rag demystified
1.0.0
LLMS (Lange-to-End Question Answering Systems를 구축하는 데 큰 인기를 얻고 있습니다. Llamaindex 및 Haystack과 같은 프레임 워크는 Rag 파이프 라인을 쉽게 사용할 수 있도록하는 데 큰 진전을 보였습니다. 이러한 프레임 워크는 고급 헝겊 파이프 라인을 구축하기위한 탁월한 추상화를 제공하지만 투명성 비용으로 그렇게합니다. 사용자의 관점에서 볼 때, 특히 오류 나 불일치가 발생할 때 후드 아래에서 무슨 일이 일어나고 있는지 쉽게 알 수 없습니다.
이 EVADB 애플리케이션에서는 종종 불투명하게 남아있는 역학, 제한 및 비용을 조사하여 고급 헝겊 파이프 라인의 내부 작업에 대해 밝히게됩니다.

랩톱에서 일하는 라마 ?
바로 이동하려면 다음 명령을 사용하여 응용 프로그램을 실행하십시오.
pip install -r requirements.txt
echo OPENAI_API_KEY='yourkey' > .env
python complex_qa.py
RAG (Resprive-Augmented Generation)는 LLM 기반 질문 답변을위한 최첨단 AI 패러다임입니다. 헝겊 파이프 라인에는 일반적으로 다음이 포함됩니다.
데이터웨어 하우스 - 질문 응답 과제와 관련된 정보를 포함하는 데이터 소스 (예 : 문서, 표 등).
벡터 검색 - 질문이 주어지면 질문에 가장 유사한 데이터 청크를 찾으십시오. 이것은 벡터 스토어 (예 : Faiss)를 사용하여 수행됩니다.
응답 생성 - 상위 K가 가장 유사한 데이터 청크를 감안할 때 큰 언어 모델 (예 : GPT -4)을 사용하여 응답을 생성합니다.
Rag는 전통적인 LLM 기반 질문에 대한 두 가지 주요 장점을 제공합니다.
최신 정보 -데이터웨어 하우스는 실시간으로 업데이트 될 수 있으므로 정보는 항상 최신입니다.
소스 추적 - RAG는 명확한 추적 성을 제공하여 사용자가 정보 소스를 식별 할 수있게 해주 며, 이는 정확도 검증 및 LLM 환각을 완화하는 데 중요합니다.
보다 복잡한 질문에 답할 수 있도록 Llamaindex와 같은 최근 AI 프레임 워크는 하위 질문 쿼리 엔진과 같은 고급 추상화를 도입했습니다.
이 애플리케이션에서는 하위 질문 쿼리 엔진을 예로 사용하여 정교한 래그 파이프 라인을 탈취 할 것입니다. 하위 질문 쿼리 엔진의 내부 작업을 검토하고 핵심 구성 요소에 대한 추상화를 단순화합니다. 우리는 또한 고급 래그 파이프 라인과 관련된 몇 가지 과제를 식별합니다.
데이터웨어 하우스는 질문 응답 작업과 관련된 정보를 포함하는 데이터 소스 (예 : 문서, 표 등)의 모음입니다.
이 예에서는 Llamaindex의 예시적인 사용 사례에서 영감을 얻은 다양한 인기 도시에 대한 여러 Wikipedia 기사가 포함 된 간단한 데이터웨어 하우스를 사용합니다. 각 도시의 위키는 별도의 데이터 소스입니다. 단순화를 위해 각 문서의 크기를 LLM 컨텍스트 제한에 맞게 제한합니다.
우리의 목표는 다음과 같은 질문에 답할 수있는 시스템을 구축하는 것입니다.
보시다시피, 질문은 단일 데이터 소스 (Q1/Q2) 또는 여러 데이터 소스 (Q3)에 대한 복잡한 사실/요약 질문에 대한 간단한 사실/요약 질문 일 수 있습니다.
우리는 우리의 처분에 다음과 같은 검색 방법을 가지고 있습니다.
벡터 검색 - 질문과 데이터 소스가 주어지면 컨텍스트로 데이터 소스에서 질문에 대한 Top -K 가장 유사한 데이터 청크를 사용하여 LLM 응답을 생성합니다. 우리는 벡터 검색을 위해 Evadb의 기성품 Faiss 벡터 인덱스를 사용합니다. 그러나 개념은 모든 벡터 인덱스에 적용 할 수 있습니다.
요약 검색 - 요약 질문과 데이터 소스가 주어지면 전체 데이터 소스를 컨텍스트로 사용하여 LLM 응답을 생성합니다.
우리의 주요 통찰력은 Advanced Rag 파이프 라인의 각 구성 요소가 단일 LLM 호출로 구동된다는 것입니다. 전체 파이프 라인은 신중하게 제작 된 프롬프트 템플릿이있는 일련의 LLM 통화입니다. 이 프롬프트 템플릿은 고급 헝겊 파이프 라인이 복잡한 작업을 수행 할 수있는 비밀 소스입니다.
실제로, 모든 고급 래그 파이프 라인은 범용 입력 패턴을 따르는 일련의 개별 LLM 통화로 분류 될 수 있습니다.

어디:
이제 우리는 하위 질문 쿼리 엔진의 내부 작업을 검사 하여이 원칙을 설명합니다.
하위 질문 쿼리 엔진은 세 가지 작업을 수행해야합니다.
각 작업을 자세히 살펴 보겠습니다.
우리의 목표는 복잡한 질문을 일련의 하위 질문으로 나누고 각 하위 질문에 대한 적절한 데이터 소스 및 검색 기능을 식별하는 것입니다. 예를 들어, "어느 도시가 인구가 가장 높은가?" "{city}의 인구는 무엇입니까?"형식의 각 도시마다 하나씩 5 개의 하위 질문으로 분류됩니다. 각 하위 질문에 대한 데이터 소스는 해당 도시의 위키이어야하며 검색 기능은 벡터 검색이어야합니다.
언뜻보기에 이것은 어려운 일처럼 보입니다. 특히 다음 질문에 답해야합니다.
놀랍게도, 세 가지 질문 모두에 대한 답은 동일합니다 - 단일 LLM 전화! 전체 하위 질문 쿼리 엔진은 신중하게 제작 된 프롬프트 템플릿이있는 단일 LLM 호출로 구동됩니다. 이 템플릿을 하위 질문 프롬프트 템플릿 이라고합시다.
-- Sub-question Prompt Template --
"""
You are an AI assistant that specializes in breaking down complex questions into simpler, manageable sub-questions.
When presented with a complex user question, your role is to generate a list of sub-questions that, when answered, will comprehensively address the original question.
You have at your disposal a pre-defined set of functions and data sources to utilize in answering each sub-question.
If a user question is straightforward, your task is to return the original question, identifying the appropriate function and data source to use for its solution.
Please remember that you are limited to the provided functions and data sources, and that each sub-question should be a full question that can be answered using a single function and a single data source.
"""
LLM 호출의 컨텍스트는 데이터 소스의 이름과 시스템에 사용 가능한 기능입니다. 문제는 사용자 질문입니다. LLM은 각각 함수 및 데이터 소스가있는 하위 질문 목록을 출력합니다.
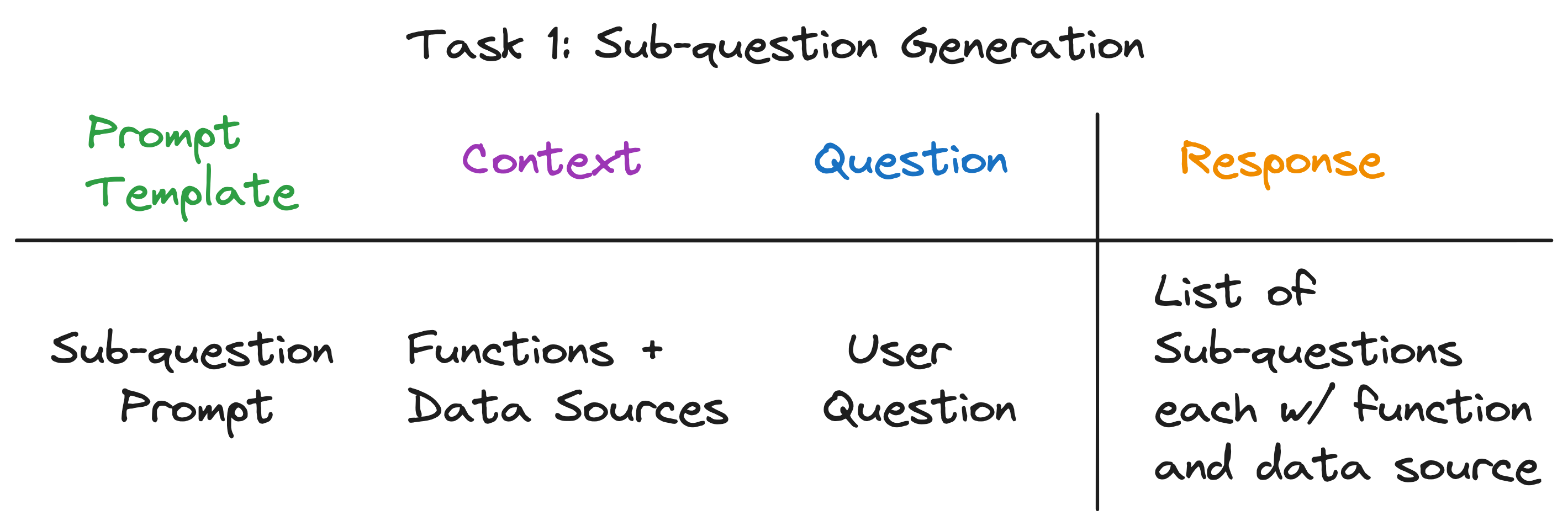
세 가지 예제 질문의 경우 LLM은 다음 출력을 반환합니다.
| 질문 | 하위 질문 | 검색 방법 | 데이터 소스 |
|---|---|---|---|
| "시카고 인구는 무엇입니까?" | "시카고 인구는 무엇입니까?" | 벡터 검색 | 시카고 |
| "애틀랜타의 긍정적 인 측면에 대한 요약을주십시오." | "애틀랜타의 긍정적 인 측면에 대한 요약을주십시오." | 요약 검색 | 애틀랜타 |
| "어느 도시가 인구가 가장 높습니까?" | "토론토 인구는 무엇입니까?" | 벡터 검색 | 토론토 |
| "시카고 인구는 무엇입니까?" | 벡터 검색 | 시카고 | |
| "휴스턴 인구는 무엇입니까?" | 벡터 검색 | 휴스턴 | |
| "보스턴 인구는 무엇입니까?" | 벡터 검색 | 보스턴 | |
| "애틀랜타 인구는 무엇입니까?" | 벡터 검색 | 애틀랜타 |
각 하위 질문에 대해 해당 데이터 소스를 통해 선택한 검색 기능을 사용하여 관련 정보를 검색합니다. 예를 들어, "시카고 인구는 무엇입니까?" , 우리는 시카고 데이터 소스를 통해 벡터 검색을 사용합니다. 마찬가지로, 하위 질문을 위해 "애틀랜타의 긍정적 인 측면에 대한 요약을주십시오." , 우리는 애틀랜타 데이터 소스에 대한 요약 검색을 사용합니다.
검색 방법 모두 동일한 LLM 프롬프트 템플릿을 사용합니다. 실제로, 우리는 Langchainhub의 인기있는 Rag 프롬프트 가이 단계에서 큰 박스를 사용한다는 것을 발견했습니다.
-- RAG Prompt Template --
"""
You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.
Question: {question}
Context: {context}
Answer:
두 검색 방법 모두 LLM 호출에 사용 된 컨텍스트에서만 다릅니다. 벡터 검색의 경우 컨텍스트로 가장 유사한 데이터 청크를 하위 질문에 사용합니다. 요약 검색을 위해 전체 데이터 소스를 컨텍스트로 사용합니다.

이것은 하위 질문의 응답을 최종 응답으로 집계하는 마지막 단계입니다. 예를 들어, "어느 도시가 인구가 가장 높은가?" , 하위 질문은 각 도시의 인구를 회수 한 다음 응답 집계는 인구가 가장 높은 도시를 발견하고 반환합니다. Rag 프롬프트는 이 단계에서도 훌륭합니다.
LLM 호출의 컨텍스트는 하위 질문의 응답 목록입니다. 문제는 원래 사용자 질문이며 LLM은 최종 응답을 출력합니다.

추상화 계층을 풀고 나면 서브 퀘스트 쿼리 엔진에 전원을 공급하는 비밀 성분을 발견했습니다. 이것은 우리가 이전에 완벽하게 식별 한 보편적 인 입력 패턴에 맞으며, 우리가 시작한 복잡한 추상화와는 거리가 멀다. 요약하려면 : 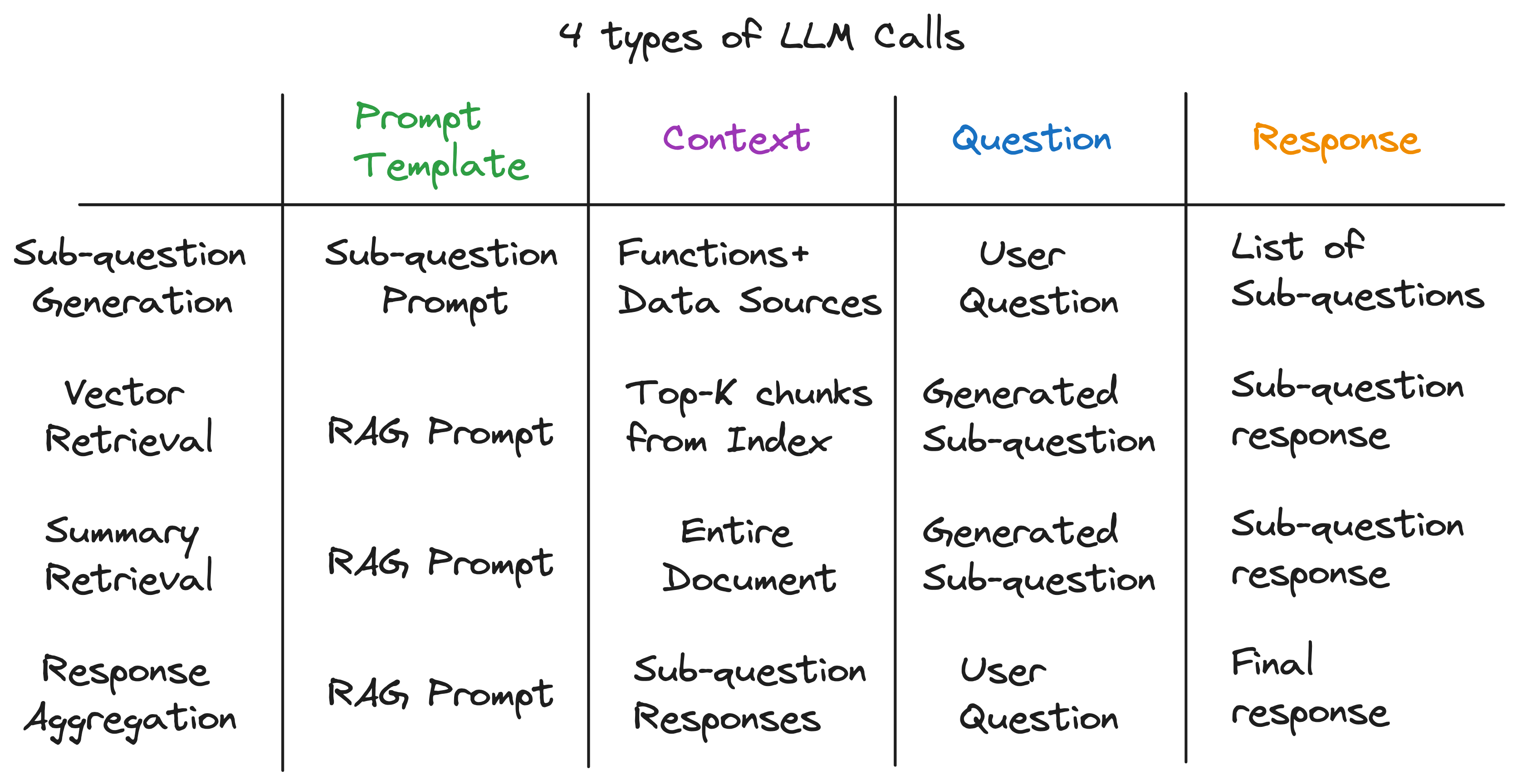
작동중인 전체 파이프 라인을 보려면 다음 명령을 실행하십시오.
pip install -r requirements.txt
echo OPENAI_API_KEY='yourkey' > .env
python complex_qa.py
다음은 "인구가 가장 높은 도시"라는 질문에 답하는 시스템의 예입니다. .
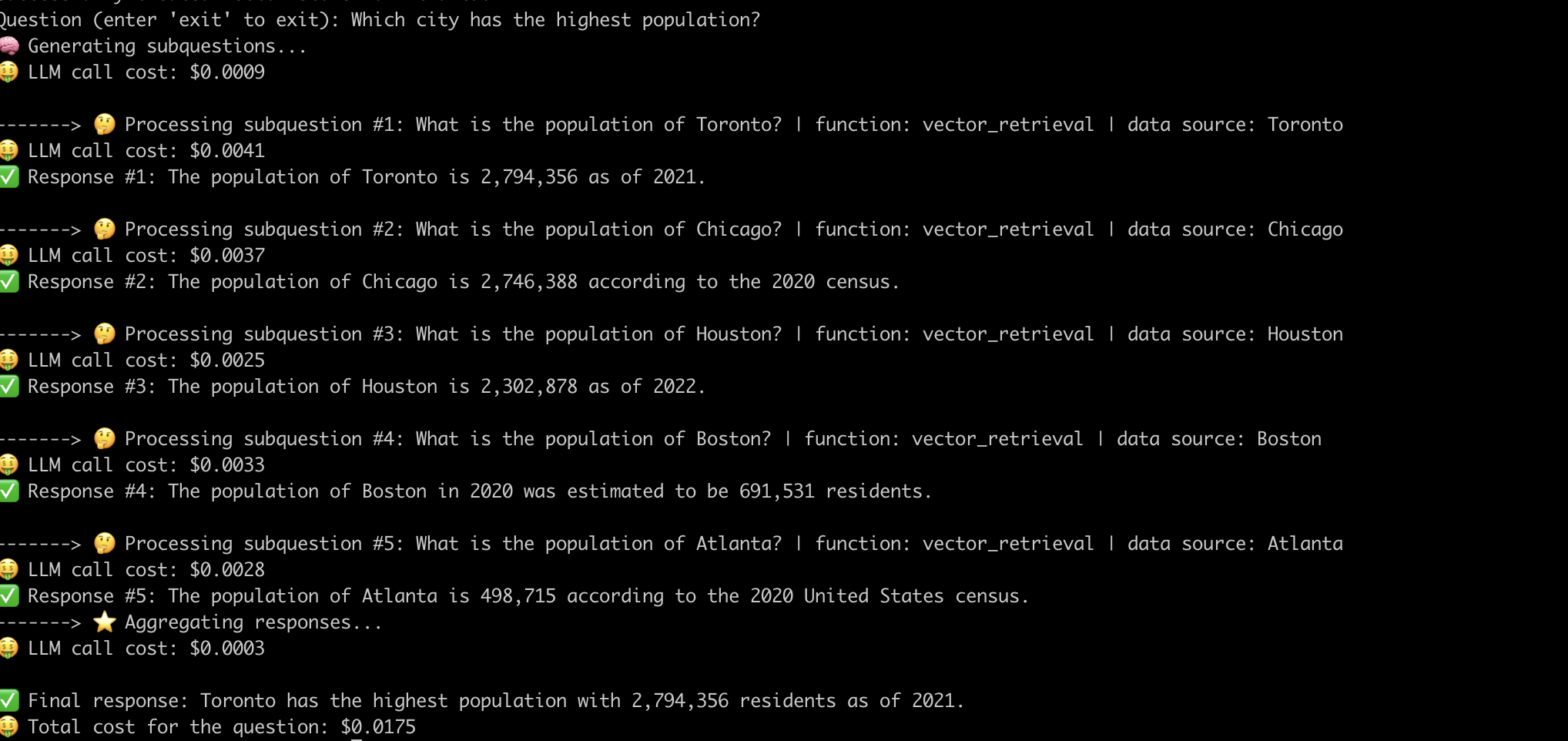
이제 우리는 고급 헝겊 파이프 라인의 내부 작업을 시연 했으므로 이와 관련된 문제를 살펴 보겠습니다.
파이프 라인이 각 질문에 대해 작동하도록 신속한 엔지니어링에 상당한 노력을 기울여야했습니다. 이것은 강력한 시스템을 구축하는 데 중요한 과제입니다.
이 동작을 확인하기 위해 Llamaindex 하위 질문 쿼리 엔진을 사용하여 예제를 구현했습니다. 우리의 관찰에 따라 시스템은 종종 잘못된 하위 질문을 생성하고 아래에 표시된 것처럼 하위 질문에 잘못된 검색 기능을 사용합니다.

summary_tool )에서 잘못된 모델 선택은 vector_tool 에 비해 3 배 높은 비용을 초래하면서 잘못된 응답을 생성합니다.LLM에 의해 구동되는 고급 래그 파이프 라인은 질문 분석 시스템에 혁명을 일으켰다. 그러나 우리가 보았 듯이 이러한 파이프 라인은 턴키 솔루션이 아닙니다. 후드 아래에서, 그들은 신중하게 설계된 프롬프트 템플릿과 여러 개의 체인 LLM 통화에 의존합니다. 이 EVADB 응용 프로그램에서 볼 수 있듯이,이 파이프 라인은 비용 역학에서 질문에 민감하고 부서지기 쉬우 며 불투명 할 수 있습니다. 이러한 복잡성을 이해하는 것은 잠재력을 최대한 활용하고 향후보다 강력하고 효율적인 시스템을위한 길을 열어주는 데 중요합니다.


