rag demystified
1.0.0
大規模な言語モデル(LLM)を搭載した検索された生成(RAG)パイプラインは、エンドツーエンドの質問回答システムを構築するために人気を博しています。 LlamaindexやHaystackなどのフレームワークは、RAGパイプラインを使いやすくすることに大きな進歩を遂げました。これらのフレームワークは、高度なラグパイプラインを構築するための優れた抽象化を提供しますが、透明性を犠牲にしてそうします。ユーザーの観点からは、特にエラーや矛盾が生じた場合、フードの下で何が起こっているのかはすぐにはわかりません。
このEVADBアプリケーションでは、しばしば不透明なままであるメカニズム、制限、コストを調べることにより、高度なRAGパイプラインの内側の仕組みに光を当てます。

ラップトップで作業しているラマ?
すぐにジャンプしたい場合は、次のコマンドを使用してアプリケーションを実行します。
pip install -r requirements.txt
echo OPENAI_API_KEY='yourkey' > .env
python complex_qa.py
検索された生成(RAG)は、LLMベースの質問応答の最先端のAIパラダイムです。通常、ぼろきれパイプラインには以下が含まれています。
データウェアハウス- 質問回答タスクに関連する情報を含むデータソース(ドキュメント、テーブルなど)のコレクション。
Vectorの検索- 質問が与えられた場合、TOP Kの最も類似したデータのチャンクを質問します。これは、ベクトルストア(例えば、FAISS)を使用して行われます。
応答生成- トップKの最も類似したデータチャンクを考えると、大規模な言語モデル(GPT -4など)を使用して応答を生成します。
RAGは、従来のLLMベースの質問応答よりも2つの重要な利点を提供します。
最新の情報- データウェアハウスはリアルタイムで更新できるため、情報は常に最新のものです。
ソーストラッキング-Ragは明確なトレーサビリティを提供し、ユーザーが情報源を特定できるようにします。これは、精度の検証とLLMの幻覚を軽減するために重要です。
より複雑な質問に答えるために、LlamainDexのような最近のAIフレームワークは、サブ質問エンジンなどのより高度な抽象化を導入しました。
このアプリケーションでは、例としてサブ質問エンジンを使用して、洗練されたラグパイプラインを分かりやすく説明します。サブ質問クエリエンジンの内側の仕組みを調べ、コアコンポーネントの抽象化を簡素化します。また、高度なRAGパイプラインに関連するいくつかの課題を特定します。
データウェアハウスは、質問に答えるタスクに関連する情報を含むデータソース(ドキュメント、表など)のコレクションです。
この例では、Llamaindexの説明的なユースケースに触発された、さまざまな人気のある都市の複数のウィキペディア記事を含む単純なデータウェアハウスを使用します。各都市のwikiは別のデータソースです。簡単にするために、各ドキュメントのサイズをLLMコンテキスト制限内に収めるように制限することに注意してください。
私たちの目標は、次のような質問に答えることができるシステムを構築することです。
ご覧のとおり、質問は、単一のデータソース(Q1/Q2)を介した単純なファクトイド/要約の質問または複数のデータソース(Q3)に対する複雑なファクトイド/要約の質問です。
次の検索方法があります。
ベクトル検索- 質問とデータソースを指定して、TOP -Kの最も類似したデータチャンクを使用してLLM応答を生成します。 Vector検索のために、EVADBの既製のFAISSベクターインデックスを使用します。ただし、概念は任意のベクトルインデックスに適用できます。
概要検索- 概要の質問とデータソースを指定すると、コンテキストとしてデータソース全体を使用してLLM応答を生成します。
私たちの重要な洞察は、高度なRAGパイプラインの各コンポーネントが単一のLLMコールで駆動されていることです。パイプライン全体は、慎重に作成されたプロンプトテンプレートを備えた一連のLLMコールです。これらのプロンプトテンプレートは、高度なRAGパイプラインが複雑なタスクを実行できるようにする秘密のソースです。
実際、高度なRAGパイプラインは、普遍的な入力パターンに従う一連の個々のLLMコールに分解できます。

どこ:
次に、サブ質問クエリエンジンの内側の仕組みを調べることにより、この原則を説明します。
サブ質問クエリエンジンは、3つのタスクを実行する必要があります。
各タスクを詳細に調べてみましょう。
私たちの目標は、複雑な質問をサブ質問のセットに分解し、各サブ質問の適切なデータソースと検索関数を特定することです。たとえば、 「どの都市が最も人口が高いのか?」という質問はありますか? 「{都市}の人口は何ですか?」という形式の5つのサブ質問、1つは都市ごとに1つに分類されています。各サブ質問のデータソースは、対応する都市のwikiである必要があり、検索関数はベクトル検索でなければなりません。
一見すると、これは困難な作業のように思えます。具体的には、次の質問に答える必要があります。
驚くべきことに、3つの質問すべてに対する答えは同じです - 単一のLLMコール!サブクエストクエリエンジン全体は、慎重に作成されたプロンプトテンプレートを備えた単一のLLMコールを搭載しています。このテンプレートをサブ質問プロンプトテンプレートと呼びましょう。
-- Sub-question Prompt Template --
"""
You are an AI assistant that specializes in breaking down complex questions into simpler, manageable sub-questions.
When presented with a complex user question, your role is to generate a list of sub-questions that, when answered, will comprehensively address the original question.
You have at your disposal a pre-defined set of functions and data sources to utilize in answering each sub-question.
If a user question is straightforward, your task is to return the original question, identifying the appropriate function and data source to use for its solution.
Please remember that you are limited to the provided functions and data sources, and that each sub-question should be a full question that can be answered using a single function and a single data source.
"""
LLMコールのコンテキストは、データソースの名前とシステムで利用可能な機能です。問題はユーザーの質問です。 LLMは、それぞれが関数とデータソースを備えたサブ質問のリストを出力します。
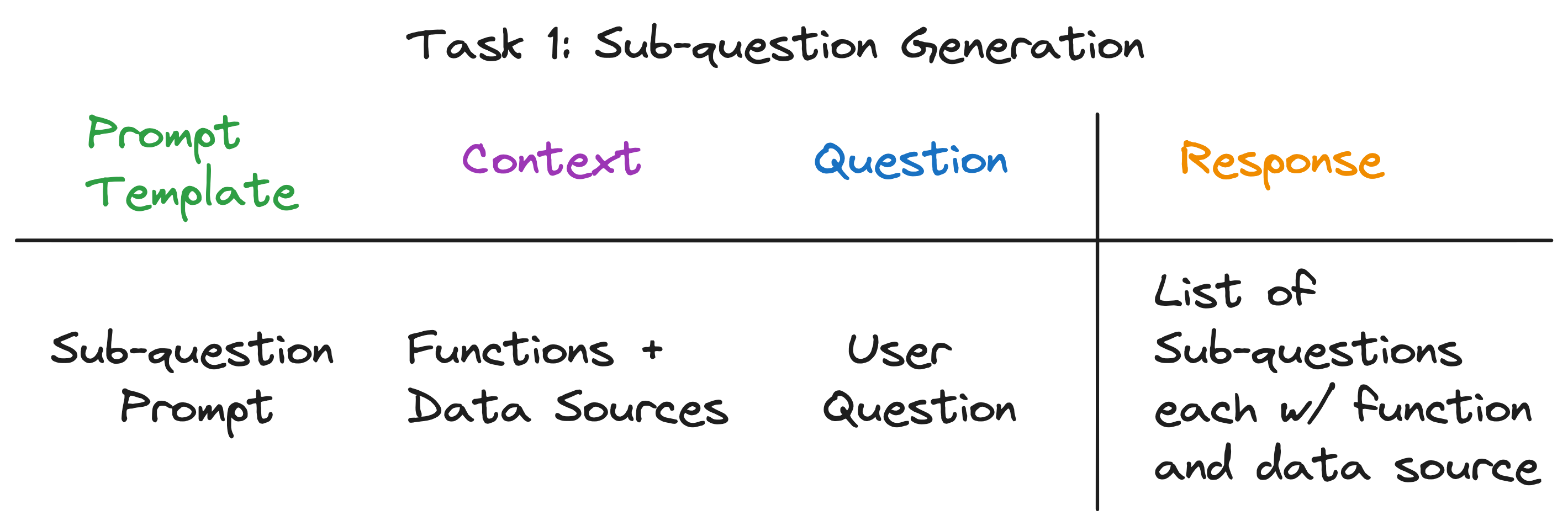
3つの例の質問について、LLMは次の出力を返します。
| 質問 | サブクエスト | 検索方法 | データソース |
|---|---|---|---|
| 「シカゴの人口は何ですか?」 | 「シカゴの人口は何ですか?」 | ベクトル検索 | シカゴ |
| 「アトランタの肯定的な側面の要約をください。」 | 「アトランタの肯定的な側面の要約をください。」 | 概要検索 | アトランタ |
| 「どの都市が最も人口が多いですか?」 | 「トロントの人口は何ですか?」 | ベクトル検索 | トロント |
| 「シカゴの人口は何ですか?」 | ベクトル検索 | シカゴ | |
| 「ヒューストンの人口は何ですか?」 | ベクトル検索 | ヒューストン | |
| 「ボストンの人口は何ですか?」 | ベクトル検索 | ボストン | |
| 「アトランタの人口は何ですか?」 | ベクトル検索 | アトランタ |
サブ質問ごとに、対応するデータソース上で選択した検索関数を使用して、関連情報を取得します。たとえば、 「シカゴの人口は何ですか?」 、シカゴのデータソースでベクトル検索を使用します。同様に、サブ質問については、「アトランタの肯定的な側面の要約を教えてください。」 、アトランタのデータソースで概要検索を使用します。
両方の検索方法で、同じLLMプロンプトテンプレートを使用します。実際、Langchainhubからの人気のあるRagプロンプトは、このステップではすぐに機能していることがわかります。
-- RAG Prompt Template --
"""
You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.
Question: {question}
Context: {context}
Answer:
両方の検索方法は、LLMコールに使用されるコンテキストでのみ異なります。ベクトル検索の場合、コンテキストとしてサブ質問と最も類似したデータチャンクを使用します。概要検索には、データソース全体をコンテキストとして使用します。

これは、サブ質問からの応答を最終的な応答に集約する最後のステップです。たとえば、 「どの都市が最も人口が高いのか?」という質問のために、サブ質問は各都市の人口を回収し、その後、応答集約は、最も高い人口のある都市を見つけて返還します。 RAGプロンプトは、このステップでもうまく機能します。
LLMコールのコンテキストは、サブ質問からの応答のリストです。問題は、元のユーザーの質問であり、LLMは最終回答を出力します。

抽象化のレイヤーを解明した後、サブクエストクエリエンジンに電力を供給する秘密の成分を明らかにしました-4種類のLLMコールは、異なるプロンプトテンプレート、コンテキスト、および質問でそれぞれ呼び出します。これは、私たちが以前に完全に特定したユニバーサル入力パターンに適合し、始めた複雑な抽象化とはかけ離れています。要約するには: 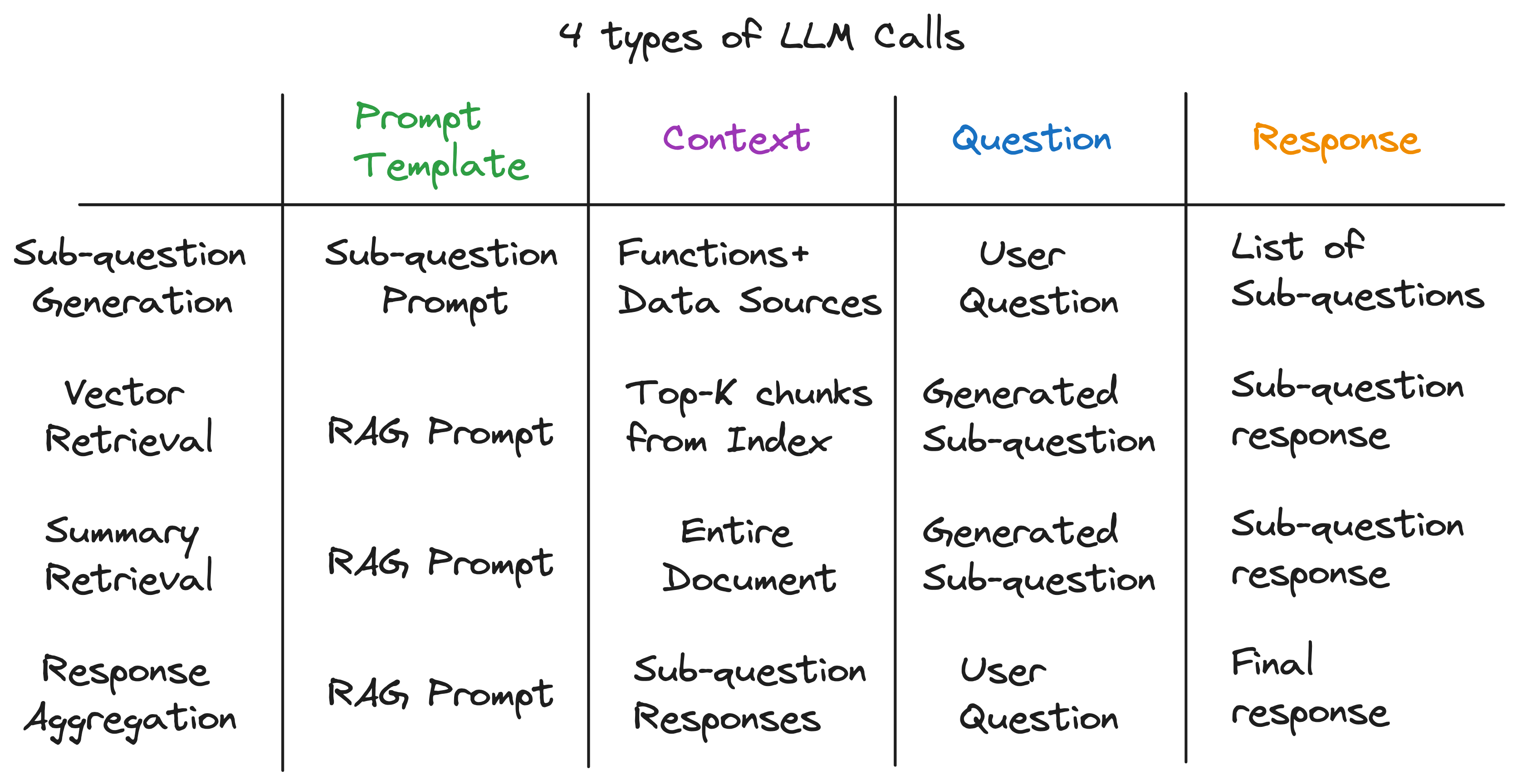
完全なパイプラインが動作しているのを見るには、次のコマンドを実行します。
pip install -r requirements.txt
echo OPENAI_API_KEY='yourkey' > .env
python complex_qa.py
「人口が最も多い都市はどの都市ですか?」という質問に答えるシステムの例です。 。
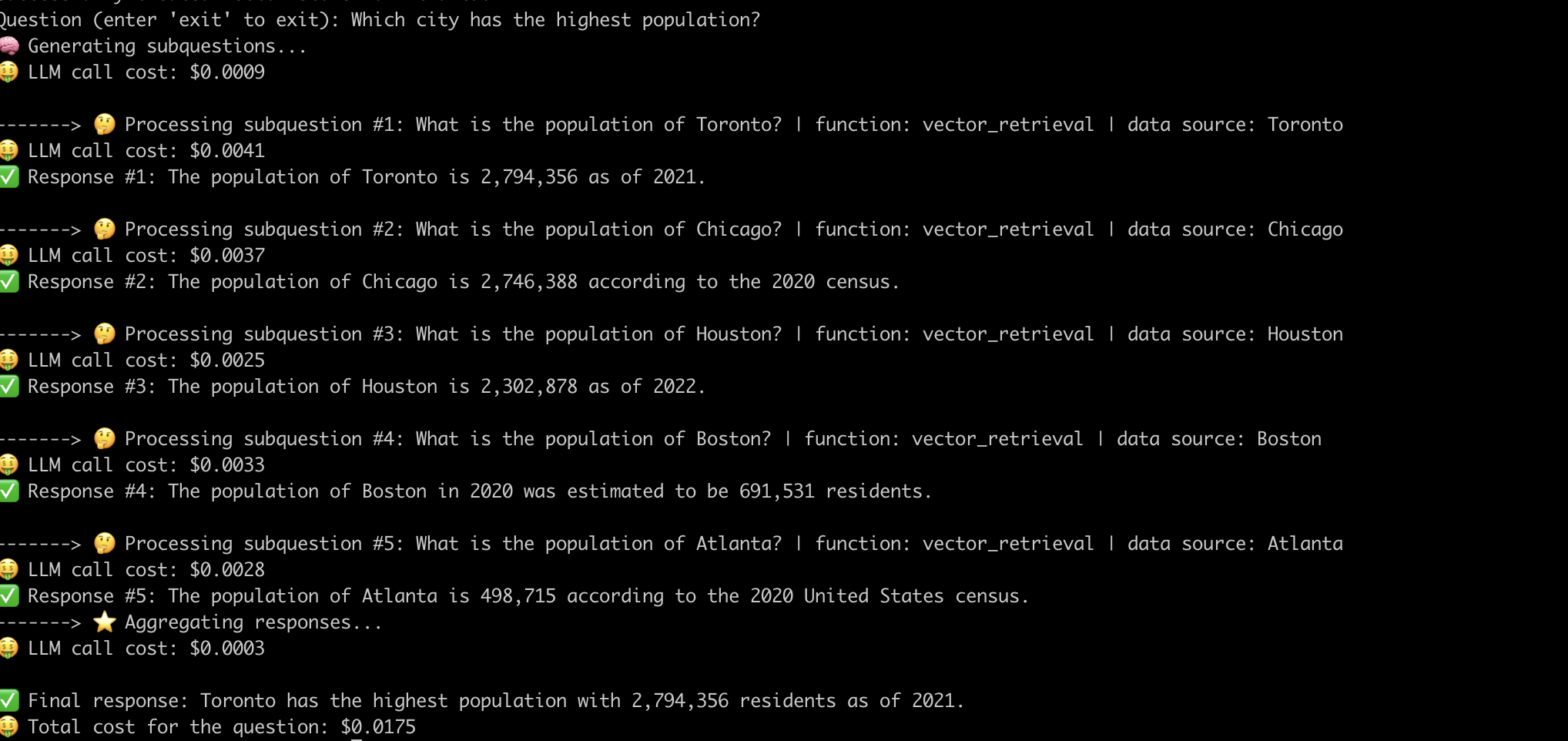
高度なRAGパイプラインの内部の仕組みを分かりやすくしたので、それらに関連する課題を調べてみましょう。
私たちは、各質問に対してパイプラインを機能させるために、迅速なエンジニアリングに多大な努力を払わなければなりませんでした。これは、堅牢なシステムを構築するための重要な課題です。
この動作を検証するために、LlamainDexサブクエストクエリエンジンを使用して例を実装しました。私たちの観察と一致して、システムはしばしば間違ったサブ質問を生成し、以下に示すようにサブ質問に対して間違った検索関数を使用します。

summary_tool )の誤ったモデルの選択により、 vector_toolと比較して3倍のコストが発生し、誤った応答も生成されます。LLMSを搭載した高度なRAGパイプラインは、質問回答システムに革命をもたらしました。ただし、これまで見てきたように、これらのパイプラインはターンキーソリューションではありません。ボンネットの下で、彼らは慎重に設計されたプロンプトテンプレートと複数のチェーンLLMコールに依存しています。このEVADBアプリケーションに示されているように、これらのパイプラインは、コストのダイナミクスにおいて疑問人民性、脆く、不透明である可能性があります。これらの複雑さを理解することは、彼らの可能性を最大限に活用し、将来より堅牢で効率的なシステムへの道を開くための鍵です。


