rag demystified
1.0.0
RAG-Pipelines (Retrieval-Augmented Generation), die von großen Sprachmodellen (LLMs) angetrieben werden, werden für den Aufbau von End-to-End-Fragenbeantwortungssystemen beliebt. Rahmenbedingungen wie Llamaindex und Haystack haben erhebliche Fortschritte bei der einfach zu bedienenden Lag -Pipelines erzielt. Während diese Frameworks hervorragende Abstraktionen für den Bau fortschrittlicher Rag -Pipelines bieten, tun sie dies auf Kosten der Transparenz. Aus Sicht der Benutzer ist es nicht leicht zu erkennen, was unter der Haube vor sich geht, insbesondere wenn Fehler oder Inkonsistenzen auftreten.
In dieser EVADB -Anwendung beleuchten wir auf die inneren Funktionsweise fortschrittlicher Rag -Pipelines, indem wir die Mechanik, Einschränkungen und Kosten untersuchen, die häufig undurchsichtig bleiben.

Lama an einem Laptop arbeiten ?
Wenn Sie direkt hineinspringen möchten, verwenden Sie die folgenden Befehle, um die Anwendung auszuführen:
pip install -r requirements.txt
echo OPENAI_API_KEY='yourkey' > .env
python complex_qa.py
Retrieval-Augmented Generation (RAG) ist ein hochmodernes AI-Paradigma für die Beantwortung von Fragen zur Frage, die auf LLM basiert. Eine Lappenpipeline enthält typischerweise:
Data Warehouse - Eine Sammlung von Datenquellen (z. B. Dokumenten, Tabellen usw.), die Informationen enthalten, die für die Fragen zur Beantwortung von Fragen relevant sind.
Vektor -Abruf - Finden Sie angesichts einer Frage die obersten K -Datenbrocken wie die Frage. Dies geschieht mit einem Vektor Store (z. B. Faiss).
Antwortgenerierung - Angesichts der am meisten ähnlichen Datenbrocken generieren eine Antwort mit einem großen Sprachmodell (z. B. GPT -4).
RAG bietet zwei wichtige Vorteile gegenüber herkömmlichen LLM-basierten Fragen zur Beantwortung:
Aktuelle Informationen -Das Data Warehouse kann in Echtzeit aktualisiert werden, sodass die Informationen immer aktuell sind.
Quellverfolgung - RAG bietet eine klare Rückverfolgbarkeit und ermöglicht es den Benutzern, die Informationsquellen zu identifizieren, was für die Genauigkeitsüberprüfung von entscheidender Bedeutung ist und die LLM -Halluzinationen mildern.
Um komplexere Fragen zu beantworten, haben neuere KI-Frameworks wie Llamaindex fortgeschrittenere Abstraktionen wie die Abfrage-Engine von Unterfragen eingeführt.
In dieser Anwendung entmystifizieren wir anspruchsvolle Rag-Pipelines, indem wir als Beispiel den Abfrage-Motor der Unterfristung verwenden. Wir werden die inneren Funktionsweise der Sub-Frage-Abfrage-Engine untersuchen und die Abstraktionen zu ihren Kernkomponenten vereinfachen. Wir werden auch einige Herausforderungen im Zusammenhang mit fortgeschrittenen Rag -Pipelines identifizieren.
Ein Data Warehouse ist eine Sammlung von Datenquellen (z. B. Dokumenten, Tabellen usw.), die Informationen enthalten, die für die Fragen zur Beantwortung von Fragen relevant sind.
In diesem Beispiel verwenden wir ein einfaches Data Warehouse mit mehreren Wikipedia-Artikeln für verschiedene beliebte Städte, die von der illustrativen Anwendung von Llamaindex inspiriert sind. Das Wiki jeder Stadt ist eine separate Datenquelle. Beachten Sie, dass wir für den Einfachheit halber die Größe jedes Dokuments so einschränken, dass sie in die LLM -Kontextgrenze passen.
Unser Ziel ist es, ein System zu erstellen, das Fragen beantworten kann wie:
Wie Sie sehen können, können die Fragen einfache faktoid-/summarisierende Fragen über eine einzelne Datenquelle (Q1/Q2) oder komplexe Faktoid-/Zusammenfassungsfragen über mehrere Datenquellen (Q3) sein.
Wir haben die folgenden Abrufmethoden zur Verfügung:
Vektor -Abruf - Bei einer Frage und einer Datenquelle generieren Sie eine LLM -Antwort unter Verwendung der am meisten ähnlichen Datenbrocken wie die Frage aus der Datenquelle als Kontext. Wir verwenden den off-the-Shelf-Faiss-Vektor-Index von EVADB für das Abruf von Vektor. Die Konzepte gelten jedoch für jeden Vektorindex.
Zusammenfassung Abruf - Bei einer zusammenfassenden Frage und einer Datenquelle generieren Sie eine LLM -Antwort unter Verwendung der gesamten Datenquelle als Kontext.
Unsere Haupteinsicht ist, dass jede Komponente in einer fortschrittlichen Lappenpipeline durch einen einzelnen LLM -Aufruf angetrieben wird. Die gesamte Pipeline ist eine Reihe von LLM -Anrufen mit sorgfältig gefertigten Eingabeaufentwicklungsvorlagen. Diese promptierten Vorlagen sind die geheime Sauce, mit der fortschrittliche Lappenpipelines komplexe Aufgaben ausführen können.
Tatsächlich kann jede fortschrittliche Lappenpipeline in eine Reihe einzelner LLM -Aufrufe unterteilt werden, die einem universellen Eingabemuster folgen:

Wo:
Jetzt veranschaulichen wir dieses Prinzip, indem wir das Innenleben der Sub-Frage-Abfrage-Engine untersuchen.
Die Sub-Frage-Abfrage-Engine muss drei Aufgaben ausführen:
Lassen Sie uns jede Aufgabe im Detail untersuchen.
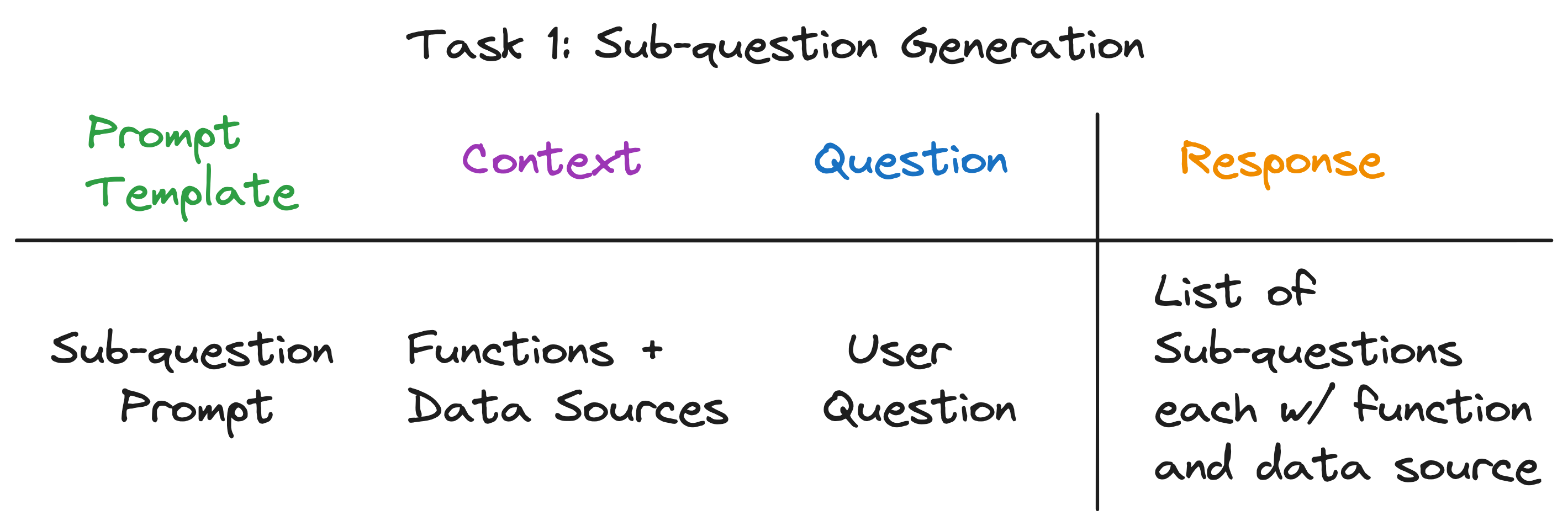
Unser Ziel ist es, eine komplexe Frage in eine Reihe von Unterfragen aufzuteilen und gleichzeitig die entsprechende Datenquelle und die Abruffunktion für jede Unterfristung zu identifizieren. Zum Beispiel die Frage "Welche Stadt hat die höchste Bevölkerung?" Ist in fünf Unterfragen unterteilt, eine für jede Stadt, der Form "Was ist die Bevölkerung von {Stadt}?". Die Datenquelle für jede Unter Frage muss das entsprechende Wiki der Stadt sein, und die Abruffunktion muss das Abruf von Vektoren sein.
Auf den ersten Blick scheint dies eine entmutigende Aufgabe zu sein. Insbesondere müssen wir die folgenden Fragen beantworten:
Bemerkenswerterweise ist die Antwort auf alle drei Fragen gleich - ein einziger LLM -Anruf! Die gesamte Abfrage-Engine von Sub-Frage wird von einem einzigen LLM-Anruf mit einer sorgfältig gefertigten Eingabeaufforderung angetrieben. Nennen wir diese Vorlage die Unterfristung der Unterfristung .
-- Sub-question Prompt Template --
"""
You are an AI assistant that specializes in breaking down complex questions into simpler, manageable sub-questions.
When presented with a complex user question, your role is to generate a list of sub-questions that, when answered, will comprehensively address the original question.
You have at your disposal a pre-defined set of functions and data sources to utilize in answering each sub-question.
If a user question is straightforward, your task is to return the original question, identifying the appropriate function and data source to use for its solution.
Please remember that you are limited to the provided functions and data sources, and that each sub-question should be a full question that can be answered using a single function and a single data source.
"""
Der Kontext für den LLM -Aufruf sind die Namen der Datenquellen und die für das System verfügbaren Funktionen. Die Frage ist die Benutzerfrage. Das LLM gibt eine Liste von Unterfragen aus, jeweils eine Funktion und eine Datenquelle.
Für die drei Beispielfragen gibt das LLM die folgende Ausgabe zurück:
| Frage | Unterfragen | Abrufmethode | Datenquelle |
|---|---|---|---|
| "Was ist die Bevölkerung von Chicago?" | "Was ist die Bevölkerung von Chicago?" | Vektor -Abruf | Chicago |
| "Geben Sie mir eine Zusammenfassung der positiven Aspekte von Atlanta." | "Geben Sie mir eine Zusammenfassung der positiven Aspekte von Atlanta." | Zusammenfassung Abruf | Atlanta |
| "Welche Stadt hat die höchste Bevölkerung?" | "Was ist die Bevölkerung von Toronto?" | Vektor -Abruf | Toronto |
| "Was ist die Bevölkerung von Chicago?" | Vektor -Abruf | Chicago | |
| "Was ist die Bevölkerung von Houston?" | Vektor -Abruf | Houston | |
| "Was ist die Bevölkerung von Boston?" | Vektor -Abruf | Boston | |
| "Was ist die Bevölkerung von Atlanta?" | Vektor -Abruf | Atlanta |
Für jede Unter Frage verwenden wir die ausgewählte Abruffunktion über die entsprechende Datenquelle, um die relevanten Informationen abzurufen. Zum Beispiel für die Unterfristung "Was ist die Bevölkerung von Chicago?" Wir verwenden das Abrufen des Vektors über die Chicago -Datenquelle. In ähnlicher Weise gibt mir für die Unterfristung "eine Zusammenfassung der positiven Aspekte von Atlanta". Wir verwenden eine summarische Abrufen über die Datenquelle von Atlanta.
Für beide Abrufmethoden verwenden wir dieselbe LLM -Eingabeaufforderung. Tatsächlich stellen wir fest, dass die beliebte Lumpen-Eingabeaufforderung von Langchainhub für diesen Schritt großartige Out-of-the-Boxs funktioniert.
-- RAG Prompt Template --
"""
You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.
Question: {question}
Context: {context}
Answer:
Beide Abrufmethoden unterscheiden sich nur in dem für den LLM -Aufruf verwendeten Kontext. Für das Abrufen von Vektor verwenden wir die obersten K-Datenbrocken für den Unterfragen als Kontext. Für das Abrufen von Zusammenfassungen verwenden wir die gesamte Datenquelle als Kontext.

Dies ist der letzte Schritt, der die Antworten aus den Unterfragen in eine endgültige Antwort aggregiert. Zum Beispiel für die Frage "Welche Stadt hat die höchste Bevölkerung?" Die Unterfragen holen die Bevölkerung jeder Stadt und dann die Reaktionsaggregation findet und kehrt die Stadt mit der höchsten Bevölkerung zurück. Die Lappen -Eingabeaufforderung eignet sich auch hervorragend für diesen Schritt.
Der Kontext für den LLM-Aufruf ist die Liste der Antworten aus den Unterfragen. Die Frage ist die ursprüngliche Benutzerfrage und die LLM gibt eine endgültige Antwort aus.

Nachdem wir die Abstraktionsschichten aufgelöst hatten, entdeckten wir den geheimen Zutaten, der die Subquestion -Abfrage -Engine mit Strom versorgt - 4 Arten von LLM -Aufrufen von jeweils unterschiedlichen Eingabeaufentwicklungsvorlagen, Kontext und eine Frage. Dies passt zum universellen Eingabemuster, das wir früher perfekt identifiziert haben, und ist weit entfernt von den komplexen Abstraktionen, mit denen wir begonnen haben. Zusammenfassen: 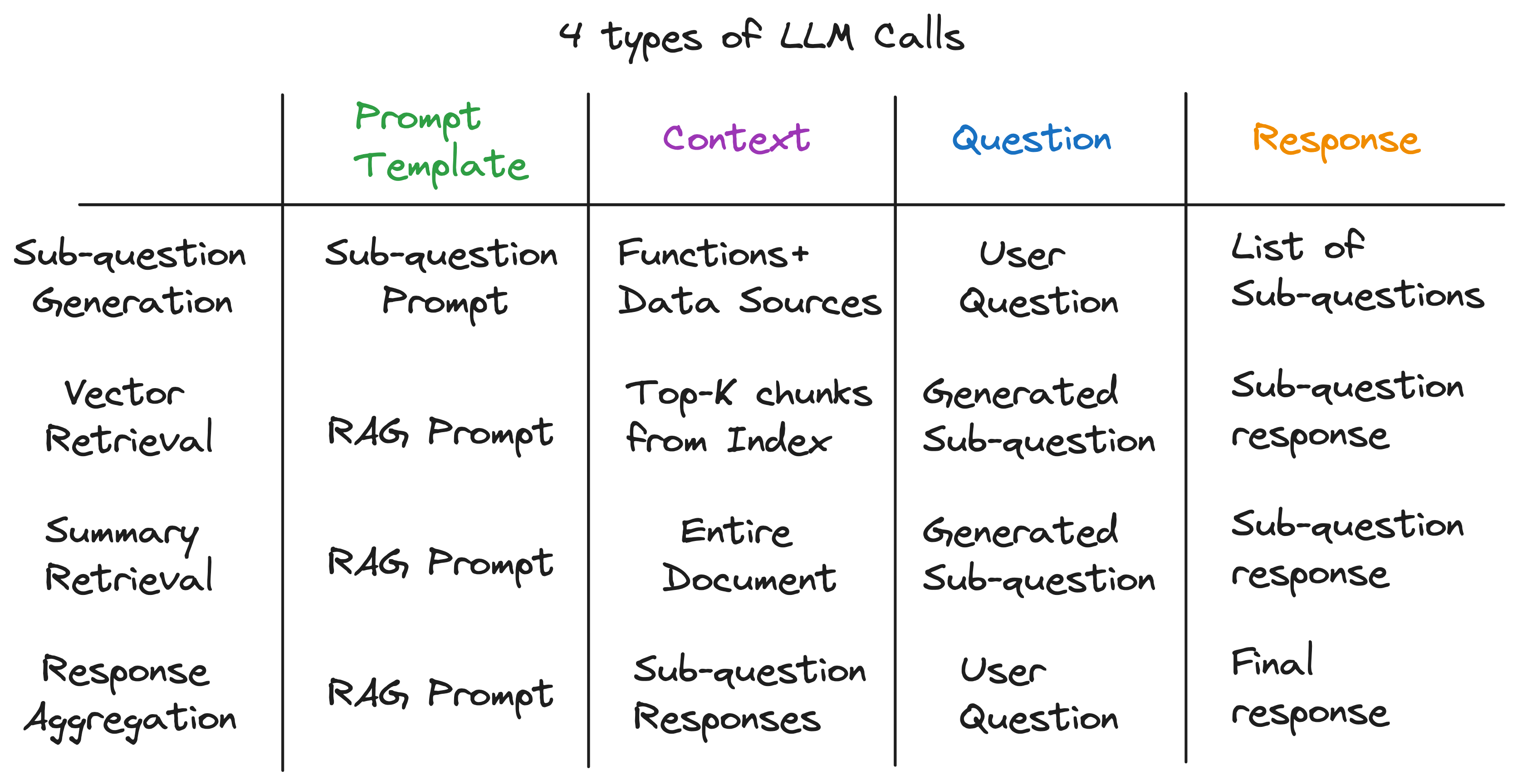
Um die vollständige Pipeline in Aktion zu sehen, führen Sie die folgenden Befehle aus:
pip install -r requirements.txt
echo OPENAI_API_KEY='yourkey' > .env
python complex_qa.py
Hier ist ein Beispiel dafür, dass das System die Frage "Welche Stadt mit der höchsten Bevölkerung?" .
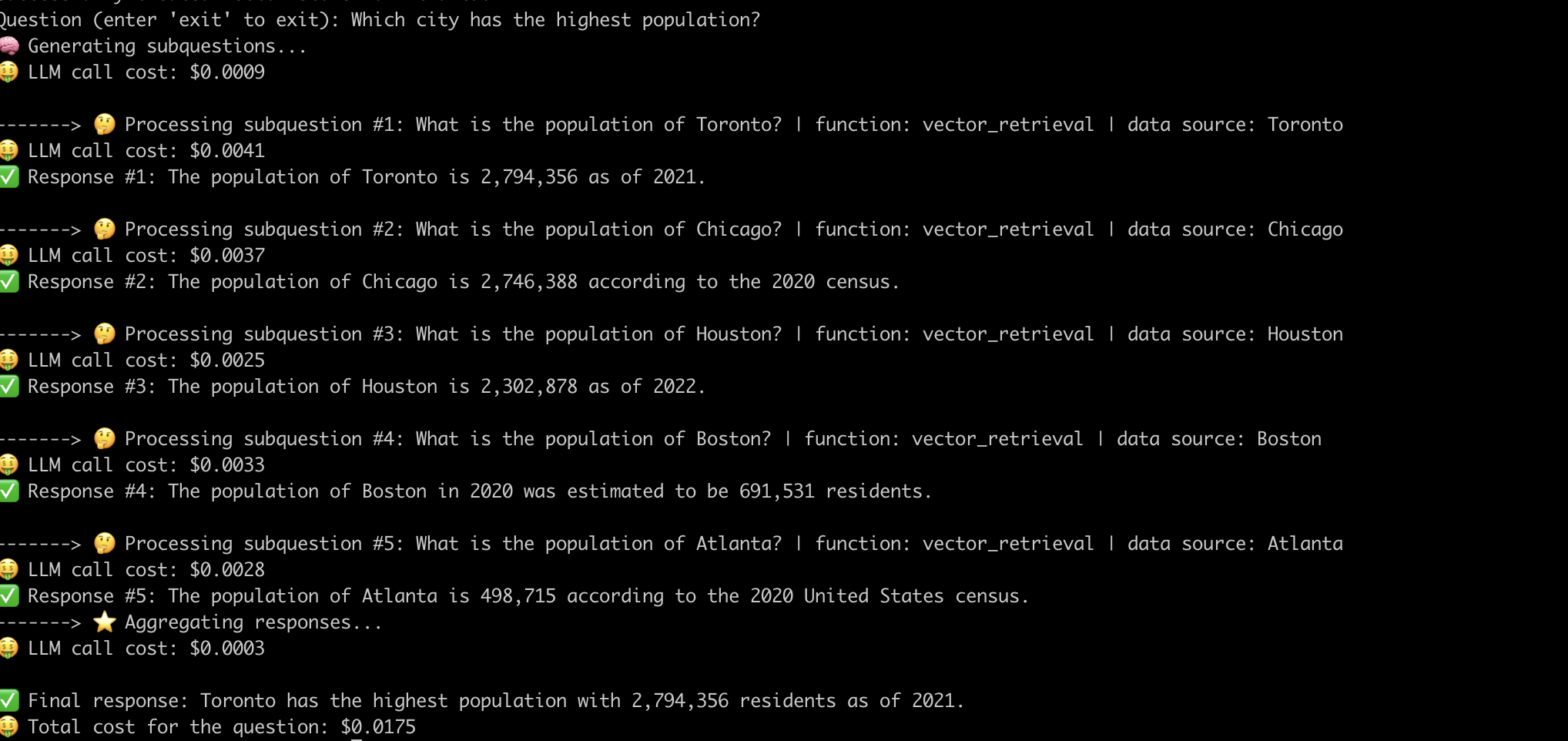
Nachdem wir die inneren Funktionsweise fortgeschrittener Rag -Pipelines entmystifiziert haben, lassen Sie uns die damit verbundenen Herausforderungen untersuchen.
Wir mussten erhebliche Anstrengungen unternommen, um die Pipeline für jede Frage zum Laufen zu bringen. Dies ist eine bedeutende Herausforderung für den Aufbau robuster Systeme.
Um dieses Verhalten zu überprüfen, haben wir das Beispiel mit der Lamaindex-Sub-Frage-Abfrage-Engine implementiert. In Übereinstimmung mit unseren Beobachtungen erzeugt das System häufig die falschen Unterfragen und verwendet auch die falsche Abruffunktion für die Unterfragen, wie unten gezeigt.

summary_tool ) im Vergleich zum vector_tool zu 3x höheren Kosten und generiert gleichzeitig eine falsche Antwort.Fortgeschrittene Rag-Pipelines, die von LLMs angetrieben werden, haben Fragen-Antworten revolutioniert. Wie wir gesehen haben, sind diese Pipelines jedoch keine schlüsselfertigen Lösungen. Unter der Motorhaube verlassen sich sie auf sorgfältig konstante Schablonen und mehrere gekettete LLM -Anrufe. Wie in dieser EVADB-Anwendung dargestellt, können diese Pipelines in ihrer Kostendynamik fragesensitiv, spröde und undurchsichtig sein. Das Verständnis dieser Feinheiten ist der Schlüssel, um ihr volles Potenzial zu nutzen und den Weg für robustere und effizientere Systeme in der Zukunft zu ebnen.


