rag demystified
1.0.0
การดึงข้อมูลการรับเงิน (RAG) ที่ขับเคลื่อนด้วยโมเดลภาษาขนาดใหญ่ (LLMS) กำลังได้รับความนิยมสำหรับการสร้างระบบตอบคำถามแบบ end-to-end เฟรมเวิร์กเช่น Llamainedex และ Haystack มีความคืบหน้าอย่างมากในการทำให้ท่อส่งเศษผ้าใช้งานง่าย ในขณะที่เฟรมเวิร์กเหล่านี้ให้นามธรรมที่ยอดเยี่ยมสำหรับการสร้างท่อส่งเศษผ้าขั้นสูงพวกเขาทำเช่นนั้นในราคาที่โปร่งใส จากมุมมองของผู้ใช้มันไม่ชัดเจนว่าเกิดอะไรขึ้นภายใต้ประทุนโดยเฉพาะอย่างยิ่งเมื่อเกิดข้อผิดพลาดหรือความไม่สอดคล้องกัน
ในแอพพลิเคชั่น EVADB นี้เราจะแสดงให้เห็นถึงการทำงานด้านในของท่อผ้าขี้ริ้วขั้นสูงโดยการตรวจสอบกลไกข้อ จำกัด และค่าใช้จ่ายที่มักจะยังคงทึบแสง

ลามาทำงานบนแล็ปท็อป ?
หากคุณต้องการกระโดดเข้ามาให้ใช้คำสั่งต่อไปนี้เพื่อเรียกใช้แอปพลิเคชัน:
pip install -r requirements.txt
echo OPENAI_API_KEY='yourkey' > .env
python complex_qa.py
Retrieval-Augmented Generation (RAG) เป็นกระบวนทัศน์ AI ที่ทันสมัยสำหรับการตอบคำถามที่ใช้ LLM โดยทั่วไปแล้วไปป์ไลน์ผ้าขี้ริ้ว:
Data Warehouse - การรวบรวมแหล่งข้อมูล (เช่นเอกสาร, ตาราง ฯลฯ ) ที่มีข้อมูลที่เกี่ยวข้องกับงานตอบคำถาม
การดึงเวกเตอร์ - ให้คำถามค้นหาข้อมูลที่คล้ายกันมากที่สุด k ที่คล้ายกันมากที่สุดกับคำถาม สิ่งนี้ทำได้โดยใช้ร้านค้าเวกเตอร์ (เช่น FAISS)
การสร้างการตอบสนอง - ให้ข้อมูลที่คล้ายกันมากที่สุด K สร้างการตอบสนองโดยใช้แบบจำลองภาษาขนาดใหญ่ (เช่น GPT -4)
RAG ให้ข้อได้เปรียบที่สำคัญสองประการในการตอบคำถามแบบดั้งเดิมตามแบบดั้งเดิม:
ข้อมูลล่าสุด -คลังข้อมูลสามารถอัปเดตแบบเรียลไทม์ดังนั้นข้อมูลจึงทันสมัยอยู่เสมอ
การติดตามแหล่งที่มา - RAG ให้การตรวจสอบย้อนกลับที่ชัดเจนทำให้ผู้ใช้สามารถระบุแหล่งที่มาของข้อมูลซึ่งเป็นสิ่งสำคัญสำหรับการตรวจสอบความถูกต้องและบรรเทาผลกระทบ LLM
เพื่อเปิดใช้งานการตอบคำถามที่ซับซ้อนมากขึ้นเฟรมเวิร์ก AI ล่าสุดเช่น Llamaidex ได้แนะนำ abstractions ขั้นสูงเช่นเอ็นจิ้นแบบสอบถามคำถามย่อย
ในแอปพลิเคชันนี้เราจะ demystify ท่อผ้าขี้ริ้วที่ซับซ้อนโดยใช้เอ็นจิ้นแบบสอบถามแบบสอบถามย่อยเป็นตัวอย่าง เราจะตรวจสอบการทำงานภายในของเอ็นจิ้นแบบสอบถามแบบสอบถามย่อยและทำให้นามธรรมของส่วนประกอบหลักของพวกเขาง่ายขึ้น นอกจากนี้เราจะระบุความท้าทายบางอย่างที่เกี่ยวข้องกับท่อส่งผ้าขี้ริ้วขั้นสูง
คลังข้อมูลคือการรวบรวมแหล่งข้อมูล (เช่นเอกสาร, ตาราง ฯลฯ ) ที่มีข้อมูลที่เกี่ยวข้องกับงานตอบคำถาม
ในตัวอย่างนี้เราจะใช้คลังข้อมูลอย่างง่ายที่มีบทความ Wikipedia หลายบทความสำหรับเมืองยอดนิยมที่แตกต่างกันซึ่งได้รับแรงบันดาลใจจากกรณีการใช้งานของ Llamaindex วิกิของแต่ละเมืองเป็นแหล่งข้อมูลแยกต่างหาก โปรดทราบว่าเพื่อความเรียบง่ายเรา จำกัด ขนาดของแต่ละเอกสารให้พอดีภายในขีด จำกัด บริบท LLM
เป้าหมายของเราคือการสร้างระบบที่สามารถตอบคำถามเช่น:
อย่างที่คุณเห็นคำถามอาจเป็นคำถามที่เรียบง่าย/การสรุปเกี่ยวกับแหล่งข้อมูลเดียว (Q1/Q2) หรือคำถามที่ซับซ้อน/การสรุปที่ซับซ้อนผ่านแหล่งข้อมูลหลายแหล่ง (Q3)
เรามี วิธีการดึงข้อมูล ต่อไปนี้ในการกำจัดของเรา:
การดึงเวกเตอร์ - ให้คำถามและแหล่งข้อมูลสร้างการตอบสนอง LLM โดยใช้ชิ้นข้อมูลที่คล้ายกันมากที่สุดกับคำถามจากแหล่งข้อมูลเป็นบริบท เราใช้ดัชนีเวกเตอร์ FAISS แบบปิดชั้นวางจาก EVADB สำหรับการดึงเวกเตอร์ อย่างไรก็ตามแนวคิดนี้ใช้กับดัชนีเวกเตอร์ใด ๆ
สรุปการดึง - ให้คำถามสรุปและแหล่งข้อมูลสร้างการตอบสนอง LLM โดยใช้แหล่งข้อมูลทั้งหมดเป็นบริบท
ข้อมูลเชิงลึกที่สำคัญของเราคือแต่ละองค์ประกอบในไปป์ไลน์ RAG ขั้นสูงนั้นใช้พลังงานจากการโทร LLM เดียว ไปป์ไลน์ทั้งหมดเป็นชุดของการโทร LLM ที่มีเทมเพลตพรอมต์ที่สร้างขึ้นอย่างระมัดระวัง เทมเพลตที่รวดเร็วเหล่านี้คือซอสลับที่เปิดใช้งานท่อส่งเศษผ้าขั้นสูงเพื่อทำงานที่ซับซ้อน
ในความเป็นจริงไปป์ไลน์ RAG ขั้นสูงใด ๆ สามารถแบ่งออกเป็นชุดของการโทร LLM แต่ละรายการที่เป็นไปตามรูปแบบการป้อนข้อมูลสากล:

ที่ไหน:
ตอนนี้เราแสดงให้เห็นถึงหลักการนี้โดยการตรวจสอบการทำงานภายในของเอ็นจิ้นแบบสอบถามคำถามย่อย
เอ็นจิ้นแบบสอบถามคำถามย่อยต้องทำงานสามอย่าง:
ลองตรวจสอบแต่ละงานโดยละเอียด
เป้าหมายของเราคือการแยกคำถามที่ซับซ้อนออกเป็นชุดของคำถามย่อยในขณะที่ระบุแหล่งข้อมูลที่เหมาะสมและฟังก์ชั่นการดึงข้อมูลสำหรับแต่ละคำถามย่อย ตัวอย่างเช่นคำถาม "เมืองใดมีประชากรสูงสุด" แบ่งออกเป็นห้าคำถามย่อยหนึ่งครั้งสำหรับแต่ละเมืองของรูปแบบ "ประชากร {city} คืออะไร?" แหล่งข้อมูลสำหรับแต่ละคำถามย่อยจะต้องเป็นวิกิของเมืองที่สอดคล้องกันและฟังก์ชั่นการดึงข้อมูลจะต้องเป็นการดึงเวกเตอร์
เมื่อมองแวบแรกดูเหมือนว่าจะเป็นงานที่น่ากลัว โดยเฉพาะเราต้องตอบคำถามต่อไปนี้:
คำตอบสำหรับคำถามทั้งสามคำถามนั้นเหมือนกัน - การโทร LLM ครั้งเดียว! เอ็นจิ้นสืบค้นคำถามย่อยทั้งหมดใช้พลังงานจากการโทร LLM เดียวพร้อมเทมเพลตพรอมต์ที่สร้างขึ้นอย่างระมัดระวัง เรียกเทมเพลตนี้ว่า เทมเพลตพรอมต์คำถามย่อย
-- Sub-question Prompt Template --
"""
You are an AI assistant that specializes in breaking down complex questions into simpler, manageable sub-questions.
When presented with a complex user question, your role is to generate a list of sub-questions that, when answered, will comprehensively address the original question.
You have at your disposal a pre-defined set of functions and data sources to utilize in answering each sub-question.
If a user question is straightforward, your task is to return the original question, identifying the appropriate function and data source to use for its solution.
Please remember that you are limited to the provided functions and data sources, and that each sub-question should be a full question that can be answered using a single function and a single data source.
"""
บริบทสำหรับการเรียก LLM คือชื่อของแหล่งข้อมูลและฟังก์ชั่นที่มีอยู่ในระบบ คำถามคือคำถามผู้ใช้ LLM ส่งออกรายการคำถามย่อยแต่ละรายการมีฟังก์ชั่นและแหล่งข้อมูล
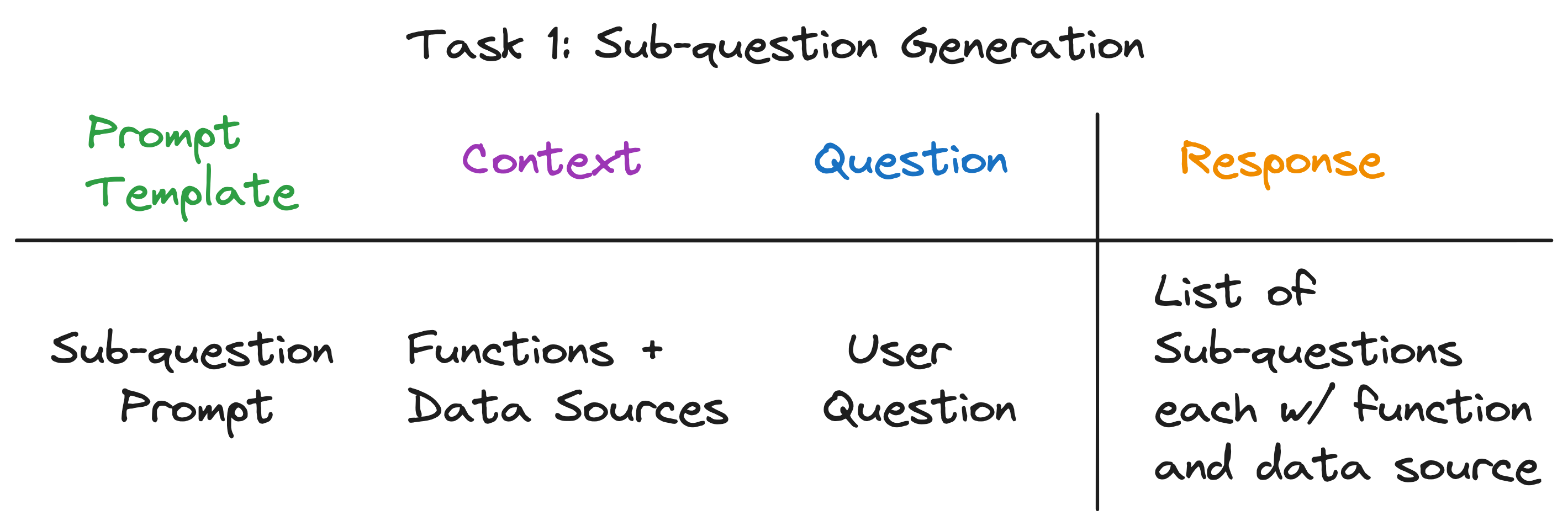
สำหรับคำถามสามตัวอย่าง LLM ส่งคืนผลลัพธ์ต่อไปนี้:
| คำถาม | คำถามย่อย | วิธีการดึงข้อมูล | แหล่งข้อมูล |
|---|---|---|---|
| "ประชากรของชิคาโกคืออะไร" | "ประชากรของชิคาโกคืออะไร" | การดึงเวกเตอร์ | ชิคาโก |
| "ขอสรุปแง่บวกของแอตแลนต้า" | "ขอสรุปแง่บวกของแอตแลนต้า" | สรุปการเรียกคืน | แอตแลนตา |
| "เมืองใดมีประชากรสูงสุด" | "ประชากรของโตรอนโตคืออะไร" | การดึงเวกเตอร์ | โตรอนโต |
| "ประชากรของชิคาโกคืออะไร" | การดึงเวกเตอร์ | ชิคาโก | |
| "ประชากรของฮูสตันคืออะไร" | การดึงเวกเตอร์ | ฮูสตัน | |
| "ประชากรของบอสตันคืออะไร" | การดึงเวกเตอร์ | บอสตัน | |
| "ประชากรของแอตแลนต้าคืออะไร" | การดึงเวกเตอร์ | แอตแลนตา |
สำหรับแต่ละคำถามย่อยเราใช้ฟังก์ชั่นการดึงข้อมูลที่เลือกผ่านแหล่งข้อมูลที่เกี่ยวข้องเพื่อดึงข้อมูลที่เกี่ยวข้อง ตัวอย่างเช่นสำหรับคำถามย่อย "ประชากรของชิคาโกคืออะไร" เราใช้การดึงเวกเตอร์ผ่านแหล่งข้อมูลชิคาโก ในทำนองเดียวกันสำหรับคำถามย่อย "ให้ฉันสรุปด้านบวกของแอตแลนต้า" เราใช้การดึงข้อมูลสรุปผ่านแหล่งข้อมูลแอตแลนตา
สำหรับวิธีการดึงข้อมูลทั้งสองเราใช้แม่แบบพรอมต์ LLM เดียวกัน ในความเป็นจริงเราพบว่า พรอมต์ RAG ยอดนิยมจาก Langchainhub ใช้งานได้ดีนอกกรอบสำหรับขั้นตอนนี้
-- RAG Prompt Template --
"""
You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.
Question: {question}
Context: {context}
Answer:
ทั้งวิธีการดึงข้อมูลแตกต่างกันในบริบทที่ใช้สำหรับการเรียก LLM เท่านั้น สำหรับการดึงเวกเตอร์เราใช้ชิ้นส่วนข้อมูลที่คล้ายกันมากที่สุด K กับคำถามย่อยเป็นบริบท สำหรับการดึงข้อมูลสรุปเราใช้แหล่งข้อมูลทั้งหมดเป็นบริบท

นี่เป็นขั้นตอนสุดท้ายที่รวมการตอบสนองจากคำถามย่อยไปสู่การตอบสนองขั้นสุดท้าย ตัวอย่างเช่นสำหรับคำถาม "เมืองใดมีประชากรสูงสุด" คำถามย่อยจะดึงประชากรของแต่ละเมืองจากนั้นตอบสนองการรวมตัวกันพบและส่งคืนเมืองด้วยประชากรสูงสุด Rag Prompt ทำงานได้ดีสำหรับขั้นตอนนี้เช่นกัน
บริบทสำหรับการเรียก LLM คือรายการคำตอบจากคำถามย่อย คำถามคือคำถามผู้ใช้ดั้งเดิมและ LLM ส่งออกการตอบกลับขั้นสุดท้าย

หลังจากคลี่คลายเลเยอร์ของสิ่งที่เป็นนามธรรมเราได้ค้นพบส่วนผสมลับที่ให้กำลังกับเครื่องยนต์สืบค้นแบบสอบถามย่อย - 4 ประเภทของ LLM เรียกแต่ละครั้งด้วยเทมเพลตพรอมต์บริบทและคำถามที่แตกต่างกัน สิ่งนี้เหมาะกับรูปแบบการป้อนข้อมูลสากลที่เราระบุไว้ก่อนหน้านี้อย่างสมบูรณ์แบบและเป็นหนทางไกลจาก abstractions ที่ซับซ้อนที่เราเริ่มต้นด้วย เพื่อสรุป: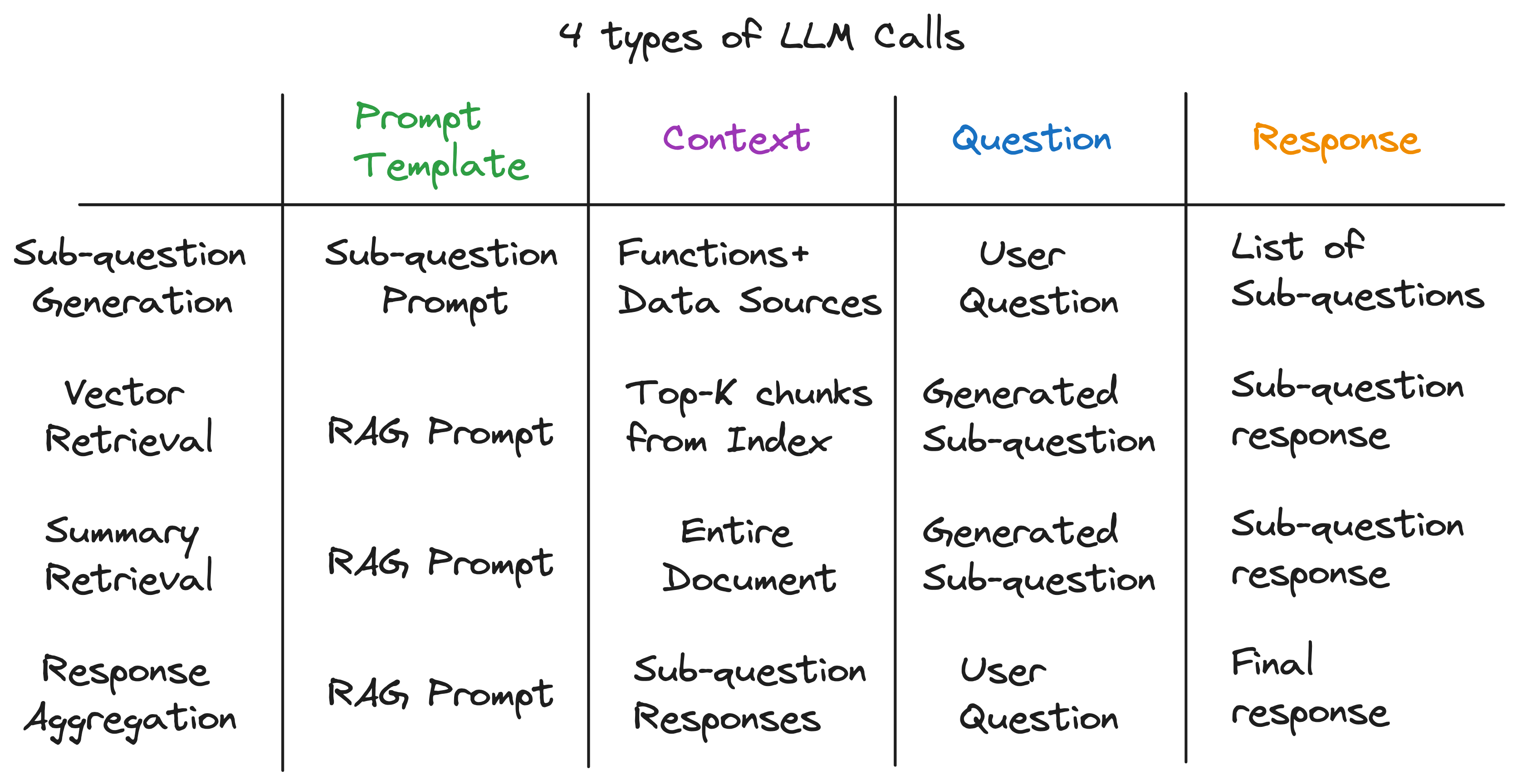
หากต้องการดูการดำเนินการไปป์ไลน์เต็มให้เรียกใช้คำสั่งต่อไปนี้:
pip install -r requirements.txt
echo OPENAI_API_KEY='yourkey' > .env
python complex_qa.py
นี่คือตัวอย่างของระบบที่ตอบคำถาม "เมืองใดที่มีประชากรสูงสุด" -
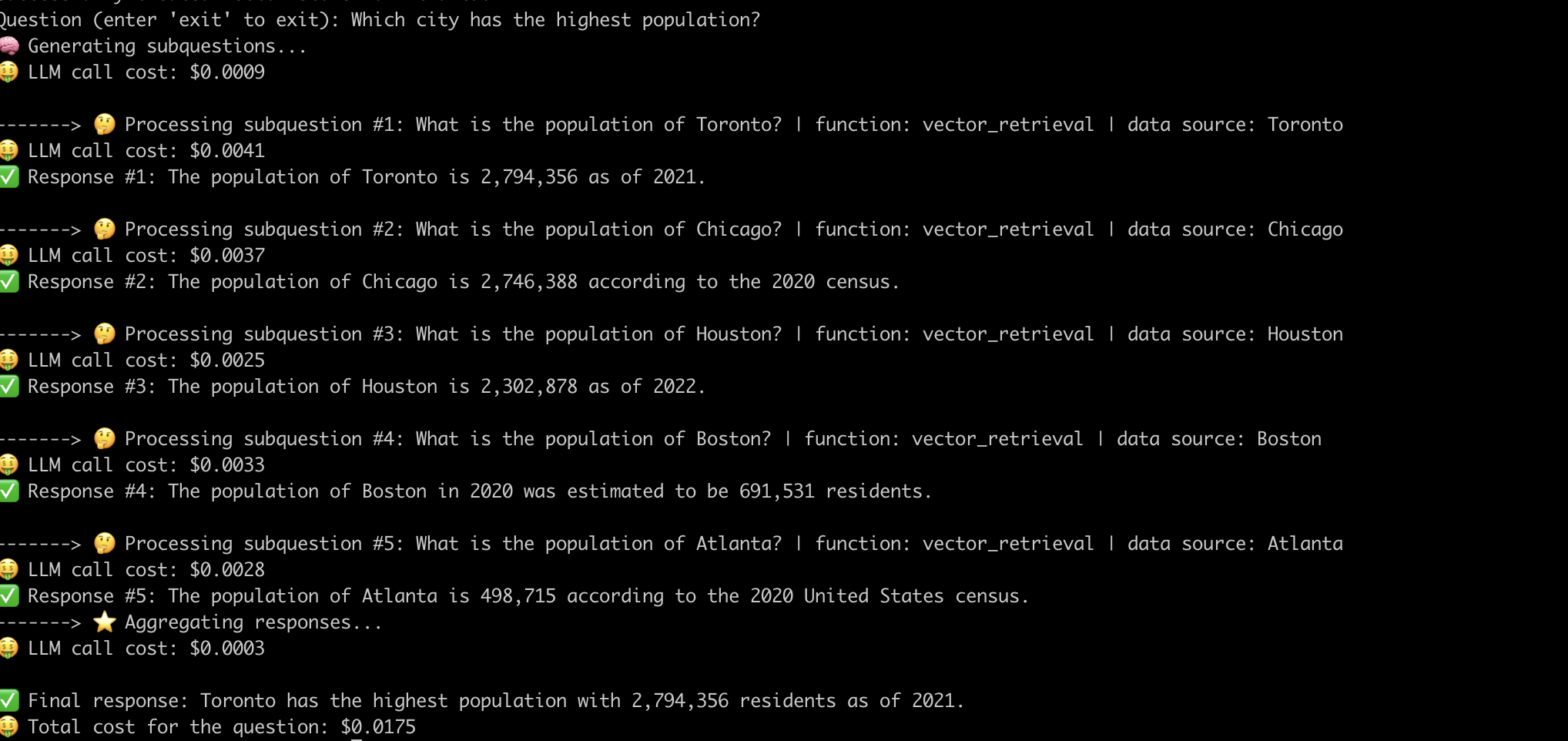
ตอนนี้เราได้เข้าใจถึงการทำงานภายในของท่อส่งเศษผ้าขั้นสูงแล้วลองตรวจสอบความท้าทายที่เกี่ยวข้องกับพวกเขา
เราต้องใช้ความพยายามอย่างมีนัยสำคัญในการวิศวกรรมที่รวดเร็วเพื่อให้ท่อส่งไปทำงานสำหรับแต่ละคำถาม นี่เป็นความท้าทายที่สำคัญสำหรับการสร้างระบบที่แข็งแกร่ง
ในการตรวจสอบพฤติกรรมนี้เราใช้ตัวอย่างโดยใช้เครื่องมือค้นหาคำถามย่อย LlamaineDex สอดคล้องกับการสังเกตของเราระบบมักจะสร้างคำถามย่อยที่ไม่ถูกต้องและยังใช้ฟังก์ชั่นการดึงข้อมูลผิดสำหรับคำถามย่อยดังที่แสดงด้านล่าง

summary_tool ) ส่งผลให้ต้นทุนสูงกว่า 3x เมื่อเทียบกับ vector_tool ในขณะเดียวกันก็สร้างการตอบสนองที่ไม่ถูกต้องท่อส่งเศษผ้าขั้นสูงที่ขับเคลื่อนโดย LLM ได้ปฏิวัติระบบการตอบคำถาม อย่างไรก็ตามอย่างที่เราได้เห็นท่อเหล่านี้ไม่ใช่วิธีแก้ปัญหาแบบครบวงจร ภายใต้ฝากระโปรงพวกเขาพึ่งพาแม่แบบพรอมต์ที่ได้รับการออกแบบมาอย่างระมัดระวังและการโทร LLM ที่ถูกล่ามโซ่หลายครั้ง ดังที่แสดงในแอปพลิเคชัน EVADB นี้ท่อเหล่านี้อาจเป็นคำถามที่ไวต่อคำถามเปราะและทึบแสงในการเปลี่ยนแปลงค่าใช้จ่าย การทำความเข้าใจความซับซ้อนเหล่านี้เป็นกุญแจสำคัญในการใช้ประโยชน์จากศักยภาพอย่างเต็มที่และปูทางสำหรับระบบที่แข็งแกร่งและมีประสิทธิภาพมากขึ้นในอนาคต


