rag demystified
1.0.0
Поизводимые конвейеры (RAG) (RAG), работающие на крупных языковых моделях (LLMS), получают популярность для создания сквозных систем ответов на вопросы. Такие рамки, как Lmamaindex и Hay Stack, добились значительного прогресса в облегчении использования тряпичных трубопроводов. В то время как эти рамки обеспечивают отличные абстракции для создания передовых трубопроводов, они делают это за счет прозрачности. С точки зрения пользователя, не так очевидно, что происходит под капюшоном, особенно когда возникают ошибки или несоответствия.
В этом приложении Evadb мы прользим свет на внутреннюю работу передовых тряпичных трубопроводов, изучив механику, ограничения и затраты, которые часто остаются непрозрачными.

Лама работает на ноутбуке ?
Если вы хотите прыгнуть прямо, используйте следующие команды для запуска приложения:
pip install -r requirements.txt
echo OPENAI_API_KEY='yourkey' > .env
python complex_qa.py
Поигрывательный поколение (RAG)-это передовая парадигма AI для ответа на вопрос на основе LLM. Рэг -конвейер обычно содержит:
GANTHOUSE DATA - Сбор источников данных (например, документы, таблицы и т. Д.), Которые содержат информацию, относящуюся к задаче ответа на вопрос.
Вектор поиск - Учитывая вопрос, найдите наиболее похожие куски данных на вопрос. Это делается с использованием векторного магазина (например, Faiss).
Генерация ответов - Учитывая наиболее похожие куски данных, генерируйте ответ с использованием большой языковой модели (например, GPT -4).
Rag предоставляет два ключевых преимущества по сравнению с традиционным ответом на основание LLM:
Сообщенная информация -хранилище данных может быть обновлено в режиме реального времени, поэтому информация всегда актуальна.
Отслеживание источника - RAG обеспечивает четкую отслеживание, позволяя пользователям идентифицировать источники информации, что имеет решающее значение для проверки точности и смягчения галлюцинаций LLM.
Чтобы позволить ответить на более сложные вопросы, недавние фреймворки ИИ, такие как LlamainDex, представили более продвинутые абстракции, такие как двигатель запросов под вопросов.
В этом приложении мы демистифицируем сложные тряпичные трубопроводы, используя в качестве примера двигатель запросов подвесок. Мы рассмотрим внутреннюю работу двигателя запросов подвесения и упростим абстракции до их основных компонентов. Мы также определим некоторые проблемы, связанные с передовыми тряпными трубопроводами.
Хранилище данных - это набор источников данных (например, документы, таблицы и т. Д.), Которые содержат информацию, относящуюся к задаче ответа на вопрос.
В этом примере мы будем использовать простое хранилище данных, содержащее несколько статей Википедии для разных популярных городов, вдохновленных иллюстративным использованием LlamainDex. Вики каждого города является отдельным источником данных. Обратите внимание, что для простоты мы ограничиваем размер каждого документа, чтобы соответствовать пределу контекста LLM.
Наша цель - создать систему, которая может ответить на такие вопросы, как:
Как вы можете видеть, вопросы могут быть простыми вопросами фактического/суммирования по сравнению с одним источником данных (Q1/Q2) или сложными вопросами фактического/суммирования по нескольким источникам данных (Q3).
У нас есть следующие методы поиска в нашем распоряжении:
Вектор поиск - Учитывая вопрос и источник данных, генерируйте ответ LLM, используя наиболее похожие куски данных Top -K на вопрос из источника данных в качестве контекста. Мы используем готовый векторный индекс FAISS от EVADB для векторного поиска. Тем не менее, концепции применимы к любому векторному индексу.
Сводка поиска - Учитывая сводный вопрос и источник данных, генерируйте ответ LLM, используя весь источник данных в качестве контекста.
Наше ключевое понимание состоит в том, что каждый компонент в расширенном тряпичном трубопроводе питается одним вызовом LLM. Весь трубопровод представляет собой серию вызовов LLM с тщательно продуманными шаблонами. Эти быстрые шаблоны являются секретным соусом, который позволяет передовым тряпным трубопроводам выполнять сложные задачи.
Фактически, любой передовый тряпичный трубопровод может быть разбит на серию отдельных вызовов LLM, которые следуют универсальному шаблону ввода:

где:
Теперь мы иллюстрируем этот принцип, изучив внутреннюю работу двигателя запросов подвесок.
Двигатель запроса под вопросов должен выполнять три задачи:
Давайте подробно рассмотрим каждую задачу.
Наша цель состоит в том, чтобы разбить сложный вопрос на набор подводов, одновременно выявляя соответствующий источник данных и функцию поиска для каждого подразделения. Например, вопрос "в каком городе самое большое население?" Разбит на пять подвесков, по одному для каждого города, формы «Что такое население {Сити}?». Источником данных для каждой подвесности должен быть соответствующий городской вики, а функция поиска должна быть векторным поиском.
На первый взгляд, это кажется сложной задачей. В частности, нам нужно ответить на следующие вопросы:
Примечательно, что ответ на все три вопроса одинаков - один вызов LLM! Весь двигатель запроса подвески оснащен одним вызовом LLM с тщательно продуманным шаблоном приглашения. Давайте назовем этот шаблон шаблоном подсказок .
-- Sub-question Prompt Template --
"""
You are an AI assistant that specializes in breaking down complex questions into simpler, manageable sub-questions.
When presented with a complex user question, your role is to generate a list of sub-questions that, when answered, will comprehensively address the original question.
You have at your disposal a pre-defined set of functions and data sources to utilize in answering each sub-question.
If a user question is straightforward, your task is to return the original question, identifying the appropriate function and data source to use for its solution.
Please remember that you are limited to the provided functions and data sources, and that each sub-question should be a full question that can be answered using a single function and a single data source.
"""
Контекст для вызова LLM - это имена источников данных и функции, доступные для системы. Вопрос - вопрос пользователя. LLM выводит список подвесок, каждый с функцией и источником данных.
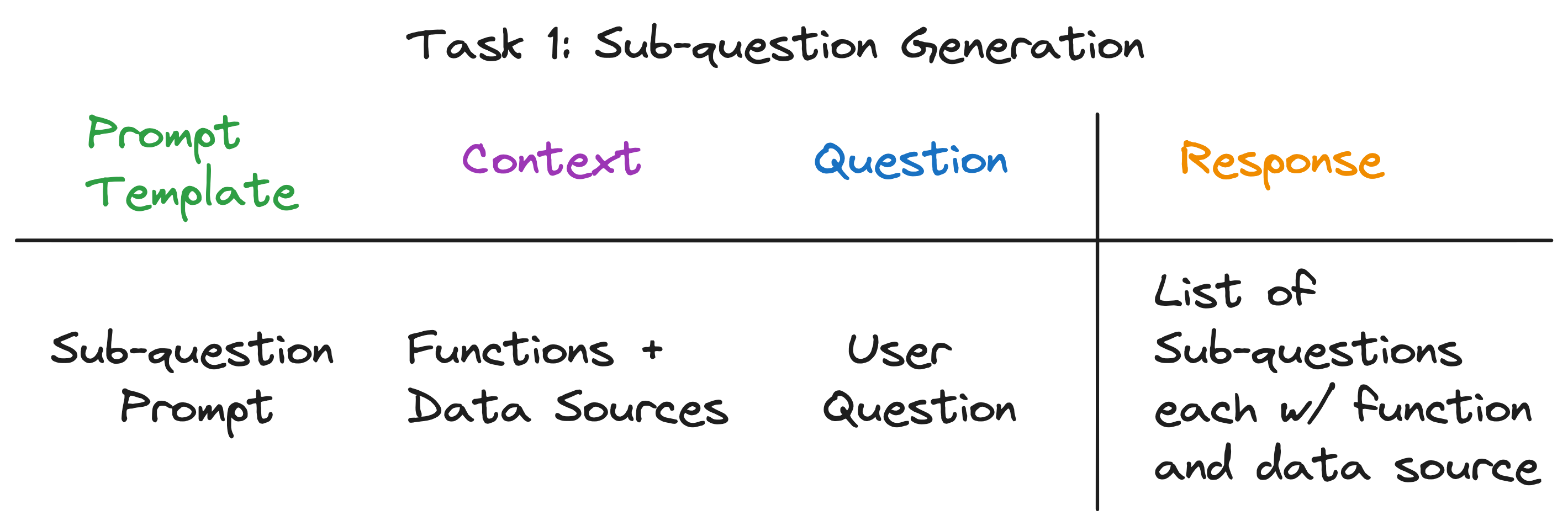
Для трех примеров вопросов LLM возвращает следующий вывод:
| Вопрос | Подпекания | Метод поиска | Источник данных |
|---|---|---|---|
| "Что такое население Чикаго?" | "Что такое население Чикаго?" | Вектор поиск | Чикаго |
| «Дайте мне краткое изложение позитивных аспектов Атланты». | «Дайте мне краткое изложение позитивных аспектов Атланты». | Сводка поиска | Атланта |
| "В каком городе самое большое население?" | "Что такое население Торонто?" | Вектор поиск | Торонто |
| "Что такое население Чикаго?" | Вектор поиск | Чикаго | |
| "Что такое население Хьюстона?" | Вектор поиск | Хьюстон | |
| "Что такое население Бостона?" | Вектор поиск | Бостон | |
| "Что такое население Атланты?" | Вектор поиск | Атланта |
Для каждой подвески мы используем выбранную функцию поиска по соответствующему источнику данных для извлечения соответствующей информации. Например, для подвесения "Что такое население Чикаго?" , мы используем векторный поиск по сравнению с источником данных в Чикаго. Точно так же для подвесения «дать мне краткое изложение положительных аспектов Атланты». , мы используем краткое извлечение по источнику данных в Атланте.
Для обоих методов поиска мы используем один и тот же шаблон быстрого приглашения LLM. На самом деле, мы обнаруживаем, что популярное подсказка из Langchainhub отлично работает на этом шаге.
-- RAG Prompt Template --
"""
You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.
Question: {question}
Context: {context}
Answer:
Оба метода поиска различаются только в контексте, используемом для вызова LLM. Для векторного поиска мы используем наиболее похожие куски данных в подвеске в качестве контекста. Для краткого извлечения мы используем весь источник данных в качестве контекста.

Это последний шаг, который объединяет ответы от подпотоков в окончательный ответ. Например, для вопроса "в каком городе самое большое население?" , подставки, забирают население каждого города, а затем агрегация реагирования находит и возвращает город с самым высоким населением. Подсказка RAG отлично подходит и для этого шага.
Контекст для вызова LLM-это список ответов из подпотоков. Вопрос - оригинальный вопрос пользователя, а LLM выводит окончательный ответ.

После раскрытия слоев абстракции мы обнаружили секретный ингредиент, питающий двигатель запросов подвесения - 4 типа LLM вызывает каждый с разным шаблоном, контекстом и вопросом. Это соответствует универсальному шаблону ввода, который мы идентифицировали ранее, и это далеко от сложных абстракций, с которых мы начали. Суммировать: 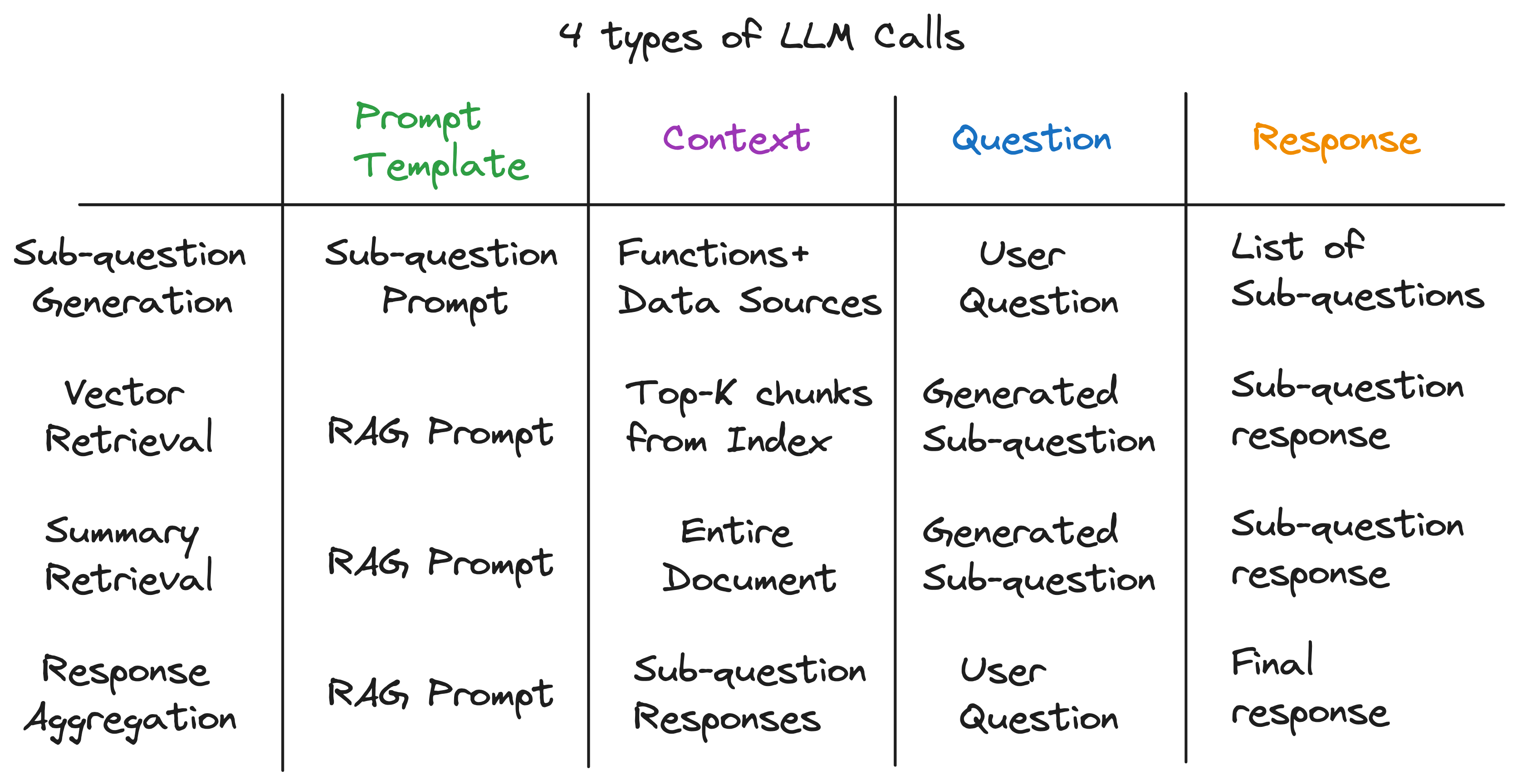
Чтобы увидеть полный трубопровод в действии, запустите следующие команды:
pip install -r requirements.txt
echo OPENAI_API_KEY='yourkey' > .env
python complex_qa.py
Вот пример того, как система отвечает на вопрос «Какой город с самым высоким населением?» Полем
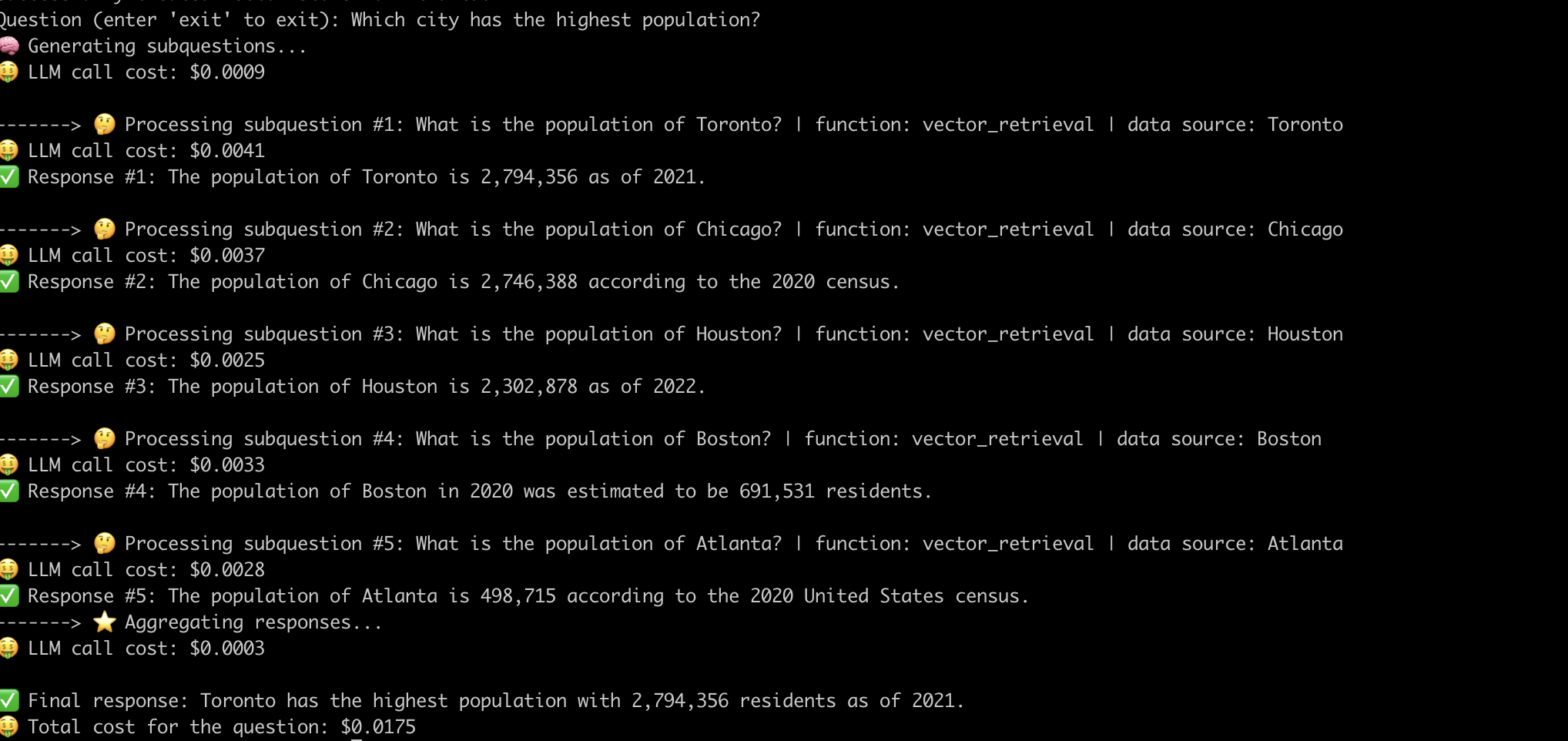
Теперь, когда мы демистифицировали внутреннюю работу передовых тряных трубопроводов, давайте рассмотрим проблемы, связанные с ними.
Нам пришлось приложить значительные усилия в быстрого разработки, чтобы заставить трубопровод работать для каждого вопроса. Это серьезная проблема для создания надежных систем.
Чтобы проверить это поведение, мы внедрили пример, используя двигатель запроса подставки LlamainDex. В соответствии с нашими наблюдениями, система часто генерирует неправильные подпоточные вопросы, а также использует неправильную функцию поиска для подводов, как показано ниже.

summary_tool ) приводит к 3 -кратному более высокой стоимости по сравнению с vector_tool , одновременно генерируя неправильный ответ.Усовершенствованные тряпичные трубопроводы, основанные на LLMS, произвели революцию в системах ответов на вопросы. Однако, как мы видели, эти трубопроводы не являются решениями под ключом. Под капотом они полагаются на тщательно разработанные шаблоны быстрого приглашения и несколько цепных вызовов LLM. Как показано в этом приложении Evadb, эти трубопроводы могут быть чувствительными к вопросам, хрупким и непрозрачным в их динамике затрат. Понимание этих тонкостей является ключом к тому, чтобы полностью использовать их потенциал и проложить путь для более надежных и эффективных систем в будущем.


