so vits svc
1.0.0
Bahasa Inggris |中文简体
Putaran pembaruan waktu terbatas ini akan segera berakhir, gudang akan memasuki negara Archieve, harap diketahui
Studio yang berisi editor F0 yang terlihat, editor timeline campuran speaker dan fitur lainnya (di mana model ONNX digunakan): Moevoicestudio
Garpu dengan antarmuka pengguna yang sangat ditingkatkan: 34j/so-vits-svc-fork
Klien mendukung konversi real-time: w-okada/pengubah suara
Proyek ini berbeda secara fundamental dari VIT, karena berfokus pada menyanyi konversi suara (SVC) daripada teks-ke-pidato (TTS). Dalam proyek ini, fungsionalitas TTS tidak didukung, dan VIT tidak mampu melakukan tugas SVC. Penting untuk dicatat bahwa model yang digunakan dalam kedua proyek ini tidak dapat dipertukarkan atau berlaku secara universal.
Tujuan dari proyek ini adalah untuk memungkinkan pengembang untuk membuat karakter anime tercinta mereka melakukan tugas menyanyi. Niat pengembang adalah untuk hanya berfokus pada karakter fiksi dan menghindari keterlibatan individu nyata, apa pun yang terkait dengan individu nyata menyimpang dari niat asli pengembang.
Proyek ini adalah open-source, usaha offline, dan semua anggota SVCDevelopteam, serta pengembang dan pengelola lain yang terlibat (selanjutnya disebut sebagai kontributor), tidak memiliki kendali atas proyek. Para kontributor tidak pernah memberikan bentuk bantuan apa pun kepada organisasi atau individu mana pun, termasuk tetapi tidak terbatas pada ekstraksi dataset, pemrosesan dataset, dukungan komputasi, dukungan pelatihan, inferensi, dan sebagainya. Para kontributor tidak dan tidak dapat menyadari tujuan yang digunakan pengguna. Oleh karena itu, setiap model AI dan audio yang disintesis yang diproduksi melalui pelatihan proyek ini tidak terkait dengan kontributor. Setiap masalah atau konsekuensi yang timbul dari penggunaannya adalah tanggung jawab satu -satunya pengguna.
Proyek ini dijalankan sepenuhnya offline dan tidak mengumpulkan informasi pengguna atau mengumpulkan data input pengguna. Oleh karena itu, kontributor untuk proyek ini tidak mengetahui semua input dan model pengguna dan karenanya tidak bertanggung jawab atas input pengguna apa pun.
Proyek ini hanya berfungsi sebagai kerangka kerja dan tidak memiliki fungsi sintesis wicara dengan sendirinya. Semua fungsi mengharuskan pengguna untuk melatih model secara mandiri. Selain itu, proyek ini tidak dibundel dengan model apa pun, dan setiap proyek terdistribusi sekunder tidak tergantung pada kontributor proyek ini.
Model konversi suara bernyanyi menggunakan encoder konten softVC untuk mengekstrak fitur ucapan dari audio sumber. Vektor fitur ini secara langsung dimasukkan ke dalam Vit tanpa perlu konversi ke representasi perantara berbasis teks. Akibatnya, nada dan intonasi audio asli dipertahankan. Sementara itu, vocoder digantikan dengan NSF hifigan untuk menyelesaikan masalah gangguan suara.
config.json . Tambahkan bidang speech_encoder ke bagian "Model" seperti yang ditunjukkan di bawah ini: "model": {
.........
"ssl_dim": 256,
"n_speakers": 200,
"speech_encoder":"vec256l9"
}
Berdasarkan pengujian kami, kami telah menentukan bahwa proyek berjalan stabil pada Python 3.8.9 .
Anda perlu memilih satu encoder dari daftar di bawah ini
vec768l12 dan vec256l9 memerlukan encoder
pretrainAtau unduh ContentVec berikut, yang hanya berukuran 199mb tetapi memiliki efek yang sama:
checkpoint_best_legacy_500.pt dan letakkan di direktori pretrain # contentvec
wget -P pretrain/ https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/hubert_base.pt -O checkpoint_best_legacy_500.pt
# Alternatively, you can manually download and place it in the hubert directory pretrain whisper-ppgwhisper-ppg-largepretrain pretrain pretrain wavlmbase+pretrain pretrain File model pra-terlatih: G_0.pth D_0.pth
logs/44k File model dasar pretraining model difusi: model_0.pt
logs/44k/diffusionDapatkan model pra-terlatih Sovits dari SVC-Develops-Team (TBD) atau di mana pun.
Model Difusi Referensi Model Difusi Difusi-SVC. Model difusi pra-terlatih bersifat universal dengan DDSP-SVC. Anda dapat pergi ke repo difusi-SVC untuk mendapatkan model difusi pra-terlatih.
Sementara model pretrain biasanya tidak menimbulkan kekhawatiran hak cipta, penting untuk tetap waspada. Dianjurkan untuk berkonsultasi dengan penulis sebelumnya atau dengan hati -hati meninjau deskripsi untuk memastikan penggunaan model yang diizinkan. Ini membantu memastikan kepatuhan terhadap pedoman atau pembatasan yang ditentukan mengenai pemanfaatannya.
Jika Anda menggunakan NSF-HIFIGAN enhancer atau shallow diffusion , Anda perlu mengunduh model NSF-Hifigan yang sudah dilatih sebelumnya.
pretrain/nsf_hifigan # nsf_hifigan
wget -P pretrain/ https://github.com/openvpi/vocoders/releases/download/nsf-hifigan-v1/nsf_hifigan_20221211.zip
unzip -od pretrain/nsf_hifigan pretrain/nsf_hifigan_20221211.zip
# Alternatively, you can manually download and place it in the pretrain/nsf_hifigan directory
# URL: https://github.com/openvpi/vocoders/releases/tag/nsf-hifigan-v1 Jika Anda menggunakan prediktor rmvpe F0, Anda perlu mengunduh model RMVPE yang sudah terlatih.
rmvpe.zip , dan ganti nama file model.pt ke rmvpe.pt dan letakkan di bawah direktori pretrain .pretrain FCPE (Estimator Pitch Basis Konteks Cepat) adalah prediktor F0 khusus yang dirancang untuk konversi suara real-time dan akan menjadi prediktor F0 yang disukai untuk konversi suara real-time di masa depan (makalah ini sedang ditulis)
Jika Anda menggunakan prediktor fcpe F0, Anda harus mengunduh model FCPE yang sudah terlatih.
pretrain Cukup tempatkan dataset di direktori dataset_raw dengan struktur file berikut:
dataset_raw
├───speaker0
│ ├───xxx1-xxx1.wav
│ ├───...
│ └───Lxx-0xx8.wav
└───speaker1
├───xx2-0xxx2.wav
├───...
└───xxx7-xxx007.wav
Tidak ada batasan khusus pada format nama untuk setiap file audio (penamaan konvensi seperti 000001.wav hingga 999999.wav juga valid), tetapi jenis file harus `wav``.
Anda dapat menyesuaikan nama speaker seperti yang ditunjukkan di bawah ini:
dataset_raw
└───suijiSUI
├───1.wav
├───...
└───25788785-20221210-200143-856_01_(Vocals)_0_0.wav
Untuk menghindari overflow memori video selama pelatihan atau pra-pemrosesan, disarankan untuk membatasi panjang klip audio. Memotong audio ke panjang "5s - 15s" lebih dianjurkan. Namun, waktu yang sedikit lebih lama dapat diterima, klip yang terlalu lama dapat menyebabkan masalah seperti torch.cuda.OutOfMemoryError .
Untuk memfasilitasi proses pengiris, Anda dapat menggunakan audio-slicer-gui atau audio-slicer-cli
Secara umum, hanya Minimum Interval yang perlu disesuaikan. Untuk audio lisan, nilai default biasanya cukup, sementara untuk menyanyikan audio, itu dapat disesuaikan dengan sekitar 100 atau bahkan 50 , tergantung pada persyaratan spesifik.
Setelah mengiris, disarankan untuk menghapus klip audio yang terlalu panjang atau terlalu pendek.
Jika Anda menggunakan Encoder Whisper-PPG untuk pelatihan, klip audio harus lebih pendek dari 30-an.
python resample.py Meskipun proyek ini memiliki skrip resample.py untuk resampling, pencocokan mono dan kenyaringan, pencocokan kenyaringan default adalah untuk mencocokkan dengan 0DB. Ini dapat menyebabkan kerusakan pada kualitas suara. Sementara paket pencocokan kenyaringan Python Pyloudnorm tidak membatasi level, ini dapat menyebabkan booming sonik. Oleh karena itu, disarankan untuk mempertimbangkan menggunakan perangkat lunak pemrosesan suara profesional, seperti adobe audition untuk pencocokan kenyaringan. Jika Anda sudah menggunakan perangkat lunak lain untuk pencocokan kenyaringan, tambahkan parameter -skip_loudnorm ke perintah run:
python resample.py --skip_loudnormpython preprocess_flist_config.py --speech_encoder vec768l12pidato_encoder memiliki opsi berikut
vec768l12
vec256l9
hubertsoft
whisper-ppg
cnhubertlarge
dphubert
whisper-ppg-large
wavlmbase+
Jika argumen wicara_encoder dihilangkan, nilai standarnya adalah vec768l12
Gunakan embedding kenyaringan
Tambahkan --vol_aug jika Anda ingin mengaktifkan embedding kenyaringan:
python preprocess_flist_config.py --speech_encoder vec768l12 --vol_augSetelah mengaktifkan embedding kenyaringan, model terlatih akan cocok dengan kenyaringan sumber input; Kalau tidak, itu akan cocok dengan kenyaringan set pelatihan.
keep_ckpts : Jaga agar jumlah model sebelumnya selama pelatihan. Diatur ke 0 untuk menjaga semuanya. Default adalah 3 .
all_in_mem : Muat semua dataset ke RAM. Ini dapat diaktifkan ketika disk IO dari beberapa platform terlalu rendah dan memori sistem jauh lebih besar dari dataset Anda.
batch_size : Jumlah data yang dimuat ke GPU untuk sesi pelatihan tunggal dapat disesuaikan dengan ukuran yang lebih rendah dari kapasitas memori GPU.
vocoder_name : Pilih vocoder. Standarnya adalah nsf-hifigan .
cache_all_data : Muat semua dataset ke RAM. Ini dapat diaktifkan ketika disk IO dari beberapa platform terlalu rendah dan memori sistem jauh lebih besar dari dataset Anda.
duration : Durasi pengiris audio selama pelatihan, dapat disesuaikan sesuai dengan ukuran memori video, CATATAN: Nilai ini harus kurang dari waktu minimum audio dalam set pelatihan!
batch_size : Jumlah data yang dimuat ke GPU untuk sesi pelatihan tunggal dapat disesuaikan dengan ukuran yang lebih rendah dari kapasitas memori video.
timesteps : Jumlah total langkah dalam model difusi, yang default menjadi 1000.
k_step_max : Pelatihan hanya dapat melatih difusi langkah k_step_max untuk menghemat waktu pelatihan, perhatikan bahwa nilainya harus kurang dari timesteps , 0 adalah untuk melatih seluruh model difusi, Catatan: Jika Anda tidak melatih seluruh model difusi tidak akan dapat digunakan Hanya_diffusion!
nsf-hifigan
nsf-snake-hifigan
python preprocess_hubert_f0.py --f0_predictor diof0_predictor memiliki opsi berikut
crepe
dio
pm
harvest
rmvpe
fcpe
Jika set pelatihan terlalu bising, disarankan untuk menggunakan crepe untuk menangani f0
Jika parameter F0_Predictor dihilangkan, nilai defaultnya adalah rmvpe
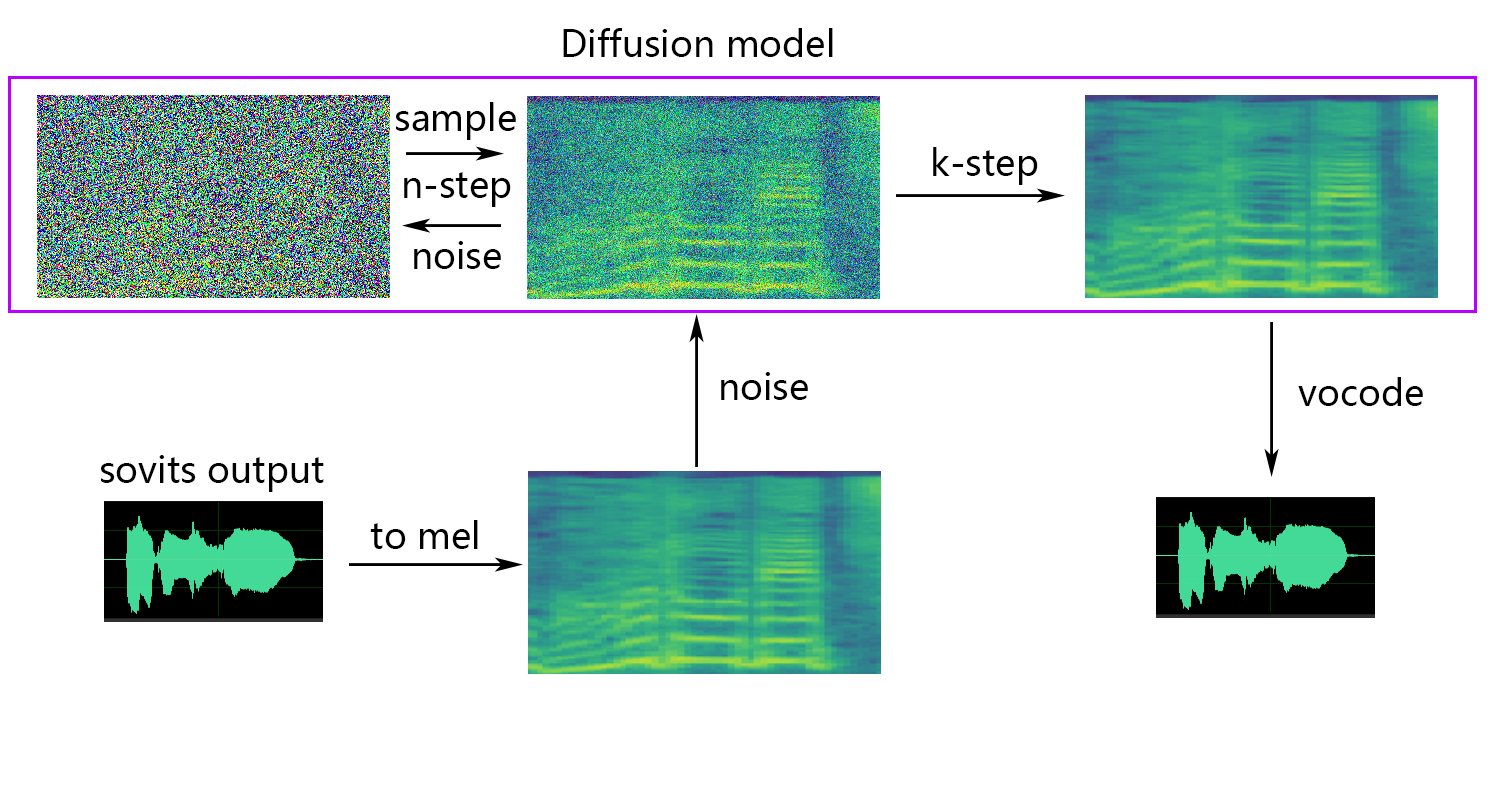
Jika Anda ingin difusi dangkal (opsional), Anda perlu menambahkan parameter --use_diff , misalnya:
python preprocess_hubert_f0.py --f0_predictor dio --use_diffMempercepat preprocess
Jika dataset Anda cukup besar, Anda dapat meningkatkan param --num_processes seperti itu:
python preprocess_hubert_f0.py --f0_predictor dio --num_processes 8Semua pekerja akan ditugaskan ke GPU yang berbeda jika Anda memiliki lebih dari satu GPU.
Setelah menyelesaikan langkah -langkah di atas, direktori dataset akan berisi data yang diproses sebelumnya, dan folder Dataset_raw dapat dihapus.
python train.py -c configs/config.json -m 44kJika fungsi difusi dangkal diperlukan, model difusi perlu dilatih. Metode pelatihan model difusi adalah sebagai berikut:
python train_diff.py -c configs/diffusion.yaml Selama pelatihan, file model akan disimpan ke logs/44k , dan model difusi akan disimpan ke logs/44k/diffusion
Gunakan inference_main.py
# Example
python inference_main.py -m " logs/44k/G_30400.pth " -c " configs/config.json " -n "君の知らない物語-src.wav " -t 0 -s " nen "Parameter yang diperlukan:
-m | --model_path : jalur ke model.-c | --config_path : Path ke file konfigurasi.-n | --clean_names : Daftar nama file WAV yang terletak di folder raw .-t | --trans : Pitch shift, mendukung nilai positif dan negatif (semitone).-s | --spk_list : Pilih ID speaker yang akan digunakan untuk konversi.-cl | --clip : Kliping audio paksa, diatur ke 0 untuk menonaktifkan (default), mengaturnya ke nilai non-nol (durasi dalam detik) untuk mengaktifkan.Parameter opsional: lihat bagian selanjutnya
-lg | --linear_gradient : Panjang salib memudar dari dua irisan audio dalam detik. Jika ada suara terputus setelah pengiris paksa, Anda dapat menyesuaikan nilai ini. Jika tidak, disarankan untuk menggunakan nilai default 0.-f0p | --f0_predictor : Pilih prediktor F0, opsi adalah crepe , pm , dio , harvest , rmvpe , fcpe , nilai default adalah pm (catatan: pooling rata-rata f0 akan diaktifkan saat menggunakan crepe )-a | --auto_predict_f0 : Prediksi pitch otomatis, jangan memungkinkan ini saat mengonversi suara bernyanyi karena dapat menyebabkan masalah pitch yang serius.-cm | --cluster_model_path : Model cluster atau jalur indeks pengambilan fitur, jika dibiarkan kosong, itu akan secara otomatis ditetapkan sebagai jalur default dari model-model ini. Jika tidak ada cluster pelatihan atau pengambilan fitur, isi sesuka hati.-cr | --cluster_infer_ratio : Proporsi skema pengelompokan atau pengambilan fitur berkisar dari 0 hingga 1. Jika tidak ada model pelatihan atau pengambilan fitur, standarnya adalah 0.-eh | --enhance : Apakah akan menggunakan penambah NSF_HIFIGAN, opsi ini memiliki efek tertentu pada peningkatan kualitas suara untuk beberapa model dengan beberapa set pelatihan, tetapi memiliki efek negatif pada model yang terlatih, sehingga dinonaktifkan secara default.-shd | --shallow_diffusion : Apakah akan menggunakan difusi dangkal, yang dapat menyelesaikan beberapa masalah suara listrik setelah digunakan. Opsi ini dinonaktifkan secara default. Saat opsi ini diaktifkan, penambah NSF_HIFIGAN akan dinonaktifkan-usm | --use_spk_mix : apakah akan menggunakan fusi suara dinamis-lea | --loudness_envelope_adjustment : Penyesuaian amplop kenyaringan sumber input sehubungan dengan rasio fusi dari amplop kenyaringan output. Semakin dekat ke 1, semakin banyak amplop kenyaringan output digunakan-fr | --feature_retrieval : Apakah akan menggunakan pengambilan fitur jika model pengelompokan digunakan, itu akan dinonaktifkan, dan parameter cm dan cr akan menjadi jalur indeks dan rasio pencampuran pengambilan fiturPengaturan Difusi Dangkal:
-dm | --diffusion_model_path : jalur model difusi-dc | --diffusion_config_path : Jalur file konfigurasi difusi-ks | --k_step : Semakin besar jumlah k_steps, semakin dekat dengan hasil model difusi. Defaultnya adalah 100-od | --only_diffusion : Apakah hanya menggunakan mode difusi, yang tidak memuat model Sovits untuk hanya menggunakan inferensi model difusi-se | --second_encoding : Yang melibatkan penerapan pengkodean tambahan ke audio asli sebelum difusi dangkal. Opsi ini dapat menghasilkan hasil yang bervariasi - terkadang positif dan terkadang negatif. Jika menyimpulkan menggunakan encoder ucapan whisper-ppg , Anda perlu mengatur --clip ke 25 dan -lg ke 1. Kalau tidak, ia akan gagal menyimpulkan dengan benar.
Jika Anda puas dengan hasil sebelumnya, atau jika Anda tidak merasa Anda mengerti apa yang berikut, Anda dapat melewatkannya dan itu tidak akan berpengaruh pada penggunaan model. Dampak dari pengaturan opsional yang disebutkan ini relatif kecil, dan sementara mereka mungkin berdampak pada kumpulan data tertentu, dalam kebanyakan kasus perbedaannya mungkin tidak signifikan.
Selama pelatihan model 4.0, prediktor F0 juga dilatih, yang memungkinkan prediksi pitch otomatis selama konversi suara. Namun, jika hasilnya tidak memuaskan, prediksi pitch manual dapat digunakan sebagai gantinya. Harap dicatat bahwa ketika mengonversi suara bernyanyi, disarankan untuk tidak mengaktifkan fitur ini karena dapat menyebabkan pergeseran pitch yang signifikan.
auto_predict_f0 ke true in inference_main.py .PENDAHULUAN: Skema pengelompokan yang diimplementasikan dalam model ini bertujuan untuk mengurangi kebocoran timbre dan meningkatkan kesamaan model yang dilatih dengan timbre target, meskipun efeknya mungkin tidak terlalu jelas. Namun, hanya mengandalkan pengelompokan dapat mengurangi kejelasan model dan membuatnya terdengar kurang berbeda. Oleh karena itu, metode fusi diadopsi dalam model ini untuk mengontrol keseimbangan antara pendekatan pengelompokan dan non-clustering. Ini memungkinkan penyesuaian manual dari pertukaran antara "terdengar seperti timbre target" dan "memiliki pengucapan yang jelas" untuk menemukan keseimbangan yang optimal.
Tidak ada perubahan yang diperlukan dalam langkah yang ada. Cukup latih model pengelompokan tambahan, yang menimbulkan biaya pelatihan yang relatif rendah.
python cluster/train_cluster.py . Model output akan disimpan dalam logs/44k/kmeans_10000.pt .python cluster/train_cluster.py --gpucluster_model_path di inference_main.py . Jika tidak ditentukan, standarnya adalah logs/44k/kmeans_10000.pt .cluster_infer_ratio di inference_main.py , di mana 0 berarti tidak menggunakan pengelompokan sama sekali, 1 berarti hanya menggunakan clustering, dan biasanya 0.5 sudah cukup.PENDAHULUAN: Seperti halnya skema pengelompokan, kebocoran timbre dapat dikurangi, pengucapan sedikit lebih baik daripada pengelompokan, tetapi akan mengurangi kecepatan inferensi. Dengan menggunakan metode fusi, menjadi mungkin untuk mengontrol keseimbangan antara pengambilan fitur dan pengambilan non-fitur, memungkinkan untuk menyempurnakan proporsi yang diinginkan.
python train_index.py -c configs/config.json Output model akan ada di logs/44k/feature_and_index.pkl
--feature_retrieval perlu dirumuskan terlebih dahulu, dan mode pengelompokan secara otomatis beralih ke mode pengambilan fitur.cluster_model_path di inference_main.py . Jika tidak ditentukan, default adalah logs/44k/feature_and_index.pkl .cluster_infer_ratio di inference_main.py , di mana 0 berarti tidak menggunakan pengambilan fitur sama sekali, 1 berarti hanya menggunakan pengambilan fitur, dan biasanya 0.5 sudah cukup. Model yang dihasilkan berisi data yang diperlukan untuk pelatihan lebih lanjut. Jika Anda mengkonfirmasi bahwa model ini final dan tidak digunakan dalam pelatihan lebih lanjut, aman untuk menghapus data ini untuk mendapatkan ukuran file yang lebih kecil (sekitar 1/3).
# Example
python compress_model.py -c= " configs/config.json " -i= " logs/44k/G_30400.pth " -o= " logs/44k/release.pth " Lihat file webUI.py untuk pencampuran timbre stabil dari fitur gadget/lab.
PENDAHULUAN: Fungsi ini dapat menggabungkan beberapa model menjadi satu model (kombinasi cembung atau kombinasi linier parameter model multipel) untuk membuat suara campuran yang tidak ada dalam kenyataan
Catatan:
model di config.json dari semua model yang akan dicampur adalah sama Lihat file spkmix.py untuk pengantar pencampuran timbre dinamis
Aturan penulisan track campuran karakter:
ID Peran: [[Mulai Waktu 1, Waktu Akhir 1, Nilai Mulai 1, Nilai Mulai 1], [Waktu Mulai 2, Waktu Akhir 2, Nilai Mulai 2]]
Waktu mulai harus sama dengan waktu akhir dari yang sebelumnya. Waktu mulai pertama harus 0, dan waktu akhir terakhir harus 1 (waktu berkisar dari 0 hingga 1).
Semua peran harus diisi. Untuk peran yang tidak digunakan, isi [[0., 1., 0., 0.]]
Nilai fusi dapat diisi secara sewenang -wenang, dan perubahan linier dari nilai awal ke nilai akhir dalam periode waktu yang ditentukan. Itu
Kombinasi linier internal akan secara otomatis dijamin 1 (kondisi kombinasi cembung), sehingga dapat digunakan dengan aman
Gunakan parameter --use_spk_mix saat beralasan untuk mengaktifkan pencampuran timbre dinamis
Gunakan onnx_export.py
checkpoints dan bukacheckpoints sebagai folder proyek Anda, menamakannya setelah proyek Anda, misalnya aziplayermodel.pth , file konfigurasi sebagai config.json , dan tempatkan di folder aziplayer yang baru saja Anda buat"NyaruTaffy" di path = "NyaruTaffy" di onnx_export.py dengan nama proyek Anda, path = "aziplayer" (onnx_export_speaker_mix membuat Anda dapat mencampur suara speaker)model.onnx akan dihasilkan di folder proyek Anda, yang merupakan model yang diekspor.Catatan: Untuk model Hubert Onnx, silakan gunakan model yang disediakan oleh Moess. Saat ini, mereka tidak dapat diekspor sendiri (Hubert di Fairseq memiliki banyak operator yang tidak didukung dan hal -hal yang melibatkan konstanta yang dapat menyebabkan kesalahan atau mengakibatkan masalah dengan bentuk input/output dan hasil ketika diekspor.)
| Url | Penamaan | Judul | Sumber Implementasi |
|---|---|---|---|
| 2106.06103 | Vits (synthesizer) | Autoencoder variasional bersyarat dengan pembelajaran permusuhan untuk teks ke ujung ke ujung | jaywalnut310/vits |
| 2111.02392 | Softvc (ucapan encoder) | Perbandingan unit pembicaraan diskrit dan lembut untuk konversi suara yang lebih baik | Bshall/Hubert |
| 2204.09224 | ContentVec (ucapan encoder) | ContentVec: Representasi pidato yang di-swasion yang ditingkatkan dengan menguraikan penutur pembicara | menguntungkan3000/contentVec |
| 2212.04356 | Whisper (ucapan encoder) | Pengenalan ucapan yang kuat melalui pengawasan lemah skala besar | Openai/Whisper |
| 2110.13900 | WAVLM (ucapan ucapan) | WAVLM: Pra-pelatihan swadaya skala besar untuk pemrosesan ucapan tumpukan penuh | Microsoft/UNILM/WAVLM |
| 2305.17651 | DPHUBERT (Encoder Pidato) | DPHUBERT: Distilasi Bersama dan Pemangkasan Model Pidato yang Di-swadaya | PYF98/DPHUBERT |
| Doi: 10.21437/interspeech.2017-68 | Panen (prediktor f0) | Panen: Estimator Frekuensi Fundamental Kinerja Tinggi dari Sinyal Pidato | mmorise/dunia/panen |
| AES35-000039 | Dio (prediktor F0) | Metode Estimasi F0 Cepat dan andal Berdasarkan Periode Ekstraksi Getaran Vokal Getaran Suara dan Pidato Bernyanyi | Mmorise/World/Dio |
| 8461329 | Crepe (prediktor F0) | Crepe: representasi konvolusional untuk estimasi nada | Maxrmorrison/Torchcrepe |
| Doi: 10.1016/j.wocn.2018.07.001 | Parselmouth (prediktor F0) | Memperkenalkan Parselmouth: Antarmuka Python ke Praat | Yannickjadoul/Parselmouth |
| 2306.15412v2 | RMVPE (prediktor F0) | RMVPE: Model yang kuat untuk estimasi pitch vokal dalam musik polifonik | Mimpi-tinggi/rmvpe |
| 2010.05646 | Hifigan (Vocoder) | HIFI-GAN: Jaringan permusuhan generatif untuk sintesis ucapan kesetiaan yang efisien dan tinggi | jik876/hifi-gan |
| 1810.11946 | NSF (vocoder) | Model bentuk gelombang berbasis-filter saraf untuk sintesis ucapan parametrik statistik | OpenVPI/Diffsinger/Modules/NSF_HIFIGAN |
| 2006.08195 | Snake (Vocoder) | Jaringan saraf gagal mempelajari fungsi berkala dan cara memperbaikinya | Edwarddixon/Snake |
| 2105.02446v3 | Difusi dangkal (postprocessing) | Diffsinger: Sintesis Suara Bernyanyi melalui Mekanisme Difusi Dangkal | CNCHTU/Difusi-SVC |
| K-means | Fitur k-means clustering (preprocessing) | Beberapa metode untuk klasifikasi dan analisis pengamatan multivariat | Repo ini |
| Fitur pengambilan topk (preprocessing) | Konversi Suara Berbasis Pengambilan | RVC-Project/Retrieval-Based-Voice-Conversion-Webui | |
| Whisper PPG | Whisper PPG | Playvoice/whisper_ppg | |
| Bigvgan | Bigvgan | Playvoice/so-vits-svc-5.0 |
Untuk beberapa alasan penulis menghapus repositori asli. Karena kelalaian anggota organisasi, daftar kontributor dihapus karena semua file secara langsung diunggulkan ke repositori ini pada awal rekonstruksi repositori ini. Sekarang tambahkan daftar kontributor sebelumnya ke ReadMe.md.
Beberapa anggota belum terdaftar sesuai dengan keinginan pribadi mereka.
Misteo | Xiaomiku01 | しぐれ | Tomogasukunai | Plachtaa | zd 小达 | 凍聲響世 |
任何组织或者个人不得以丑化、污损 , 或者利用信息技术手段伪造等方式侵害他人的肖像权。未经肖像权人同意 , 不得制作、使用、公开肖像权人的肖像 , 但是法律另有规定的除外。未经肖像权人同意 , 肖像作品权利人不得以发表、复制、发行、出租、展览等方式使用或者公开肖像权人的肖像。对自然人声音的保护 , 参照适用肖像权保护的有关规定。
【名誉权】民事主体享有名誉权。任何组织或者个人不得以侮辱、诽谤等方式侵害他人的名誉权。
【作品侵害名誉权】行为人发表的文学、艺术作品以真人真事或者特定人为描述对象 , 含有侮辱、诽谤内容 , 侵害他人名誉权的 , 受害人有权依法请求该行为人承担民事责任。行为人发表的文学、艺术作品不以特定人为描述对象 , 仅其中的情节与该特定人的情况相似的 , 不承担民事责任。


