rag demystified
1.0.0
تكتسب خطوط أنابيب التوليد (RAG) المتمحورة للاسترجاع التي تعمل بنماذج لغوية كبيرة (LLMS) شعبية لبناء أنظمة الإجابة على أسئلة شاملة. أحرزت الأطر مثل Llamaindex و Haystack تقدمًا كبيرًا في جعل خطوط أنابيب الخرقة سهلة الاستخدام. في حين توفر هذه الأطر تجريدات ممتازة لبناء خطوط أنابيب خرقة متقدمة ، فإنها تفعل ذلك على حساب الشفافية. من وجهة نظر المستخدم ، ليس من الواضح بسهولة ما يجري تحت الغطاء ، خاصة عندما تنشأ الأخطاء أو التناقضات.
في تطبيق EVADB هذا ، سنلقي الضوء على الأعمال الداخلية لخطوط الأنابيب المتقدمة من خلال فحص الميكانيكا والقيود والتكاليف التي لا تزال غامضة.

Llama يعمل على جهاز كمبيوتر محمول ؟
إذا كنت ترغب في القفز مباشرة ، استخدم الأوامر التالية لتشغيل التطبيق:
pip install -r requirements.txt
echo OPENAI_API_KEY='yourkey' > .env
python complex_qa.py
الجيل المتمثل في الاسترجاع (RAG) هو نموذج من الذكاء الاصطناعي المتطور للإجابة على أسئلة قائم على LLM. يحتوي خط أنابيب خرقة عادة على:
مستودع البيانات - مجموعة من مصادر البيانات (على سبيل المثال ، المستندات والجداول وما إلى ذلك) تحتوي على معلومات ذات صلة بمهمة الإجابة على الأسئلة.
استرجاع Vector - إعطاء سؤال ، ابحث عن أفضل أجزاء البيانات المماثلة إلى السؤال. يتم ذلك باستخدام متجر متجه (على سبيل المثال ، FAISS).
توليد الاستجابة - بالنظر إلى الجزء العلوي من قطع البيانات المتشابهة ، قم بإنشاء استجابة باستخدام نموذج لغة كبير (على سبيل المثال GPT -4).
يوفر Rag مزايزتين رئيسيتين على الإجابة على أسئلة LLM التقليدية:
المعلومات الحديثة -يمكن تحديث مستودع البيانات في الوقت الفعلي ، وبالتالي فإن المعلومات محدثة دائمًا.
تتبع المصادر - يوفر RAG إمكانية تتبع واضحة ، مما يمكّن المستخدمين من تحديد مصادر المعلومات ، وهو أمر بالغ الأهمية للتحقق من الدقة وتخفيف الهلوسة LLM.
لتمكين الإجابة على أسئلة أكثر تعقيدًا ، أدخلت أطر منظمة العفو الدولية الحديثة مثل Llamaindex تجريدات أكثر تقدمًا مثل محرك الاستعلام عن الأسئلة الفرعية.
في هذا التطبيق ، سنقوم بإزالة الغموض عن خطوط أنابيب خرقة متطورة باستخدام محرك الاستعلام عن الأسئلة الفرعية كمثال. سنقوم بفحص الأعمال الداخلية لمحرك الاستعلام عن الأسئلة الفرعية وتبسيط التجريدات على مكوناتها الأساسية. سنحدد أيضًا بعض التحديات المرتبطة بخطوط الأنابيب المتقدمة.
مستودع البيانات هو مجموعة من مصادر البيانات (على سبيل المثال ، المستندات والجداول وما إلى ذلك) التي تحتوي على معلومات ذات صلة بمهمة الإجابة على الأسئلة.
في هذا المثال ، سنستخدم مستودع بيانات بسيط يحتوي على مقالات ويكيبيديا متعددة للمدن الشعبية المختلفة ، المستوحاة من حالة الاستخدام التوضيحية لـ Llamaindex. ويكي كل مدينة هو مصدر بيانات منفصل. لاحظ أنه بالنسبة للبساطة ، فإننا نحد من حجم كل مستند لتناسب ضمن حد سياق LLM.
هدفنا هو إنشاء نظام يمكنه الإجابة على أسئلة مثل:
كما ترون ، يمكن أن تكون الأسئلة أسئلة بسيطة من الواقع/تلخيص على مصدر بيانات واحد (Q1/Q2) أو أسئلة معقدة/تلخيص معقدة على مصادر بيانات متعددة (Q3).
لدينا أساليب الاسترجاع التالية تحت تصرفنا:
استرجاع Vector - إعطاء سؤال ومصدر بيانات ، قم بإنشاء استجابة LLM باستخدام الجزء العلوي من أجزاء البيانات المماثلة إلى السؤال من مصدر البيانات كسياق. نحن نستخدم مؤشر Vactor Faiss من EVADB لاسترجاع المتجه. ومع ذلك ، فإن المفاهيم قابلة للتطبيق على أي مؤشر متجه.
الاسترجاع الموجز - بالنظر إلى سؤال موجز ومصدر بيانات ، قم بإنشاء استجابة LLM باستخدام مصدر البيانات بأكمله كسياق.
تتمثل البصيرة الرئيسية لدينا في أن كل مكون في خط أنابيب قطعة قماش متقدم مدعوم عن طريق مكالمة LLM واحدة. خط الأنابيب بأكمله عبارة عن سلسلة من مكالمات LLM مع قوالب موجهة بعناية. هذه القوالب السريعة هي الصلصة السرية التي تمكن خطوط أنابيب الخرقة المتقدمة من أداء المهام المعقدة.
في الواقع ، يمكن تقسيم أي خط أنابيب للقطعة المتقدمة إلى سلسلة من مكالمات LLM الفردية التي تتبع نمط الإدخال العالمي:

أين:
الآن ، نوضح هذا المبدأ من خلال فحص الأعمال الداخلية لمحرك الاستعلام عن الأسئلة الفرعية.
يجب أن يؤدي محرك الاستعلام عن الأسئلة الفرعية ثلاث مهام:
دعنا نفحص كل مهمة بالتفصيل.
هدفنا هو تقسيم سؤال معقد إلى مجموعة من الأسئلة الفرعية ، مع تحديد مصدر البيانات المناسبة ووظيفة الاسترجاع لكل سؤال فرعي. على سبيل المثال ، السؤال "أي مدينة لديها أعلى عدد السكان؟" يتم تقسيمها إلى خمسة أسئلة فرعية ، واحدة لكل مدينة ، من النموذج "ما هو عدد سكان {City}؟". يجب أن يكون مصدر البيانات لكل سؤال فرعي هو ويكي في المدينة المقابلة ، ويجب أن تكون وظيفة الاسترجاع استرجاع المتجهات.
للوهلة الأولى ، يبدو أن هذه مهمة شاقة. على وجه التحديد ، نحتاج إلى الإجابة على الأسئلة التالية:
ومن اللافت للنظر أن الإجابة على جميع الأسئلة الثلاثة هي نفسها - مكالمة LLM واحدة! يتم تشغيل محرك الاستعلام عن الأسئلة الفرعية بأكملها عن طريق مكالمة LLM واحدة مع قالب موجه مصمم بعناية. دعنا نسمي هذا القالب قالب موجه الأسئلة الفرعية .
-- Sub-question Prompt Template --
"""
You are an AI assistant that specializes in breaking down complex questions into simpler, manageable sub-questions.
When presented with a complex user question, your role is to generate a list of sub-questions that, when answered, will comprehensively address the original question.
You have at your disposal a pre-defined set of functions and data sources to utilize in answering each sub-question.
If a user question is straightforward, your task is to return the original question, identifying the appropriate function and data source to use for its solution.
Please remember that you are limited to the provided functions and data sources, and that each sub-question should be a full question that can be answered using a single function and a single data source.
"""
سياق مكالمة LLM هو أسماء مصادر البيانات والوظائف المتاحة للنظام. السؤال هو سؤال المستخدم. تقوم LLM بإخراج قائمة بالأسئلة الفرعية ، ولكل منها وظيفة ومصدر بيانات.
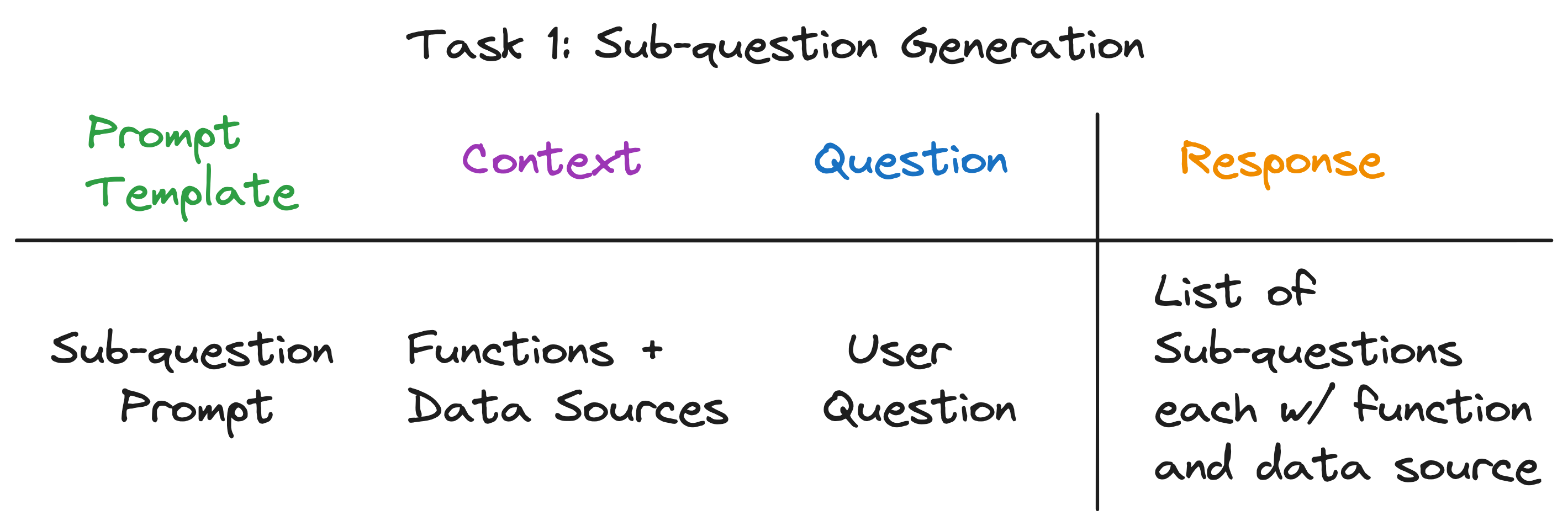
بالنسبة للأسئلة الثلاثة على سبيل المثال ، تقوم LLM بإرجاع الإخراج التالي:
| سؤال | الاختبارات الفرعية | طريقة الاسترداد | مصدر البيانات |
|---|---|---|---|
| "ما هي سكان شيكاغو؟" | "ما هي سكان شيكاغو؟" | استرجاع المتجهات | شيكاغو |
| "أعطني ملخصًا للجوانب الإيجابية لأتلانتا." | "أعطني ملخصًا للجوانب الإيجابية لأتلانتا." | استرجاع ملخص | أتلانتا |
| "أي مدينة لديها أعلى عدد السكان؟" | "ما هو عدد سكان تورنتو؟" | استرجاع المتجهات | تورونتو |
| "ما هي سكان شيكاغو؟" | استرجاع المتجهات | شيكاغو | |
| "ما هو سكان هيوستن؟" | استرجاع المتجهات | هيوستن | |
| "ما هو سكان بوسطن؟" | استرجاع المتجهات | بوسطن | |
| "ما هو عدد سكان أتلانتا؟" | استرجاع المتجهات | أتلانتا |
بالنسبة لكل سؤال فرعي ، نستخدم وظيفة الاسترجاع المختارة على مصدر البيانات المقابل لاسترداد المعلومات ذات الصلة. على سبيل المثال ، بالنسبة للمسألة الفرعية "ما هو سكان شيكاغو؟" ، نستخدم استرجاع المتجهات على مصدر بيانات شيكاغو. وبالمثل ، بالنسبة للرسالة الفرعية "أعطني ملخصًا للجوانب الإيجابية لأتلانتا." ، نستخدم الاسترجاع الموجز على مصدر بيانات أتلانتا.
لكل من طرق الاسترجاع ، نستخدم نفس قالب LLM. في الواقع ، نجد أن مطالبة الخرقة الشهيرة من Langchainhub تعمل بشكل كبير خارج الصندوق لهذه الخطوة.
-- RAG Prompt Template --
"""
You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.
Question: {question}
Context: {context}
Answer:
كل من طرق الاسترجاع تختلف فقط في السياق المستخدم لمكالمة LLM. لاسترجاع المتجهات ، نستخدم أعلى أجزاء البيانات الأكثر مماثلة للبيانات الفرعية كسياق. لاسترجاع الملخص ، نستخدم مصدر البيانات بأكمله كسياق.

هذه هي الخطوة الأخيرة التي تجمع الردود من الأسئلة الفرعية إلى استجابة نهائية. على سبيل المثال ، بالنسبة للسؤال "أي مدينة لديها أعلى عدد السكان؟" ، تسترجع الاختبارات الفرعية سكان كل مدينة ثم يجد تجميع الاستجابة ويعيد المدينة بأعلى عدد السكان. موجه خرقة يعمل بشكل رائع لهذه الخطوة كذلك.
سياق مكالمة LLM هو قائمة الاستجابات من الخيول الفرعية. والسؤال هو سؤال المستخدم الأصلي ويقوم LLM بإخراج الرد النهائي.

بعد كشف طبقات التجريد ، اكتشفنا المكون السري الذي يعمل على تشغيل محرك الاستعلام الفرعي - 4 أنواع من LLM مكالمات كل من قالب موجه مختلف ، سياق ، وسؤال. هذا يناسب نمط الإدخال العالمي الذي حددناه سابقًا تمامًا ، وهو بعيد كل البعد عن التجريدات المعقدة التي بدأناها. لتلخيص: 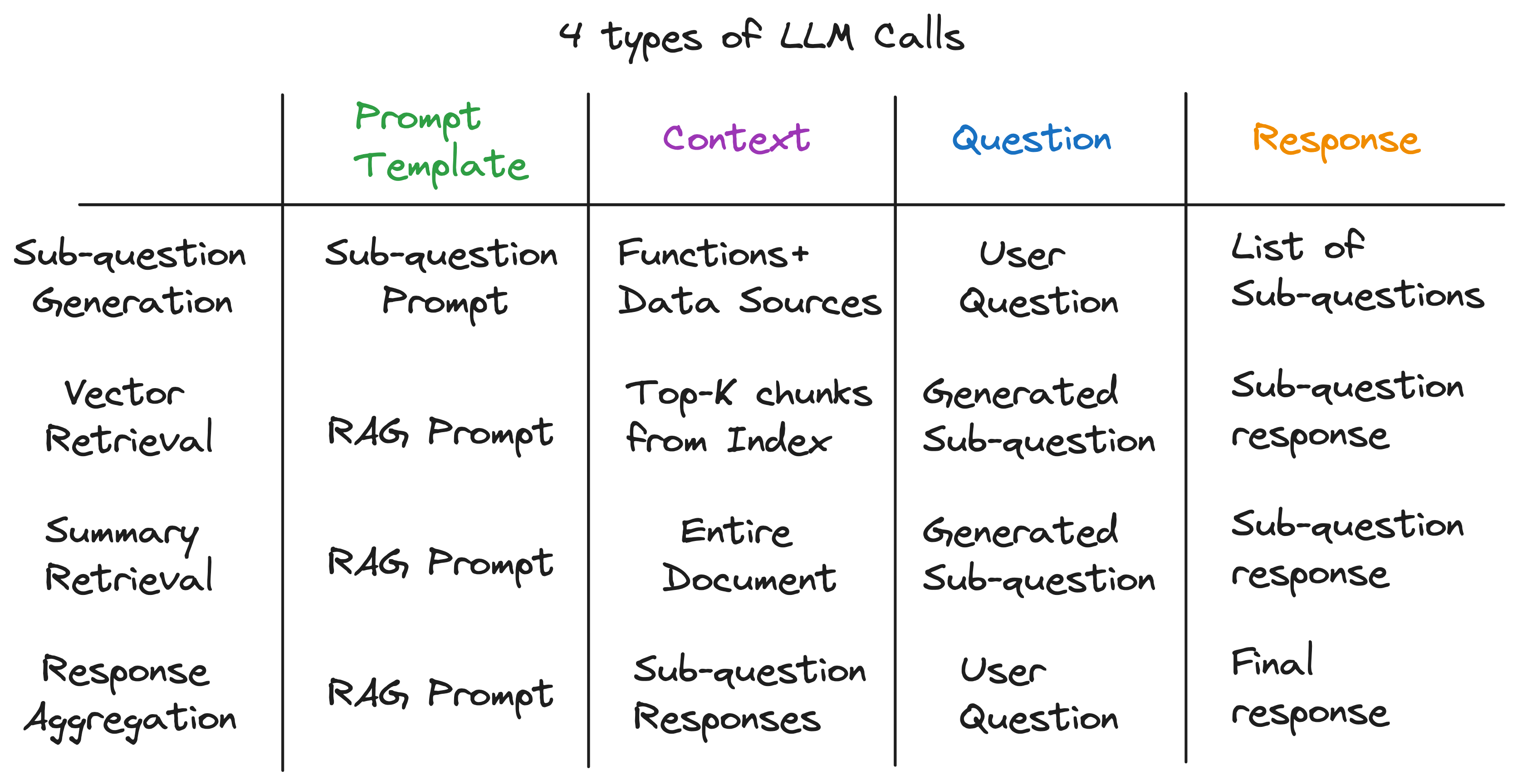
لرؤية خط الأنابيب الكامل في العمل ، قم بتشغيل الأوامر التالية:
pip install -r requirements.txt
echo OPENAI_API_KEY='yourkey' > .env
python complex_qa.py
فيما يلي مثال على النظام الذي يجيب على السؤال "أي مدينة بها أعلى عدد السكان؟" .
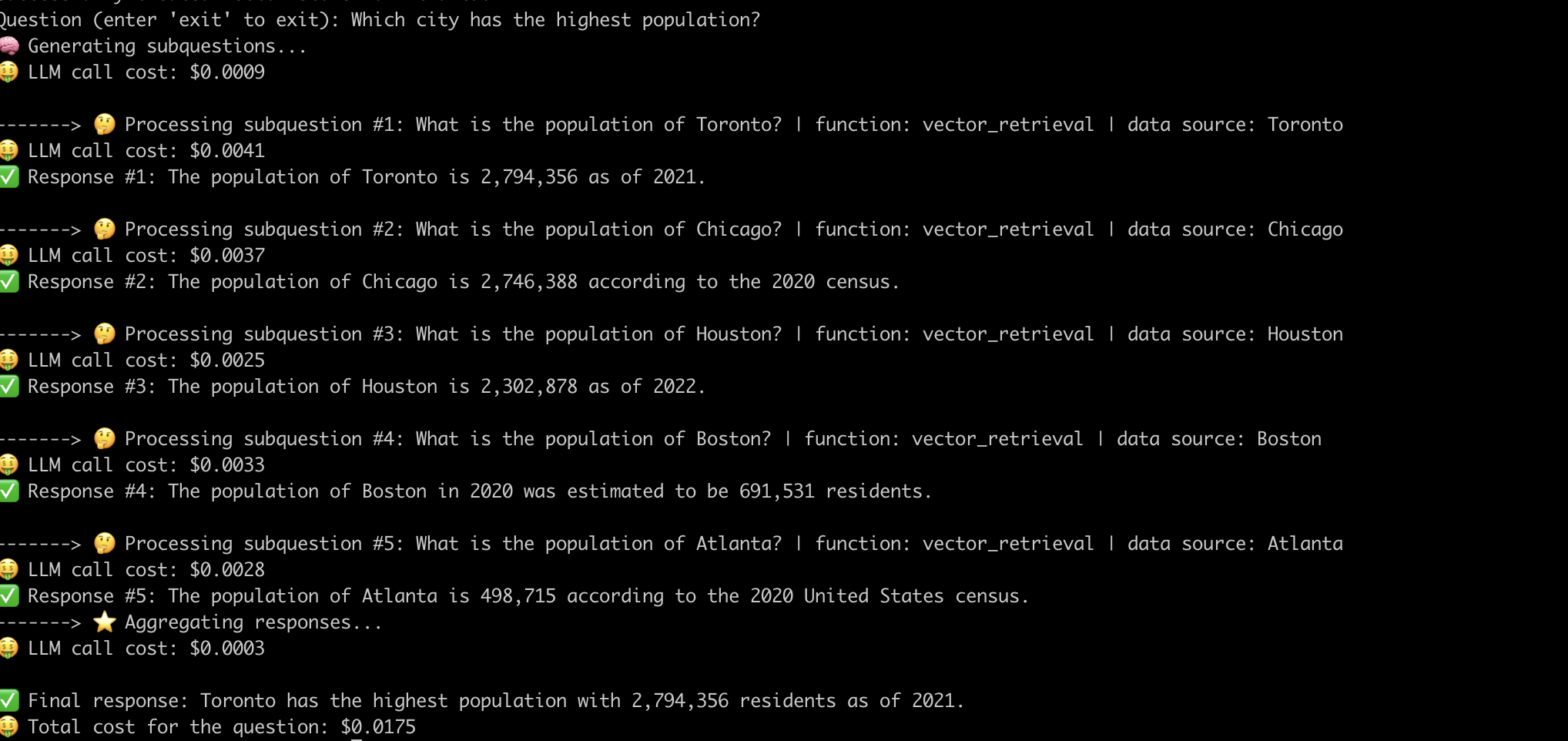
الآن بعد أن قمنا بإزالة الغموض عن الأعمال الداخلية لخطوط أنابيب الخرقة المتقدمة ، دعنا ندرس التحديات المرتبطة بها.
اضطررنا إلى بذل جهد كبير في الهندسة السريعة للحصول على خط الأنابيب للعمل لكل سؤال. هذا تحد كبير لبناء أنظمة قوية.
للتحقق من هذا السلوك ، قمنا بتنفيذ المثال باستخدام محرك الاستعلام الفرعي Llamaindex. تمشيا مع ملاحظاتنا ، غالبًا ما يولد النظام الأسئلة الفرعية الخاطئة ويستخدم أيضًا وظيفة الاسترجاع الخاطئة للأسئلة الفرعية ، كما هو موضح أدناه.

summary_tool ) تكلفة أعلى 3x مقارنة مع vector_tool مع إنشاء استجابة غير صحيحة أيضًا.أحدثت خطوط أنابيب RAG المتقدمة التي تعمل بها LLMs أنظمة إجابة الأسئلة. ومع ذلك ، كما رأينا ، فإن خطوط الأنابيب هذه ليست حلول تسليم المفتاح. تحت الغطاء ، يعتمدون على قوالب موجهة هندسية بعناية ومكالمات LLM متعددة بالسلاسل. كما هو موضح في تطبيق EVADB هذا ، يمكن أن تكون خطوط الأنابيب هذه حساسة للأسئلة ، هشة ، ومعتمة في ديناميات التكلفة. إن فهم هذه التعقيدات هو مفتاح الاستفادة من إمكاناتها الكاملة وتوفير الطريق لأنظمة أكثر قوة وفعالية في المستقبل.


