rag demystified
1.0.0
Des pipelines de génération (RAG) (RAG) de récupération alimentés par de grands modèles de langue (LLM) gagnent en popularité pour créer des systèmes de réponse aux questions de bout en bout. Des cadres tels que Llamaindex et Haystack ont fait des progrès significatifs pour rendre les pipelines de chiffon faciles à utiliser. Bien que ces cadres fournissent d'excellentes abstractions pour construire des pipelines de chiffon avancés, ils le font au prix de la transparence. Du point de vue de l'utilisateur, il n'est pas évident ce qui se passe sous le capot, en particulier lorsque des erreurs ou des incohérences surviennent.
Dans cette application EVADB, nous allons éclairer le fonctionnement interne des pipelines de chiffon avancés en examinant les mécanismes, les limitations et les coûts qui restent souvent opaques.

Lama travaillant sur un ordinateur portable ?
Si vous souhaitez sauter directement, utilisez les commandes suivantes pour exécuter l'application:
pip install -r requirements.txt
echo OPENAI_API_KEY='yourkey' > .env
python complex_qa.py
La génération de la récupération (RAG) est un paradigme AI de pointe pour la réponse aux questions basée sur LLM. Un pipeline de chiffon contient généralement:
Entrepôt de données - Une collecte de sources de données (par exemple, documents, tableaux, etc.) qui contiennent des informations pertinentes pour la tâche de réponse à la question.
Récupération vectorielle - Compte tenu d'une question, trouvez les k de données les plus similaires les plus similaires à la question. Cela se fait à l'aide d'un magasin vectoriel (par exemple, FAISS).
Génération de réponse - Compte tenu des K des morceaux de données les plus similaires, génèrent une réponse en utilisant un modèle de langue large (par exemple GPT-4).
Le RAG offre deux avantages clés par rapport à la question de la question traditionnelle basée sur LLM:
Informations à jour - L'entrepôt de données peut être mis à jour en temps réel, de sorte que les informations sont toujours à jour.
Suivi de la source - RAG fournit une traçabilité claire, permettant aux utilisateurs d'identifier les sources d'informations, ce qui est crucial pour la vérification de la précision et l'atténuation des hallucinations LLM.
Pour permettre de répondre à des questions plus complexes, des cadres d'IA récents comme Llamaindex ont introduit des abstractions plus avancées telles que le moteur de requête de sous-question.
Dans cette application, nous démystifierons des pipelines de chiffon sophistiqués en utilisant le moteur de requête de sous-question comme exemple. Nous examinerons le fonctionnement interne du moteur de requête de sous-question et simplifier les abstractions à leurs composants principaux. Nous identifierons également certains défis associés aux pipelines de chiffon avancés.
Un entrepôt de données est une collection de sources de données (par exemple, documents, tableaux, etc.) qui contiennent des informations pertinentes pour la tâche de réponse à la question.
Dans cet exemple, nous utiliserons un entrepôt de données simple contenant plusieurs articles Wikipedia pour différentes villes populaires, inspirées du cas d'utilisation illustratif de Llamaindex. Le wiki de chaque ville est une source de données distincte. Notez que pour la simplicité, nous limitons la taille de chaque document pour s'adapter à la limite de contexte LLM.
Notre objectif est de construire un système qui peut répondre à des questions comme:
Comme vous pouvez le voir, les questions peuvent être des questions de factoïde / résumé simples sur une seule source de données (Q1 / Q2) ou des questions complexes de factoïde / de résumé sur plusieurs sources de données (Q3).
Nous avons les méthodes de récupération suivantes à notre disposition:
Vector Retrieval - Compte tenu d'une question et d'une source de données, générez une réponse LLM en utilisant les morceaux de données les plus similaires de K Top-K à la question de la source de données comme contexte. Nous utilisons l'indice vectoriel FAISS standard de EVADB pour la récupération vectorielle. Cependant, les concepts sont applicables à tout indice vectoriel.
Résumé Récupération - Compte tenu d'une question de résumé et d'une source de données, générez une réponse LLM en utilisant la source de données entière comme contexte.
Notre aperçu clé est que chaque composant d'un pipeline de chiffon avancé est alimenté par un seul appel LLM. L'ensemble du pipeline est une série d'appels LLM avec des modèles rapides soigneusement conçus. Ces modèles rapides sont la sauce secrète qui permet aux pipelines de chiffon avancés d'effectuer des tâches complexes.
En fait, tout pipeline de chiffon avancé peut être décomposé en une série d'appels LLM individuels qui suivent un modèle d'entrée universel:

où:
Maintenant, nous illustrons ce principe en examinant le fonctionnement interne du moteur de requête de sous-question.
Le moteur de requête de sous-question doit effectuer trois tâches:
Examinons chaque tâche en détail.
Notre objectif est de décomposer une question complexe en un ensemble de sous-questions, tout en identifiant la source de données et la fonction de récupération appropriées pour chaque sous-question. Par exemple, la question "Quelle ville a la population la plus élevée?" est divisé en cinq sous-questions, une pour chaque ville, de la forme "Quelle est la population de {ville}?". La source de données pour chaque sous-question doit être le wiki de la ville correspondante, et la fonction de récupération doit être une récupération de vecteur.
À première vue, cela semble être une tâche intimidante. Plus précisément, nous devons répondre aux questions suivantes:
Remarquablement, la réponse aux trois questions est la même - un seul appel LLM! L'ensemble du moteur de requête de sous-question est propulsé par un seul appel LLM avec un modèle invite soigneusement conçu. Appelons ce modèle le modèle d'invite de sous-question .
-- Sub-question Prompt Template --
"""
You are an AI assistant that specializes in breaking down complex questions into simpler, manageable sub-questions.
When presented with a complex user question, your role is to generate a list of sub-questions that, when answered, will comprehensively address the original question.
You have at your disposal a pre-defined set of functions and data sources to utilize in answering each sub-question.
If a user question is straightforward, your task is to return the original question, identifying the appropriate function and data source to use for its solution.
Please remember that you are limited to the provided functions and data sources, and that each sub-question should be a full question that can be answered using a single function and a single data source.
"""
Le contexte de l'appel LLM est les noms des sources de données et les fonctions disponibles pour le système. La question est la question de l'utilisateur. Le LLM publie une liste de sous-questions, chacune avec une fonction et une source de données.
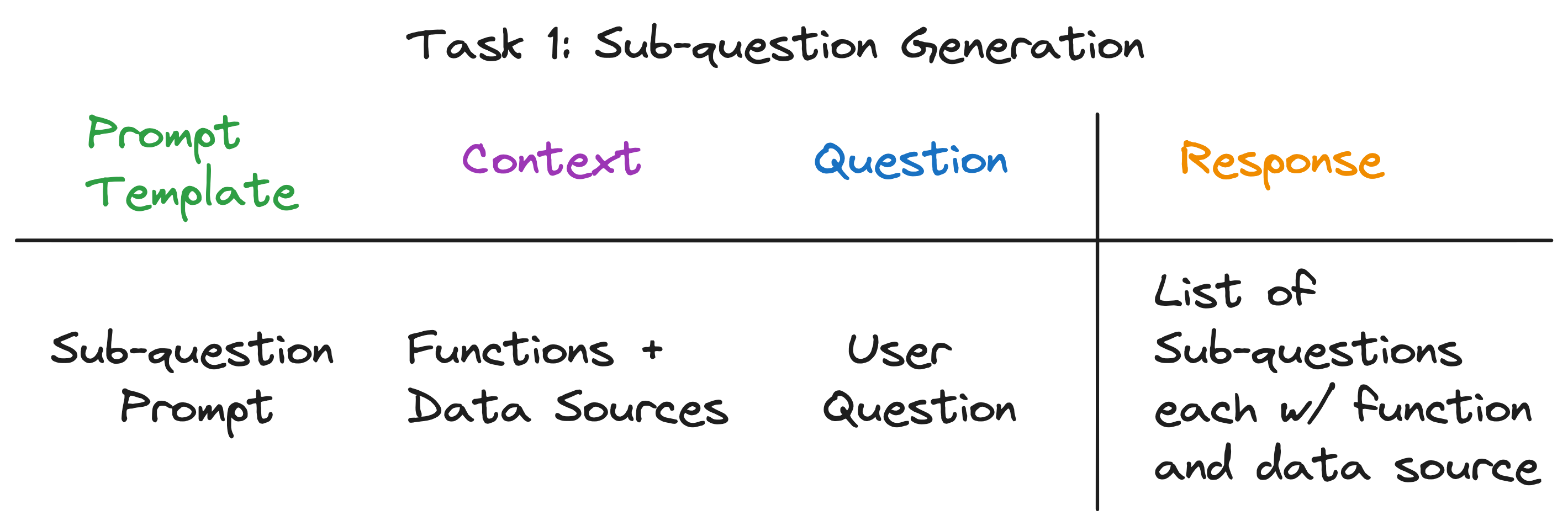
Pour les trois exemples de questions, le LLM renvoie la sortie suivante:
| Question | Sous-questions | Méthode de récupération | Source de données |
|---|---|---|---|
| "Quelle est la population de Chicago?" | "Quelle est la population de Chicago?" | récupération vectorielle | Chicago |
| "Donnez-moi un résumé des aspects positifs d'Atlanta." | "Donnez-moi un résumé des aspects positifs d'Atlanta." | Résumé de la récupération | Atlanta |
| "Quelle ville a la population la plus élevée?" | "Quelle est la population de Toronto?" | récupération vectorielle | Toronto |
| "Quelle est la population de Chicago?" | récupération vectorielle | Chicago | |
| "Quelle est la population de Houston?" | récupération vectorielle | Houes | |
| "Quelle est la population de Boston?" | récupération vectorielle | Boston | |
| "Quelle est la population d'Atlanta?" | récupération vectorielle | Atlanta |
Pour chaque sous-question, nous utilisons la fonction de récupération choisie sur la source de données correspondante pour récupérer les informations pertinentes. Par exemple, pour la sous-question "Quelle est la population de Chicago?" , nous utilisons la récupération vectorielle sur la source de données de Chicago. De même, pour la sous-question «donne-moi un résumé des aspects positifs d'Atlanta». , nous utilisons la récupération de résumé sur la source de données d'Atlanta.
Pour les deux méthodes de récupération, nous utilisons le même modèle d'invite LLM. En fait, nous constatons que l' invite de chiffon populaire de Langchainhub fonctionne très loin de la boîte pour cette étape.
-- RAG Prompt Template --
"""
You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.
Question: {question}
Context: {context}
Answer:
Les deux méthodes de récupération ne diffèrent que dans le contexte utilisé pour l'appel LLM. Pour la récupération vectorielle, nous utilisons les k top k les plus similaires de données de données à la sous-question comme contexte. Pour la récupération de résumé, nous utilisons toute la source de données comme contexte.

Il s'agit de la dernière étape qui agrége les réponses des sous-questions en une réponse finale. Par exemple, pour la question "Quelle ville a la population la plus élevée?" , les sous-questions récupèrent la population de chaque ville, puis l'agrégation de réponse trouve et renvoie la ville avec la population la plus élevée. L' invite de chiffon fonctionne également très bien pour cette étape.
Le contexte de l'appel LLM est la liste des réponses des sous-questions. La question est la question de l'utilisateur d'origine et le LLM publie une réponse finale.

Après avoir démêlé les couches d'abstraction, nous avons découvert l'ingrédient secret alimentant le moteur de requête de sous-question - 4 types d'appels LLM avec un modèle, un contexte et une question différents. Cela correspond au modèle d'entrée universel que nous avons parfaitement identifié plus tôt, et est loin des abstractions complexes avec lesquelles nous avons commencé. Pour résumer: 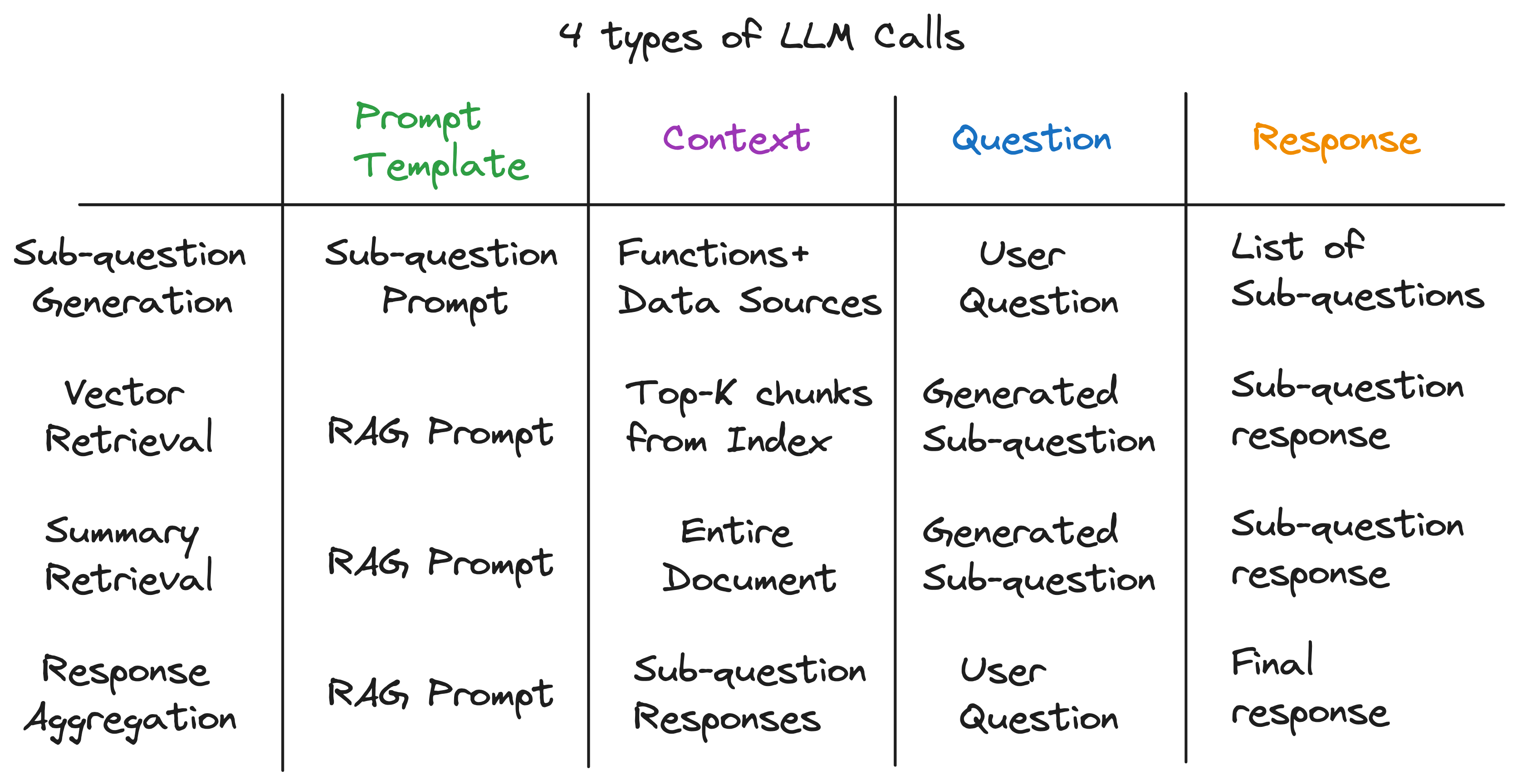
Pour voir le pipeline complet en action, exécutez les commandes suivantes:
pip install -r requirements.txt
echo OPENAI_API_KEY='yourkey' > .env
python complex_qa.py
Voici un exemple du système répondant à la question "Quelle ville avec la population la plus élevée?" .
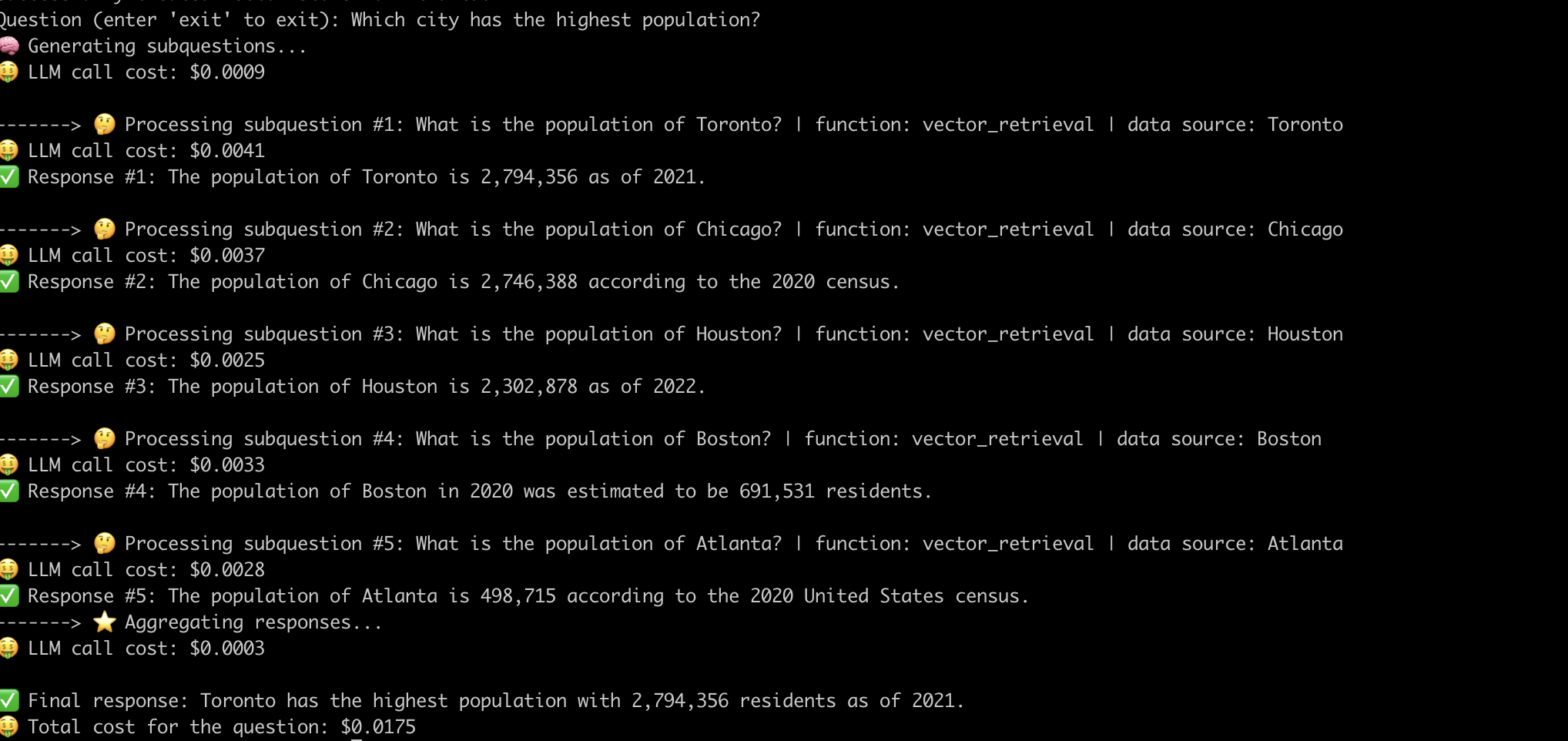
Maintenant que nous avons démystifié le fonctionnement interne des pipelines de chiffon avancés, examinons les défis qui leur sont associés.
Nous avons dû faire des efforts importants dans l'ingénierie rapide pour faire fonctionner le pipeline pour chaque question. Il s'agit d'un défi important pour construire des systèmes robustes.
Pour vérifier ce comportement, nous avons mis en œuvre l'exemple à l'aide du moteur de requête de sous-question Llamaindex. Conformément à nos observations, le système génère souvent les mauvaises sous-questions et utilise également la mauvaise fonction de récupération pour les sous-questions, comme indiqué ci-dessous.

summary_tool ) entraîne un coût 3x plus élevé par rapport au vector_tool tout en générant une réponse incorrecte.Les pipelines de chiffon avancés alimentés par les LLM ont révolutionné les systèmes de réponses aux questions. Cependant, comme nous l'avons vu, ces pipelines ne sont pas des solutions clé en main. Sous le capot, ils comptent sur des modèles rapides soigneusement conçus et plusieurs appels LLM enchaînés. Comme illustré dans cette application EVADB, ces pipelines peuvent être sensibles aux questions, cassants et opaques dans leur dynamique de coût. Comprendre ces subtilités est essentiel pour tirer parti de leur plein potentiel et ouvrir la voie à des systèmes plus robustes et efficaces à l'avenir.


