rag demystified
1.0.0
Os pipelines de geração de recuperação de recuperação (RAG) alimentados por grandes modelos de idiomas (LLMS) estão ganhando popularidade para criar sistemas de atendimento de perguntas de ponta a ponta. Estruturas como Llamaindex e Haystack fizeram um progresso significativo para facilitar o uso de pipelines de rag. Embora essas estruturas forneçam excelentes abstrações para a criação de dutos avançados, eles o fazem com o custo da transparência. Do ponto de vista do usuário, não é prontamente aparente o que está acontecendo sob o capô, principalmente quando surgem erros ou inconsistências.
Nesta aplicação do EVADB, lançaremos luz sobre o funcionamento interno de oleodutos avançados, examinando a mecânica, as limitações e os custos que geralmente permanecem opacos.

Lhama trabalhando em um laptop ?
Se você quiser pular direto, use os seguintes comandos para executar o aplicativo:
pip install -r requirements.txt
echo OPENAI_API_KEY='yourkey' > .env
python complex_qa.py
A geração de recuperação de recuperação (RAG) é um paradigma de IA de ponta para a resposta de perguntas baseadas em LLM. Um pipeline RAG normalmente contém:
Data Warehouse - Uma coleção de fontes de dados (por exemplo, documentos, tabelas etc.) que contêm informações relevantes para a tarefa de resposta a perguntas.
Recuperação de vetores - Dada uma pergunta, encontre os principais shungs de dados mais semelhantes à pergunta. Isso é feito usando uma loja de vetores (por exemplo, FAISS).
Geração de respostas - Dados os principais Kes de dados mais semelhantes, geram uma resposta usando um modelo de idioma grande (por exemplo, GPT -4).
RAG fornece duas vantagens principais sobre a resposta de perguntas tradicionais baseadas em LLM:
Informações atualizadas -o data warehouse pode ser atualizado em tempo real, portanto as informações estão sempre atualizadas.
Rastreamento de origem - RAG fornece rastreabilidade clara, permitindo que os usuários identifiquem as fontes de informação, o que é crucial para verificação de precisão e atenuar as alucinações LLM.
Para permitir a resposta de perguntas mais complexas, estruturas recentes de IA como o Llamaindex introduziram abstrações mais avançadas, como o motor de consulta Sub-Perq.
Neste aplicativo, desmistificaremos pipelines de raio sofisticados usando o mecanismo de consulta Sub-perguntas como exemplo. Examinaremos o funcionamento interno do mecanismo de consulta de sub-perguntas e simplificará as abstrações em seus componentes principais. Também identificaremos alguns desafios associados a pipelines avançados de RAG.
Um data warehouse é uma coleção de fontes de dados (por exemplo, documentos, tabelas etc.) que contêm informações relevantes para a tarefa de resposta a perguntas.
Neste exemplo, usaremos um data warehouse simples contendo vários artigos da Wikipedia para diferentes cidades populares, inspiradas no Caso de Uso Ilustrativo da Llamaindex. O wiki de cada cidade é uma fonte de dados separada. Observe que, por simplicidade, limitamos o tamanho de cada documento a se encaixar no limite de contexto LLM.
Nosso objetivo é construir um sistema que possa responder a perguntas como:
Como você pode ver, as perguntas podem ser questões simples de factóides/resumo em uma única fonte de dados (Q1/Q2) ou questões complexas de factoid/resumo sobre várias fontes de dados (Q3).
Temos os seguintes métodos de recuperação à nossa disposição:
Recuperação de vetores - dada uma pergunta e uma fonte de dados, gerar uma resposta LLM usando os principais pedaços de dados mais semelhantes da pergunta da fonte de dados como o contexto. Utilizamos o índice de vetores FAISS do EVADB para recuperação de vetores. No entanto, os conceitos são aplicáveis a qualquer índice vetorial.
Resumo Recuperação - Dada uma pergunta de resumo e uma fonte de dados, gerar uma resposta LLM usando toda a fonte de dados como contexto.
Nosso insight principal é que cada componente em um pipeline avançado de RAG é alimentado por uma única chamada LLM. Todo o pipeline é uma série de chamadas de LLM com modelos de prompt cuidadosamente criados. Esses modelos imediatos são o molho secreto que permite que os dutos avançados de RAG realizem tarefas complexas.
De fato, qualquer pipeline avançado de RAG pode ser dividido em uma série de chamadas individuais de LLM que seguem um padrão de entrada universal:

onde:
Agora, ilustramos esse princípio examinando o funcionamento interno do mecanismo de consulta Sub-Question.
O mecanismo de consulta Sub-perguntas deve executar três tarefas:
Vamos examinar cada tarefa em detalhes.
Nosso objetivo é dividir uma pergunta complexa em um conjunto de sub-perguntas, enquanto identifica a fonte de dados e a função de recuperação apropriada para cada sub-perguntas. Por exemplo, a pergunta "Qual cidade tem a população mais alta?" é dividido em cinco sub-perguntas, uma para cada cidade, da forma "Qual é a população de {City}?". A fonte de dados para cada sub-pergunta deve ser o wiki da cidade correspondente, e a função de recuperação deve ser uma recuperação de vetores.
À primeira vista, isso parece uma tarefa assustadora. Especificamente, precisamos responder às seguintes perguntas:
Notavelmente, a resposta para todas as três perguntas é a mesma - uma única chamada LLM! Todo o mecanismo de consulta de sub-perguntas é alimentado por uma única chamada LLM com um modelo de prompt cuidadosamente criado. Vamos chamar esse modelo de modelo de prompt de sub-perguntas .
-- Sub-question Prompt Template --
"""
You are an AI assistant that specializes in breaking down complex questions into simpler, manageable sub-questions.
When presented with a complex user question, your role is to generate a list of sub-questions that, when answered, will comprehensively address the original question.
You have at your disposal a pre-defined set of functions and data sources to utilize in answering each sub-question.
If a user question is straightforward, your task is to return the original question, identifying the appropriate function and data source to use for its solution.
Please remember that you are limited to the provided functions and data sources, and that each sub-question should be a full question that can be answered using a single function and a single data source.
"""
O contexto para a chamada LLM são os nomes das fontes de dados e as funções disponíveis para o sistema. A questão é a questão do usuário. O LLM gera uma lista de sub-perguntas, cada uma com uma função e uma fonte de dados.
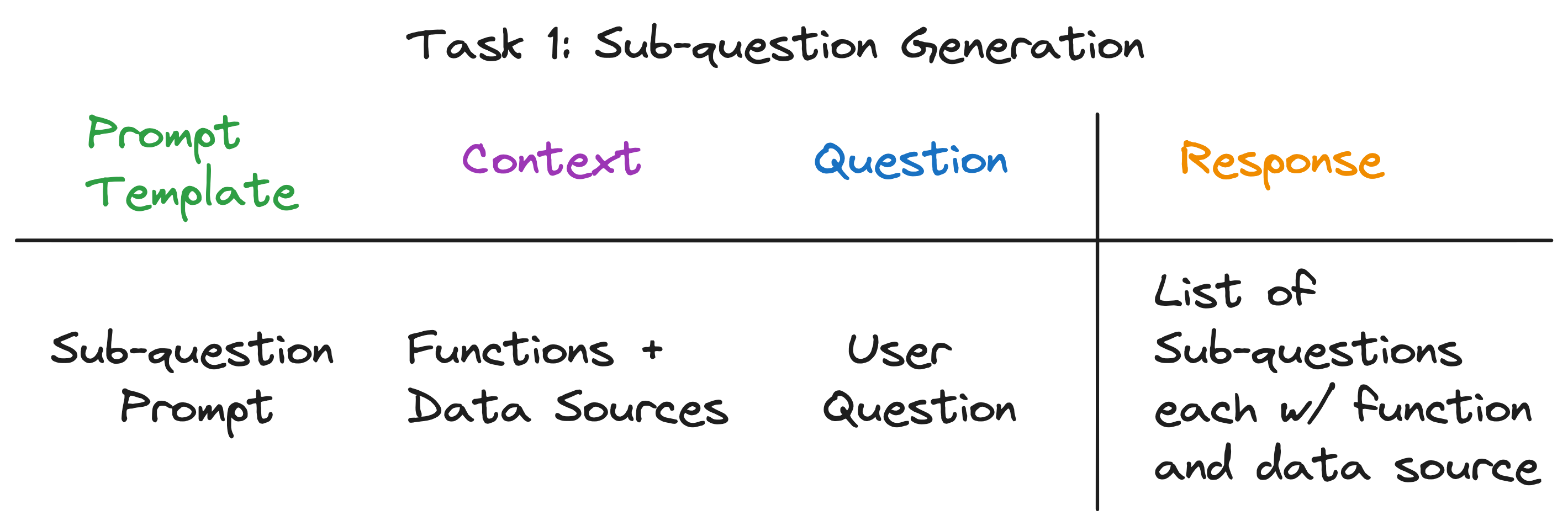
Para as três perguntas de exemplo, o LLM retorna a seguinte saída:
| Pergunta | Subquestões | Método de recuperação | Fonte de dados |
|---|---|---|---|
| "Qual é a população de Chicago?" | "Qual é a população de Chicago?" | Recuperação de vetores | Chicago |
| "Dê -me um resumo dos aspectos positivos de Atlanta." | "Dê -me um resumo dos aspectos positivos de Atlanta." | Resumo Recuperação | Atlanta |
| "Qual cidade tem a população mais alta?" | "Qual é a população de Toronto?" | Recuperação de vetores | Toronto |
| "Qual é a população de Chicago?" | Recuperação de vetores | Chicago | |
| "Qual é a população de Houston?" | Recuperação de vetores | Houston | |
| "Qual é a população de Boston?" | Recuperação de vetores | Boston | |
| "Qual é a população de Atlanta?" | Recuperação de vetores | Atlanta |
Para cada subestão, usamos a função de recuperação escolhida sobre a fonte de dados correspondente para recuperar as informações relevantes. Por exemplo, para a sub-pergunta "Qual é a população de Chicago?" , Usamos a recuperação de vetores sobre a fonte de dados de Chicago. Da mesma forma, para a sub-pergunta "me dê um resumo dos aspectos positivos de Atlanta". , Usamos a recuperação de resumo sobre a fonte de dados de Atlanta.
Para ambos os métodos de recuperação, usamos o mesmo modelo de prompt LLM. De fato, descobrimos que o prompt de pano popular de Langchainhub funciona muito bem para esta etapa.
-- RAG Prompt Template --
"""
You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.
Question: {question}
Context: {context}
Answer:
Ambos os métodos de recuperação diferem apenas no contexto usado para a chamada LLM. Para a recuperação de vetores, usamos os principais Kes de dados mais semelhantes à sub-pergunta como contexto. Para recuperação de resumo, usamos toda a fonte de dados como contexto.

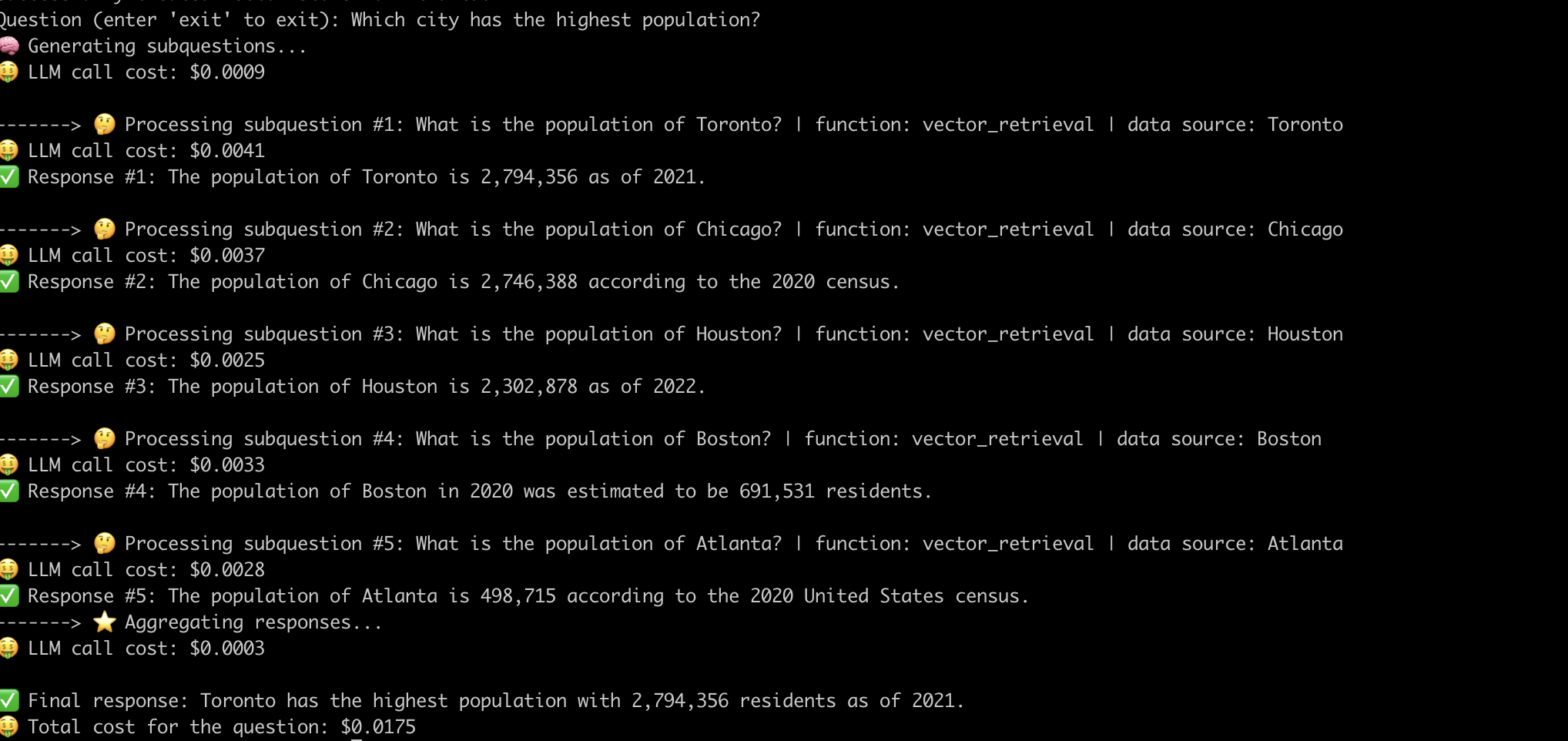
Esta é a etapa final que agrega as respostas das sub-perguntas em uma resposta final. Por exemplo, para a pergunta "Qual cidade tem a população mais alta?" , as sub-perguntas recuperam a população de cada cidade e, em seguida, a agregação de resposta encontra e devolve a cidade com a população mais alta. O prompt RAG também funciona muito bem para esta etapa.
O contexto para a chamada LLM é a lista de respostas das sub-perguntas. A questão é a pergunta original do usuário e o LLM gera uma resposta final.

Depois de desvendar as camadas de abstração, descobrimos o ingrediente secreto que alimenta o mecanismo de consulta da sub -pergunta - 4 tipos de chamadas de LLM, cada uma com modelos de prompt de diferentes diferentes perguntas. Isso se encaixa no padrão de entrada universal que identificamos anteriormente e está muito longe das abstrações complexas com as quais começamos. Para resumir: 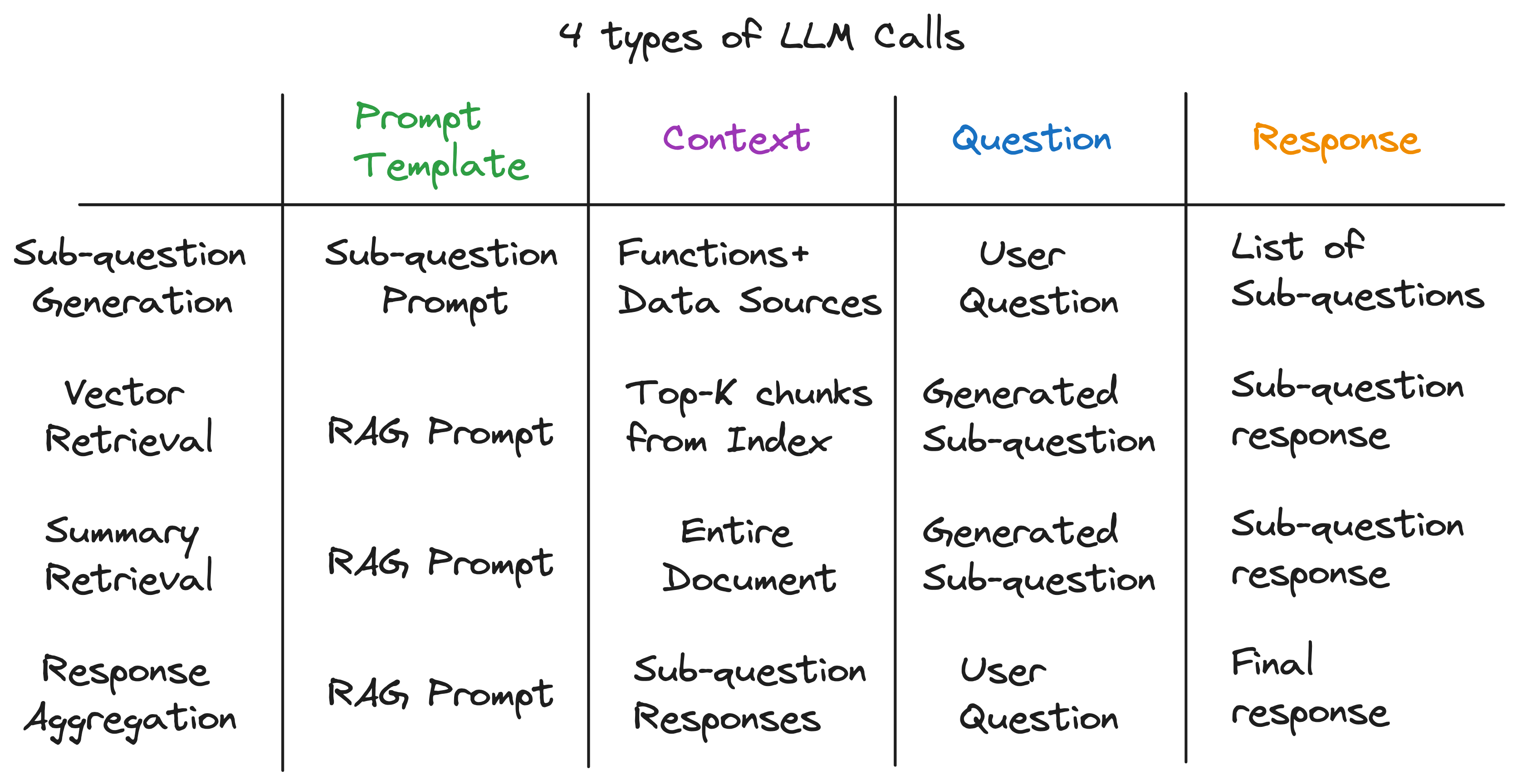
Para ver o pipeline completo em ação, execute os seguintes comandos:
pip install -r requirements.txt
echo OPENAI_API_KEY='yourkey' > .env
python complex_qa.py
Aqui está um exemplo do sistema que responde à pergunta "Qual cidade com a população mais alta?" .
Agora que desmistificamos o funcionamento interno de oleodutos avançados, vamos examinar os desafios associados a eles.
Tivemos que fazer um esforço significativo em engenharia imediata para fazer com que o pipeline funcione para cada pergunta. Este é um desafio significativo para a construção de sistemas robustos.
Para verificar esse comportamento, implementamos o exemplo usando o mecanismo de consulta Sub-Questão Llamaindex. Consistente com nossas observações, o sistema geralmente gera as sub-perguntas erradas e também usa a função de recuperação errada para as sub-perguntas, como mostrado abaixo.

summary_tool ) resulta em um custo 3x mais alto em comparação com o vector_tool , ao mesmo tempo em que gera uma resposta incorreta.Os pipelines avançados de RAG alimentados pelo LLMS revolucionaram os sistemas de resposta a perguntas. No entanto, como vimos, esses oleodutos não são soluções de mão. Sob o capô, eles contam com modelos de prompt cuidadosamente projetados e várias chamadas LLM encadeadas. Conforme ilustrado nesta aplicação do EVADB, esses dutos podem ser sensíveis à pergunta, quebradiça e opaca em sua dinâmica de custos. Compreender esses meandros é essencial para alavancar todo o seu potencial e abrir caminho para sistemas mais robustos e eficientes no futuro.


