub و Openai API من أجل استخدام هذه البرامج النصية.
مجموعات بيانات مجمعة مسبقًا مدرجة في هذا المستودع:
4.x - ~ 60K صفوف يمكن إضافة مجموعات بيانات أخرى في المستقبل (خاصة فيما يتعلق ببيانات 3.x )
تعكس عملية الضبط بشكل وثيق تلك التي قدمتها Stanford_Alpaca.
لإعادة إنتاج نسخة معدلة من Llama ، يرجى اتباع الخطوات أدناه.
من أجل FineTune A llama-7b أو llama-13b بشكل فعال ، يوصى بشدة باستخدام وحدات معالجة الرسومات A100 80GB على الأقل. قد تواجه خلاف ذلك عن أخطاء الذاكرة أو تجربة أوقات تدريب طويلة للغاية ، وستحتاج إلى ضبط معلمات التدريب.
من أجل finetuning godot_dodo_4x_60k_llama_13b ، تم استخدام ثمانية A100 80GB وحدات معالجة الرسومات.
اعتبار مهم آخر هو البروتوكول المستخدم لاتصالات GPU. يوصى باستخدام إعدادات NVLink بدلاً من PCIe .
إذا كان لديك فقط الوصول إلى إعدادات PCIe ، يرجى استبدال full-shard مع shard_grad_op في أمر torchrun . قد يؤدي هذا إلى تسريع تدريبك بشدة على حساب استخدام الذاكرة المرتفعة.
قبل Finetuning ، تأكد من تثبيت جميع المتطلبات باستخدام:
pip install -r requirements.txtللأوامر الدقيقة المستخدمة في نماذج Finetuning ، يرجى الرجوع إلى صفحات النموذج الفردية:
لاختبار النموذج الخاص بك ، يمكنك استخدام البرنامج النصي eval.py ببساطة الجري:
python finetune/eval.py --model_name_or_path PATH_TO_FINETUNED_MODEL/لتحميل طراز Finituned بسهولة إلى Luggingface ، يمكنك استخدام:
python finetune/push_to_hub.py --model_name_or_path PATH_TO_FINETUNED_MODEL/ --push_name HF_MODEL_NAME --auth_token HF_ACCESS_TOKENيتم توفير روابط للأوزان النموذجية المستضاف في Luggingface في صفحات النموذج المعنية:
تحت التكلفة بالدولار لتجميع كل مجموعة بيانات متوفرة وعلاج كل نموذج.
30$ (تكاليف واجهة gpt-3.5-turbo )24$ (8x A100 80 جيجابايت تكاليف مثيل)84$ (8x A100 80 جيجابايت تكاليف مثيل) استخدام النماذج المحفوظة بالحيوية مع Godot-Copilot للمحرر ، قد يتم دعم توليد الكود المحلي بالكامل في المستقبل.
شكرا لجميع مشاريع Godot المرخصة معهد ماساتشوستس للتكنولوجيا! هذا لن يكون ممكنا بدونك.
يتم سرد جميع المشاريع التي تم تجاهلها أثناء تجميع البيانات الموروثة في مجلدات مجموعة البيانات المعنية في البيانات.
شكر آخر أنت يذهب إلى FluidStack.io على مثيلات GPU الموثوقة والرخيصة التي تم استخدامها في هذه النماذج.
إذا كنت ترغب في الاستشهاد بهذا المشروع ، فيرجى استخدام:
@misc{godot-dodo,
author = {Markus Sobkowski},
title = {Godot-Dodo: Finetuned language models for GDScript generation},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/minosvasilias/godot-dodo}},
}
يجب عليك أيضًا الاستشهاد بورقة Llama الأصلية وكذلك Stanford-Alpaca.


