rag demystified
1.0.0
Las tuberías de generación de recuperación (RAG) generadas por modelos de idiomas grandes (LLM) están ganando popularidad para construir sistemas de respuesta de preguntas de extremo a extremo. Los marcos como Llamaindex y Haystack han hecho un progreso significativo para hacer que las tuberías de trapo sean fáciles de usar. Si bien estos marcos proporcionan excelentes abstracciones para construir tuberías de trapo avanzadas, lo hacen a costa de transparencia. Desde la perspectiva del usuario, no es evidente lo que está sucediendo debajo del capó, particularmente cuando surgen errores o inconsistencias.
En esta aplicación EVADB, arrojaremos luz sobre el funcionamiento interno de las tuberías avanzadas de RAG al examinar la mecánica, las limitaciones y los costos que a menudo permanecen opacos.

¿Llama trabajando en una computadora portátil ?
Si desea saltar directamente, use los siguientes comandos para ejecutar la aplicación:
pip install -r requirements.txt
echo OPENAI_API_KEY='yourkey' > .env
python complex_qa.py
La generación de recuperación aumentada (RAG) es un paradigma de IA de vanguardia para la respuesta de preguntas basadas en LLM. Una tubería de trapo generalmente contiene:
Data Warehouse : una recopilación de fuentes de datos (por ejemplo, documentos, tablas, etc.) que contienen información relevante para la tarea de respuesta de preguntas.
Recuperación de vectores : dada una pregunta, encuentre los k fragmentos de datos más similares a la pregunta. Esto se realiza utilizando una tienda vectorial (por ejemplo, FAISS).
Generación de respuestas : dados los k fragmentos de datos más similares, generan una respuesta utilizando un modelo de lenguaje grande (por ejemplo, GPT -4).
RAG proporciona dos ventajas clave sobre la respuesta tradicional de preguntas basadas en LLM:
Información actualizada : el almacén de datos se puede actualizar en tiempo real, por lo que la información siempre está actualizada.
Seguimiento de origen : el RAG proporciona una trazabilidad clara, lo que permite a los usuarios identificar las fuentes de información, lo cual es crucial para la verificación de precisión y la mitigación de alucinaciones de LLM.
Para permitir responder preguntas más complejas, los marcos de IA recientes como Llamaindex han introducido abstracciones más avanzadas, como el motor de consulta de subcuestión.
En esta aplicación, desmitificaremos las tuberías de trapo sofisticadas utilizando el motor de consulta de subconsección como ejemplo. Examinaremos el funcionamiento interno del motor de consulta de subcuestiones y simplificaremos las abstracciones a sus componentes centrales. También identificaremos algunos desafíos asociados con las tuberías avanzadas de RAG.
Un almacén de datos es una colección de fuentes de datos (por ejemplo, documentos, tablas, etc.) que contienen información relevante para la tarea de respuesta de preguntas.
En este ejemplo, utilizaremos un almacén de datos simple que contenga múltiples artículos de Wikipedia para diferentes ciudades populares, inspiradas en el caso de uso ilustrativo de Llamaindex. El wiki de cada ciudad es una fuente de datos separada. Tenga en cuenta que para simplificar, limitamos el tamaño de cada documento para que se ajuste dentro del límite de contexto de LLM.
Nuestro objetivo es construir un sistema que pueda responder preguntas como:
Como puede ver, las preguntas pueden ser preguntas simples de datos/resumen en una sola fuente de datos (Q1/Q2) o preguntas complejas de factoid/resumen en múltiples fuentes de datos (Q3).
Tenemos los siguientes métodos de recuperación a nuestra disposición:
Recuperación de vectores : dada una pregunta y una fuente de datos, genere una respuesta LLM utilizando los fragmentos de datos más similares de Top -K a la pregunta de la fuente de datos como el contexto. Utilizamos el índice de vectores Faiss estándar de EVADB para la recuperación de vectores. Sin embargo, los conceptos son aplicables a cualquier índice vectorial.
Recuperación de resumen : dada una pregunta resumida y una fuente de datos, genere una respuesta LLM utilizando toda la fuente de datos como contexto.
Nuestra información clave es que cada componente en una tubería de trapo avanzada funciona con una sola llamada LLM. Toda la tubería es una serie de llamadas de LLM con plantillas de inmediato cuidadosamente elaboradas. Estas plantillas de inmediato son la salsa secreta que permite que las tuberías avanzadas de RAG realicen tareas complejas.
De hecho, cualquier oleoducto avanzada se puede dividir en una serie de llamadas de LLM individuales que siguen un patrón de entrada universal:

dónde:
Ahora, ilustramos este principio examinando el funcionamiento interno del motor de consulta de subconsección.
El motor de consulta de subconsección tiene que realizar tres tareas:
Examinemos cada tarea en detalle.
Nuestro objetivo es dividir una pregunta compleja en un conjunto de subcuestiones, al tiempo que identifica la fuente de datos apropiada y la función de recuperación para cada subcuestión. Por ejemplo, la pregunta "¿Qué ciudad tiene la población más alta?" se descompone en cinco subcuestiones, una para cada ciudad, de la forma "¿Cuál es la población de {ciudad}?". La fuente de datos para cada subcuestión debe ser el wiki de la ciudad correspondiente, y la función de recuperación debe ser la recuperación de vectores.
A primera vista, esto parece una tarea desalentadora. Específicamente, necesitamos responder las siguientes preguntas:
Sorprendentemente, la respuesta a las tres preguntas es la misma: ¡una sola llamada LLM! Todo el motor de consulta de subconsección está alimentado por una sola llamada LLM con una plantilla de inmediato cuidadosamente elaborada. Llamemos a esta plantilla la plantilla de solicitud de subconsección .
-- Sub-question Prompt Template --
"""
You are an AI assistant that specializes in breaking down complex questions into simpler, manageable sub-questions.
When presented with a complex user question, your role is to generate a list of sub-questions that, when answered, will comprehensively address the original question.
You have at your disposal a pre-defined set of functions and data sources to utilize in answering each sub-question.
If a user question is straightforward, your task is to return the original question, identifying the appropriate function and data source to use for its solution.
Please remember that you are limited to the provided functions and data sources, and that each sub-question should be a full question that can be answered using a single function and a single data source.
"""
El contexto para la llamada LLM son los nombres de las fuentes de datos y las funciones disponibles para el sistema. La pregunta es la pregunta del usuario. El LLM emite una lista de subcuestiones, cada una con una función y una fuente de datos.
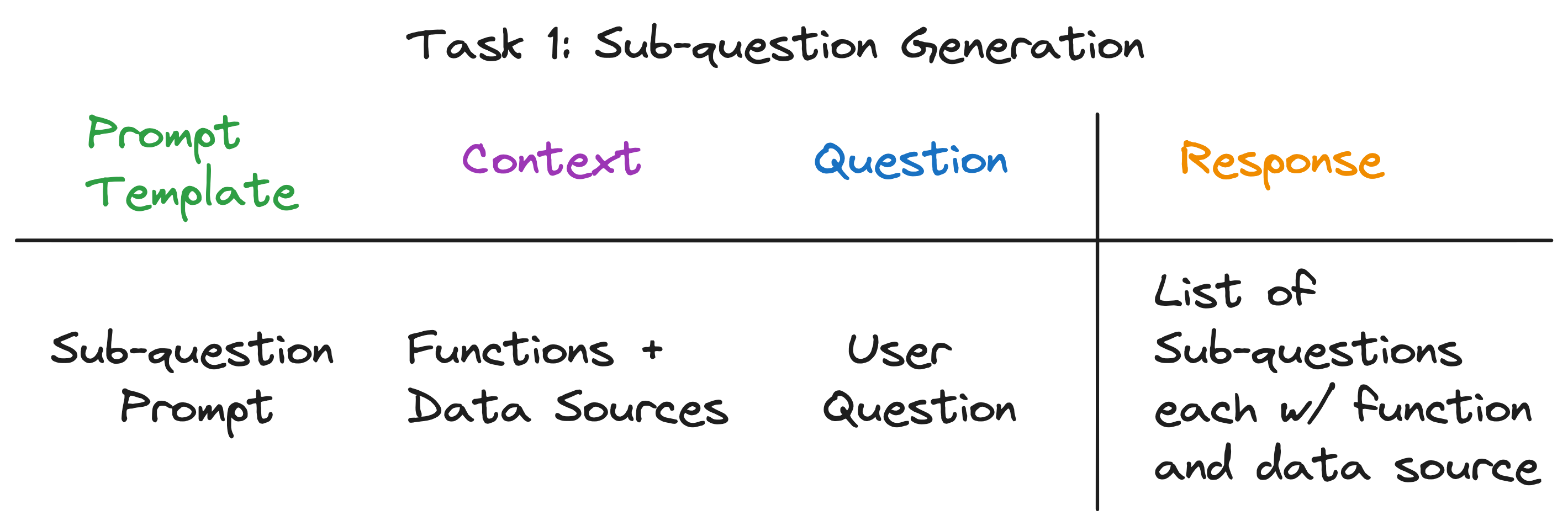
Para las tres preguntas de ejemplo, el LLM devuelve la siguiente salida:
| Pregunta | Subcondaciones | Método de recuperación | Fuente de datos |
|---|---|---|---|
| "¿Cuál es la población de Chicago?" | "¿Cuál es la población de Chicago?" | recuperación de vectores | Chicago |
| "Dame un resumen de los aspectos positivos de Atlanta". | "Dame un resumen de los aspectos positivos de Atlanta". | recuperación de resumen | Atlanta |
| "¿Qué ciudad tiene la población más alta?" | "¿Cuál es la población de Toronto?" | recuperación de vectores | Toronto |
| "¿Cuál es la población de Chicago?" | recuperación de vectores | Chicago | |
| "¿Cuál es la población de Houston?" | recuperación de vectores | Houston | |
| "¿Cuál es la población de Boston?" | recuperación de vectores | Bostón | |
| "¿Cuál es la población de Atlanta?" | recuperación de vectores | Atlanta |
Para cada subcuestión, utilizamos la función de recuperación elegida sobre la fuente de datos correspondiente para recuperar la información relevante. Por ejemplo, para la subcuestión "¿Cuál es la población de Chicago?" , utilizamos la recuperación de vectores sobre la fuente de datos de Chicago. Del mismo modo, para la subcalla "dame un resumen de los aspectos positivos de Atlanta". , utilizamos la recuperación de resumen sobre la fuente de datos de Atlanta.
Para ambos métodos de recuperación, utilizamos la misma plantilla de solicitud de LLM. De hecho, encontramos que el popular mensaje de trapo de Langchainhub funciona muy bien fuera de la caja para este paso.
-- RAG Prompt Template --
"""
You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.
Question: {question}
Context: {context}
Answer:
Ambos métodos de recuperación solo difieren en el contexto utilizado para la llamada LLM. Para la recuperación de vectores, utilizamos los topetos de datos más similares a la subcuestión como contexto. Para la recuperación de resumen, utilizamos toda la fuente de datos como contexto.

Este es el paso final que agrega las respuestas de las subcuestiones a una respuesta final. Por ejemplo, para la pregunta "¿Qué ciudad tiene la población más alta?" , Las subcoscciones recuperan la población de cada ciudad y luego la agregación de respuesta encuentra y devuelve la ciudad con la población más alta. El mensaje de trapo funciona muy bien para este paso también.
El contexto para la llamada LLM es la lista de respuestas de las subcuestiones. La pregunta es la pregunta del usuario original y el LLM emite una respuesta final.

Después de desentrañar las capas de abstracción, descubrimos el ingrediente secreto que alimenta el motor de consulta de subcuestión: 4 tipos de llamadas LLM con una plantilla de inmediato, contexto y una pregunta. Esto se ajusta al patrón de entrada universal que identificamos anteriormente perfectamente, y está muy lejos de las complejas abstracciones con las que comenzamos. Para resumir: 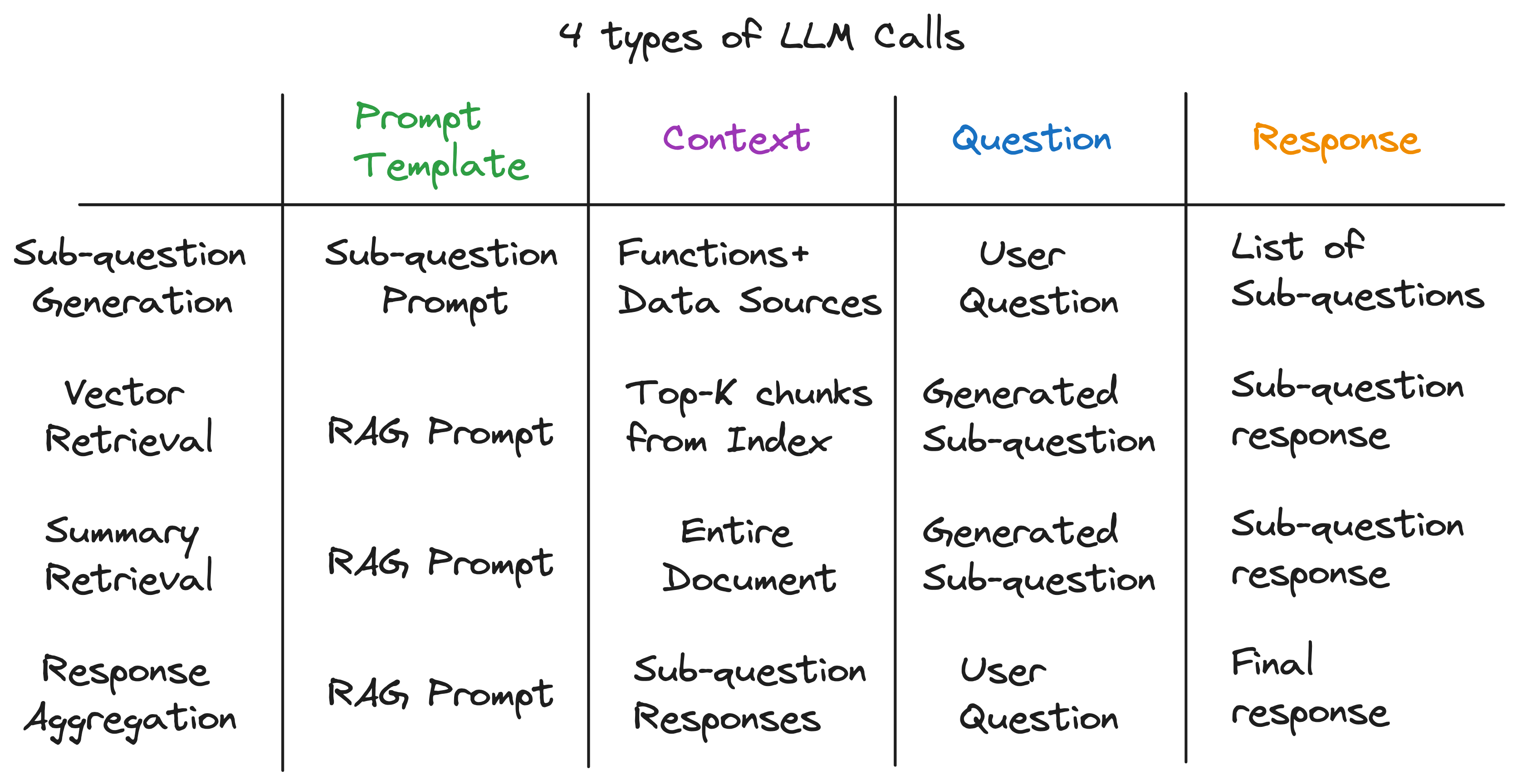
Para ver la tubería completa en acción, ejecute los siguientes comandos:
pip install -r requirements.txt
echo OPENAI_API_KEY='yourkey' > .env
python complex_qa.py
Aquí hay un ejemplo del sistema que responde a la pregunta "¿Qué ciudad con la población más alta?" .
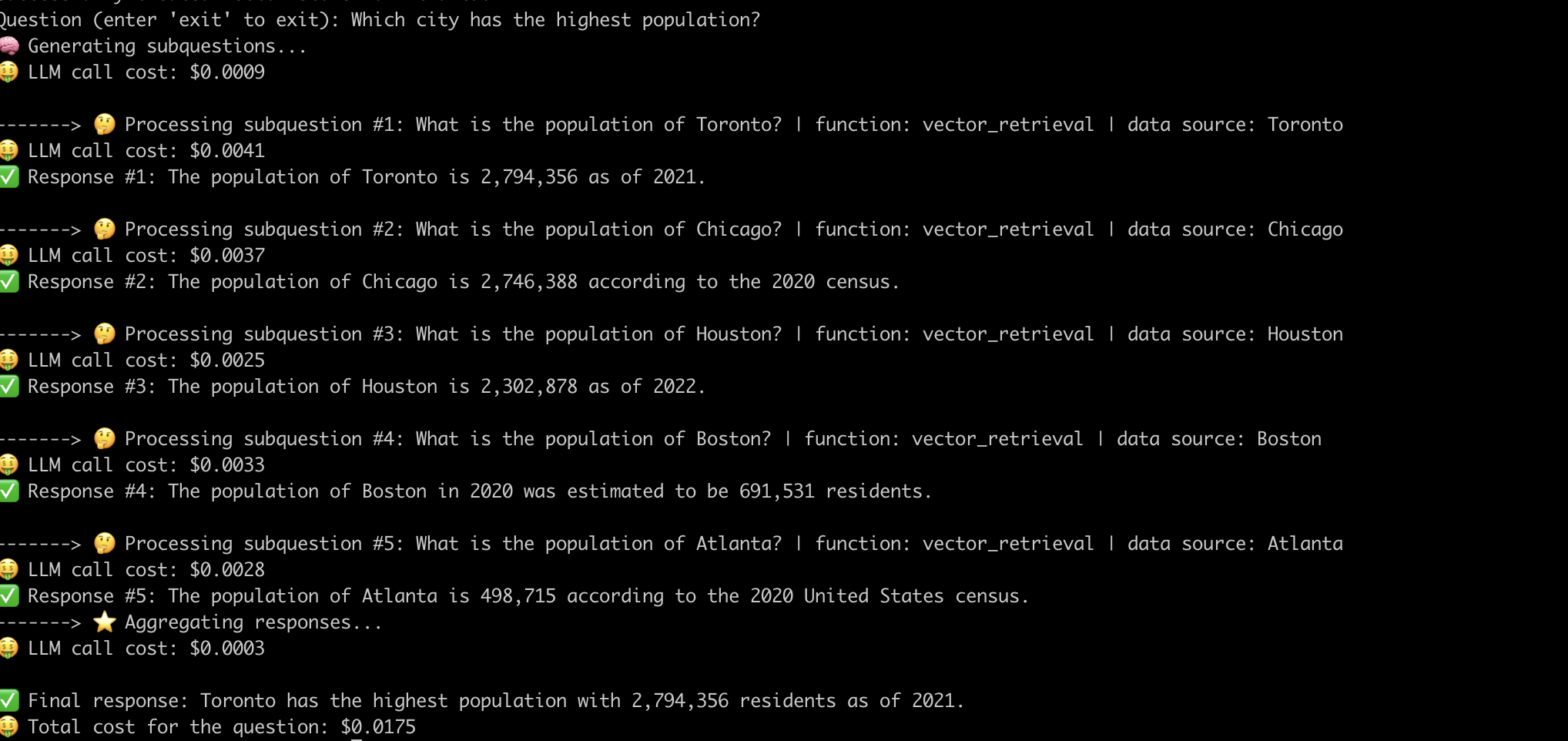
Ahora que hemos desmitificado el funcionamiento interno de las tuberías avanzadas de trapo, examinemos los desafíos asociados con ellos.
Tuvimos que hacer un esfuerzo significativo para una ingeniería rápida para que la tubería funcione para cada pregunta. Este es un desafío importante para construir sistemas robustos.
Para verificar este comportamiento, implementamos el ejemplo utilizando el motor de consulta de subcuestiones de Llamaindex. De acuerdo con nuestras observaciones, el sistema a menudo genera las subcuestiones incorrectas y también utiliza la función de recuperación incorrecta para las subcuestiones, como se muestra a continuación.

summary_tool ) da como resultado un costo 3x más alto en comparación con el vector_tool al tiempo que genera una respuesta incorrecta.Las tuberías avanzadas de RAG impulsadas por LLMS han revolucionado los sistemas de preguntas sobre la pregunta. Sin embargo, como hemos visto, estas tuberías no son soluciones llave en mano. Debajo del capó, confían en plantillas de inmediato con cuidadosamente diseñadas y múltiples llamadas LLM encadenadas. Como se ilustra en esta aplicación EVADB, estas tuberías pueden ser sensibles a las preguntas, quebradizas y opacas en su dinámica de costos. Comprender estas complejidades es clave para aprovechar todo su potencial y allanar el camino para sistemas más robustos y eficientes en el futuro.


