so vits svc
1.0.0
اللغة الإنجليزية |中文简体
هذه الجولة من تحديث الوقت المحدود على نهايتها ، سيدخل المستودع في حالة الأرشفة ، يرجى العلم
استوديو يحتوي على محرر F0 المرئي ، محرر الجدول الزمني لـ SPEAKER MIX وميزات أخرى (حيث يتم استخدام نماذج ONNX): Moevoicestudio
شوكة مع واجهة مستخدم محسّنة بشكل كبير: 34J/SO-VITS-SVC-Fork
يدعم العميل التحويل في الوقت الفعلي: W-Okada/تغيير الصوت
يختلف هذا المشروع بشكل أساسي عن الحالات ، لأنه يركز على غناء تحويل الصوت (SVC) بدلاً من النص إلى كلام (TTS). في هذا المشروع ، لا يتم دعم وظيفة TTS ، وتكون Vits غير قادرة على أداء مهام SVC. من المهم أن نلاحظ أن النماذج المستخدمة في هذين المشروعين ليست قابلة للتبديل أو قابلة للتطبيق عالميًا.
كان الغرض من هذا المشروع هو تمكين المطورين من جعل شخصياتهم المحببة في الأنيمي تؤدي مهام الغناء. كانت نية المطورين هي التركيز فقط على الشخصيات الخيالية وتجنب أي مشاركة للأفراد الحقيقيين ، أي شيء يتعلق بالأفراد الحقيقيين ينحرف عن نية المطور الأصلية.
هذا المشروع عبارة عن مسعى مفتوح المصدر غير متصل بالإنترنت ، ولم يكن لجميع أعضاء SVCDeviverseam ، وكذلك المطورين والمحاربين الآخرين المشاركين (المشار إليها فيما يلي باسم المساهمين) ، أي سيطرة على المشروع. لم يقدم المساهمون أي شكل من أشكال المساعدة لأي منظمة أو فرد ، بما في ذلك على سبيل المثال لا الحصر ، استخراج مجموعة البيانات ، ومعالجة مجموعات البيانات ، ودعم الحوسبة ، ودعم التدريب ، والاستدلال ، وما إلى ذلك. لا يمكن للمساهمين ولا يمكنهم أن يكونوا على دراية بالأغراض التي يستخدمها المستخدمون المشروع. لذلك ، فإن أي نماذج منظمة العفو الدولية والصوت المصنوع المنتجة من خلال تدريب هذا المشروع لا علاقة لها بالمساهمين. أي مشكلات أو عواقب ناشئة عن استخدامها هي المسؤولية الوحيدة للمستخدم.
يتم تشغيل هذا المشروع بشكل غير متصل تمامًا ولا يجمع أي معلومات مستخدم أو جمع بيانات إدخال المستخدم. لذلك ، فإن المساهمين في هذا المشروع ليسوا على دراية بجميع مدخلات المستخدم والنماذج ، وبالتالي لا يتحملون أي إدخال للمستخدم.
يعمل هذا المشروع كإطار فقط ولا يمتلك وظائف توليف الكلام في حد ذاته. تتطلب جميع الوظائف من المستخدمين تدريب النماذج بشكل مستقل. علاوة على ذلك ، لا يأتي هذا المشروع مع أي نماذج ، وأي مشاريع موزعة ثانوية مستقلة عن المساهمين في هذا المشروع.
يستخدم نموذج تحويل الصوت الغنائي مشفر محتوى SoftVC لاستخراج ميزات الكلام من الصوت المصدر. يتم تغذية ناقلات الميزات هذه مباشرة في حالات دون الحاجة إلى التحويل إلى تمثيل وسيط قائم على النص. نتيجة لذلك ، يتم الحفاظ على الملعب وتجميد الصوت الأصلي. وفي الوقت نفسه ، تم استبدال الماسكور بـ NSF Hifigan لحل مشكلة انقطاع الصوت.
config.json . أضف حقل speech_encoder إلى قسم "النموذج" كما هو موضح أدناه: "model": {
.........
"ssl_dim": 256,
"n_speakers": 200,
"speech_encoder":"vec256l9"
}
بناءً على اختباراتنا ، قررنا أن المشروع يعمل على مستقر على Python 3.8.9 .
تحتاج إلى تحديد مشفر واحد من القائمة أدناه
يتطلب vec768l12 و vec256l9 التشفير
pretrainأو قم بتنزيل ContentVec التالي ، الذي لا يزيد حجمه عن 199 ميجابايت ولكن له نفس التأثير:
checkpoint_best_legacy_500.pt ووضعه في دليل pretrain # contentvec
wget -P pretrain/ https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/hubert_base.pt -O checkpoint_best_legacy_500.pt
# Alternatively, you can manually download and place it in the hubert directory pretrain whisper-ppgwhisper-ppg-largepretrain pretrain pretrain wavlmbase+pretrain pretrain ملفات النماذج المدربة مسبقًا: G_0.pth D_0.pth
logs/44k نموذج النموذج الأساسي للنموذج: model_0.pt
logs/44k/diffusionاحصل على نموذج Sovits مسبقًا من SVC-Develop-Team (TBD) أو في أي مكان آخر.
مراجع نموذج الانتشار نموذج الانتشار SVC. نموذج الانتشار الذي تم تدريبه قبل التدريب عالمي مع DDSP-SVC. يمكنك الانتقال إلى REPO من Diffusion-SVC للحصول على نموذج الانتشار الذي تم تدريبه مسبقًا.
في حين أن النموذج المسبق لا يشكل عادة مخاوف حقوق الطبع والنشر ، فمن الضروري أن تظل متيقظًا. يُنصح بالتشاور مع المؤلف مسبقًا أو مراجعة الوصف بعناية للتأكد من الاستخدام المسموح به للنموذج. يساعد ذلك في ضمان الامتثال لأي إرشادات أو قيود محددة بشأن استخدامها.
إذا كنت تستخدم NSF-HIFIGAN enhancer أو shallow diffusion ، فستحتاج إلى تنزيل نموذج NSF-Hifigan المدربين مسبقًا.
pretrain/nsf_hifigan # nsf_hifigan
wget -P pretrain/ https://github.com/openvpi/vocoders/releases/download/nsf-hifigan-v1/nsf_hifigan_20221211.zip
unzip -od pretrain/nsf_hifigan pretrain/nsf_hifigan_20221211.zip
# Alternatively, you can manually download and place it in the pretrain/nsf_hifigan directory
# URL: https://github.com/openvpi/vocoders/releases/tag/nsf-hifigan-v1 إذا كنت تستخدم تنبؤ rmvpe F0 ، فستحتاج إلى تنزيل نموذج RMVPE الذي تم تدريبه مسبقًا.
rmvpe.zip , وقم بإعادة تسمية ملف model.pt إلى rmvpe.pt ووضعه تحت دليل pretrain .pretrain FCPE (مقدر الملعب السريع للسياق) هو تنبؤ مخصص F0 مصمم لتحويل الصوت في الوقت الفعلي وسيصبح المتنبئ F0 المفضل لتحويل الصوت في الوقت الفعلي في المستقبل. (تتم كتابة الورقة)
إذا كنت تستخدم تنبؤ fcpe F0 ، فستحتاج إلى تنزيل نموذج FCPE الذي تم تدريبه مسبقًا.
pretrain ما عليك سوى وضع مجموعة البيانات في دليل dataset_raw مع بنية الملف التالية:
dataset_raw
├───speaker0
│ ├───xxx1-xxx1.wav
│ ├───...
│ └───Lxx-0xx8.wav
└───speaker1
├───xx2-0xxx2.wav
├───...
└───xxx7-xxx007.wav
لا توجد قيود محددة على تنسيق الاسم لكل ملف صوتي (اتفاقيات تسمية مثل 000001.wav to 999999.wav صالحة أيضًا) ، ولكن يجب أن يكون نوع الملف "wav``.
يمكنك تخصيص اسم السماعة كما هو موضح أدناه:
dataset_raw
└───suijiSUI
├───1.wav
├───...
└───25788785-20221210-200143-856_01_(Vocals)_0_0.wav
لتجنب تدفق ذاكرة الفيديو أثناء التدريب أو المعالجة المسبقة ، يوصى بالحد من طول مقاطع الصوت. يوصى بقطع الصوت إلى طول "5s - 15s". أوقات أطول بقليل مقبولة ، ومع ذلك ، قد تسبب مقاطع طويلة بشكل مفرط مشاكل مثل torch.cuda.OutOfMemoryError .
لتسهيل عملية التقطيع ، يمكنك استخدام Sucker-Gui أو Audio-Slicer-Cli
بشكل عام ، يجب تعديل Minimum Interval . بالنسبة للصوت المنطوق ، عادة ما تكفي القيمة الافتراضية ، بينما يمكن تعديلها إلى حوالي 100 أو حتى 50 ، اعتمادًا على المتطلبات المحددة.
بعد التقطيع ، يوصى بإزالة أي مقاطع صوتية طويلة أو قصيرة جدًا.
إذا كنت تستخدم تشفير Whisper-PPG للتدريب ، فيجب أن تكون مقاطع الصوت أقصر من الثلاثينات.
python resample.py على الرغم من أن هذا المشروع يحتوي على reglate.py البرامج النصية لإعادة أخذ العينات ، و mono و lootness مطابقة ، فإن مطابقة الصوت الافتراضية هي مطابقة 0DB. هذا يمكن أن يسبب أضرارا لجودة الصوت. في حين أن حزمة مطابقة Lootness الخاصة ببيثون لا تحد من المستوى ، فإن هذا يمكن أن يؤدي إلى طفرة صوتية. لذلك ، يوصى بالنظر في استخدام برامج معالجة الصوت المهنية ، مثل adobe audition لمطابقة الصوت. إذا كنت تستخدم بالفعل برامج أخرى لمطابقة الصوت ، فأضف المعلمة -skip_loudnorm إلى الأمر Run:
python resample.py --skip_loudnormpython preprocess_flist_config.py --speech_encoder vec768l12الكلام _encoder لديه الخيارات التالية
vec768l12
vec256l9
hubertsoft
whisper-ppg
cnhubertlarge
dphubert
whisper-ppg-large
wavlmbase+
إذا تم حذف وسيطة الكلام _encoder ، فإن القيمة الافتراضية هي vec768l12
استخدم تضمين الصوت
إضافة --vol_aug إذا كنت ترغب في تمكين الصوت الصاخب:
python preprocess_flist_config.py --speech_encoder vec768l12 --vol_augبعد تمكين التضمين الصاخب ، سوف يتطابق النموذج المدرب مع صوت مصدر الإدخال ؛ خلاف ذلك ، سوف يتطابق مع صوت مجموعة التدريب.
keep_ckpts : حافظ على عدد النماذج السابقة أثناء التدريب. ضبط على 0 للحفاظ على كل شيء. الافتراضي هو 3 .
all_in_mem : قم بتحميل جميع مجموعة البيانات إلى ذاكرة الوصول العشوائي. يمكن تمكينه عندما يكون القرص IO لبعض المنصات منخفضة للغاية وذاكرة النظام أكبر بكثير من مجموعة البيانات الخاصة بك.
batch_size : يمكن ضبط كمية البيانات المحملة على وحدة معالجة الرسومات لجلسة تدريبية واحدة بحجم أقل من سعة ذاكرة GPU.
vocoder_name : حدد Vocoder. الافتراضي هو nsf-hifigan .
cache_all_data : قم بتحميل جميع مجموعة البيانات إلى ذاكرة الوصول العشوائي. يمكن تمكينه عندما يكون القرص IO لبعض المنصات منخفضة للغاية وذاكرة النظام أكبر بكثير من مجموعة البيانات الخاصة بك.
duration : يمكن تعديل مدة تقطيع الصوت أثناء التدريب ، وفقًا لحجم ذاكرة الفيديو ، ملاحظة: يجب أن تكون هذه القيمة أقل من الحد الأدنى لوقت الصوت في مجموعة التدريب!
batch_size : يمكن ضبط كمية البيانات المحملة على وحدة معالجة الرسومات لجلسة تدريبية واحدة بحجم أقل من سعة ذاكرة الفيديو.
timesteps : إجمالي عدد الخطوات في نموذج الانتشار ، والذي يتخلف عن 1000.
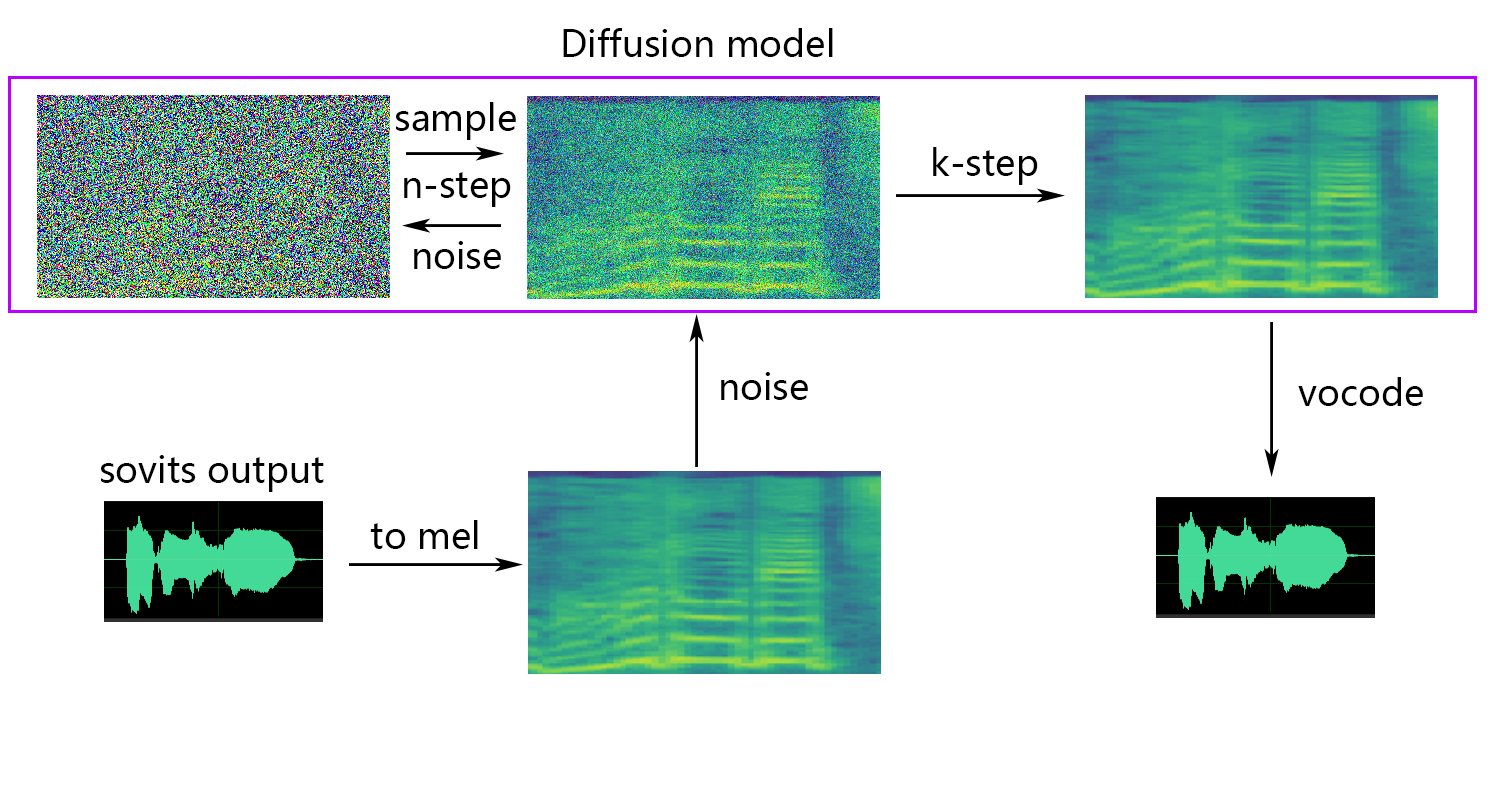
k_step_max : يمكن للتدريب فقط تدريب نشر الخطوة k_step_max لتوفير وقت التدريب ، لاحظ أن القيمة يجب أن تكون أقل من timesteps ، 0 هي تدريب نموذج الانتشار بأكمله ، ملاحظة: إذا لم تقم بتدريب نموذج الانتشار بأكمله ، فلن يتمكن نموذج الانتشار بالكامل فقط _diffusion!
nsf-hifigan
nsf-snake-hifigan
python preprocess_hubert_f0.py --f0_predictor dioF0_predictor لديه الخيارات التالية
crepe
dio
pm
harvest
rmvpe
fcpe
إذا كانت مجموعة التدريب صاخبة للغاية ، فمن المستحسن استخدام crepe للتعامل مع F0
إذا تم حذف المعلمة f0_predictor ، فإن القيمة الافتراضية هي rmvpe
إذا كنت تريد الانتشار الضحل (اختياري) ، فأنت بحاجة إلى إضافة المعلمة --use_diff ، على سبيل المثال:
python preprocess_hubert_f0.py --f0_predictor dio --use_diffتسريع المعالجة المسبقة
إذا كانت مجموعة البيانات الخاصة بك كبيرة جدًا ، فيمكنك زيادة المعلمة --num_processes من هذا القبيل:
python preprocess_hubert_f0.py --f0_predictor dio --num_processes 8سيتم تعيين جميع العامل إلى وحدة معالجة الرسومات المختلفة إذا كان لديك أكثر من وحدات معالجة الرسومات.
بعد الانتهاء من الخطوات المذكورة أعلاه ، سيحتوي دليل مجموعة البيانات على البيانات المعالجة مسبقًا ، ويمكن حذف مجلد Dataset_raw.
python train.py -c configs/config.json -m 44kإذا كانت هناك حاجة إلى وظيفة الانتشار الضحلة ، فيجب تدريب نموذج الانتشار. طريقة تدريب نموذج الانتشار هي كما يلي:
python train_diff.py -c configs/diffusion.yaml أثناء التدريب ، سيتم حفظ ملفات النماذج إلى logs/44k ، وسيتم حفظ نموذج الانتشار في logs/44k/diffusion
استخدم Interference_main.py
# Example
python inference_main.py -m " logs/44k/G_30400.pth " -c " configs/config.json " -n "君の知らない物語-src.wav " -t 0 -s " nen "المعلمات المطلوبة:
-m | --model_path : مسار إلى النموذج.-c | --config_path : مسار إلى ملف التكوين.-n | --clean_names : قائمة بأسماء ملفات WAV الموجودة في المجلد raw .-t | --trans : تحول الملعب ، يدعم القيم الإيجابية والسلبية (النمفية).-s | --spk_list : حدد معرف السماعة لاستخدامه في التحويل.-cl | --clip : قطع الصوت القسري ، تم تعيينه على 0 لتعطيل (افتراضي) ، وضعه على قيمة غير صفرية (المدة في الثواني) لتمكين.المعلمات الاختيارية: انظر القسم التالي
-lg | --linear_gradient : طول التلاشي المتقاطع لشرائح صوتية في ثوانٍ. إذا كان هناك صوت متقطع بعد التقطيع القسري ، فيمكنك ضبط هذه القيمة. خلاف ذلك ، يوصى باستخدام القيمة الافتراضية لـ 0.-f0p | --f0_predictor : حدد تنبؤًا F0 ، والخيارات هي crepe ، pm ، dio ، harvest ، rmvpe ، fcpe ، القيمة الافتراضية هي pm (ملاحظة: سيتم تمكين تجميع F0 عند استخدام crepe )-a | --auto_predict_f0 : التنبؤ التلقائي في الملعب ، لا تمكّن ذلك عند تحويل أصوات الغناء لأنه يمكن أن يسبب مشكلات خطيرة في الملعب.-cm | --cluster_model_path : مسار فهرس استرجاع الكتلة أو ميزة ، إذا تركت فارغة ، فسيتم تعيينها تلقائيًا كمسار افتراضي لهذه النماذج. إذا لم يكن هناك مجموعة تدريب أو استرجاع ميزة ، املأ في الإرادة.-cr | --cluster_infer_ratio : نسبة مخطط التجميع أو نطاقات استرجاع الميزات من 0 إلى 1. إذا لم يكن هناك نموذج تجميع التدريب أو استرجاع الميزة ، فإن الافتراضي هو 0.-eh | --enhance : ما إذا كان يجب استخدام NSF_Hifigan Enhancer ، فإن هذا الخيار له تأثير معين على تحسين جودة الصوت لبعض النماذج مع عدد قليل من مجموعات التدريب ، ولكن له تأثير سلبي على النماذج المدربة جيدًا ، لذلك يتم تعطيله افتراضيًا.-shd | --shallow_diffusion : ما إذا كان يجب استخدام الانتشار الضحل ، والذي يمكنه حل بعض مشاكل الصوت الكهربائي بعد الاستخدام. يتم تعطيل هذا الخيار افتراضيًا. عند تمكين هذا الخيار ، سيتم تعطيل NSF_Hifigan Enhancer-usm | --use_spk_mix : ما إذا كنت تريد استخدام الانصهار الصوتي الديناميكي-lea | --loudness_envelope_adjustment : تعديل مغلف صوت مصدر الإدخال فيما يتعلق بنسبة الانصهار في غلاف انطلاق الإخراج. كلما اقتربت من 1 ، كلما تم استخدام مظروف بصوت عالٍ أكثر-fr | --feature_retrieval : ما إذا كان يجب استخدام استرجاع الميزات إذا تم استخدام نموذج التجميع ، وسيتم تعطيله ، وسيصبح معلمات cm و cr مسار الفهرس ونسبة الخلط لاسترجاع الميزاتإعدادات الانتشار الضحلة:
-dm | --diffusion_model_path : مسار نموذج الانتشار-dc | --diffusion_config_path : مسار ملف تكوين الانتشار-ks | --k_step : كلما زاد عدد k_steps ، كلما اقترب من نتيجة نموذج الانتشار. الافتراضي هو 100-od | --only_diffusion : ما إذا كنت تريد استخدام وضع الانتشار فقط ، والذي لا يقوم بتحميل نموذج SOVITS لاستخدام نموذج نشر النشر فقط-se | --second_encoding : والتي تتضمن تطبيق ترميز إضافي على الصوت الأصلي قبل الانتشار الضحل. يمكن أن ينتج عن هذا الخيار نتائج مختلفة - في بعض الأحيان إيجابية وأحيانًا سلبية. إذا كان الاستدلال باستخدام تشفير الكلام whisper-ppg ، فأنت بحاجة إلى ضبط --clip إلى 25 و -lg إلى 1. وإلا فإنه ستفشل في الاستنتاج بشكل صحيح.
إذا كنت راضيًا عن النتائج السابقة ، أو إذا كنت لا تشعر أنك تفهم ما يلي ، فيمكنك تخطيه ولن يكون له أي تأثير على استخدام النموذج. تأثير هذه الإعدادات الاختيارية المذكورة صغيرة نسبيًا ، وعلى الرغم من أنها قد يكون لها بعض التأثير على مجموعات البيانات المحددة ، إلا أن الفرق قد لا يكون كبيرًا.
أثناء تدريب نموذج 4.0 ، يتم تدريب تنبؤ F0 أيضًا ، والذي يتيح التنبؤ التلقائي في الملعب أثناء تحويل الصوت. ومع ذلك ، إذا لم تكن النتائج مرضية ، فيمكن استخدام التنبؤ اليدوي بدلا من ذلك. يرجى ملاحظة أنه عند تحويل أصوات الغناء ، يُنصح بعدم تمكين هذه الميزة لأنها قد تتسبب في تحول كبير في الملعب.
auto_predict_f0 إلى true in inference_main.py .مقدمة: يهدف مخطط التجميع الذي تم تنفيذه في هذا النموذج إلى تقليل تسرب Timbre وتعزيز تشابه النموذج المدرب مع timbre الهدف ، على الرغم من أن التأثير قد لا يكون واضحًا للغاية. ومع ذلك ، فإن الاعتماد فقط على التجميع يمكن أن يقلل من وضوح النموذج ويجعله يبدو أقل تميزًا. لذلك ، يتم اعتماد طريقة الانصهار في هذا النموذج للتحكم في التوازن بين نهج التجميع وغير المتجانسة. يتيح ذلك التعديل اليدوي للمفاضلة بين "السبر مثل timbre الهدف" و "لديهم عملية تعبير واضح" لإيجاد توازن مثالي.
لا توجد تغييرات مطلوبة في الخطوات الحالية. ما عليك سوى تدريب نموذج تجميع إضافي ، والذي يتحمل تكاليف تدريب منخفضة نسبيًا.
python cluster/train_cluster.py . سيتم حفظ نموذج الإخراج في logs/44k/kmeans_10000.pt .pt.python cluster/train_cluster.py --gpucluster_model_path في inference_main.py . إذا لم يتم تحديدها ، فإن الافتراضي هو logs/44k/kmeans_10000.pt .pt.cluster_infer_ratio في inference_main.py ، حيث يعني 0 عدم استخدام التجميع على الإطلاق ، 1 يعني فقط استخدام المجموعات ، وعادة ما يكون 0.5 كافيًا.مقدمة: كما هو الحال مع مخطط التجميع ، يمكن تقليل تسرب timbre ، والانبط أفضل قليلاً من التجميع ، ولكنه سيقلل من سرعة الاستنتاج. من خلال استخدام طريقة الانصهار ، يصبح من الممكن التحكم خطيًا في التوازن بين استرجاع الميزات واسترجاع غير الميزة ، مما يتيح ضبط النسبة المطلوبة.
python train_index.py -c configs/config.json سيكون إخراج النموذج في logs/44k/feature_and_index.pkl
--feature_retrieval أولاً ، ويتم تشغيل وضع التجميع تلقائيًا إلى وضع استرجاع الميزة.cluster_model_path في inference_main.py . إذا لم يتم تحديدها ، فإن الافتراضي هو logs/44k/feature_and_index.pkl .cluster_infer_ratio في inference_main.py ، حيث يعني 0 عدم استخدام استرجاع الميزات على الإطلاق ، 1 يعني فقط استخدام استرجاع الميزة ، وعادة ما يكون 0.5 كافيًا. يحتوي النموذج الذي تم إنشاؤه على بيانات مطلوبة لمزيد من التدريب. إذا أكدت أن النموذج نهائي ولا يتم استخدامه في مزيد من التدريب ، فمن الآمن إزالة هذه البيانات للحصول على حجم ملف أصغر (حوالي 1/3).
# Example
python compress_model.py -c= " configs/config.json " -i= " logs/44k/G_30400.pth " -o= " logs/44k/release.pth " ارجع إلى ملف webUI.py لخلط timbre المستقر لميزة الأداة/المختبر.
مقدمة: يمكن أن تجمع هذه الوظيفة بين نماذج متعددة في نموذج واحد (مزيج محدب أو مزيج خطي من معلمات النموذج المتعددة) لإنشاء صوت مختلط غير موجود في الواقع
ملحوظة:
model في config.json من جميع النماذج المراد خلطها هي نفسها ارجع إلى ملف spkmix.py للحصول على مقدمة لخلط timbre الديناميكي
قواعد كتابة مزيج الأحرف:
معرف الدور: [[وقت البدء 1 ، وقت الانتهاء 1 ، قيمة البدء 1 ، قيمة البدء 1] ، [وقت البدء 2 ، وقت الانتهاء 2 ، قيمة البدء 2]]
يجب أن يكون وقت البدء هو نفسه وقت نهاية السابق. يجب أن يكون وقت البدء الأول 0 ، ويجب أن يكون الوقت الأخير 1 (يتراوح الوقت من 0 إلى 1).
يجب ملء جميع الأدوار. للأدوار غير المستخدمة ، ملء [[0. ، 1. ، 0. ، 0.]]
يمكن ملء قيمة الانصهار بشكل تعسفي ، والتغيير الخطي من قيمة البداية إلى القيمة النهائية خلال فترة الزمن المحددة. ال
سيتم ضمان تركيبة خطية داخلية تلقائيًا لتكون 1 (حالة مجموعة محدبة) ، بحيث يمكن استخدامها بأمان
استخدم المعلمة --use_spk_mix عند التفكير لتمكين خلط timbre الديناميكي
استخدم onnx_export.py
checkpoints وفتحهcheckpoints كمجلد لمشروعك ، وتسميةه بعد مشروعك ، على سبيل المثال aziplayerconfig.json النموذج aziplayer بك model.pth"NyaruTaffy" في path = "NyaruTaffy" في onnx_export.py إلى اسم مشروعك ، path = "aziplayer" (onnx_export_speaker_mix يجعلك يمكنك مزج صوت السماعة)model.onnx في مجلد المشروع الخاص بك ، وهو النموذج المصدر.ملاحظة: بالنسبة لنماذج Hubert Onnx ، يرجى استخدام النماذج التي توفرها Moess. في الوقت الحالي ، لا يمكن تصديرها بمفردها (لدى Hubert في Fairseq العديد من المشغلين غير المدعومين والأشياء التي تنطوي على ثوابت يمكن أن تسبب أخطاء أو تؤدي إلى مشاكل في شكل الإدخال/الإخراج والنتائج عند تصديرها.)
| عنوان URL | تعيين | عنوان | مصدر التنفيذ |
|---|---|---|---|
| 2106.06103 | حالات (مزج) | أدوات تلقائية متغيرة مشروطة مع تعلم عدواني للرسالة من نص إلى طرف إلى خط الكلام | Jaywalnut310/vits |
| 2111.02392 | Softvc (تشفير الكلام) | مقارنة بين وحدات الكلام المنفصلة والناعمة لتحسين التحويل الصوتي | Bshall/Hubert |
| 2204.09224 | ContentVec (تشفير الكلام) | ContentVec: تمثيل خطاب محسّن خضع لذاته من خلال تفكيك المتحدثين | AUSPIUCITION3000/contentVec |
| 2212.04356 | الهمس (تشفير الكلام) | اعتراف قوي بالكلام عبر إشراف ضعيف على نطاق واسع | Openai/Whisper |
| 2110.13900 | wavlm (تشفير الكلام) | WAVLM: التدريب على نطاق واسع على نطاق واسع من أجل معالجة الكلام الكامل للكتابة | Microsoft/Unilm/Wavlm |
| 2305.17651 | Dphubert (تشفير الكلام) | Dphubert: التقطير المشترك وتشذيب نماذج الكلام الخاضعة للإشراف ذاتيا | PYF98/dphubert |
| doi: 10.21437/interspeech.2017-68 | الحصاد (تنبؤ F0) | الحصاد: مقدر تردد أساسي عالي الأداء من إشارات الكلام | Mmorise/العالم/الحصاد |
| AES35-000039 | DIO (F0 Prepictor) | طريقة تقدير F0 السريعة والموثوقة بناءً على استخراج فترة الاهتزاز الصوتية من صوت الغناء والكلام | Mmorise/World/Dio |
| 8461329 | كريب (تنبؤ F0) | كريب: تمثيل تلافيفي لتقدير الملعب | maxrmorrison/torchcrepe |
| doi: 10.1016/j.wocn.2018.07.001 | Parselmouth (F0 Prepictor) | تقديم Parselmouth: واجهة Python إلى Praat | Yannickjadoul/Parselmouth |
| 2306.15412v2 | RMVPE (تنبؤ F0) | RMVPE: نموذج قوي لتقدير الملعب الصوتي في الموسيقى متعددة الفقرة | الحلم عالية/RMVPE |
| 2010.05646 | Hifigan (Vocoder) | HIFI-Gang | JIK876/HIFI-GAN |
| 1810.11946 | NSF (Vocoder) | نموذج الموجة الموجي المستند إلى مرشح المصدر العصبي لتوليف الكلام الحدودي الإحصائي | OpenVPI/diffsinger/الوحدات النمطية/nsf_hifigan |
| 2006.08195 | الأفعى (Vocoder) | تفشل الشبكات العصبية في تعلم الوظائف الدورية وكيفية إصلاحها | Edwarddixon/Snake |
| 2105.02446v3 | الانتشار الضحل (ما بعد المعالجة) | Diffsinger: غناء تخليق الصوت عبر آلية الانتشار الضحلة | cnchtu/diffusion-svc |
| K-Means | ميزة التجميع K-means (المعالجة المسبقة) | بعض طرق تصنيف وتحليل الملاحظات متعددة المتغيرات | هذا الريبو |
| ميزة Topk Retrieval (المعالجة المسبقة) | تحويل الصوت القائم على الاسترجاع | RVC-Project/Retrieval-Voice-Conversion-Webui | |
| الهمس PPG | الهمس PPG | playvoice/whisper_ppg | |
| Bigvgan | Bigvgan | playvoice/so-its-svc-5.0 |
لسبب ما حذف المؤلف المستودع الأصلي. بسبب إهمال أعضاء المؤسسة ، تم مسح قائمة المساهمين لأنه تم إعادة تحميل جميع الملفات مباشرة إلى هذا المستودع في بداية إعادة بناء هذا المستودع. أضف الآن قائمة مساهمات سابقة إلى readme.md.
بعض الأعضاء لم يدرجوا وفقًا لرغباتهم الشخصية.
Misteo | Xiaomiku01 | しぐれ | Tomogasukunai | plachtaa | ZD 小达 | 凍聲響世 |
任何组织或者个人不得以丑化、污损 , 或者利用信息技术手段伪造等方式侵害他人的肖像权。未经肖像权人同意 , 不得制作、使用、公开肖像权人的肖像 , 但是法律另有规定的除外。未经肖像权人同意 , 肖像作品权利人不得以发表、复制、发行、出租、展览等方式使用或者公开肖像权人的肖像。对自然人声音的保护 , 参照适用肖像权保护的有关规定。
【名誉权】民事主体享有名誉权。任何组织或者个人不得以侮辱、诽谤等方式侵害他人的名誉权。
【作品侵害名誉权】行为人发表的文学、艺术作品以真人真事或者特定人为描述对象 , 含有侮辱、诽谤内容 , 侵害他人名誉权的 , 受害人有权依法请求该行为人承担民事责任。行为人发表的文学、艺术作品不以特定人为描述对象 , 仅其中的情节与该特定人的情况相似的 , 不承担民事责任。


