rag demystified
1.0.0
Palangan pipa generasi (RAG) Retrieval-Agusted (LLM) mendapatkan popularitas untuk membangun sistem penjawab pertanyaan end-to-end. Kerangka kerja seperti Llamaindex dan Haystack telah membuat kemajuan yang signifikan dalam membuat pipa kain mudah digunakan. Sementara kerangka kerja ini memberikan abstraksi yang sangat baik untuk membangun jaringan pipa kain canggih, mereka melakukannya dengan biaya transparansi. Dari perspektif pengguna, tidak jelas apa yang terjadi di bawah kap, terutama ketika kesalahan atau ketidakkonsistenan muncul.
Dalam aplikasi EVADB ini, kami akan menjelaskan cara kerja pipa rag canggih dengan memeriksa mekanika, keterbatasan, dan biaya yang sering tetap buram.

Llama bekerja di laptop ?
Jika Anda ingin langsung masuk, gunakan perintah berikut untuk menjalankan aplikasi:
pip install -r requirements.txt
echo OPENAI_API_KEY='yourkey' > .env
python complex_qa.py
Retrieval-Agusted Generation (RAG) adalah paradigma AI mutakhir untuk menjawab pertanyaan berbasis LLM. Pipa kain biasanya berisi:
Data Warehouse - Kumpulan sumber data (misalnya, dokumen, tabel dll.) Yang berisi informasi yang relevan dengan tugas penjawab pertanyaan.
Vector Retrieval - Diberikan pertanyaan, temukan potongan data paling mirip dengan pertanyaan. Ini dilakukan dengan menggunakan toko vektor (misalnya, FAISS).
Generasi Respons - Mengingat potongan data paling mirip k, menghasilkan respons menggunakan model bahasa besar (misalnya GPT -4).
Rag memberikan dua keunggulan utama dibandingkan dengan pertanyaan berbasis LLM tradisional:
Informasi terkini -Gudang data dapat diperbarui secara real-time, sehingga informasinya selalu terkini.
Pelacakan Sumber - RAG memberikan keterlacakan yang jelas, memungkinkan pengguna untuk mengidentifikasi sumber informasi, yang sangat penting untuk verifikasi akurasi dan mengurangi halusinasi LLM.
Untuk memungkinkan menjawab pertanyaan yang lebih kompleks, kerangka kerja AI terbaru seperti Llamaindex telah memperkenalkan abstraksi yang lebih maju seperti mesin kueri sub-pertanyaan.
Dalam aplikasi ini, kami akan mendemistikasi pipa kain canggih dengan menggunakan mesin kueri sub-pertanyaan sebagai contoh. Kami akan memeriksa cara kerja dalam mesin kueri sub-pertanyaan dan menyederhanakan abstraksi ke komponen inti mereka. Kami juga akan mengidentifikasi beberapa tantangan yang terkait dengan jaringan pipa kain canggih.
Gudang data adalah kumpulan sumber data (misalnya, dokumen, tabel, dll.) Yang berisi informasi yang relevan dengan tugas penjawab pertanyaan.
Dalam contoh ini, kami akan menggunakan gudang data sederhana yang berisi beberapa artikel Wikipedia untuk berbagai kota populer, yang terinspirasi oleh kasus penggunaan ilustratif Llamaindex. Setiap wiki kota adalah sumber data yang terpisah. Perhatikan bahwa untuk kesederhanaan, kami membatasi ukuran masing -masing dokumen agar sesuai dengan batas konteks LLM.
Tujuan kami adalah membangun sistem yang dapat menjawab pertanyaan seperti:
Seperti yang Anda lihat, pertanyaannya dapat berupa pertanyaan factoid/ringkasan sederhana melalui sumber data tunggal (Q1/Q2) atau pertanyaan factoid/ringkasan kompleks atas beberapa sumber data (Q3).
Kami memiliki metode pengambilan berikut yang kami miliki:
Vector Retrieval - Diberikan pertanyaan dan sumber data, menghasilkan respons LLM menggunakan potongan data paling mirip dengan pertanyaan dari pertanyaan dari sumber data sebagai konteks. Kami menggunakan indeks vektor FAISS di luar rak dari EVADB untuk pengambilan vektor. Namun, konsep tersebut berlaku untuk indeks vektor apa pun.
Ringkasan Pengambilan - Diberikan pertanyaan ringkasan dan sumber data, menghasilkan respons LLM menggunakan seluruh sumber data sebagai konteks.
Wawasan utama kami adalah bahwa setiap komponen dalam pipa kain canggih ditenagai oleh panggilan LLM tunggal. Seluruh pipa adalah serangkaian panggilan LLM dengan templat cepat yang dibuat dengan cermat. Template cepat ini adalah saus rahasia yang memungkinkan pipa kain canggih untuk melakukan tugas -tugas kompleks.
Bahkan, setiap pipa kain canggih dapat dipecah menjadi serangkaian panggilan LLM individu yang mengikuti pola input universal:

Di mana:
Sekarang, kami menggambarkan prinsip ini dengan memeriksa cara kerja dalam mesin kueri sub-pertanyaan.
Mesin kueri sub-pertanyaan harus melakukan tiga tugas:
Mari kita periksa setiap tugas secara rinci.
Tujuan kami adalah untuk memecah pertanyaan kompleks menjadi serangkaian sub-pertanyaan, sambil mengidentifikasi sumber data yang sesuai dan fungsi pengambilan untuk setiap sub-pertanyaan. Misalnya, pertanyaan "kota mana yang memiliki populasi tertinggi?" dipecah menjadi lima sub-pertanyaan, satu untuk setiap kota, dari bentuk "Apa populasi {City}?". Sumber data untuk setiap sub-pertanyaan harus wiki kota yang sesuai, dan fungsi pengambilan harus berupa pengambilan vektor.
Sekilas, ini sepertinya tugas yang menakutkan. Secara khusus, kita perlu menjawab pertanyaan berikut:
Hebatnya, jawaban untuk ketiga pertanyaan adalah sama - satu panggilan LLM! Seluruh mesin kueri sub-pertanyaan ditenagai oleh panggilan LLM tunggal dengan templat cepat yang dibuat dengan cermat. Mari kita sebut templat ini template prompt sub-pertanyaan .
-- Sub-question Prompt Template --
"""
You are an AI assistant that specializes in breaking down complex questions into simpler, manageable sub-questions.
When presented with a complex user question, your role is to generate a list of sub-questions that, when answered, will comprehensively address the original question.
You have at your disposal a pre-defined set of functions and data sources to utilize in answering each sub-question.
If a user question is straightforward, your task is to return the original question, identifying the appropriate function and data source to use for its solution.
Please remember that you are limited to the provided functions and data sources, and that each sub-question should be a full question that can be answered using a single function and a single data source.
"""
Konteks untuk panggilan LLM adalah nama -nama sumber data dan fungsi yang tersedia untuk sistem. Pertanyaannya adalah pertanyaan pengguna. LLM mengeluarkan daftar sub-pertanyaan, masing-masing dengan fungsi dan sumber data.
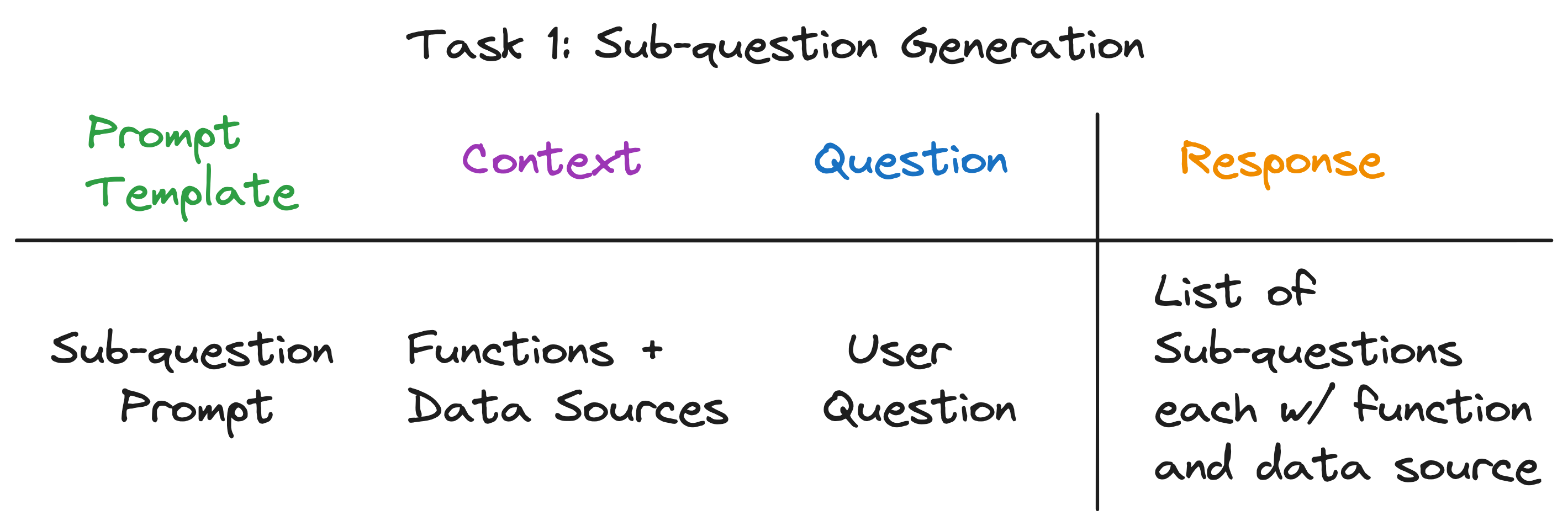
Untuk tiga contoh pertanyaan, LLM mengembalikan output berikut:
| Pertanyaan | Sub -pertanyaan | Metode pengambilan | Sumber data |
|---|---|---|---|
| "Apa populasi Chicago?" | "Apa populasi Chicago?" | pengambilan vektor | Chicago |
| "Beri aku ringkasan aspek positif Atlanta." | "Beri aku ringkasan aspek positif Atlanta." | ringkasan pengambilan | Atlanta |
| "Kota mana yang memiliki populasi tertinggi?" | "Apa populasi Toronto?" | pengambilan vektor | Toronto |
| "Apa populasi Chicago?" | pengambilan vektor | Chicago | |
| "Apa populasi Houston?" | pengambilan vektor | Houston | |
| "Apa populasi Boston?" | pengambilan vektor | Boston | |
| "Apa populasi Atlanta?" | pengambilan vektor | Atlanta |
Untuk setiap sub-pertanyaan, kami menggunakan fungsi pengambilan yang dipilih atas sumber data yang sesuai untuk mengambil informasi yang relevan. Misalnya, untuk sub-pertanyaan "Apa populasi Chicago?" , kami menggunakan pengambilan vektor atas sumber data Chicago. Demikian pula, untuk sub-pertanyaan "Beri saya ringkasan aspek positif Atlanta." , kami menggunakan ringkasan pengambilan atas sumber data Atlanta.
Untuk kedua metode pengambilan, kami menggunakan template prompt LLM yang sama. Bahkan, kami menemukan bahwa prompt kain populer dari LangchainHub bekerja dengan baik untuk langkah ini.
-- RAG Prompt Template --
"""
You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.
Question: {question}
Context: {context}
Answer:
Kedua metode pengambilan hanya berbeda dalam konteks yang digunakan untuk panggilan LLM. Untuk pengambilan vektor, kami menggunakan potongan data paling mirip dengan sub-pertanyaan sebagai konteks. Untuk ringkasan pengambilan, kami menggunakan seluruh sumber data sebagai konteks.

Ini adalah langkah terakhir yang mengumpulkan respons dari sub-pertanyaan menjadi respons akhir. Misalnya, untuk pertanyaan "Kota mana yang memiliki populasi tertinggi?" , sub-pertanyaan mengambil populasi masing-masing kota dan kemudian agregasi respons menemukan dan mengembalikan kota dengan populasi tertinggi. Prompt kain berfungsi dengan baik untuk langkah ini juga.
Konteks untuk panggilan LLM adalah daftar tanggapan dari sub-pertanyaan. Pertanyaannya adalah pertanyaan pengguna asli dan LLM mengeluarkan respons akhir.

Setelah mengungkap lapisan abstraksi, kami menemukan bahan rahasia yang menyalakan mesin kueri sub -pertanyaan - 4 jenis panggilan LLM masing -masing dengan template cepat, konteks, dan pertanyaan yang berbeda. Ini cocok dengan pola input universal yang kami identifikasi sebelumnya dengan sempurna, dan jauh dari abstraksi kompleks yang kami mulai. Untuk meringkas: 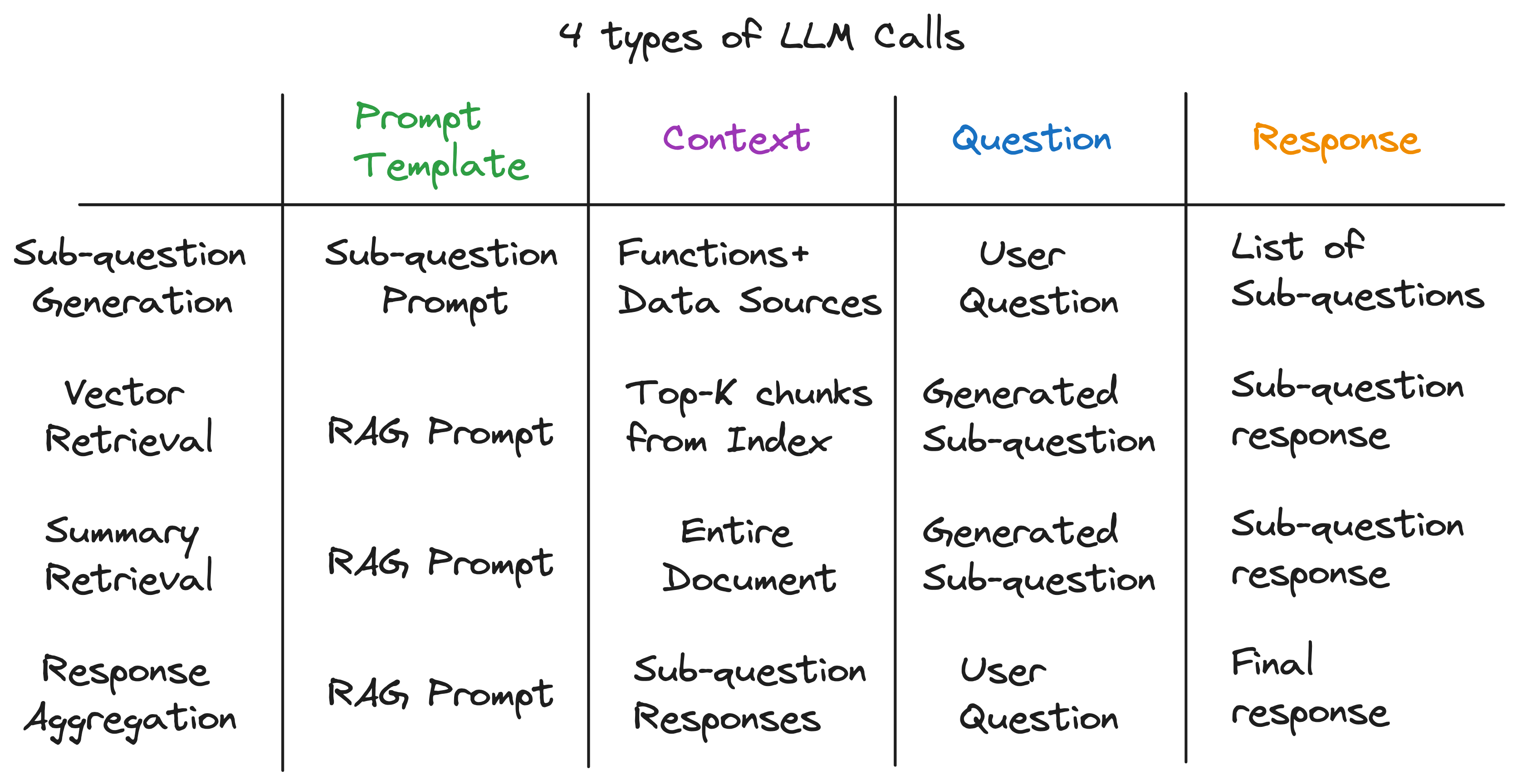
Untuk melihat pipa lengkap beraksi, jalankan perintah berikut:
pip install -r requirements.txt
echo OPENAI_API_KEY='yourkey' > .env
python complex_qa.py
Berikut adalah contoh sistem yang menjawab pertanyaan "kota mana dengan populasi tertinggi?" .
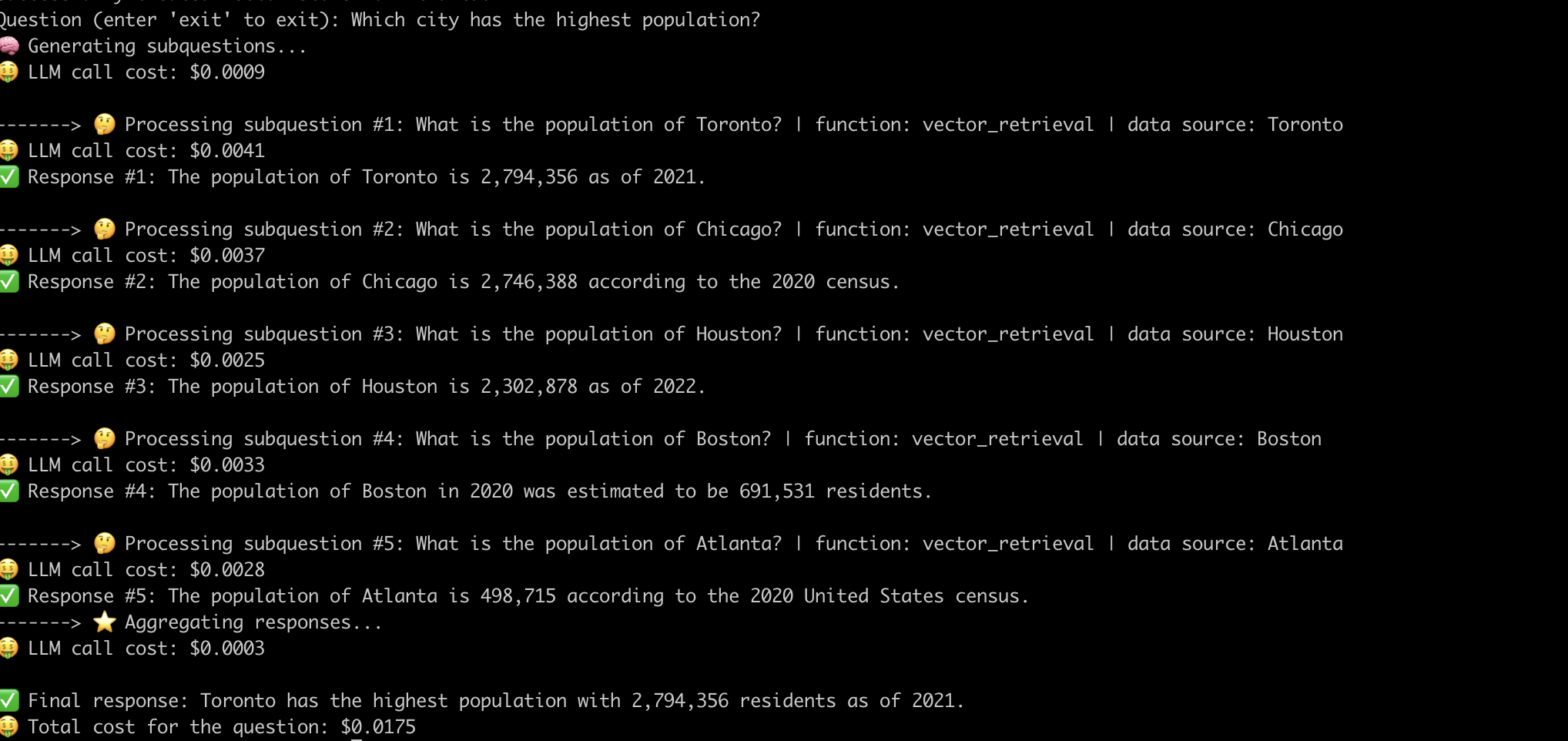
Sekarang kita telah menghilangkan hitik kerja dalam pipa -pipa kain canggih, mari kita periksa tantangan yang terkait dengannya.
Kami harus berupaya keras untuk melakukan rekayasa cepat agar pipa bekerja untuk setiap pertanyaan. Ini adalah tantangan yang signifikan untuk membangun sistem yang kuat.
Untuk memverifikasi perilaku ini, kami menerapkan contoh menggunakan mesin kueri sub-pertanyaan llamaindex. Konsisten dengan pengamatan kami, sistem sering menghasilkan sub-pertanyaan yang salah dan juga menggunakan fungsi pengambilan yang salah untuk sub-pertanyaan, seperti yang ditunjukkan di bawah ini.

summary_tool ) menghasilkan biaya 3x lebih tinggi dibandingkan dengan vector_tool sementara juga menghasilkan respons yang salah.Pipa kain canggih yang ditenagai oleh LLMS telah merevolusi sistem jawaban pertanyaan. Namun, seperti yang telah kita lihat, jalur pipa ini bukan solusi turnkey. Di bawah kap, mereka mengandalkan templat cepat yang direkayasa dengan cermat dan beberapa panggilan LLM rantai. Seperti diilustrasikan dalam aplikasi EVADB ini, pipa-pipa ini dapat menjadi tanya-tanya, rapuh, dan buram dalam dinamika biaya mereka. Memahami seluk -beluk ini adalah kunci untuk memanfaatkan potensi penuh mereka dan membuka jalan bagi sistem yang lebih kuat dan efisien di masa depan.


