so vits svc
1.0.0
Englisch |中文简体
Diese Runde des begrenzten Zeit -Updates endet, das Lagerhaus wird in den Archieve -Staat eintreten, bitte wissen Sie
Ein Studio, das sichtbaren F0 -Editor, Speaker Mix Timeline -Editor und andere Funktionen enthält (wo die ONNX -Modelle verwendet werden): Moevoicestudio
Eine Gabel mit einer stark verbesserten Benutzeroberfläche: 34J/SO-Vits-SVC-Gabel
Ein Kunde unterstützt Echtzeitkonvertierung: W-OKADA/Voice Changer
Dieses Projekt unterscheidet sich grundlegend von Vits, da es sich eher auf die Gesangs-Voice Conversion (SVC) als auf Text-to-Speech (TTS) konzentriert. In diesem Projekt wird TTS -Funktionalität nicht unterstützt, und Vits können SVC -Aufgaben nicht ausführen. Es ist wichtig zu beachten, dass die in diesen beiden Projekten verwendeten Modelle nicht austauschbar oder universell anwendbar sind.
Ziel dieses Projekts war es, Entwicklern zu ermöglichen, dass ihre geliebten Anime -Charaktere Gesangsaufgaben ausführen. Die Absicht der Entwickler war es, sich ausschließlich auf fiktive Charaktere zu konzentrieren und echte Personen zu vermeiden, alles, was mit echten Individuen zusammenhängt, weicht von der ursprünglichen Absicht des Entwicklers ab.
Dieses Projekt ist ein Open-Source-Offline-Bestreben, und alle Mitglieder von SVCDevelopteam sowie anderen beteiligten Entwicklern und Inhaber (im Folgenden als Mitwirkenden bezeichnet) haben keine Kontrolle über das Projekt. Die Mitwirkenden haben noch nie eine Organisation oder Person unterstützt, einschließlich, aber nicht beschränkt auf Datensatzextraktion, Datensatzverarbeitung, Computerunterstützung, Schulungsunterstützung, Inferenz usw. Die Mitwirkenden sind nicht und können sich der Zwecke nicht bewusst sein, für die Benutzer das Projekt nutzen. Daher haben alle AI -Modelle und synthetisierten Audioen, die durch das Training dieses Projekts erzeugt werden, nichts mit den Mitwirkenden zu tun. Probleme oder Konsequenzen, die sich aus ihrer Verwendung ergeben, liegen in der alleinigen Verantwortung des Benutzers.
Dieses Projekt wird vollständig offline ausgeführt und sammelt keine Benutzerinformationen oder sammelte Benutzereingabedaten. Die Mitwirkenden an diesem Projekt sind daher nicht alle Benutzereingaben und -modelle bekannt und sind daher für keine Benutzereingaben verantwortlich.
Dieses Projekt dient nur als Framework und besitzt keine Sprachsynthesefunktionalität für sich. Alle Funktionen erfordern, dass Benutzer die Modelle unabhängig schulen. Darüber hinaus wird dieses Projekt nicht mit Modellen gebündelt, und alle sekundären verteilten Projekte sind unabhängig von den Mitwirkenden dieses Projekts.
Das Sanging Voice Conversion -Modell verwendet SoftVC -Inhaltscodierer, um Sprachmerkmale aus dem Quell -Audio zu extrahieren. Diese Feature-Vektoren werden direkt in Vits eingespeist, ohne dass eine Konvertierung in eine textbasierte Zwischendarstellung erforderlich ist. Infolgedessen bleiben die Tonhöhe und die Intonationen des ursprünglichen Audios erhalten. In der Zwischenzeit wurde der Vokoder durch NSF Hifigan ersetzt, um das Problem der Schallunterbrechung zu lösen.
config.json vornehmen. Fügen Sie das Feld " speech_encoder zum Abschnitt "Modell" hinzu, wie unten gezeigt: "model": {
.........
"ssl_dim": 256,
"n_speakers": 200,
"speech_encoder":"vec256l9"
}
Basierend auf unseren Tests haben wir festgestellt, dass das Projekt auf Python 3.8.9 stabil ausgeführt wird.
Sie müssen einen Encoder aus der folgenden Liste auswählen
vec768l12 und vec256l9 benötigen den Encoder
pretrainOder laden Sie den folgenden ContentVec herunter, der nur eine Größe von 199 MB hat, aber den gleichen Effekt hat:
checkpoint_best_legacy_500.pt und platzieren Sie ihn in das pretrain # contentvec
wget -P pretrain/ https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/hubert_base.pt -O checkpoint_best_legacy_500.pt
# Alternatively, you can manually download and place it in the hubert directory pretrain whisper-ppgwhisper-ppg-largepretrain pretrain pretrain wavlmbase+pretrain pretrain Vorausgebildete Modelldateien: G_0.pth D_0.pth
logs/44k -Verzeichnis Diffusionsmodell Vorabbasismodelldatei: model_0.pt
logs/44k/diffusion einHolen Sie sich Sovits vorgebildetes Modell aus dem SVC-Entwicklungsteam (TBD) oder irgendwo anders.
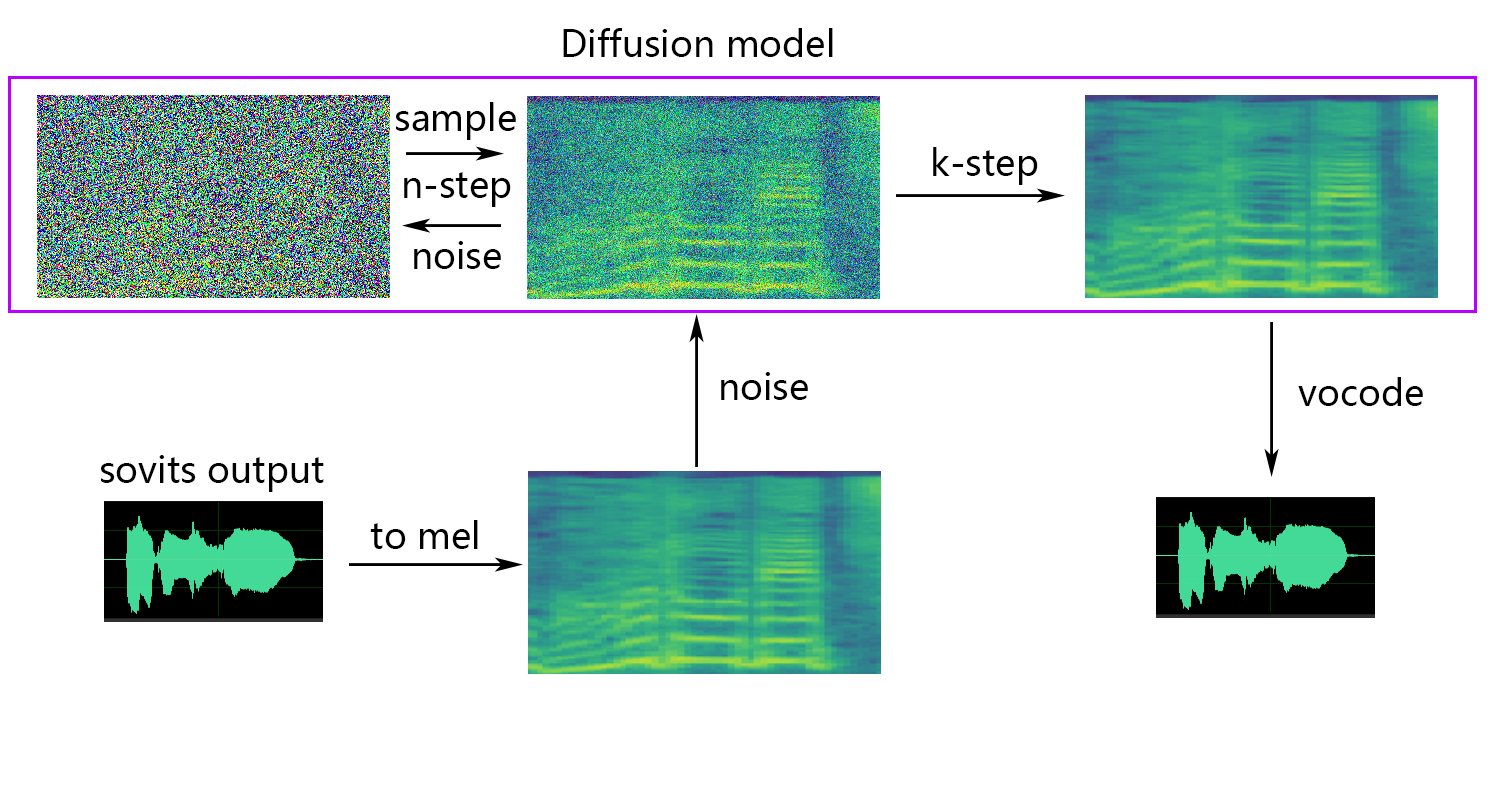
Diffusionsmodell referenziert das Diffusions-SVC-Diffusionsmodell. Das vorgebildete Diffusionsmodell ist mit den DDSP-SVCs universell. Sie können zum Repo von Diffusion-SVC gehen, um das vorgebildete Diffusionsmodell zu erhalten.
Während das vorbereitete Modell in der Regel keine Urheberrechtsbedenken darstellt, ist es wichtig, wachsam zu bleiben. Es ist ratsam, den Autor vorher zu konsultieren oder die Beschreibung sorgfältig zu überprüfen, um die zulässige Verwendung des Modells zu ermitteln. Dies hilft, die Einhaltung der festgelegten Richtlinien oder Einschränkungen hinsichtlich der Nutzung zu gewährleisten.
Wenn Sie den NSF-HIFIGAN enhancer oder shallow diffusion verwenden, müssen Sie das vorgebildete NSF-Hifigan-Modell herunterladen.
pretrain/nsf_hifigan # nsf_hifigan
wget -P pretrain/ https://github.com/openvpi/vocoders/releases/download/nsf-hifigan-v1/nsf_hifigan_20221211.zip
unzip -od pretrain/nsf_hifigan pretrain/nsf_hifigan_20221211.zip
# Alternatively, you can manually download and place it in the pretrain/nsf_hifigan directory
# URL: https://github.com/openvpi/vocoders/releases/tag/nsf-hifigan-v1 Wenn Sie den rmvpe F0-Prädiktor verwenden, müssen Sie das vorgebildete RMVPE-Modell herunterladen.
rmvpe.zip , und benennen Sie die model.pt -Datei in rmvpe.pt um und legen Sie sie unter das pretrain .pretrain FCPE (schneller Kontext-Basis-Pitch-Schätzer) ist ein dedizierter F0-Prädiktor für die Umwandlung in Echtzeit-Sprache und wird in Zukunft der bevorzugte F0-Prädiktor für Sovits Echtzeit-Sprachumwandlung. (Das Papier wird geschrieben)
Wenn Sie den fcpe F0-Prädiktor verwenden, müssen Sie das vorgebildete FCPE-Modell herunterladen.
pretrain Platzieren Sie einfach den Datensatz in das Verzeichnis dataset_raw mit der folgenden Dateistruktur:
dataset_raw
├───speaker0
│ ├───xxx1-xxx1.wav
│ ├───...
│ └───Lxx-0xx8.wav
└───speaker1
├───xx2-0xxx2.wav
├───...
└───xxx7-xxx007.wav
Das Format des Namens für jede Audiodatei gibt keine spezifischen Einschränkungen (Namenskonventionen wie 000001.wav bis 999999.wav sind ebenfalls gültig), aber der Dateityp muss "WAV" sein.
Sie können den Namen des Sprechers wie unten gezeigt anpassen:
dataset_raw
└───suijiSUI
├───1.wav
├───...
└───25788785-20221210-200143-856_01_(Vocals)_0_0.wav
Um den Überlauf des Videospeichers während des Trainings oder der Vorverarbeitung zu vermeiden, wird empfohlen, die Länge von Audioclips zu begrenzen. Es wird empfohlen, das Audio auf eine Länge von "5s - 15s" zu schneiden. Etwas längere Zeiten sind akzeptabel, aber übermäßig lange Clips können zu Problemen wie torch.cuda.OutOfMemoryError führen.
Um den Schnittprozess zu erleichtern, können Sie Audio-Slicer-Gui oder Audio-Slicer-Cli verwenden
Im Allgemeinen muss nur das Minimum Interval angepasst werden. Für gesprochenes Audio reicht der Standardwert normalerweise aus, während er für das Singen von Audio je nach den spezifischen Anforderungen auf rund 100 oder sogar 50 eingestellt werden kann.
Nach dem Schneiden wird empfohlen, alle übermäßig langen oder zu kurzen Audioclips zu entfernen.
Wenn Sie Whisper-PPG-Encoder für das Training verwenden, müssen die Audioclips kürzer als 30er Jahre.
python resample.py Obwohl dieses Projekt res Beispiele. Dies kann die Klangqualität beschädigen. Während Pythons Lautstärkepaket Pyloudnorm den Niveau nicht einschränkt, kann dies zu Klangboom führen. Daher wird empfohlen, eine professionelle Software für Soundverarbeitungssoftware wie adobe audition für Lautstärkeanpassungen zu verwenden. Wenn Sie bereits eine andere Software für die Lautstärke verwenden, fügen Sie den Parameter -skip_loudnorm zum Befehl run hinzu:
python resample.py --skip_loudnormpython preprocess_flist_config.py --speech_encoder vec768l12real_encoder hat die folgenden Optionen
vec768l12
vec256l9
hubertsoft
whisper-ppg
cnhubertlarge
dphubert
whisper-ppg-large
wavlmbase+
Wenn das Argument des Rede_Coder weggelassen wird, ist der Standardwert vec768l12
Verwenden Sie Lautstärke
Fügen Sie --vol_aug hinzu, wenn Sie Lautstärke einbetten möchten:
python preprocess_flist_config.py --speech_encoder vec768l12 --vol_augNach der Einbettung der Lautstärke entspricht das geschulte Modell mit der Lautstärke der Eingangsquelle. Andernfalls entspricht es der Lautstärke des Trainingssatzes.
keep_ckpts : Halten Sie die Anzahl der früheren Modelle während des Trainings. Setzen Sie auf 0 um sie alle zu halten. Standard ist 3 .
all_in_mem : Laden Sie den gesamten Datensatz in RAM. Es kann aktiviert werden, wenn die Festplatte einiger Plattformen zu niedrig ist und der Systemspeicher viel größer ist als Ihr Datensatz.
batch_size : Die Datenmenge, die für eine einzelne Trainingseinheit in die GPU geladen wird, kann auf eine Größe, die niedriger als die GPU -Speicherkapazität ist, angepasst werden.
vocoder_name : Wählen Sie einen Vocoder aus. Der Standard ist nsf-hifigan .
cache_all_data : Laden Sie den gesamten Datensatz in RAM. Es kann aktiviert werden, wenn die Festplatte einiger Plattformen zu niedrig ist und der Systemspeicher viel größer ist als Ihr Datensatz.
duration : Die Dauer des Audioschneide während des Trainings kann gemäß der Größe des Videospeichers angepasst werden. Hinweis: Dieser Wert muss geringer sein als die Mindestzeit des Audio im Trainingssatz!
batch_size : Die Datenmenge, die für eine einzelne Trainingseinheit in die GPU geladen wird, kann auf eine Größe, die niedriger als die Videospeicherkapazität ist, angepasst werden.
timesteps : Die Gesamtzahl der Schritte im Diffusionsmodell, die auf 1000 standardmäßig sind.
k_step_max : Das Training kann nur k_step_max -Schrittdiffusion trainieren , um die Trainingszeit zu sparen. Beachten Sie, dass der Wert weniger als timesteps sein muss. nur_diffusion!
nsf-hifigan
nsf-snake-hifigan
python preprocess_hubert_f0.py --f0_predictor dioF0_PREDICTOR hat die folgenden Optionen
crepe
dio
pm
harvest
rmvpe
fcpe
Wenn das Trainingssatz zu laut ist, wird empfohlen, crepe für F0 zu verwenden
Wenn der Parameter f0_prredictor weggelassen wird, ist der Standardwert rmvpe
Wenn Sie eine flache Diffusion (optional) wünschen, müssen Sie den Parameter --use_diff hinzufügen, z. B.:
python preprocess_hubert_f0.py --f0_predictor dio --use_diffBeschleunigen Sie die Vorverarbeitung
Wenn Ihr Datensatz ziemlich groß ist, können Sie den Param --num_processes wie diese erhöhen:
python preprocess_hubert_f0.py --f0_predictor dio --num_processes 8Der gesamte Arbeiter wird verschiedenen GPU zugeordnet, wenn Sie mehr als einen GPUs haben.
Nach Abschluss der oben genannten Schritte enthält das Dataset -Verzeichnis die vorverarbeiteten Daten, und der Ordner Dataset_raw kann gelöscht werden.
python train.py -c configs/config.json -m 44kWenn die flache Diffusionsfunktion benötigt wird, muss das Diffusionsmodell trainiert werden. Die Diffusionsmodell -Trainingsmethode lautet wie folgt:
python train_diff.py -c configs/diffusion.yaml Während des Trainings werden die Modelldateien in logs/44k gespeichert, und das Diffusionsmodell wird auf logs/44k/diffusion gespeichert
Verwenden Sie Inference_Main.py
# Example
python inference_main.py -m " logs/44k/G_30400.pth " -c " configs/config.json " -n "君の知らない物語-src.wav " -t 0 -s " nen "Erforderliche Parameter:
-m | --model_path : Pfad zum Modell.-c | --config_path : Pfad zur Konfigurationsdatei.-n | --clean_names : Eine Liste der WAV-Dateinamen im raw Ordner.-t | --trans : Tonhöheverschiebung, unterstützt positive und negative (Semiton-) Werte.-s | --spk_list : Wählen Sie die Lautsprecher-ID für die Konvertierung aus.-cl | --clip : Erzwungenes Audio-Clipping, auf 0 gesetzt, um zu deaktivieren (Standard), um es auf einen Wert ungleich Null zu setzen (Dauer in Sekunden), um es zu aktivieren.Optionale Parameter: Siehe den nächsten Abschnitt
-lg | --linear_gradient : Die Querverblassungslänge von zwei Audioscheiben in Sekunden. Wenn nach erzwungenem Schnitt eine diskontinuierliche Stimme vorliegt, können Sie diesen Wert anpassen. Andernfalls wird empfohlen, den Standardwert von 0 zu verwenden.-f0p | --f0_predictor : Wählen Sie einen F0-Prädiktor aus, Optionen sind crepe , pm , dio , harvest , rmvpe , fcpe , Standardwert ist pm (Anmerkung: F0-Pooling wird bei Verwendung von crepe aktiviert)-a | --auto_predict_f0 : Automatische Pitch-Vorhersage, aktivieren Sie dies nicht, wenn Sie Gesangsstimmen konvertieren, da dies schwerwiegende Pitch-Probleme verursachen kann.-cm | --cluster_model_path : Clustermodell oder Feature-Abruf-Indexpfad, wenn es leer ist, wird es automatisch als Standardpfad dieser Modelle festgelegt. Wenn es keinen Trainingscluster oder Feature -Abruf gibt, füllen Sie nach Belieben aus.-cr | --cluster_infer_ratio : Der Anteil des Clustering-Schemas oder der Abrufen von Features reicht von 0 bis 1. Wenn kein Trainingsclustering-Modell oder Feature-Abruf vorhanden ist, beträgt die Standardeinstellung 0.-eh | --enhance : Ob Sie NSF_HIFIGAN-Enhancer verwenden möchten, hat diese Option einen gewissen Einfluss auf die Verbesserung der Schallqualität für einige Modelle mit wenigen Trainingssätzen, hat jedoch negative Auswirkungen auf gut ausgebildete Modelle, sodass sie standardmäßig deaktiviert ist.-shd | --shallow_diffusion : Ob Sie eine flache Diffusion verwenden möchten, die nach der Verwendung einige elektrische Klangprobleme lösen kann. Diese Option ist standardmäßig deaktiviert. Wenn diese Option aktiviert ist, wird der NSF_HIFIGAN -Enhancer deaktiviert-usm | --use_spk_mix : Ob Sie eine dynamische Sprachfusion verwenden möchten-lea | --loudness_envelope_adjustment : Die Anpassung der Lautstärke der Eingangsquelle in Bezug auf das Fusionsverhältnis der Ausgabe-Lautstärkehülle. Je näher an 1, desto mehr wird die Ausgabelautstärke verwendet-fr | --feature_retrieval : Ob Sie das Abrufen von Funktionen verwenden, wenn ein Clustering-Modell verwendet wird, es wird deaktiviert, und cm und cr -Parameter werden zum Indexpfad und Mischungsverhältnis des Abrufs von Features werdenEinstellungen der flachen Diffusion:
-dm | --diffusion_model_path : Diffusionsmodellpfad-dc | --diffusion_config_path : Diffusion Config Datei Path-ks | --k_step : Je größer die Anzahl der K_steps ist, desto näher ist es dem Ergebnis des Diffusionsmodells. Der Standard ist 100-od | --only_diffusion : Ob Sie nur den Diffusionsmodus verwenden, wodurch das Sovits-Modell nicht geladen wird, um nur Diffusionsmodellinferenz zu verwenden-se | --second_encoding : Bei der Anwendung einer zusätzlichen Codierung auf das ursprüngliche Audio vor der flachen Diffusion. Diese Option kann unterschiedliche Ergebnisse erzielen - manchmal positiv und manchmal negativ. Wenn die Inferenzung mit whisper-ppg -Sprachcodierer in --clip mit 25 und -lg auf 1 einstellen müssen. Andernfalls schließt es ansonsten nicht ordnungsgemäß ab.
Wenn Sie mit den vorherigen Ergebnissen zufrieden sind oder nicht das Gefühl haben, dass Sie verstehen, was folgt, können Sie es überspringen und es hat keinen Einfluss auf die Verwendung des Modells. Die Auswirkungen dieser erwähnten optionalen Einstellungen sind relativ gering, und obwohl sie sich auf bestimmte Datensätze auswirken können, ist der Unterschied in den meisten Fällen möglicherweise nicht signifikant.
Während des Trainings des 4.0 -Modells wird auch ein F0 -Prädiktor trainiert, der die automatische Pitch -Vorhersage während der Sprachumwandlung ermöglicht. Wenn die Ergebnisse jedoch nicht zufriedenstellend sind, kann stattdessen manuelle Tonhöhenvorhersage verwendet werden. Bitte beachten Sie, dass bei der Konvertierung von Gesangsstimmen empfohlen wird, diese Funktion nicht zu aktivieren, da dies zu einem erheblichen Schaltwechsel führen kann.
auto_predict_f0 auf true in inference_main.py .Einführung: Das in diesem Modell implementierte Clustering -Schema zielt darauf ab, die Leckage von Timbre zu reduzieren und die Ähnlichkeit des geschulten Modells mit dem Timbre des Ziels zu verbessern, obwohl der Effekt möglicherweise nicht sehr ausgeprägt ist. Wenn Sie sich jedoch ausschließlich auf Clustering verlassen, können Sie die Klarheit des Modells verringern und es weniger deutlich klingen. Daher wird in diesem Modell eine Fusionsmethode angewendet, um das Gleichgewicht zwischen den Clustering- und Nicht-Clustering-Ansätzen zu steuern. Dies ermöglicht die manuelle Einstellung des Kompromisses zwischen "klingt wie das Timbre des Ziels" und "klare Ausdrücke", um ein optimales Gleichgewicht zu finden.
In den vorhandenen Schritten sind keine Änderungen erforderlich. Trainieren Sie einfach ein zusätzliches Clustering -Modell, das relativ niedrige Schulungskosten verursacht.
python cluster/train_cluster.py aus. Das Ausgabemodell wird in logs/44k/kmeans_10000.pt gespeichert.python cluster/train_cluster.py --gpu ausführtcluster_model_path in inference_main.py an. Wenn nicht angegeben, ist der Standardprotokollen logs/44k/kmeans_10000.pt .cluster_infer_ratio in inference_main.py an, wobei 0 bedeutet, dass Clustering überhaupt nicht verwendet wird, 1 bedeutet nur die Verwendung von Clustering, und normalerweise ist 0.5 ausreichend.Einführung: Wie beim Clustering -Schema kann die Timbre -Leckage reduziert werden, die Auskürzung ist etwas besser als das Clustering, verringert jedoch die Inferenzgeschwindigkeit. Durch die Verwendung der Fusionsmethode wird es möglich, das Gleichgewicht zwischen Merkmalabruf und Nicht-Feature-Abruf linear zu steuern, wodurch die Feinabstimmung des gewünschten Anteils ermöglicht wird.
python train_index.py -c configs/config.json Die Ausgabe des Modells befindet sich in logs/44k/feature_and_index.pkl
--feature_retrieval muss zuerst formuliert werden, und der Clustering -Modus wechselt automatisch in den Feature -Abrufmodus.cluster_model_path in inference_main.py an. Wenn nicht angegeben, ist der Standard logs/44k/feature_and_index.pkl .cluster_infer_ratio in inference_main.py an, wobei 0 bedeutet, dass die Feature -Abruf überhaupt nicht verwendet wird, 1 bedeutet nur, dass das Abrufen von Funktionen verwendet wird und normalerweise 0.5 ausreichend sind. Das generierte Modell enthält Daten, die für ein weiteres Training benötigt werden. Wenn Sie bestätigen, dass das Modell endgültig ist und nicht im weiteren Training verwendet wird, kann diese Daten sicher entfernen, um eine kleinere Dateigröße (ca. 1/3) zu erhalten.
# Example
python compress_model.py -c= " configs/config.json " -i= " logs/44k/G_30400.pth " -o= " logs/44k/release.pth " Weitere Informationen zur stabilen Timbre -Mischung der Gadget/Lab -Funktion finden Sie in webUI.py -Datei.
Einführung: Diese Funktion kann mehrere Modelle in einem Modell (konvexe Kombination oder lineare Kombination mehrerer Modellparameter) kombinieren, um gemischte Sprache zu erstellen, die in der Realität nicht existieren
Notiz:
model in config.json aller Modelle gemischt werden Eine Einführung in die dynamische Timbre -Mischung finden Sie in der Datei spkmix.py
Charaktermix -Track -Schreibregeln:
Rollen -ID: [Startzeit 1, Endzeit 1, Startwert 1, Startwert 1], [Startzeit 2, Endzeit 2, Startwert 2]]
Die Startzeit muss der Endzeit der vorherigen sein. Die erste Startzeit muss 0 betragen, und die letzte Endzeit muss 1 betragen (Zeitbereiche von 0 bis 1).
Alle Rollen müssen ausgefüllt werden. Für ungenutzte Rollen füllen [0., 1., 0., 0.]]
Der Fusionswert kann willkürlich und die lineare Änderung vom Startwert zum Endwert innerhalb des angegebenen Zeitraums ausgefüllt werden. Der
Die interne lineare Kombination wird automatisch 1 (konvexer Kombinationszustand) garantiert, sodass sie sicher verwendet werden kann
Verwenden Sie den Parameter --use_spk_mix beim Argumentieren, um das dynamische Timbre -Mischen zu aktivieren
Verwenden Sie onnx_export.py
checkpoints und öffnen Sie ihncheckpoints als Projektordner und benennen Sie ihn nach Ihrem Projekt, z. B. aziplayermodel.pth , die Konfigurationsdatei als config.json , um und aziplayer"NyaruTaffy" in path = "NyaruTaffy" in ontnx_export.py zu Ihrem Projektnamen, path = "aziplayer" (onnx_export_speaker_mix, bringt Sie dazu, die Stimme des Lautsprechers zu mischen)model.onnx wird in Ihrem Projektordner generiert, das das exportierte Modell ist.Hinweis: Verwenden Sie für Hubert -OnNX -Modelle bitte die von Moess bereitgestellten Modelle. Derzeit können sie nicht alleine exportiert werden (Hubert in Fairseq hat viele nicht unterstützte Betreiber und Dinge, an denen Konstanten beteiligt sind, die Fehler verursachen oder zu Problemen mit der Eingangs-/Ausgangsform und den Ergebnissen führen können, wenn sie exportiert werden.)
| URL | Bezeichnung | Titel | Implementierungsquelle |
|---|---|---|---|
| 2106.06103 | Vits (Synthesizer) | Bedingter Variationskautocoder mit widersprüchlichen Lernen für End-to-End-Text-zu-Sprach | Jaywalnut310/vits |
| 2111.02392 | SoftVC (Sprachcodierer) | Ein Vergleich diskreter und weicher Spracheinheiten für eine verbesserte Sprachumwandlung | Bshall/Hubert |
| 2204.09224 | ContentVec (Sprachcodierer) | ContentVEC: Eine verbesserte selbstüberwachende Sprachdarstellung durch Entwirrung der Sprecher | Haltschnell3000/ContentVec |
| 2212.04356 | Flüster (Sprachcodierer) | Robuste Spracherkennung durch große schwache Überwachung | Openai/Whisper |
| 2110.13900 | Wavlm (Sprachcodierer) | WAVLM: groß angelegte Selbstüberwachung vor dem Training für die vollständige Sprachverarbeitung | Microsoft/Unilm/Wavlm |
| 2305.17651 | Dphubert (Sprachcodierer) | DPHUBERT: Joint Destillation und Beschneiden von selbst beträchtlichen Sprachmodellen | PYF98/DPHUBERT |
| Doi: 10.21437/interspeech.2017-68 | Ernte (F0 -Prädiktor) | Ernte: Ein Hochleistungs-Grundfrequenzschätzer aus Sprachsignalen | Mmorise/Welt/Ernte |
| AES35-000039 | DIO (F0 -Prädiktor) | Schnelle und zuverlässige F0 -Schätzmethode basierend auf der Periodenextraktion der Vokalfaltzibration von Gesangsstimme und Sprache | Mmorise/World/Dio |
| 8461329 | Crepe (F0 -Prädiktor) | Crepe: Eine Faltungsdarstellung für die Tonhöhenschätzung | Maxrmorrison/Torchcrepe |
| Doi: 10.1016/j.wocn.2018.07.001 | Parselmouth (F0 -Prädiktor) | Einführung in Parselmouth: Eine Python -Schnittstelle zu Praat | Yannickjadoul/Parselmouth |
| 2306.15412v2 | RMVPE (F0 -Prädiktor) | RMVPE: Ein robustes Modell für die Schätzung der Vokal -Tonhöhe in der polyphonischen Musik | Traumhoch/RMVPE |
| 2010.05646 | HiFigan (Vocoder) | Hifi-Gan: Generative kontroverse Netzwerke für eine effiziente und High-Fidelity-Sprachsynthese | Jik876/Hifigan |
| 1810.11946 | NSF (Vocoder) | Neuronales Quellfilter-basierte Wellenformmodell für die statistische parametrische Sprachsynthese | OpenVPI/Diffsinger/Module/NSF_HIFIGAN |
| 2006.08195 | Schlange (Vocoder) | Neuronale Netzwerke lernen keine regelmäßigen Funktionen und wie man sie behebt | EdwardDixon/Snake |
| 2105.02446v3 | Flache Diffusion (Nachverarbeitung) | Diffsinger: Singen der Sprachsynthese über den flachen Diffusionsmechanismus singen | CNCHTU/Diffusion-SVC |
| K-Means | Feature K-Means Clustering (Vorverarbeitung) | Einige Methoden zur Klassifizierung und Analyse multivariater Beobachtungen | Dieses Repo |
| Feature Topk Abruf (Vorverarbeitung) | Abrufbasierte Sprachkonvertierung | RVC-Project/Retrieval-basierte Voice-Conversion-Webui | |
| flüstere ppg | flüstere ppg | PlayVoice/Whisper_ppg | |
| Bigvgan | Bigvgan | PlayVoice/SO-Vits-SVC-5.0 |
Aus irgendeinem Grund hat der Autor das ursprüngliche Repository gelöscht. Aufgrund der Fahrlässigkeit der Organisationsmitglieder wurde die Mitwirkungsliste gelöscht, da alle Dateien zu Beginn der Rekonstruktion dieses Repositorys direkt in dieses Repository aufgeladen wurden. Fügen Sie nun eine frühere Mitwirkungsliste zu Readme.md hinzu.
Einige Mitglieder haben nicht nach ihren persönlichen Wünschen aufgeführt.
Mist | Xiaomiku01 | しぐれ | Tomogasukunai | Plachtaa | Zd 小达 | 凍聲響世 |
任何组织或者个人不得以丑化、污损 , 或者利用信息技术手段伪造等方式侵害他人的肖像权。未经肖像权人同意 , 不得制作、使用、公开肖像权人的肖像 , 但是法律另有规定的 但是法律另有规定的除外。未经肖像权人同意 , 肖像作品权利人不得以发表、复制、发行、出租、展览等方式使用或者公开肖像权人的肖像。对自然人声音的保护 , 参照适用肖像权保护的有关规定。 参照适用肖像权保护的有关规定。
【名誉权】民事主体享有名誉权。任何组织或者个人不得以侮辱、诽谤等方式侵害他人的名誉权。
【作品侵害名誉权】行为人发表的文学、艺术作品以真人真事或者特定人为描述对象 , 含有侮辱、诽谤内容 , 侵害他人名誉权的 , 受害人有权依法请求该行为人承担民事责任。行为 受害人有权依法请求该行为人承担民事责任。行为人发表的文学、艺术作品不以特定人为描述对象 , 仅其中的情节与该特定人的情况相似的 , 不承担民事责任。 不承担民事责任。


