godot dodo
1.0.0

โครงการ Godot-Dodo นำเสนอไปป์ไลน์ไปยังแบบจำลองภาษาโอเพ่นซอร์ส Finetune บนรหัสที่สร้างขึ้นโดยมนุษย์และเฉพาะภาษาที่ดึงมาจาก GitHub
ในกรณีนี้ภาษาเป้าหมายคือ GDScript แต่วิธีการเดียวกันสามารถนำไปใช้กับภาษาอื่นได้
ที่เก็บนี้รวมถึงสิ่งต่อไปนี้:
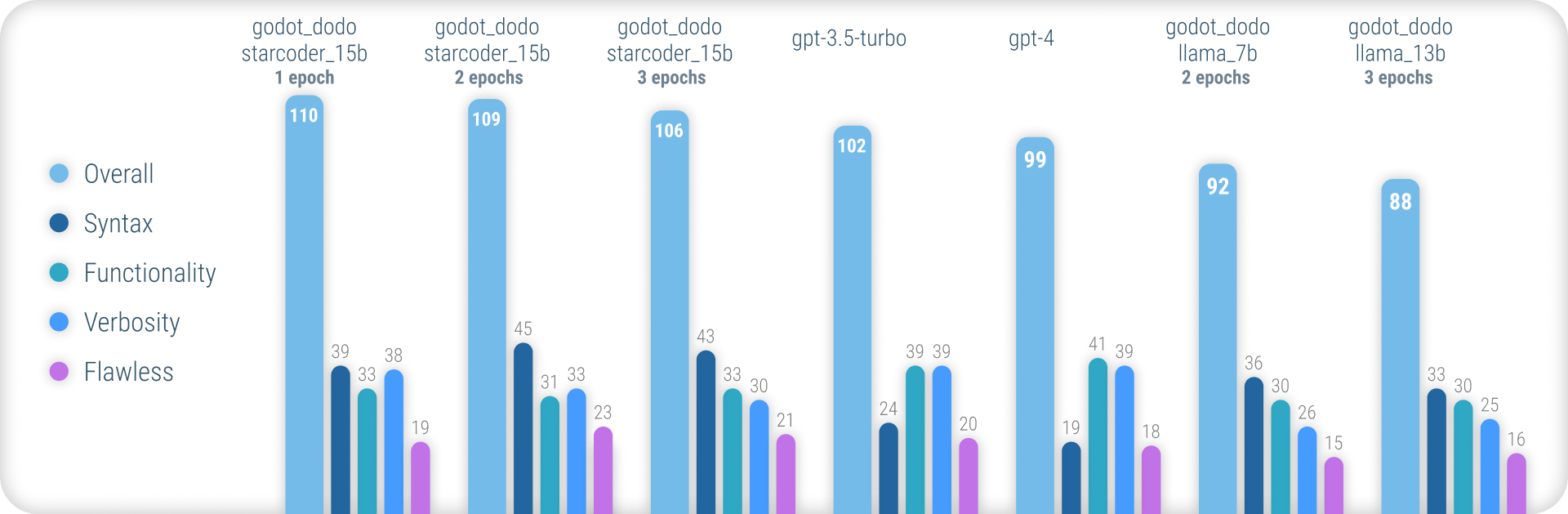
สำหรับผลลัพธ์ที่ครอบคลุมการอธิบายวิธีการที่ใช้และรายการทั้งหมดของผลลัพธ์ทั้งหมดโปรดดูรายงานประสิทธิภาพเต็มรูปแบบที่นี่
โดยสรุปโมเดล godot_dodo บรรลุความสอดคล้องที่ดีกว่า gpt-4 / gpt-3.5-turbo อย่างมีนัยสำคัญเมื่อมันมาถึงการสร้างไวยากรณ์ GDScript ที่แม่นยำและตัวแปรที่ผ่านการฝึกอบรมเกี่ยวกับโมเดลพื้นฐานเฉพาะโค้ดสามารถทำได้ดีกว่าคำสั่งที่ซับซ้อน
จุดอ่อนที่เหลืออยู่ของวิธีการนี้คือการสูญเสียการใช้คำฟุ่มเฟือยที่เหมาะสมเมื่อเขียนวิธีการ เนื่องจากตัวอย่างที่เขียนโดยมนุษย์มักจะรวมถึงการอ้างอิงถึงวัตถุที่เริ่มต้นนอกขอบเขตของวิธีการตัวอย่างแบบจำลองจึงเรียนรู้ที่จะทำเช่นเดียวกันทำให้เกิดกรณีที่การทำงานที่เกี่ยวข้องกับคำสั่งจะถูกนำไปใช้แล้ว สิ่งนี้น่าจะได้รับการปรับปรุงอย่างมีนัยสำคัญโดยชุดข้อมูลที่ซับซ้อนยิ่งขึ้น
ซึ่งแตกต่างจากวิธีการอื่น ๆ ที่คล้ายกันในการสร้างโมเดล finetuning เช่น Stanford-Alpaca วิธีการนี้ไม่ได้ใช้แบบจำลองภาษาที่มีอยู่ขนาดใหญ่สำหรับค่าเอาท์พุทของค่า Finetuning-Dataset รหัสทั้งหมดที่ใช้เป็นมนุษย์ที่สร้างขึ้น แบบจำลองภาษาใช้แทน การติดฉลาก แต่ละโค้ด
ดังนั้นเราสามารถรวบรวม comment:code ในรูปแบบของ CodeSearchNet ใช้ประโยชน์จากโมเดลที่มีประสิทธิภาพที่มีอยู่เพื่อใส่รหัสที่สร้างขึ้นด้วยมนุษย์คุณภาพสูง
รูปแบบภาษาที่มีอยู่บางรุ่นเช่น gpt-4 เป็นโค้ดที่ยอดเยี่ยม อย่างไรก็ตามความสามารถของพวกเขาจำนวนมากนั้นมีความเข้มข้นในภาษาที่ได้รับความนิยมมากที่สุดเช่น Python หรือ JavaScript
ภาษาที่ใช้กันอย่างแพร่หลายน้อยกว่านั้นมีบทบาทในการฝึกอบรมและสัมผัสกับการลดลงของประสิทธิภาพที่ยิ่งใหญ่ซึ่งรูปแบบไวยากรณ์ผิดพลาดเป็นประจำหรือคุณสมบัติภาษาภาพหลอนที่ไม่มีอยู่
สิ่งนี้มีจุดมุ่งหมายเพื่อให้โมเดลเฉพาะภาษาที่มีประสิทธิภาพมากขึ้นซึ่งสามารถใช้ในการสร้างรหัสที่รวบรวมได้อย่างน่าเชื่อถือในการลองครั้งแรก
หากต้องการลองใช้โมเดลที่ผ่านการฝึกอบรมมาก่อนคุณสามารถใช้สมุดบันทึกการอนุมาน _demo.ipynb
ในการใช้สมุดบันทึกนั้นบน Google Colab ให้ไปที่ลิงค์นี้
เนื่องจากวิธีการนี้อาศัยข้อมูลที่สร้างขึ้นของมนุษย์เราจึงขูดที่เก็บ GitHub โดยใช้ GitHub Search API
การใช้ language:gdscript เราดึงรายการที่เก็บรวมถึงรหัส GDScript
นอกจากนี้เรายังใช้ license:mit เพื่อ จำกัด ชุดข้อมูลให้เป็นที่เก็บที่เหมาะสม ใช้รหัสเฉพาะ MIT เท่านั้นที่ใช้สำหรับการฝึกอบรม!
จากนั้นเราโคลนแต่ละคนและใช้ตรรกะต่อไปนี้:
project.godot3.x หรือ 4.x Godot.gd ทั้งหมดที่พบในที่เก็บข้อมูลgpt-3.5-turbo ) สำหรับความคิดเห็นโดยละเอียดที่อธิบายวัตถุประสงค์ฟังก์ชันinstruction:response ไปยังชุดข้อมูล โปรดทราบว่าความคิดเห็นที่มีอยู่และเขียนที่อยู่เหนือบล็อกบล็อกไม่ได้ใช้สำหรับค่า instruction เรามีความสนใจในรายละเอียดที่สอดคล้องกันสำหรับความคิดเห็นแทนที่จะพยายามรักษาคนที่มีคุณภาพสูงกว่าที่เขียนไว้
ความคิดเห็นของมนุษย์ภายในบล็อกรหัสอย่างไรก็ตามจะได้รับการเก็บรักษาไว้
ในการรวบรวมชุดข้อมูลด้วยตัวเองทำตามคำแนะนำเหล่านี้:
python data/generate_unlabeled_dataset.pypython data/label_dataset.pyโปรดทราบว่าคุณจะต้องใช้คีย์ GitHub และ OpenAI API เพื่อใช้สคริปต์เหล่านี้
ชุดข้อมูลที่ประกอบไว้ล่วงหน้ารวมอยู่ในที่เก็บนี้:
4.x Godot - ~ 60k แถว อาจมีการเพิ่มชุดข้อมูลเพิ่มเติมในอนาคต (โดยเฉพาะอย่างยิ่งเกี่ยวกับข้อมูล 3.x )
กระบวนการปรับแต่งอย่างใกล้ชิดสะท้อนให้เห็นถึงการแนะนำโดย Stanford_Alpaca
หากต้องการทำซ้ำ Llama รุ่นที่ปรับแต่งได้โปรดทำตามขั้นตอนด้านล่าง
เพื่อให้รุ่น llama-7b หรือ llama-13b ได้อย่างมีประสิทธิภาพขอแนะนำให้ใช้ GPU A100 80GB อย่างน้อยสองตัว คุณอาจพบกับข้อผิดพลาดของหน่วยความจำหรือประสบการณ์การฝึกอบรมที่ยาวนานมากและจะต้องปรับพารามิเตอร์การฝึกอบรม
สำหรับ finetuning godot_dodo_4x_60k_llama_13b ใช้ GPU A100 80GB แปดตัว
การพิจารณาที่สำคัญอีกประการหนึ่งคือโปรโตคอลที่ใช้สำหรับการสื่อสาร GPU ขอแนะนำให้ใช้การตั้งค่า NVLink มากกว่า PCIe
shard_grad_op คุณสามารถเข้าถึงการตั้งค่า PCIe ได้โปรดแทนที่ full-shard ในคำสั่ง torchrun สิ่งนี้อาจเพิ่มความเร็วในการฝึกอบรมของคุณอย่างรุนแรงด้วยค่าใช้จ่ายในการใช้หน่วยความจำที่สูงขึ้น
ก่อนที่จะ finetuning ตรวจสอบให้แน่ใจว่าได้ติดตั้งข้อกำหนดทั้งหมดโดยใช้:
pip install -r requirements.txtสำหรับคำสั่งที่แน่นอนที่ใช้สำหรับโมเดล finetuning โปรดดูหน้าโมเดลแต่ละหน้า:
ในการทดสอบโมเดล finetuned ของคุณคุณสามารถใช้สคริปต์ eval.py เพียงแค่วิ่ง:
python finetune/eval.py --model_name_or_path PATH_TO_FINETUNED_MODEL/หากต้องการอัปโหลดโมเดล finetuned ไปยัง HuggingFace ได้อย่างง่ายดายคุณสามารถใช้:
python finetune/push_to_hub.py --model_name_or_path PATH_TO_FINETUNED_MODEL/ --push_name HF_MODEL_NAME --auth_token HF_ACCESS_TOKENลิงก์ไปยังแบบจำลองน้ำหนักที่โฮสต์บน HuggingFace มีให้ในหน้ารุ่นที่เกี่ยวข้อง:
ด้านล่างค่าเงินดอลลาร์ของการประกอบชุดข้อมูลที่มีอยู่แต่ละชุดและ finetuning แต่ละรุ่น
30$ ( gpt-3.5-turbo API ค่าใช้จ่าย)24$ (ค่าใช้จ่ายอินสแตนซ์ 8x A100 80GB)84$ (ค่าใช้จ่ายอินสแตนซ์ 8x A100 80GB) การใช้แบบจำลอง finetuned กับ Godot-Copilot สำหรับผู้แก้ไขในการสร้างรหัสท้องถิ่นอย่างเต็มที่อาจได้รับการสนับสนุนในอนาคต
ขอบคุณโครงการ Godot ที่ได้รับอนุญาตจาก MIT! สิ่งนี้จะเป็นไปไม่ได้หากไม่มีคุณ
โครงการทั้งหมดที่ถูกคัดลอกในระหว่างการประกอบข้อมูล finetuning ที่รวมอยู่จะแสดงอยู่ในโฟลเดอร์ชุดข้อมูลที่เกี่ยวข้องในข้อมูล
ขอขอบคุณอีกครั้งไปที่ fluidstack.io สำหรับอินสแตนซ์ GPU ราคาถูกที่เชื่อถือได้ซึ่งใช้สำหรับการปรับรุ่นเหล่านี้
หากคุณต้องการอ้างถึงโครงการนี้โปรดใช้:
@misc{godot-dodo,
author = {Markus Sobkowski},
title = {Godot-Dodo: Finetuned language models for GDScript generation},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/minosvasilias/godot-dodo}},
}
คุณควรอ้างถึงกระดาษ Llama ต้นฉบับเช่นเดียวกับ Stanford-Alpaca


