godot dodo
1.0.0

Proyek Godot-Dodo menyajikan saluran pipa untuk Finetune Model Bahasa Sumber Terbuka pada kode yang diciptakan manusia dan spesifik bahasa yang diambil dari GitHub.
Dalam hal ini, bahasa yang ditargetkan adalah GDScript, tetapi metodologi yang sama dapat diterapkan pada bahasa lain.
Repositori ini mencakup yang berikut:
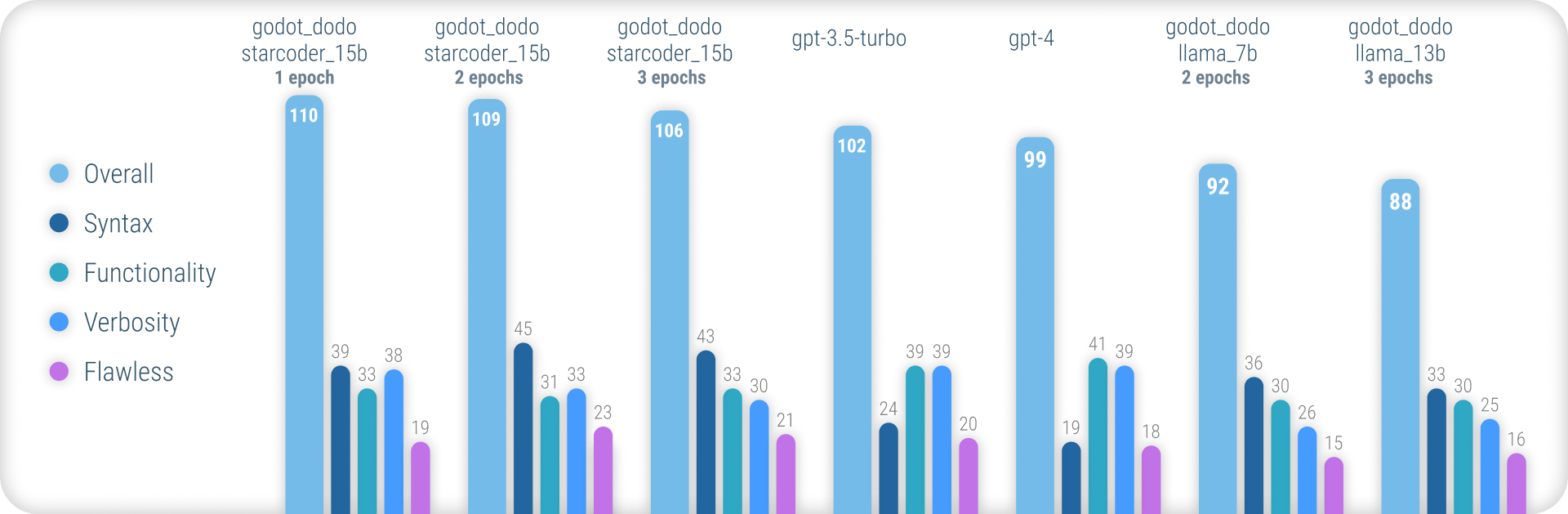
Untuk hasil komprehensif yang menjelaskan metodologi yang digunakan dan daftar lengkap semua hasil, silakan merujuk ke laporan kinerja lengkap di sini.
Singkatnya, model godot_dodo mencapai konsistensi yang jauh lebih besar daripada gpt-4 / gpt-3.5-turbo ketika datang untuk menghasilkan sintaks GDScript yang akurat, dan varian yang dilatih pada model dasar-dasar-kode bahkan dapat mengungguli mereka pada instruksi yang kompleks.
Titik lemah utama yang tersisa dari pendekatan ini adalah kerugian dalam verbositas yang tepat saat menulis metode. Karena sampel yang ditulis manusia akan sering memasukkan referensi ke objek yang diinisialisasi di luar ruang lingkup metode sampel, model belajar untuk melakukan hal yang sama, menghasilkan kasus di mana fungsionalitas yang relevan dengan instruksi diasumsikan sudah diimplementasikan. Ini kemungkinan besar dapat ditingkatkan secara signifikan dengan dataset yang lebih canggih.
Tidak seperti yang lain, pendekatan serupa untuk model finetuning seperti Stanford-Alpaca, pendekatan ini tidak menggunakan model bahasa yang ada dan lebih besar untuk nilai output-finetuning-dataset. Semua kode yang digunakan dibuat manusia. Model bahasa sebaliknya hanya digunakan untuk memberi label pada setiap cuplikan kode.
Dengan demikian, kami dapat merakit comment:code -pasangan kode dalam gaya CodesearchNet, memanfaatkan model yang ada yang kuat untuk membubuhi nama kode yang dibuat manusia berkualitas tinggi.
Beberapa model bahasa yang ada seperti gpt-4 adalah pembuat kode yang sangat baik. Namun, banyak kemampuan mereka terkonsentrasi hanya dalam bahasa yang paling populer, seperti Python atau JavaScript.
Bahasa yang kurang banyak digunakan kurang terwakili dalam data pelatihan dan mengalami penurunan kinerja besar-besaran, di mana model secara rutin salah sintaks atau fitur bahasa halusinasi yang tidak ada.
Ini bertujuan untuk menyediakan model spesifik bahasa yang jauh lebih kuat yang dapat digunakan untuk menghasilkan kode yang dikompilasi pada percobaan pertama.
Untuk mencoba model pra-terlatih, Anda dapat menggunakan notebook inference_demo.ipynb.
Untuk menggunakan buku catatan itu di Google Colab, ikuti tautan ini.
Karena pendekatan ini mengandalkan data yang dibuat manusia, kami mengikis repositori GitHub menggunakan API pencarian GitHub.
Menggunakan language:gdscript , kami mengambil daftar repositori termasuk kode gdscript.
Kami juga menggunakan license:mit untuk membatasi dataset ke repositori yang sesuai. Hanya kode berlisensi MIT yang digunakan untuk pelatihan!
Kami kemudian mengkloning masing -masing dan menerapkan logika berikut:
project.godot3.x atau 4.x Godot.gd yang ditemukan di repositorigpt-3.5-turbo ) untuk komentar terperinci yang menggambarkan tujuan fungsiinstruction:response ke Dataset Perhatikan bahwa komentar yang ada dan ditulis manusia yang terletak di atas blok kode tidak digunakan untuk nilai instruction . Kami tertarik pada detail yang konsisten untuk komentar, daripada mencoba melestarikan beberapa yang berkualitas lebih tinggi.
Namun komentar manusia dalam blok kode dipertahankan.
Untuk merakit dataset sendiri, ikuti instruksi ini:
python data/generate_unlabeled_dataset.pypython data/label_dataset.pyHarap perhatikan bahwa Anda membutuhkan kunci API GitHub dan OpenAI untuk menggunakan skrip ini.
Dataset pra-rakitan termasuk dalam repositori ini:
4.x Proyek Godot - ~ 60K Baris Dataset lebih lanjut dapat ditambahkan di masa mendatang (terutama mengenai data 3.x )
Proses fine-tuning mencerminkan erat yang diperkenalkan oleh Stanford_alpaca.
Untuk mereproduksi versi Llama yang disesuaikan, silakan ikuti langkah-langkah di bawah ini.
Untuk secara efektif finetune model llama-7b atau llama-13b , sangat disarankan untuk menggunakan setidaknya dua GPU A100 80GB . Anda mungkin menghadapi kesalahan memori atau mengalami waktu pelatihan yang sangat lama, dan perlu menyesuaikan parameter pelatihan.
Untuk finetuning godot_dodo_4x_60k_llama_13b , delapan A100 80GB GPU digunakan.
Pertimbangan penting lainnya adalah protokol yang digunakan untuk komunikasi GPU. Disarankan untuk menggunakan pengaturan NVLink daripada PCIe .
Jika Anda hanya memiliki akses ke pengaturan PCIe , harap ganti full-shard dengan shard_grad_op di perintah torchrun . Ini dapat mempercepat pelatihan Anda dengan biaya penggunaan memori yang berpotensi lebih tinggi.
Sebelum finetuning, pastikan untuk menginstal semua persyaratan menggunakan:
pip install -r requirements.txtUntuk perintah yang tepat yang digunakan untuk model finetuning, silakan merujuk ke setiap halaman model:
Untuk menguji model finetuned Anda, Anda dapat menggunakan skrip eval.py Cukup jalankan:
python finetune/eval.py --model_name_or_path PATH_TO_FINETUNED_MODEL/Untuk dengan mudah mengunggah model finetuned ke Huggingface, Anda dapat menggunakan:
python finetune/push_to_hub.py --model_name_or_path PATH_TO_FINETUNED_MODEL/ --push_name HF_MODEL_NAME --auth_token HF_ACCESS_TOKENTautan ke Model Bobot yang Di -host di Huggingface disediakan di masing -masing halaman model:
Di bawah biaya dolar dari merakit setiap dataset yang tersedia dan finetuning setiap model.
30$ ( gpt-3.5-turbo API Biaya)24$ (8x A100 80GB Biaya Instance)84$ (8x A100 80GB Biaya Instance) Penggunaan model finetuned dengan godot-copilot untuk editor, generasi kode lokal sepenuhnya dapat didukung di masa depan.
Terima kasih untuk semua proyek Godot berlisensi mit! Ini tidak akan mungkin tanpamu.
Semua proyek yang dikikis selama perakitan data finetuning yang disertakan tercantum dalam masing -masing folder dataset dalam data.
Terima kasih lainnya yang diberikan kepada FluidStack.io untuk instance GPU mereka yang andal dan murah yang digunakan untuk melakukan finetuning model -model ini.
Jika Anda ingin mengutip proyek ini, silakan gunakan:
@misc{godot-dodo,
author = {Markus Sobkowski},
title = {Godot-Dodo: Finetuned language models for GDScript generation},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/minosvasilias/godot-dodo}},
}
Anda juga harus mengutip kertas Llama asli serta Stanford-Alpaca.


