rag demystified
1.0.0
由大语言模型(LLMS)提供动力的检索增强发电(RAG)管道正在越来越受欢迎,以构建端到端的问答系统。 Llamaindex和Haystack等框架在使破布管道易于使用方面取得了重大进展。尽管这些框架为构建高级抹布管道提供了出色的抽象,但它们以透明度为代价。从用户的角度来看,这并不容易看出引擎盖下发生的事情,尤其是在出现错误或不一致的情况下。
在此EVADB应用中,我们将通过检查通常保持不透明的机制,局限性和成本来阐明高级抹布管道的内部工作。

骆驼在笔记本电脑上工作?
如果要直接跳入,请使用以下命令运行应用程序:
pip install -r requirements.txt
echo OPENAI_API_KEY='yourkey' > .env
python complex_qa.py
检索演示的一代(RAG)是用于基于LLM的问题答案的尖端AI范式。破布管道通常包含:
数据仓库- 包含与问题回答任务相关的信息的数据源(例如文档,表等)的集合。
向量检索- 给出一个问题,找到与问题的最相似的数据块。这是使用矢量存储(例如,faiss)完成的。
响应生成- 给定最类似的数据块,使用大语言模型(例如GPT -4)生成响应。
与传统的基于LLM的问题回答相比,RAG提供了两个关键优势:
最新信息- 数据仓库可以实时更新,因此信息始终是最新的。
来源跟踪- RAG提供了清晰的可追溯性,使用户能够识别信息来源,这对于准确验证和缓解LLM幻觉至关重要。
为了启用更复杂的问题,最近的AI框架(例如LlamainDex)引入了更高级的抽象,例如子问题,例如sub-teastion查询引擎。
在此应用程序中,我们将使用子问题查询引擎作为示例来揭开复杂的RAG管道。我们将检查子问题查询引擎的内部工作原理,并将抽象简化为其核心组件。我们还将确定与高级抹布管道相关的一些挑战。
数据仓库是包含与问答任务相关的信息的数据源(例如,文档,表等)的集合。
在此示例中,我们将使用一个简单的数据仓库,其中包含来自LlamainDex的说明性用例的启发,其中包含多个Wikipedia文章。每个城市的Wiki是一个单独的数据源。请注意,为简单起见,我们限制了每个文档的大小以适合LLM上下文限制。
我们的目标是建立一个可以回答类似问题的系统
如您所见,这些问题可以是单个数据源(Q1/Q2)或复杂的Factoid/Summarization问题(Q3)上的简单事实/摘要问题。
我们可以使用以下检索方法:
向量检索- 给出一个问题和数据源,使用TOP -K最相似的数据块与来自数据源作为上下文的问题生成LLM响应。我们使用EVADB的现成的FAISS矢量指数进行矢量检索。但是,这些概念适用于任何向量指数。
摘要检索- 给出一个摘要问题和数据源,使用整个数据源作为上下文生成LLM响应。
我们的关键见解是,高级抹布管道中的每个组件都由单个LLM调用供电。整个管道是一系列具有精心制作的及时模板的LLM呼叫。这些及时的模板是使高级抹布管道能够执行复杂任务的秘密酱。
实际上,任何高级的抹布管道都可以分为一系列遵循通用输入模式的单独的LLM调用:

在哪里:
现在,我们通过检查子问题查询引擎的内部运作来说明这一原理。
该子问题查询引擎必须执行三个任务:
让我们详细检查每个任务。
我们的目标是将一个复杂的问题分解为一组子问题,同时确定每个亚问题的适当数据源和检索功能。例如, “哪个城市人口最多?”这个问题。是否将“ {City}的人口是多少?”形式分为五个子问题,一个是每个城市的一个。每个子问题的数据源必须是相应的城市Wiki,并且检索功能必须是向量检索。
乍一看,这似乎是一项艰巨的任务。具体来说,我们需要回答以下问题:
值得注意的是,所有三个问题的答案都是相同的 - 单个LLM呼叫!整个子问题查询引擎由单个LLM调用提供动力,并使用精心设计的及时模板。让我们称此模板为子问题提示模板。
-- Sub-question Prompt Template --
"""
You are an AI assistant that specializes in breaking down complex questions into simpler, manageable sub-questions.
When presented with a complex user question, your role is to generate a list of sub-questions that, when answered, will comprehensively address the original question.
You have at your disposal a pre-defined set of functions and data sources to utilize in answering each sub-question.
If a user question is straightforward, your task is to return the original question, identifying the appropriate function and data source to use for its solution.
Please remember that you are limited to the provided functions and data sources, and that each sub-question should be a full question that can be answered using a single function and a single data source.
"""
LLM调用的上下文是数据源的名称和系统可用的功能。问题是用户问题。 LLM输出一个子问题列表,每个列表都有一个功能和数据源。
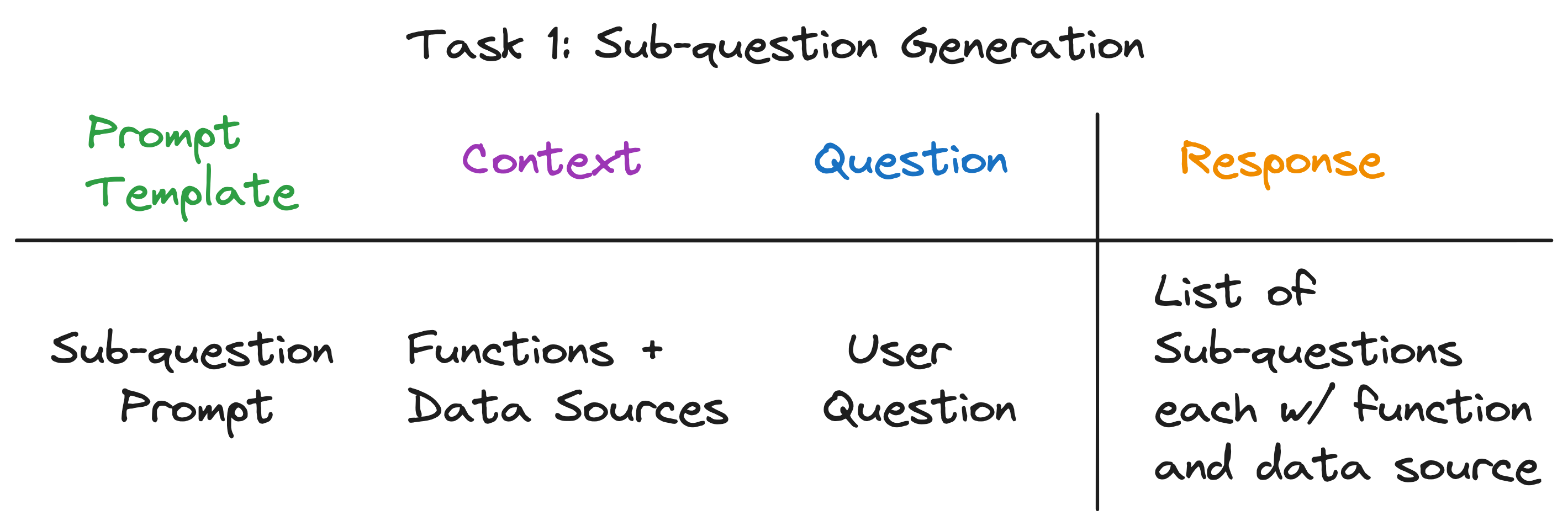
对于三个示例问题,LLM返回以下输出:
| 问题 | 子问题 | 检索方法 | 数据源 |
|---|---|---|---|
| “芝加哥的人口是多少?” | “芝加哥的人口是多少?” | 向量检索 | 芝加哥 |
| “给我总结亚特兰大的积极方面。” | “给我总结亚特兰大的积极方面。” | 摘要检索 | 亚特兰大 |
| “哪个城市人口最多?” | “多伦多的人口是多少?” | 向量检索 | 多伦多 |
| “芝加哥的人口是多少?” | 向量检索 | 芝加哥 | |
| “休斯顿的人口是多少?” | 向量检索 | 休斯顿 | |
| “波士顿的人口是多少?” | 向量检索 | 波士顿 | |
| “亚特兰大的人口是多少?” | 向量检索 | 亚特兰大 |
对于每个子问题,我们在相应的数据源上使用所选检索功能来检索相关信息。例如,对于“芝加哥的人口是多少?” ,我们在芝加哥数据源上使用矢量检索。同样,对于“给我亚特兰大的积极方面的总结”。 ,我们使用亚特兰大数据源的摘要检索。
对于这两种检索方法,我们使用相同的LLM提示模板。实际上,我们发现LangchainHub的流行RAG提示为此步骤提供了很棒的开箱即用。
-- RAG Prompt Template --
"""
You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.
Question: {question}
Context: {context}
Answer:
两种检索方法仅在用于LLM调用的上下文中有所不同。对于向量检索,我们将最顶级的K最相似的数据块与子问题作为上下文。对于摘要检索,我们将整个数据源用作上下文。

这是将子问题响应汇总为最终响应的最后一步。例如,对于“哪个城市人口最多的问题?” ,子问题检索了每个城市的人口,然后响应汇总发现并返回人口最高的城市。 RAG提示也适合此步骤。
LLM调用的上下文是子问题的响应列表。问题是原始用户问题,LLM输出了最终回应。

揭开抽象层后,我们发现了为子问题引擎提供动力的秘密成分-LM的4种类型的LLM调用各种带有不同的提示模板,上下文和问题。这符合我们完美地确定的通用输入模式,并且与我们开始的复杂抽象相去甚远。总结: 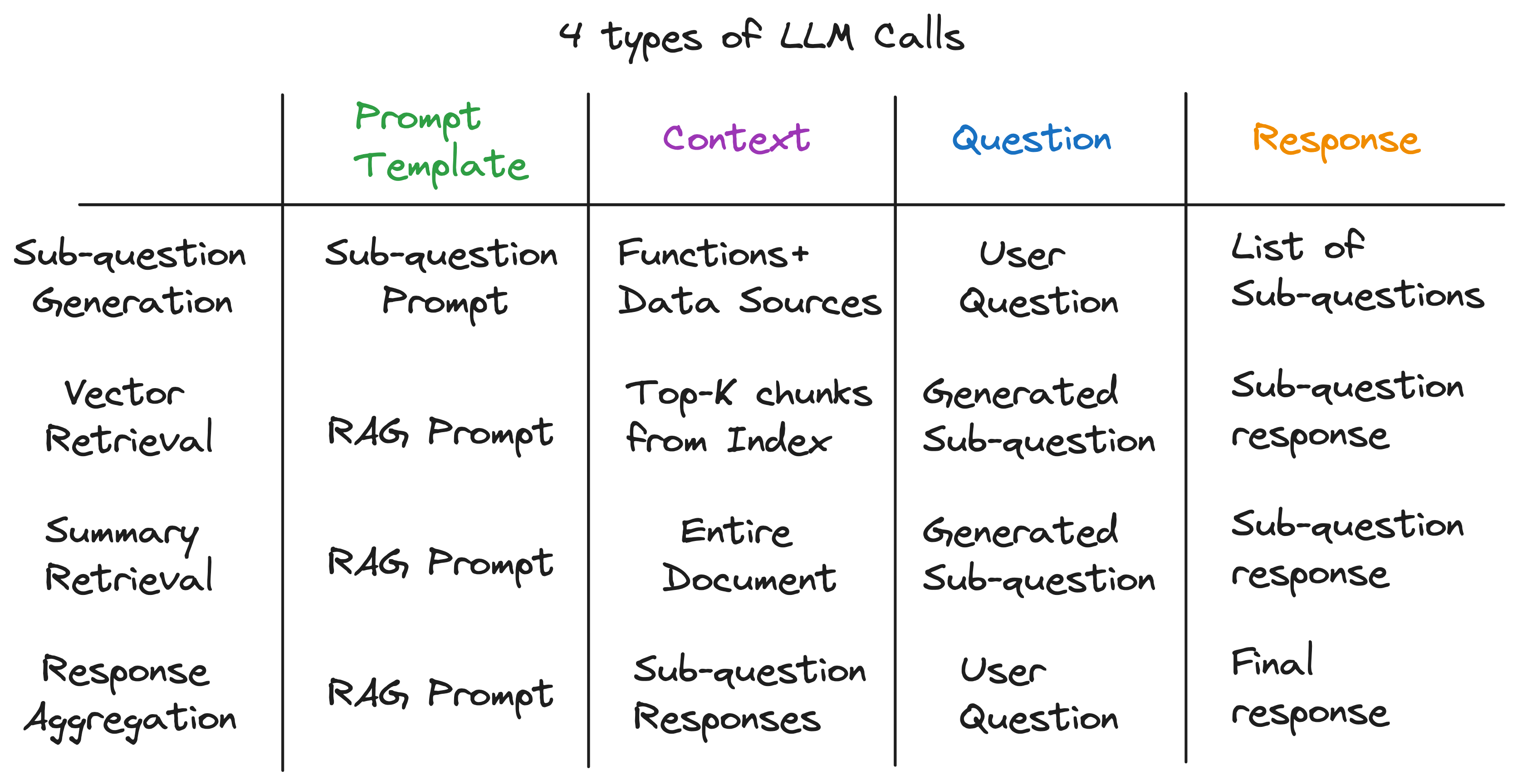
要查看整个管道的操作,请运行以下命令:
pip install -r requirements.txt
echo OPENAI_API_KEY='yourkey' > .env
python complex_qa.py
这是系统回答“人口最多的城市?”问题的一个示例。 。
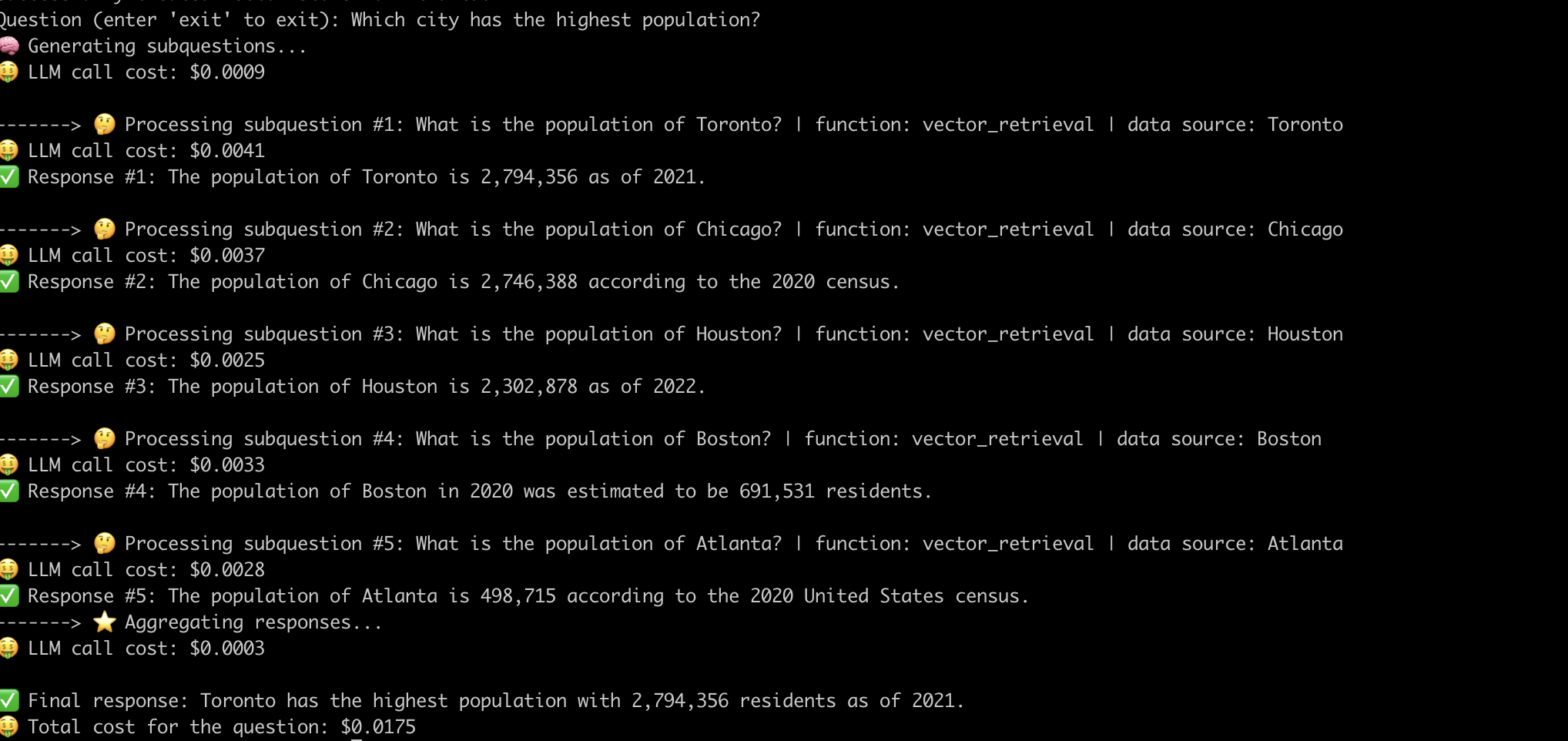
现在,我们已经揭开了高级抹布管道的内部工作,让我们研究与之相关的挑战。
我们不得不付出巨大的努力迅速工程,以使管道为每个问题工作。这是构建强大系统的重大挑战。
为了验证这种行为,我们使用LlamainDex子问题查询引擎实施了示例。与我们的观察结果一致,该系统通常会产生错误的子问题,并且还使用错误的检索功能作为子问题,如下所示。

vector_tool相比,上面的LlamainDex基线示例( summary_tool )中的模型选择不正确,同时也会产生不正确的响应。LLM提供支持的先进的抹布管道已彻底改变了提问系统。但是,正如我们已经看到的那样,这些管道不是交钥匙解决方案。在引擎盖下,他们依靠经过精心设计的及时及时的LLM呼叫。如本EVADB应用中所示,这些管道的成本动态可能对问题敏感,脆弱和不透明。理解这些复杂性是利用其全部潜力并为将来更有效的系统铺平道路的关键。


