so vits svc
1.0.0
英語|中文簡體
這一輪限時更新即將結束,倉庫將進入拱門狀態,請知道
一個包含可見F0編輯器,揚聲器混音時間表編輯器和其他功能的工作室(使用ONNX型號):MoevoiceStudio
具有大大改進的用戶界面的叉子:34J/so-vits-svc-fork
客戶支持實時轉換:W-OKADA/語音改變者
該項目從根本上與VIT不同,因為它專注於唱歌語音轉換(SVC),而不是文本到語音(TTS)。在此項目中,不支持TTS功能,VIT無法執行SVC任務。重要的是要注意,這兩個項目中使用的模型不可互換或普遍適用。
該項目的目的是使開發人員能夠讓他們心愛的動漫角色執行歌唱任務。開發商的意圖是只專注於虛構的角色,避免真正的個人參與,與真實個人有關的任何事物都偏離了開發人員的最初意圖。
該項目是一個開源,離線努力,以及SVCDevelopteam的所有成員,以及其他所涉及的開發人員和維護者(以下稱為貢獻者),對該項目沒有控制權。貢獻者從未向任何組織或個人提供任何形式的幫助,包括但不限於數據集提取,數據集處理,計算支持,培訓支持,推理等。貢獻者沒有也不能意識到用戶使用該項目的目的。因此,通過該項目訓練產生的任何AI模型和合成的音頻都與貢獻者無關。用戶使用的任何問題或後果都是用戶的全部責任。
該項目完全離線運行,不會收集任何用戶信息或收集用戶輸入數據。因此,該項目的貢獻者並不了解所有用戶輸入和模型,因此對任何用戶輸入概不負責。
該項目僅作為框架,並且不具有語音合成功能。所有功能都要求用戶獨立訓練模型。此外,該項目並未與任何模型捆綁在一起,任何二級分佈式項目都與該項目的貢獻者無關。
Singing語音轉換模型使用SOFTVC內容編碼器從源音頻中提取語音功能。這些特徵向量直接被饋入VIT,而無需轉換為基於文本的中間表示。結果,保留了原始音頻的音高和音調。同時,Vocoder被NSF Hifigan取代,以解決聲音中斷的問題。
config.json文件進行修改。如下所示,將speech_encoder字段添加到“模型”部分: "model": {
.........
"ssl_dim": 256,
"n_speakers": 200,
"speech_encoder":"vec256l9"
}
根據我們的測試,我們確定該項目在Python 3.8.9上運行穩定。
您需要從下面的列表中選擇一個編碼器
vec768l12和vec256l9需要編碼器
pretrain目錄下或下載以下contentvec,大小僅為199MB,但效果相同:
checkpoint_best_legacy_500.pt並將其放在pretrain目錄中 # contentvec
wget -P pretrain/ https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/hubert_base.pt -O checkpoint_best_legacy_500.pt
# Alternatively, you can manually download and place it in the hubert directory pretrain目錄下whisper-ppgwhisper-ppg-largepretrain目錄下pretrain目錄下pretrain目錄下wavlmbase+pretrain目錄下pretrain目錄下預訓練的模型文件: G_0.pth D_0.pth
logs/44k目錄下擴散模型預處理基本模型文件: model_0.pt
logs/44k/diffusion目錄中從SVC-developem-Team(TBD)或其他任何地方獲取Sovits預訓練的模型。
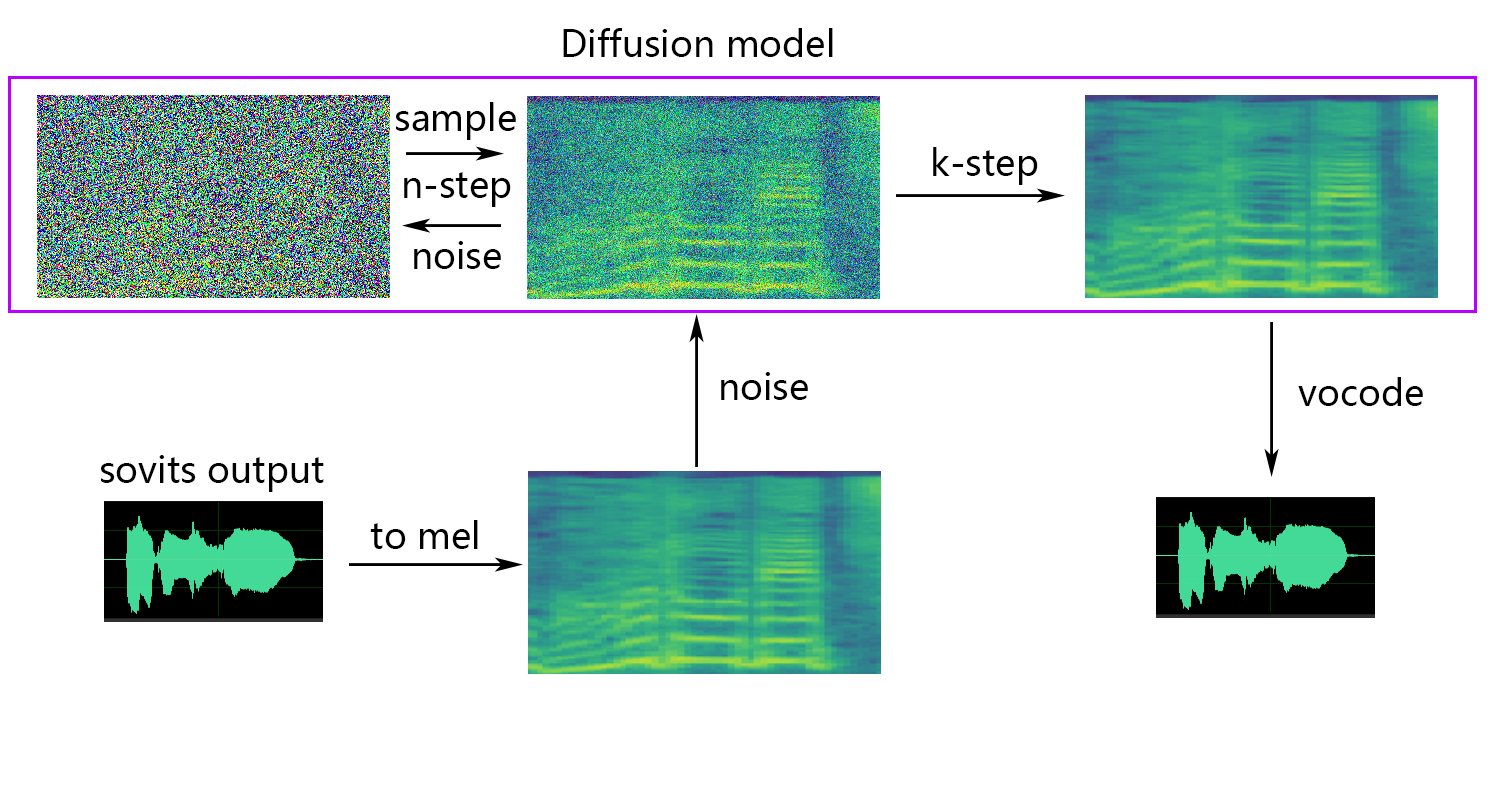
擴散模型參考擴散-SVC擴散模型。預先訓練的擴散模型與DDSP-SVC是通用的。您可以轉到擴散-SVC的存儲庫以獲取預訓練的擴散模型。
雖然驗證的模型通常不會引起版權問題,但保持警惕至關重要。建議事先與作者諮詢或仔細查看描述,以確定模型的允許用法。這有助於確保遵守有關其利用的任何指定準則或限制。
如果您使用的是NSF-HIFIGAN enhancer或shallow diffusion ,則需要下載預訓練的NSF-Hifigan模型。
pretrain/nsf_hifigan目錄下 # nsf_hifigan
wget -P pretrain/ https://github.com/openvpi/vocoders/releases/download/nsf-hifigan-v1/nsf_hifigan_20221211.zip
unzip -od pretrain/nsf_hifigan pretrain/nsf_hifigan_20221211.zip
# Alternatively, you can manually download and place it in the pretrain/nsf_hifigan directory
# URL: https://github.com/openvpi/vocoders/releases/tag/nsf-hifigan-v1 如果您使用的是rmvpe F0預測器,則需要下載預訓練的RMVPE模型。
rmvpe.zip pretrain並將model.pt rmvpe.ptpretrain目錄下FCPE(快速上下文基量估計器)是一個專門的F0預測器,專為實時語音轉換而設計,並將成為未來Sovits實時語音轉換的首選F0預測指標。(正在撰寫論文)
如果您使用的是fcpe F0預測器,則需要下載預訓練的FCPE模型。
pretrain目錄下只需將數據集放在dataset_raw目錄中,並具有以下文件結構:
dataset_raw
├───speaker0
│ ├───xxx1-xxx1.wav
│ ├───...
│ └───Lxx-0xx8.wav
└───speaker1
├───xx2-0xxx2.wav
├───...
└───xxx7-xxx007.wav
每個音頻文件的名稱格式沒有特定的限制(命名慣例,例如000001.wav至999999.wav也有效),但是文件類型必須為``wav''。
您可以自定義揚聲器的名稱,如下所示:
dataset_raw
└───suijiSUI
├───1.wav
├───...
└───25788785-20221210-200143-856_01_(Vocals)_0_0.wav
為了避免在訓練或預處理過程中進行視頻記憶溢出,建議限制音頻剪輯的長度。建議將音頻切成“ 5s -15s”的長度。但是,稍長的時間是可以接受的,但是,剪輯過長可能會引起諸如torch.cuda.OutOfMemoryError之類的問題。
為了促進切片過程,您可以使用音頻 - 縫合器或音頻式CLI
通常,只需要調整Minimum Interval 。對於口語音頻,默認值通常就足夠了,而對於唱歌音頻,可以根據特定要求將其調整為100甚至50 。
切片後,建議刪除任何過長或太短的音頻剪輯。
如果您使用Whisper-PPG編碼器進行培訓,則音頻剪輯必須短於30s。
python resample.py儘管此項目具有重新採樣腳本。這可能會損害音質。雖然Python的響度匹配包pylodnorm並沒有限制水平,但這可能導致聲音繁榮。因此,建議考慮使用專業的聲音處理軟件,例如adobe audition進行響度匹配。如果您已經在使用其他軟件進行響度匹配,請將參數-skip_loudnorm添加到運行命令:
python resample.py --skip_loudnormpython preprocess_flist_config.py --speech_encoder vec768l12secement_encoder有以下選項
vec768l12
vec256l9
hubertsoft
whisper-ppg
cnhubertlarge
dphubert
whisper-ppg-large
wavlmbase+
如果省略了specy_encoder參數,則默認值為vec768l12
使用響度嵌入
添加--vol_aug如果要啟用響度嵌入:
python preprocess_flist_config.py --speech_encoder vec768l12 --vol_aug啟用響度嵌入後,訓練有素的模型將與輸入源的響度相匹配。否則,它將與訓練集的響度相匹配。
keep_ckpts :在訓練過程中保留先前型號的數量。設置為0以保持全部。默認值為3 。
all_in_mem :將所有數據集加載到RAM。當某些平台的磁盤IO太低並且系統內存比數據集大得多時,可以啟用它。
batch_size :單個培訓會話加載到GPU的數據量可以調整到小於GPU內存容量的大小。
vocoder_name :選擇一個vocoder。默認值為nsf-hifigan 。
cache_all_data :將所有數據集加載到RAM。當某些平台的磁盤IO太低並且系統內存比數據集大得多時,可以啟用它。
duration :可以根據視頻記憶的大小來調整訓練期間音頻切片的持續時間,請注意:此值必須小於訓練集中音頻的最小時間!
batch_size :單個培訓會話加載到GPU的數據量可以調整到低於視頻記憶容量的大小。
timesteps :擴散模型中的步驟總數,默認為1000。
k_step_max :訓練只能訓練k_step_max步驟擴散以節省訓練時間,請注意,該值必須小於timesteps ,0是訓練整個擴散模型,請注意:如果不訓練整個擴散模型,則無法使用唯一的_ -Diffusion!
nsf-hifigan
nsf-snake-hifigan
python preprocess_hubert_f0.py --f0_predictor dioF0_predictor具有以下選項
crepe
dio
pm
harvest
rmvpe
fcpe
如果訓練集太嘈雜,建議使用crepe處理F0
如果省略了f0_predictor參數,則默認值為rmvpe
如果要淺擴散(可選),則需要添加--use_diff參數,例如:
python preprocess_hubert_f0.py --f0_predictor dio --use_diff加快預處理的速度
如果您的數據集很大,則可以增加param --num_processes這樣:
python preprocess_hubert_f0.py --f0_predictor dio --num_processes 8如果您有一個以上的GPU,則所有工人將被分配給其他GPU。
完成上述步驟後,數據集目錄將包含預處理數據,並且可以刪除數據集_RAW文件夾。
python train.py -c configs/config.json -m 44k如果需要淺擴散函數,則需要訓練擴散模型。擴散模型訓練方法如下:
python train_diff.py -c configs/diffusion.yaml在培訓期間,模型文件將保存到logs/44k ,擴散模型將保存到logs/44k/diffusion
使用inperion_main.py
# Example
python inference_main.py -m " logs/44k/G_30400.pth " -c " configs/config.json " -n "君の知らない物語-src.wav " -t 0 -s " nen "必需參數:
-m | --model_path :模型的路徑。-c | --config_path :配置文件的路徑。-n | --clean_names :位於raw文件夾中的WAV文件名的列表。-t | --trans :俯仰轉移,支持正(半元素)值。-s | --spk_list :選擇用於轉換的揚聲器ID。-cl | --clip :強制音頻剪輯,將其設置為0 to禁用(默認值),將其設置為非零值(秒為秒)以啟用。可選參數:請參閱下一部分
-lg | --linear_gradient :兩秒鐘內兩個音頻切片的交叉褪色長度。如果強迫切片後有不連續的聲音,則可以調整此值。否則,建議使用默認值為0。-f0p | --f0_predictor :選擇一個F0預測器,選項是crepe , pm , dio , harvest , rmvpe , fcpe ,默認值為pm (注意:使用crepe時F0平均池將啟用)-a | --auto_predict_f0 :自動音調預測,在轉換唱歌聲音時不要啟用這一點,因為它可能會導致嚴重的音調問題。-cm | --cluster_model_path :群集模型或功能檢索索引路徑,如果剩餘空白,它將自動設置為這些模型的默認路徑。如果沒有培訓集群或功能檢索,請隨意填寫。-cr | --cluster_infer_ratio :聚類方案的比例或特徵檢索範圍為0到1。如果沒有訓練聚類模型或功能檢索,則默認值為0。-eh | --enhance :是否使用NSF_HIFIGAN增強器,此選項對某些訓練集很少的模型對聲音質量增強有一定的影響,但對訓練有素的模型具有負面影響,因此默認情況下將其禁用。-shd | --shallow_diffusion :是否使用淺擴散,可以在使用後解決一些電氣問題。此選項默認情況下是禁用的。啟用此選項後,將禁用NSF_HIFIGAN增強器-usm | --use_spk_mix :是否使用動態語音融合-lea | --loudness_envelope_adjustment :與輸出響應比率相關的輸入源的響度信封的調整。接近1的距-fr | --feature_retrieval :如果使用聚類模型,將被禁用, cm和cr參數將成為索引路徑和功能檢索的混合率,是否使用特徵檢索。淺擴散設置:
-dm | --diffusion_model_path :擴散模型路徑-dc | --diffusion_config_path :擴散配置文件路徑-ks | --k_step :k_steps的數量越大,與擴散模型的結果越接近。默認值為100-od | --only_diffusion :是否僅使用擴散模式,該模式不加載Sovits模型僅使用擴散模型推斷-se | --second_encoding :涉及在淺散佈之前對原始音頻進行附加編碼。此選項可以產生不同的結果 - 有時是正面的,有時有時為負。如果使用whisper-ppg語音編碼器進行推斷,則需要將--clip設置為25和-lg至1。否則,它將無法正確推斷。
如果您對先前的結果感到滿意,或者您不理解以下內容,則可以跳過它,並且對模型的使用不會影響。提到的這些可選設置的影響相對較小,儘管它們可能會對特定數據集產生一定的影響,但在大多數情況下,差異可能並不顯著。
在訓練4.0型號的過程中,還對F0預測變量進行了訓練,這可以在語音轉換過程中自動預測。但是,如果結果不滿意,則可以使用手動音高預測。請注意,在轉換唱歌聲音時,建議不要啟用此功能,因為它可能會導致大幅變化。
auto_predict_f0設置為true in inference_main.py 。簡介:該模型中實施的聚類方案旨在減少音色洩漏,並增強受過訓練的模型與目標音色的相似性,儘管效果可能不是很明顯。但是,僅依靠聚類可以降低模型的清晰度,並使其聽起來不那麼明顯。因此,在此模型中採用了一種融合方法來控制聚類和非聚類方法之間的平衡。這允許手動調整“聽起來像目標音色”和“具有清晰的發音”之間的權衡,以找到最佳的平衡。
在現有步驟中無需更改。只需培訓額外的聚類模型,該模型會產生相對較低的培訓成本。
python cluster/train_cluster.py 。輸出模型將保存在logs/44k/kmeans_10000.pt中。python cluster/train_cluster.py --gpuinference_main.py中指定cluster_model_path 。如果未指定,則默認值為logs/44k/kmeans_10000.pt 。inference_main.py中指定cluster_infer_ratio ,其中0表示完全不使用群集, 1僅表示使用群集,通常0.5就足夠了。簡介:與聚類方案一樣,可以減少音色洩漏,發音比聚類略好,但它會降低推理速度。通過採用融合方法,可以線性地控制特徵檢索和非功能檢索之間的平衡,從而對所需比例進行微調。
python train_index.py -c configs/config.json該模型的輸出將在logs/44k/feature_and_index.pkl中
--feature_retrieval需要先配製 - 聚類模式自動切換到功能檢索模式。inference_main.py中指定cluster_model_path 。如果未指定,則默認值為logs/44k/feature_and_index.pkl 。inference_main.py中指定cluster_infer_ratio ,其中0表示完全不使用特徵檢索, 1僅表示僅使用特徵檢索,通常0.5就足夠了。 生成的模型包含進一步培訓所需的數據。如果您確認該模型是最終的,而不是在進一步的培訓中使用,則可以刪除這些數據以獲取較小的文件大小(約1/3)。
# Example
python compress_model.py -c= " configs/config.json " -i= " logs/44k/G_30400.pth " -o= " logs/44k/release.pth " 請參閱webUI.py文件,以獲取小工具/實驗室功能的穩定音色混合。
簡介:此功能可以將多個模型組合為一個模型(凸組合或多個模型參數的線性組合),以創建現實中不存在的混合語音
筆記:
model字段是相同的請參閱spkmix.py文件,以獲取動態音色混合的簡介
角色混合軌道寫作規則:
角色ID:[[開始時間1,結束時間1,開始值1,啟動值1],[開始時間2,結束時間2,開始值2]]
開始時間必須與上一個時間的結束時間相同。第一個開始時間必須為0,最後一個結束時間必須為1(時間為0到1)。
所有角色都必須填補。對於未使用的角色,填充[[0.,1。,0.,0。]]
融合值可以任意填充,並在指定的時間段內將線性從啟動值變為最終值。這
內部線性組合將自動保證為1(凸組合條件),因此可以安全使用
推理時,請使用--use_spk_mix參數啟用動態音色混合
使用onnx_export.py
checkpoints的文件夾並將其打開checkpoints文件夾中創建一個文件夾,在項目之後命名,例如aziplayerconfig.json model.pth aziplayerpath = "NyaruTaffy" "NyaruTaffy" nyarutaffy”在onnx_export.py中的“ nyarutaffy”為您的項目名稱, path = "aziplayer" (onnx_export_speaker_mix可以使您的語音混合使用)model.onnx ,即導出的模型。注意:對於Hubert ONNX型號,請使用Moess提供的型號。目前,他們無法自行出口(Fairseq中的Hubert有許多不支持的操作員,並且涉及常數可能導致錯誤或導致輸入時出現問題的常數問題。)
| URL | 指定 | 標題 | 實現來源 |
|---|---|---|---|
| 2106.06103 | VIT(合成器) | 端到端文本到語音的對抗性學習的條件變異自動編碼器 | jaywalnut310/vits |
| 2111.02392 | SOFTVC(語音編碼器) | 比較離散語音和軟言語單元以改善語音轉換 | Bshall/Hubert |
| 2204.09224 | ContentVec(語音編碼器) | ContentVec:通過解開演講者的改進的自我監督語音表示 | auspious3000/contentvec |
| 2212.04356 | 耳語(語音編碼器) | 通過大規模的弱監督識別強大的語音識別 | Openai/竊竊私語 |
| 2110.13900 | WAVLM(語音編碼器) | WAVLM:大規模自我監督的預培訓,用於完整的堆棧語音處理 | Microsoft/Unilm/wavlm |
| 2305.17651 | Dphubert(語音編碼) | Dphubert:自我監督語音模型的聯合蒸餾和修剪 | pyf98/dphubert |
| doi:10.21437/Interspeech.2017-68 | 收穫(F0預測指標) | 收穫:來自語音信號的高性能基本頻率估計器 | mmorise/世界/收穫 |
| AES35-000039 | DIO(F0預測指標) | 基於歌聲和語音的聲帶振動的周期提取的快速和可靠的F0估計方法 | mmorise/world/dio |
| 8461329 | Crepe(F0預測指標) | 可麗餅:卷積表示音高估計 | MAXRMORRISON/TORCHCREPE |
| doi:10.1016/j.wocn.2018.07.001 | Parselmouth(F0預測指標) | 介紹Parselmouth:Praat的Python界面 | Yannickjadoul/Parselmouth |
| 2306.15412v2 | RMVPE(F0預測指標) | rmvpe:多形音樂中聲音估算的強大模型 | 夢幻/rmvpe |
| 2010.05646 | Hifigan(Vocoder) | HIFI-GAN:生成的對抗網絡,可高效且高保真語音綜合 | JIK876/HIFI-GAN |
| 1810.11946 | NSF(Vocoder) | 基於神經源過濾器的統計參數語音綜合波形模型 | OpenVPI/DIFFSINGER/模塊/NSF_HIFIGAN |
| 2006.08195 | 蛇(Vocoder) | 神經網絡無法學習定期功能以及如何修復它 | Edwarddixon/Snake |
| 2105.02446v3 | 淺擴散(後處理) | DIFFSINGER:通過淺擴散機制唱歌聲音綜合 | CNCHTU/擴散-SVC |
| k均值 | 功能K-均值聚類(預處理) | 一些分類和分析多元觀察的方法 | 這個存儲庫 |
| 功能TOPK檢索(預處理) | 基於檢索的語音轉換 | RVC項目/基於基於檢索的Voice Conversion-webui | |
| 耳語ppg | 耳語ppg | PlayVoice/hisper_ppg | |
| Bigvgan | Bigvgan | PlayVoice/so-Vits-SVC-5.0 |
由於某種原因,作者刪除了原始存儲庫。由於組織成員的疏忽,因此清除了貢獻者列表,因為在此存儲庫重建開始時,所有文件均直接重新上傳到該存儲庫。現在,將以前的貢獻列表添加到readme.md。
一些成員尚未按照他們的個人意願列出。
米斯特 | 小米01 | しぐれ | tomogasukunai | Plachtaa | ZD小達 | 凍聲響世 |
任何組織或者個人不得以醜化、污損,或者利用信息技術手段偽造等方式侵害他人的肖像權。未經肖像權人同意,不得製作、使用、公開肖像權人的肖像,但是法律另有規定的除外。未經肖像權人同意,肖像作品權利人不得以發表、複製、發行、出租、展覽等方式使用或者公開肖像權人的肖像。對自然人聲音的保護,參照適用肖像權保護的有關規定。 ,參照適用肖像權保護的有關規定。
【名譽權】民事主體享有名譽權。任何組織或者個人不得以侮辱、誹謗等方式侵害他人的名譽權。
【作品侵害名譽權】行為人發表的文學、藝術作品以真人真事或者特定人為描述對象,含有侮辱、誹謗內容,侵害他人名譽權的,受害人有權依法請求該行為人承擔民事責任。行為人發表的文學、藝術作品不以特定人為描述對象,僅其中的情節與該特定人的情況相似的,不承擔民事責任。,不承擔民事責任。


