godot dodo
1.0.0

Проект Годо-Додо представляет собой конвейер для моделей с открытым исходным кодом на разработанном человеке, языковом коде, извлеченном из GitHub.
В этом случае целевым языком является GDSICT, но та же методология может быть применена к другим языкам.
Этот репозиторий включает в себя следующее:
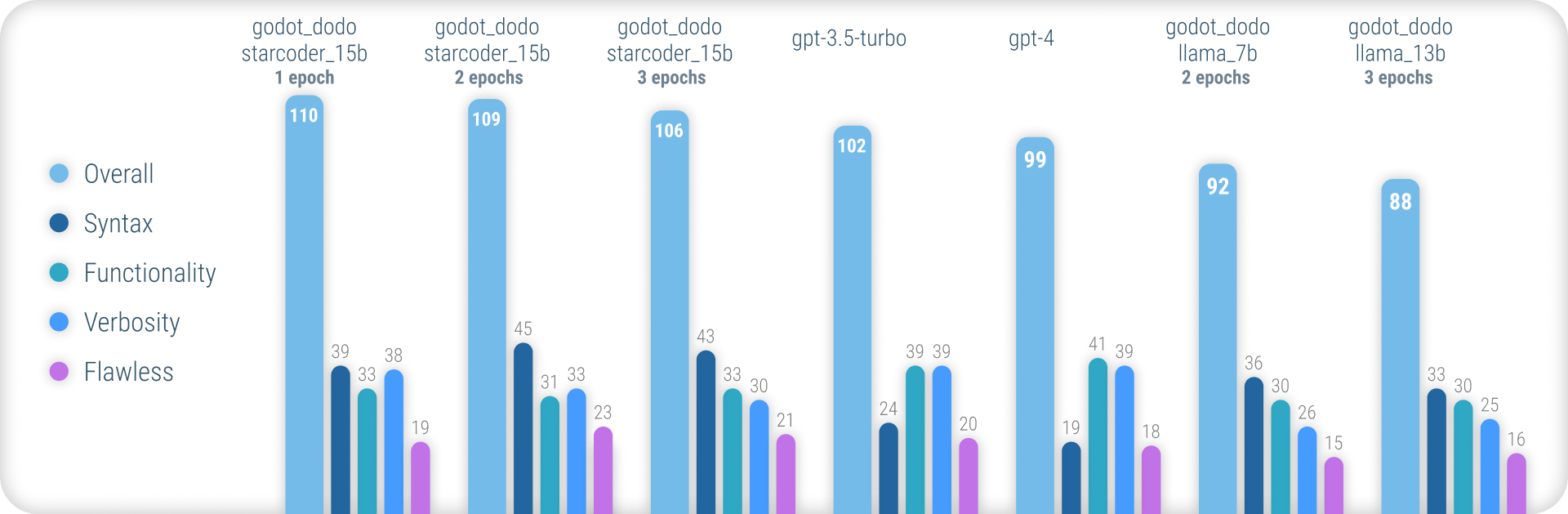
Для получения комплексных результатов, объясняющих используемую методологию, и полный список всех результатов, пожалуйста, обратитесь к полному отчету о производительности здесь.
Таким образом, модели godot_dodo достигают значительно большей согласованности, чем gpt-4 / gpt-3.5-turbo когда речь идет о создании точного синтаксиса GDSCRIPT, и варианты, обученные на основе кода, могут даже превосходить их по сложным инструкциям.
Основным оставшимся слабым пунктом этого подхода является потеря соответствующей условности при написании методов. Поскольку образцы, написанные человеком, часто включают ссылки на объекты, инициализированные вне объема метода выборки, модель учится делать то же самое, что приводит к случаям, когда предполагается, что функция, относящаяся к инструкции, уже реализована. Скорее всего, это можно значительно улучшить с помощью более сложного набора данных.
В отличие от других, аналогичные подходы к созданию моделей создания, таких как Стэнфорд-Альпака, в этом подходе не используется существующие, более крупные языковые модели для выходных значений Manetuning-Dataset. Весь используемый код создан человеком. Языковые модели вместо этого используются только для маркировки каждого фрагмента кода.
Таким образом, мы можем собрать comment:code данные в стиле CodeSearchnet, используя мощные существующие модели для аннотирования высококачественного кода, созданного человеком.
Некоторые существующие языковые модели, такие как gpt-4 являются отличными кодерами. Тем не менее, большая часть их способности сосредоточена только на самых популярных языках, таких как Python или JavaScript.
Менее широко используемые языки недопредставлены в учебных данных и испытывают массовое снижение производительности, где модели регулярно ошибаются синтаксисом или функциями галлюцинатного языка, которые не существуют.
Это направлено на то, чтобы предоставить гораздо более надежные модели, специфичные для языка, которые можно использовать для надежного генерирования кода, который компилируется с первой попытки.
Чтобы попробовать предварительно обученные модели, вы можете использовать ноутбук ounference_demo.ipynb.
Чтобы использовать эту записную книжку в Google Colab, перейдите по этой ссылке.
Благодаря этому подходу полагается на созданные человеческие данные, мы царапаем репозитории GitHub, используя API поиска GitHub.
Используя language:gdscript поисковый термин, мы получаем список репозиториев, включая код GDSCRIPT.
Мы также используем license:mit для ограничения набора данных до подходящих репозиториев. Для обучения используется только лицензированный код MIT!
Затем мы клонируем каждый и применяем следующую логику:
project.godot3.x или 4.x Godot.gd , найденные в репозиторииgpt-3.5-turbo ) для подробного комментария, описывающего цель функцийinstruction:response в набор данных Обратите внимание, что существующие, написанные человеком комментарии, расположенные над блоком кода, не используются для значения instruction . Мы заинтересованы в последовательных деталях для комментариев, вместо того, чтобы пытаться сохранить некоторые потенциально более качественные человеческие, написанные человеком.
Человеческие комментарии в кодовом блоке, однако, сохраняются.
Чтобы собрать набор данных самостоятельно, следуйте этим инструкциям:
python data/generate_unlabeled_dataset.pypython data/label_dataset.pyПожалуйста, обратите внимание, что вам понадобятся клавиши GitHub и OpenAI API, чтобы использовать эти сценарии.
Предварительно собранные наборы данных включены в этот репозиторий:
4.x Годо Дальнейшие наборы данных могут быть добавлены в будущем (особенно в отношении данных 3.x )
Процесс тонкой настройки внимательно отражает тот, который представлен Stanford_alpaca.
Чтобы воспроизвести тонкую версию Llama, пожалуйста, выполните шаги ниже.
Чтобы эффективно определить модель llama-7b или llama-13b , настоятельно рекомендуется использовать как минимум два графических процессора A100 80GB . В противном случае вы можете столкнуться с ошибками памяти или испытать чрезвычайно длительное время обучения, и вам нужно будет настроить параметры обучения.
Для создания godot_dodo_4x_60k_llama_13b использовались восемь A100 80GB GPU.
Другим важным соображением является протокол, используемый для общения с графическим процессором. Рекомендуется использовать настройки NVLink , а не PCIe .
Если у вас есть только доступ к настройкам PCIe , замените full-shard на shard_grad_op в команде torchrun . Это может серьезно ускорить ваши тренировочные прогоны за счет потенциально более высокого использования памяти.
Перед созданием, обязательно установите все требования, используя:
pip install -r requirements.txtДля точных команд, используемых для моделей создания, пожалуйста, обратитесь к отдельным страницам модели:
Чтобы проверить свою современную модель, вы можете использовать сценарий eval.py Просто беги:
python finetune/eval.py --model_name_or_path PATH_TO_FINETUNED_MODEL/Чтобы легко загрузить современную модель в HuggingFace, вы можете использовать:
python finetune/push_to_hub.py --model_name_or_path PATH_TO_FINETUNED_MODEL/ --push_name HF_MODEL_NAME --auth_token HF_ACCESS_TOKENСсылки на веса модели, размещенные на Huggingface, представлены на соответствующих страницах моделей:
Ниже затрат в долларах сборки каждого доступного набора данных и создания каждой модели.
30$ ( gpt-3.5-turbo API затрат)24$ (8x A100 80 ГБ затраты)84$ (8x A100 80 ГБ затраты) Использование современных моделей с Годо-Копилотом для Editor, полностью локальная генерация кода может быть поддержана в будущем.
Спасибо всем MIT-лицензированным проектам Годо! Это было бы невозможно без вас.
Все проекты, которые были сохранены во время сборки включенных данных о создании, перечислены в соответствующих папках набора данных в данных.
Еще одна благодарность за FluidStack.io за их надежные, дешевые экземпляры GPU, которые использовались для создания этих моделей.
Если вы хотите привести этот проект, используйте:
@misc{godot-dodo,
author = {Markus Sobkowski},
title = {Godot-Dodo: Finetuned language models for GDScript generation},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/minosvasilias/godot-dodo}},
}
Вам также следует привести оригинальную ламаную бумагу, а также Стэнфорд-Альпака.


