rag demystified
1.0.0
由大語言模型(LLMS)提供動力的檢索增強發電(RAG)管道正在越來越受歡迎,以構建端到端的問答系統。 Llamaindex和Haystack等框架在使破布管道易於使用方面取得了重大進展。儘管這些框架為構建高級抹布管道提供了出色的抽象,但它們以透明度為代價。從用戶的角度來看,這並不容易看出引擎蓋下發生的事情,尤其是在出現錯誤或不一致的情況下。
在此EVADB應用中,我們將通過檢查通常保持不透明的機制,局限性和成本來闡明高級抹布管道的內部工作。

駱駝在筆記本電腦上工作?
如果要直接跳入,請使用以下命令運行應用程序:
pip install -r requirements.txt
echo OPENAI_API_KEY='yourkey' > .env
python complex_qa.py
檢索演示的一代(RAG)是用於基於LLM的問題答案的尖端AI範式。破布管道通常包含:
數據倉庫- 包含與問題回答任務相關的信息的數據源(例如文檔,表等)的集合。
向量檢索- 給出一個問題,找到與問題的最相似的數據塊。這是使用矢量存儲(例如,faiss)完成的。
響應生成- 給定最類似的數據塊,使用大語言模型(例如GPT -4)生成響應。
與傳統的基於LLM的問題回答相比,RAG提供了兩個關鍵優勢:
最新信息- 數據倉庫可以實時更新,因此信息始終是最新的。
來源跟踪- RAG提供了清晰的可追溯性,使用戶能夠識別信息來源,這對於準確驗證和緩解LLM幻覺至關重要。
為了啟用更複雜的問題,最近的AI框架(例如LlamainDex)引入了更高級的抽象,例如子問題,例如sub-teastion查詢引擎。
在此應用程序中,我們將使用子問題查詢引擎作為示例來揭開復雜的RAG管道。我們將檢查子問題查詢引擎的內部工作原理,並將抽像簡化為其核心組件。我們還將確定與高級抹布管道相關的一些挑戰。
數據倉庫是包含與問答任務相關的信息的數據源(例如,文檔,表等)的集合。
在此示例中,我們將使用一個簡單的數據倉庫,其中包含來自LlamainDex的說明性用例的啟發,其中包含多個Wikipedia文章。每個城市的Wiki是一個單獨的數據源。請注意,為簡單起見,我們限制了每個文檔的大小以適合LLM上下文限制。
我們的目標是建立一個可以回答類似問題的系統
如您所見,這些問題可以是單個數據源(Q1/Q2)或複雜的Factoid/Summarization問題(Q3)上的簡單事實/摘要問題。
我們可以使用以下檢索方法:
向量檢索- 給出一個問題和數據源,使用TOP -K最相似的數據塊與來自數據源作為上下文的問題生成LLM響應。我們使用EVADB的現成的FAISS矢量指數進行矢量檢索。但是,這些概念適用於任何向量指數。
摘要檢索- 給出一個摘要問題和數據源,使用整個數據源作為上下文生成LLM響應。
我們的關鍵見解是,高級抹布管道中的每個組件都由單個LLM調用供電。整個管道是一系列具有精心製作的及時模板的LLM呼叫。這些及時的模板是使高級抹布管道能夠執行複雜任務的秘密醬。
實際上,任何高級的抹布管道都可以分為一系列遵循通用輸入模式的單獨的LLM調用:

在哪裡:
現在,我們通過檢查子問題查詢引擎的內部運作來說明這一原理。
該子問題查詢引擎必須執行三個任務:
讓我們詳細檢查每個任務。
我們的目標是將一個複雜的問題分解為一組子問題,同時確定每個亞問題的適當數據源和檢索功能。例如, “哪個城市人口最多?”這個問題。是否將“ {City}的人口是多少?”形式分為五個子問題,一個是每個城市的一個。每個子問題的數據源必須是相應的城市Wiki,並且檢索功能必須是向量檢索。
乍一看,這似乎是一項艱鉅的任務。具體來說,我們需要回答以下問題:
值得注意的是,所有三個問題的答案都是相同的 - 單個LLM呼叫!整個子問題查詢引擎由單個LLM調用提供動力,並使用精心設計的及時模板。讓我們稱此模板為子問題提示模板。
-- Sub-question Prompt Template --
"""
You are an AI assistant that specializes in breaking down complex questions into simpler, manageable sub-questions.
When presented with a complex user question, your role is to generate a list of sub-questions that, when answered, will comprehensively address the original question.
You have at your disposal a pre-defined set of functions and data sources to utilize in answering each sub-question.
If a user question is straightforward, your task is to return the original question, identifying the appropriate function and data source to use for its solution.
Please remember that you are limited to the provided functions and data sources, and that each sub-question should be a full question that can be answered using a single function and a single data source.
"""
LLM調用的上下文是數據源的名稱和系統可用的功能。問題是用戶問題。 LLM輸出一個子問題列表,每個列表都有一個功能和數據源。
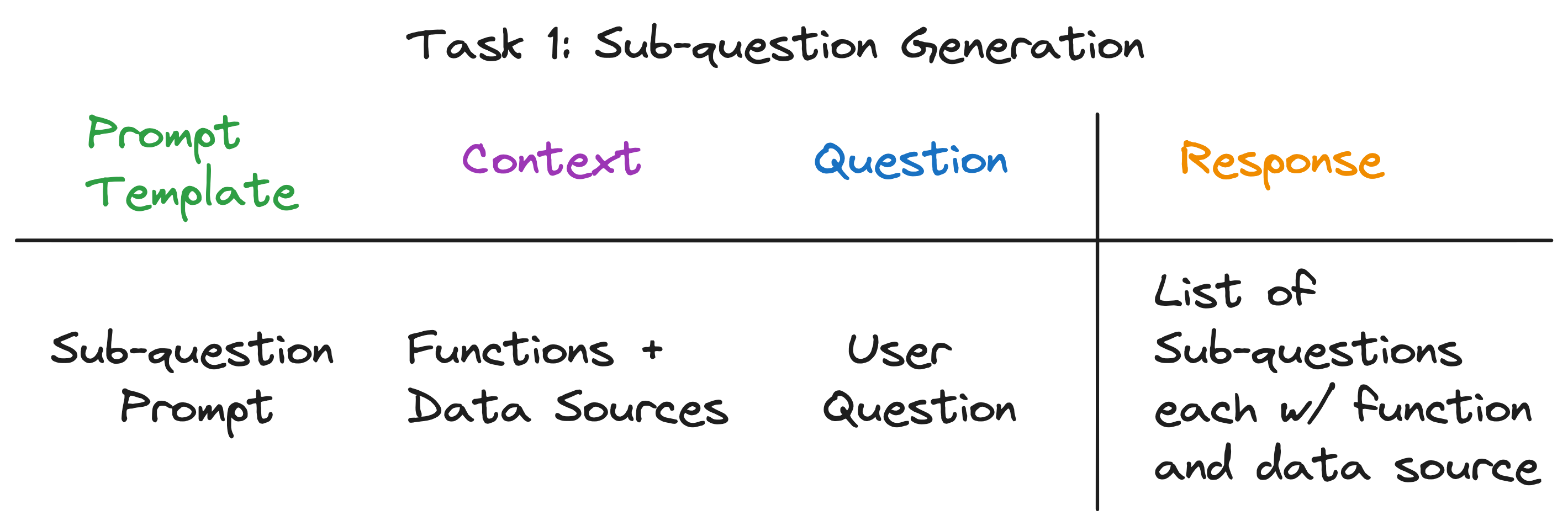
對於三個示例問題,LLM返回以下輸出:
| 問題 | 子問題 | 檢索方法 | 數據源 |
|---|---|---|---|
| “芝加哥的人口是多少?” | “芝加哥的人口是多少?” | 向量檢索 | 芝加哥 |
| “給我總結亞特蘭大的積極方面。” | “給我總結亞特蘭大的積極方面。” | 摘要檢索 | 亞特蘭大 |
| “哪個城市人口最多?” | “多倫多的人口是多少?” | 向量檢索 | 多倫多 |
| “芝加哥的人口是多少?” | 向量檢索 | 芝加哥 | |
| “休斯頓的人口是多少?” | 向量檢索 | 休士頓 | |
| “波士頓的人口是多少?” | 向量檢索 | 波士頓 | |
| “亞特蘭大的人口是多少?” | 向量檢索 | 亞特蘭大 |
對於每個子問題,我們在相應的數據源上使用所選檢索功能來檢索相關信息。例如,對於“芝加哥的人口是多少?” ,我們在芝加哥數據源上使用矢量檢索。同樣,對於“給我亞特蘭大的積極方面的總結”。 ,我們使用亞特蘭大數據源的摘要檢索。
對於這兩種檢索方法,我們使用相同的LLM提示模板。實際上,我們發現LangchainHub的流行RAG提示為此步驟提供了很棒的開箱即用。
-- RAG Prompt Template --
"""
You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.
Question: {question}
Context: {context}
Answer:
兩種檢索方法僅在用於LLM調用的上下文中有所不同。對於向量檢索,我們將最頂級的K最相似的數據塊與子問題作為上下文。對於摘要檢索,我們將整個數據源用作上下文。

這是將子問題響應匯總為最終響應的最後一步。例如,對於“哪個城市人口最多的問題?” ,子問題檢索了每個城市的人口,然後響應匯總發現並返回人口最高的城市。 RAG提示也適合此步驟。
LLM調用的上下文是子問題的響應列表。問題是原始用戶問題,LLM輸出了最終回應。

揭開抽象層後,我們發現了為子問題引擎提供動力的秘密成分-LM的4種類型的LLM調用各種帶有不同的提示模板,上下文和問題。這符合我們完美地確定的通用輸入模式,並且與我們開始的複雜抽象相去甚遠。總結: 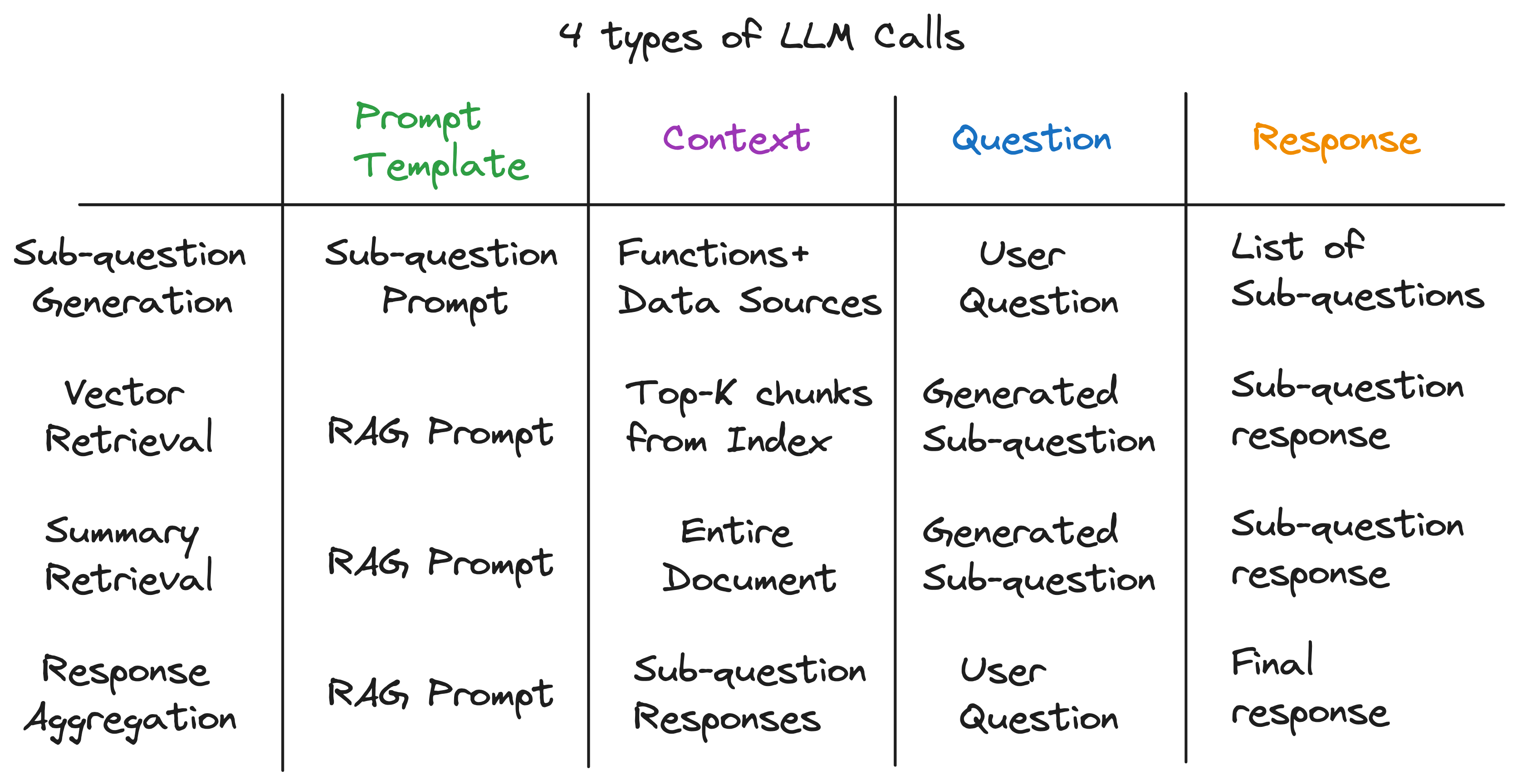
要查看整個管道的操作,請運行以下命令:
pip install -r requirements.txt
echo OPENAI_API_KEY='yourkey' > .env
python complex_qa.py
這是系統回答“人口最多的城市?”問題的一個示例。 。
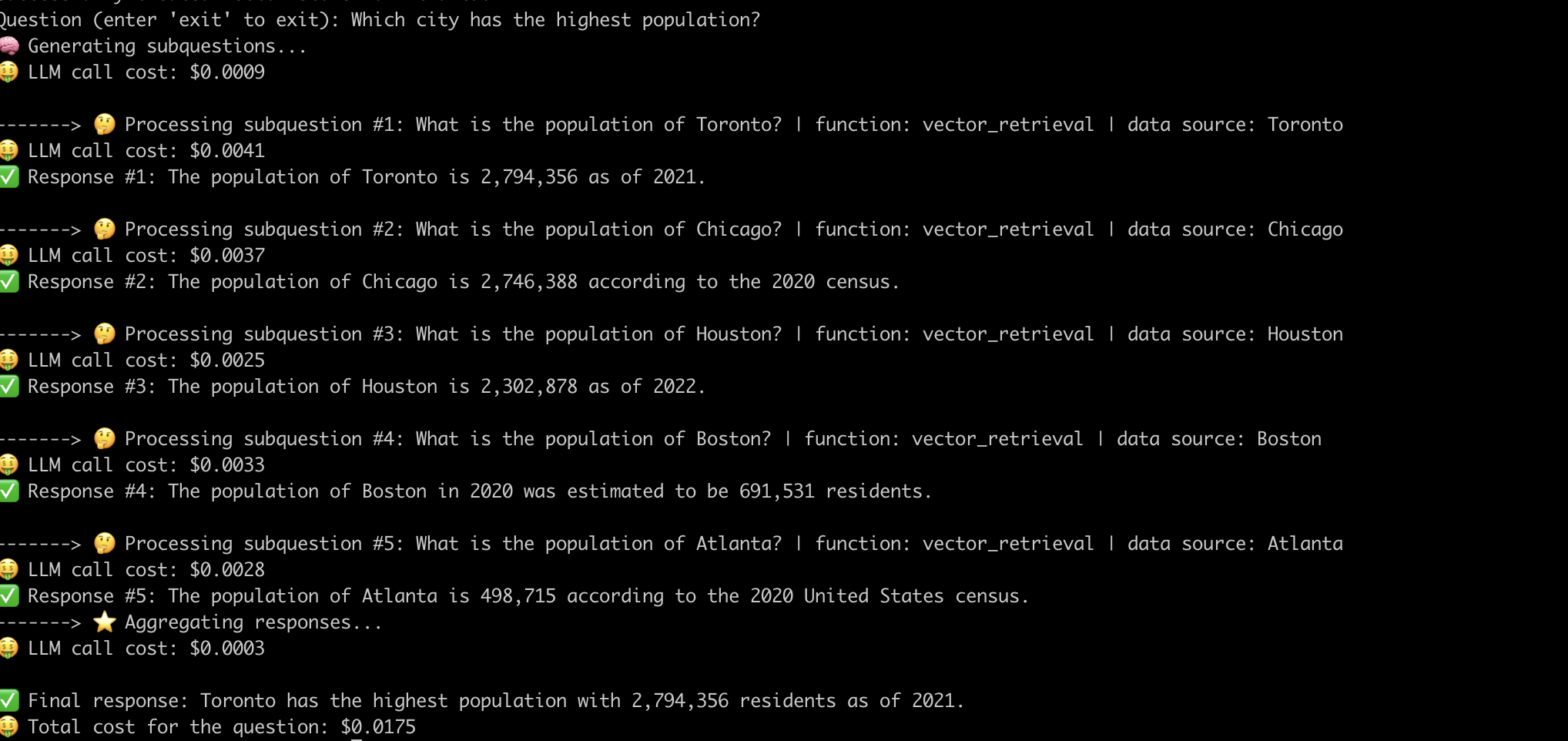
現在,我們已經揭開了高級抹布管道的內部工作,讓我們研究與之相關的挑戰。
我們不得不付出巨大的努力迅速工程,以使管道為每個問題工作。這是構建強大系統的重大挑戰。
為了驗證這種行為,我們使用LlamainDex子問題查詢引擎實施了示例。與我們的觀察結果一致,該系統通常會產生錯誤的子問題,並且還使用錯誤的檢索功能作為子問題,如下所示。

vector_tool相比,上面的LlamainDex基線示例( summary_tool )中的模型選擇不正確,同時也會產生不正確的響應。LLM提供支持的先進的抹布管道已徹底改變了提問系統。但是,正如我們已經看到的那樣,這些管道不是交鑰匙解決方案。在引擎蓋下,他們依靠經過精心設計的及時及時的LLM呼叫。如本EVADB應用中所示,這些管道的成本動態可能對問題敏感,脆弱和不透明。理解這些複雜性是利用其全部潛力並為將來更有效的系統鋪平道路的關鍵。


