so vits svc
1.0.0
ภาษาอังกฤษ |中文简体
การอัปเดตรอบเวลาที่ จำกัด นี้สิ้นสุดลงคลังสินค้าจะเข้าสู่รัฐ Archieve โปรดทราบ
สตูดิโอที่มีตัวแก้ไข F0 ที่มองเห็นได้ตัวแก้ไขไทม์ไลน์ของลำโพงผสมและคุณสมบัติอื่น ๆ (ที่ใช้โมเดล ONNX): Moevoicestudio
ส้อมที่มีส่วนต่อประสานผู้ใช้ที่ได้รับการปรับปรุงอย่างมาก: 34J/SO-VITS-SVC-FORK
ลูกค้ารองรับการแปลงแบบเรียลไทม์: W-okada/Voice-Changer
โครงการนี้แตกต่างจาก VITS โดยมุ่งเน้นไปที่การแปลงเสียงการร้องเพลง (SVC) มากกว่าข้อความเป็นคำพูด (TTS) ในโครงการนี้ไม่รองรับฟังก์ชั่น TTS และ VITS ไม่สามารถปฏิบัติงาน SVC ได้ เป็นสิ่งสำคัญที่จะต้องทราบว่าแบบจำลองที่ใช้ในโครงการทั้งสองนี้ไม่สามารถใช้แทนกันได้หรือใช้ได้ในระดับสากล
วัตถุประสงค์ของโครงการนี้คือเพื่อให้นักพัฒนาสามารถมีตัวละครอนิเมะที่รักของพวกเขาทำงานร้องเพลง ความตั้งใจของนักพัฒนาคือการมุ่งเน้นไปที่ตัวละครสมมติ แต่เพียงผู้เดียวและหลีกเลี่ยงการมีส่วนร่วมของบุคคลจริงทุกสิ่งที่เกี่ยวข้องกับบุคคลจริงเบี่ยงเบนจากความตั้งใจดั้งเดิมของนักพัฒนา
โครงการนี้เป็นโอเพ่นซอร์สความพยายามแบบออฟไลน์และสมาชิกทุกคนของ SVCDevelopTeam รวมถึงนักพัฒนาและผู้ดูแลอื่น ๆ ที่เกี่ยวข้อง (ต่อไปนี้เรียกว่าผู้มีส่วนร่วม) ไม่มีการควบคุมโครงการ ผู้มีส่วนร่วมไม่เคยให้ความช่วยเหลือในรูปแบบใด ๆ แก่องค์กรหรือบุคคลใด ๆ รวมถึง แต่ไม่ จำกัด เฉพาะการสกัดชุดข้อมูลการประมวลผลชุดข้อมูลการสนับสนุนการคำนวณการสนับสนุนการฝึกอบรมการอนุมานและอื่น ๆ ผู้มีส่วนร่วมไม่ได้และไม่สามารถตระหนักถึงวัตถุประสงค์ที่ผู้ใช้ใช้โครงการ ดังนั้นโมเดล AI ใด ๆ และเสียงสังเคราะห์ที่ผลิตผ่านการฝึกอบรมของโครงการนี้จะไม่เกี่ยวข้องกับผู้มีส่วนร่วม ปัญหาหรือผลกระทบใด ๆ ที่เกิดขึ้นจากการใช้งานของพวกเขาเป็นความรับผิดชอบเพียงอย่างเดียวของผู้ใช้
โครงการนี้ทำงานแบบออฟไลน์อย่างสมบูรณ์และไม่ได้รวบรวมข้อมูลผู้ใช้หรือรวบรวมข้อมูลผู้ใช้ ดังนั้นผู้มีส่วนร่วมในโครงการนี้ไม่ได้ตระหนักถึงการป้อนข้อมูลและรุ่นของผู้ใช้ทั้งหมดดังนั้นจึงไม่รับผิดชอบต่อการป้อนข้อมูลของผู้ใช้ใด ๆ
โครงการนี้ทำหน้าที่เป็นเฟรมเวิร์กเท่านั้นและไม่มีฟังก์ชั่นการสังเคราะห์คำพูดด้วยตัวเอง ฟังก์ชันทั้งหมดต้องการให้ผู้ใช้ฝึกอบรมแบบจำลองอย่างอิสระ นอกจากนี้โครงการนี้ไม่ได้มาพร้อมกับโมเดลใด ๆ และโครงการที่มีการแจกจ่ายรองใด ๆ นั้นเป็นอิสระจากผู้มีส่วนร่วมของโครงการนี้
รูปแบบการแปลงเสียงร้องเพลงใช้ตัวเข้ารหัสเนื้อหา SoftVC เพื่อแยกคุณสมบัติการพูดออกจากเสียงต้นฉบับ เวกเตอร์คุณลักษณะเหล่านี้จะถูกป้อนเข้าสู่ VITS โดยตรงโดยไม่จำเป็นต้องแปลงเป็นตัวแทนระดับกลางที่ใช้ข้อความ เป็นผลให้ระดับเสียงและน้ำเสียงของเสียงดั้งเดิมได้รับการเก็บรักษาไว้ ในขณะเดียวกันผู้ร้องก็ถูกแทนที่ด้วย NSF Hifigan เพื่อแก้ปัญหาการหยุดชะงักของเสียง
config.json เพิ่มฟิลด์ speech_encoder ในส่วน "โมเดล" ดังที่แสดงด้านล่าง: "model": {
.........
"ssl_dim": 256,
"n_speakers": 200,
"speech_encoder":"vec256l9"
}
จากการทดสอบของเราเราได้พิจารณาแล้วว่าโครงการทำงานเสถียรบน Python 3.8.9
คุณต้องเลือกหนึ่ง encoder จากรายการด้านล่าง
vec768l12 และ vec256l9 จำเป็นต้องมี encoder
pretrainหรือดาวน์โหลด ContentVec ต่อไปนี้ซึ่งมีขนาด 199MB แต่มีเอฟเฟกต์เดียวกัน:
checkpoint_best_legacy_500.pt และวางไว้ในไดเรกทอรี pretrain # contentvec
wget -P pretrain/ https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/hubert_base.pt -O checkpoint_best_legacy_500.pt
# Alternatively, you can manually download and place it in the hubert directory pretrain whisper-ppgwhisper-ppg-largepretrain pretrain pretrain wavlmbase+pretrain pretrain ไฟล์รุ่นที่ผ่านการฝึกอบรมมาก่อน: G_0.pth D_0.pth
logs/44k รูปแบบการแพร่กระจายไฟล์พื้นฐาน pretraining ไฟล์: model_0.pt
logs/44k/diffusion directoryรับแบบจำลองที่ได้รับการฝึกอบรมล่วงหน้าจาก SOVITS จาก SVC-Develop-Develop-Team (TBD) หรือที่อื่น ๆ
โมเดลการแพร่กระจายการอ้างอิงแบบจำลองการแพร่กระจาย SVC รูปแบบการแพร่กระจายที่ผ่านการฝึกอบรมมาก่อนเป็นสากลกับ DDSP-SVC คุณสามารถไปที่ Repo ของ Diffusion-SVC เพื่อรับแบบจำลองการแพร่กระจายที่ผ่านการฝึกอบรมมาก่อน
ในขณะที่แบบจำลองที่ผ่านการฝึกอบรมโดยทั่วไปไม่ได้เป็นข้อกังวลเกี่ยวกับลิขสิทธิ์ แต่ก็เป็นสิ่งสำคัญที่จะต้องระมัดระวัง ขอแนะนำให้ปรึกษากับผู้เขียนล่วงหน้าหรือตรวจสอบคำอธิบายอย่างรอบคอบเพื่อตรวจสอบการใช้งานที่อนุญาตของแบบจำลอง สิ่งนี้จะช่วยให้มั่นใจว่าสอดคล้องกับแนวทางหรือข้อ จำกัด ที่ระบุใด ๆ เกี่ยวกับการใช้ประโยชน์
หากคุณใช้ NSF-HIFIGAN enhancer หรือ shallow diffusion คุณจะต้องดาวน์โหลดโมเดล NSF-Hifigan ที่ผ่านการฝึกอบรมมาก่อน
pretrain/nsf_hifigan # nsf_hifigan
wget -P pretrain/ https://github.com/openvpi/vocoders/releases/download/nsf-hifigan-v1/nsf_hifigan_20221211.zip
unzip -od pretrain/nsf_hifigan pretrain/nsf_hifigan_20221211.zip
# Alternatively, you can manually download and place it in the pretrain/nsf_hifigan directory
# URL: https://github.com/openvpi/vocoders/releases/tag/nsf-hifigan-v1 หากคุณใช้ตัวทำนาย rmvpe F0 คุณจะต้องดาวน์โหลดรุ่น RMVPE ที่ผ่านการฝึกอบรมมาก่อน
rmvpe.zip , และเปลี่ยนชื่อไฟล์ model.pt เป็น rmvpe.pt และวางไว้ใต้ไดเรกทอรี pretrainpretrain FCPE (ตัวประมาณพิทช์บริบทที่รวดเร็ว) เป็นตัวทำนาย F0 โดยเฉพาะที่ออกแบบมาสำหรับการแปลงเสียงแบบเรียลไทม์และจะกลายเป็นตัวทำนาย F0 ที่ต้องการสำหรับการแปลงเสียงแบบเรียลไทม์ในอนาคต (กระดาษกำลังเขียน)
หากคุณใช้ตัวทำนาย fcpe F0 คุณจะต้องดาวน์โหลดโมเดล FCPE ที่ผ่านการฝึกอบรมมาก่อน
pretrain เพียงวางชุดข้อมูลในไดเรกทอรี dataset_raw ด้วยโครงสร้างไฟล์ต่อไปนี้:
dataset_raw
├───speaker0
│ ├───xxx1-xxx1.wav
│ ├───...
│ └───Lxx-0xx8.wav
└───speaker1
├───xx2-0xxx2.wav
├───...
└───xxx7-xxx007.wav
ไม่มีข้อ จำกัด เฉพาะในรูปแบบของชื่อสำหรับไฟล์เสียงแต่ละไฟล์ (การตั้งชื่อการประชุมเช่น 000001.wav ถึง 999999.wav ก็ใช้ได้) แต่ประเภทไฟล์จะต้องเป็น `wav``
คุณสามารถปรับแต่งชื่อของผู้พูดตามที่แสดงด้านล่าง:
dataset_raw
└───suijiSUI
├───1.wav
├───...
└───25788785-20221210-200143-856_01_(Vocals)_0_0.wav
เพื่อหลีกเลี่ยงการล้นหน่วยความจำวิดีโอในระหว่างการฝึกอบรมหรือการประมวลผลล่วงหน้าขอแนะนำให้ จำกัด ความยาวของคลิปเสียง ขอแนะนำให้ตัดเสียงเป็นความยาวของ "5s - 15s" มากขึ้น อย่างไรก็ตามเวลานานขึ้นเล็กน้อยเป็นที่ยอมรับได้คลิปที่ยาวมากเกินไปอาจทำให้เกิดปัญหาเช่น torch.cuda.OutOfMemoryError
เพื่ออำนวยความสะดวกในกระบวนการหั่นคุณสามารถใช้เสียงเครื่องยิงเสียงหรือเสียง
โดยทั่วไปจะต้องปรับ Minimum Interval เท่านั้น สำหรับเสียงที่พูดค่าเริ่มต้นมักจะเพียงพอในขณะที่สำหรับการร้องเพลงเสียงสามารถปรับได้ประมาณ 100 หรือ 50 ขึ้นอยู่กับข้อกำหนดเฉพาะ
หลังจากหั่นแล้วขอแนะนำให้ลบคลิปเสียงใด ๆ ที่ยาวมากหรือสั้นเกินไป
หากคุณใช้เครื่องเข้ารหัส Whisper-PPG สำหรับการฝึกอบรมคลิปเสียงจะต้องสั้นกว่า 30 วินาที
python resample.py แม้ว่าโครงการนี้จะมีการสุ่มตัวอย่างสคริปต์ PY สำหรับการสุ่มตัวอย่างการจับคู่โมโนและความดังการจับคู่ความดังเริ่มต้นคือการจับคู่กับ 0dB ซึ่งอาจทำให้เกิดความเสียหายต่อคุณภาพเสียง ในขณะที่แพ็คเกจการจับคู่ความดังของ Python Pyloudnorm ไม่ได้ จำกัด ระดับ แต่สิ่งนี้สามารถนำไปสู่ Sonic Boom ดังนั้นจึงขอแนะนำให้พิจารณาใช้ซอฟต์แวร์การประมวลผลเสียงระดับมืออาชีพเช่น adobe audition สำหรับการจับคู่ความดัง หากคุณกำลังใช้ซอฟต์แวร์อื่นสำหรับการจับคู่ความดังเพิ่มพารามิเตอร์ -skip_loudnorm ไปยังคำสั่ง Run:
python resample.py --skip_loudnormpython preprocess_flist_config.py --speech_encoder vec768l12Speech_enCoder มีตัวเลือกต่อไปนี้
vec768l12
vec256l9
hubertsoft
whisper-ppg
cnhubertlarge
dphubert
whisper-ppg-large
wavlmbase+
หากการอาร์กิวเมนต์ speech_encoder ถูกละเว้นค่าเริ่มต้นคือ vec768l12
ใช้การฝังความดัง
เพิ่ม --vol_aug หากคุณต้องการเปิดใช้งานการฝังความดัง:
python preprocess_flist_config.py --speech_encoder vec768l12 --vol_augหลังจากเปิดใช้งานการฝังความดังโมเดลที่ผ่านการฝึกอบรมจะตรงกับความดังของแหล่งอินพุต มิฉะนั้นมันจะตรงกับความดังของชุดการฝึกอบรม
keep_ckpts : รักษาจำนวนรุ่นก่อนหน้าในระหว่างการฝึกอบรม ตั้งค่าเป็น 0 เพื่อให้พวกเขาทั้งหมด ค่าเริ่มต้นคือ 3
all_in_mem : โหลดชุดข้อมูลทั้งหมดไปยัง RAM สามารถเปิดใช้งานได้เมื่อดิสก์ IO ของบางแพลตฟอร์มต่ำเกินไปและหน่วยความจำระบบมี ขนาดใหญ่กว่าชุดข้อมูลของคุณมาก
batch_size : จำนวนข้อมูลที่โหลดไปยัง GPU สำหรับเซสชันการฝึกอบรมครั้งเดียวสามารถปรับได้เป็นขนาดที่ต่ำกว่าความจุหน่วยความจำ GPU
vocoder_name : เลือก Vocoder ค่าเริ่มต้นคือ nsf-hifigan
cache_all_data : โหลดชุดข้อมูลทั้งหมดไปยัง RAM สามารถเปิดใช้งานได้เมื่อดิสก์ IO ของบางแพลตฟอร์มต่ำเกินไปและหน่วยความจำระบบมี ขนาดใหญ่กว่าชุดข้อมูลของคุณมาก
duration : ระยะเวลาของการหั่นด้วยเสียงในระหว่างการฝึกอบรมสามารถปรับได้ตามขนาดของหน่วยความจำวิดีโอ หมายเหตุ: ค่านี้จะต้องน้อยกว่าเวลาขั้นต่ำของเสียงในชุดการฝึกอบรม!
batch_size : จำนวนข้อมูลที่โหลดไปยัง GPU สำหรับเซสชันการฝึกอบรมครั้งเดียวสามารถปรับได้เป็นขนาดที่ต่ำกว่าความจุหน่วยความจำวิดีโอ
timesteps : จำนวนขั้นตอนทั้งหมดในรูปแบบการแพร่กระจายซึ่งเริ่มต้นเป็น 1,000
k_step_max : การฝึกอบรมสามารถฝึกอบรมการแพร่กระจาย k_step_max เพื่อประหยัดเวลาการฝึกอบรมโปรดทราบว่าค่าจะต้องน้อยกว่า timesteps 0 คือการฝึกอบรมโมเดลการแพร่กระจายทั้งหมด หมายเหตุ: หากคุณไม่ได้ฝึกอบรมแบบจำลองการแพร่กระจายทั้งหมดจะไม่สามารถใช้งานได้ only_diffusion!
nsf-hifigan
nsf-snake-hifigan
python preprocess_hubert_f0.py --f0_predictor diof0_predictor มีตัวเลือกต่อไปนี้
crepe
dio
pm
harvest
rmvpe
fcpe
หากชุดฝึกอบรมมีเสียงดังเกินไปขอแนะนำให้ใช้ crepe เพื่อจัดการ F0
หากมีการละเว้นพารามิเตอร์ f0_predictor ค่าเริ่มต้นคือ rmvpe
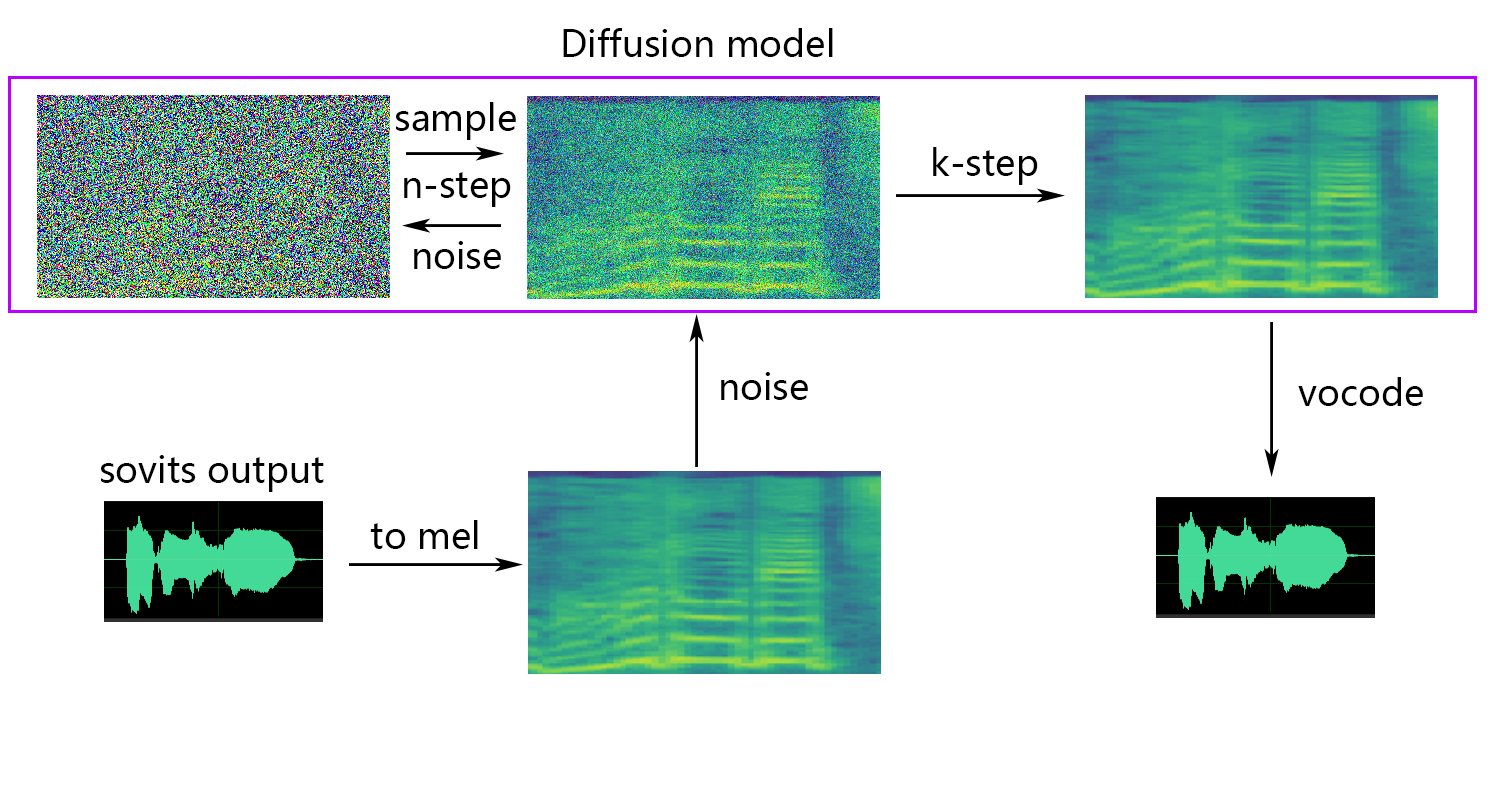
หากคุณต้องการการแพร่กระจายแบบตื้น (ไม่บังคับ) คุณต้องเพิ่มพารามิเตอร์ --use_diff ตัวอย่างเช่น:
python preprocess_hubert_f0.py --f0_predictor dio --use_diffเร่งความเร็วล่วงหน้า
หากชุดข้อมูลของคุณค่อนข้างใหญ่คุณสามารถเพิ่ม param --num_processes เช่นนั้น:
python preprocess_hubert_f0.py --f0_predictor dio --num_processes 8คนงานทั้งหมดจะได้รับมอบหมายให้ GPU ที่แตกต่างกันหากคุณมีมากกว่าหนึ่ง GPU
หลังจากทำตามขั้นตอนข้างต้นเสร็จแล้วไดเรกทอรีชุดข้อมูลจะมีข้อมูลที่ประมวลผลล่วงหน้าและโฟลเดอร์ DataSet_raw สามารถลบได้
python train.py -c configs/config.json -m 44kหากจำเป็นต้องใช้ฟังก์ชั่นการแพร่กระจายแบบตื้นรูปแบบการแพร่กระจายจะต้องได้รับการฝึกอบรม วิธีการฝึกอบรมแบบจำลองการแพร่กระจายมีดังนี้:
python train_diff.py -c configs/diffusion.yaml ในระหว่างการฝึกอบรมไฟล์โมเดลจะถูกบันทึกลงใน logs/44k และรูปแบบการแพร่กระจายจะถูกบันทึกลงใน logs/44k/diffusion
ใช้ inference_main.py
# Example
python inference_main.py -m " logs/44k/G_30400.pth " -c " configs/config.json " -n "君の知らない物語-src.wav " -t 0 -s " nen "พารามิเตอร์ที่จำเป็น:
-m | --model_path : เส้นทางสู่โมเดล-c | --config_path : พา ธ ไปยังไฟล์การกำหนดค่า-n | --clean_names : รายการชื่อไฟล์ WAV ที่อยู่ในโฟลเดอร์ raw-t | --trans : Pitch Shift สนับสนุนค่าบวกและลบ (semitone)-s | --spk_list : เลือก ID ลำโพงเพื่อใช้สำหรับการแปลง-cl | --clip : การตัดเสียงบังคับตั้งค่าเป็น 0 เพื่อปิดการใช้งาน (ค่าเริ่มต้น) ตั้งค่าเป็นค่าที่ไม่ใช่ศูนย์ (ระยะเวลาในวินาที) เพื่อเปิดใช้งานพารามิเตอร์เสริม: ดูส่วนถัดไป
-lg | --linear_gradient : ความยาวข้ามจางหายไปสองชิ้นในไม่กี่วินาที หากมีเสียงที่ไม่ต่อเนื่องหลังจากถูกบังคับให้หั่นคุณสามารถปรับค่านี้ได้ มิฉะนั้นขอแนะนำให้ใช้ค่าเริ่มต้นที่ 0-f0p | --f0_predictor : เลือกตัวทำนาย F0 ตัวเลือกคือ crepe , pm , dio , harvest , rmvpe , fcpe , ค่าเริ่มต้นคือ pm (หมายเหตุ: F0 หมายถึงการรวมค่าเฉลี่ยจะเปิดใช้งานเมื่อใช้ crepe )-a | --auto_predict_f0 : การทำนายระดับเสียงอัตโนมัติไม่เปิดใช้งานเมื่อแปลงเสียงร้องเพลงเนื่องจากอาจทำให้เกิดปัญหาระดับเสียงดัง-cm | --cluster_model_path : รุ่นคลัสเตอร์หรือเส้นทางดัชนีการดึงคุณสมบัติหากว่างเปล่าจะถูกตั้งค่าเป็นเส้นทางเริ่มต้นของรุ่นเหล่านี้โดยอัตโนมัติ หากไม่มีคลัสเตอร์การฝึกอบรมหรือการดึงคุณลักษณะให้กรอกที่จะ-cr | --cluster_infer_ratio : สัดส่วนของการจัดกลุ่มรูปแบบหรือช่วงการดึงข้อมูลจาก 0 ถึง 1 หากไม่มีรูปแบบการฝึกอบรมการจัดกลุ่มหรือการดึงคุณลักษณะค่าเริ่มต้นคือ 0-eh | --enhance : ไม่ว่าจะใช้ตัวเพิ่มประสิทธิภาพ NSF_Hifigan ตัวเลือกนี้มีผลกระทบบางอย่างต่อการเพิ่มคุณภาพเสียงสำหรับบางรุ่นที่มีชุดฝึกอบรมน้อย แต่มีผลกระทบเชิงลบต่อโมเดลที่ผ่านการฝึกอบรมมาอย่างดีดังนั้นจึงถูกปิดใช้งานโดยค่าเริ่มต้น-shd | --shallow_diffusion : ไม่ว่าจะใช้การแพร่กระจายแบบตื้นหรือไม่ซึ่งสามารถแก้ปัญหาเสียงไฟฟ้าบางอย่างหลังการใช้งานได้ ตัวเลือกนี้ถูกปิดใช้งานโดยค่าเริ่มต้น เมื่อเปิดใช้งานตัวเลือกนี้ตัวเพิ่มประสิทธิภาพ NSF_HIFIGAN จะถูกปิดใช้งาน-usm | --use_spk_mix : ไม่ว่าจะใช้ฟิวชั่นเสียงแบบไดนามิก-lea | --loudness_envelope_adjustment : การปรับซองจดหมายเสียงดังของแหล่งอินพุตที่เกี่ยวข้องกับอัตราส่วนฟิวชั่นของซองเสียงดัง ยิ่งใกล้กับ 1 ยิ่งใช้ซองไฟดังขึ้นมากขึ้นเท่านั้น-fr | --feature_retrieval : ว่าจะใช้การดึงคุณสมบัติหรือไม่หากใช้โมเดลการจัดกลุ่มมันจะถูกปิดใช้งานและพารามิเตอร์ cm และ cr จะกลายเป็นเส้นทางดัชนีและอัตราส่วนการผสมของการดึงคุณสมบัติการตั้งค่าการแพร่กระจายแบบตื้น:
-dm | --diffusion_model_path : เส้นทางโมเดลการแพร่กระจาย-dc | --diffusion_config_path : เส้นทางไฟล์กำหนดค่าการแพร่กระจาย-ks | --k_step : ยิ่งจำนวน k_steps มากขึ้นเท่าไหร่ก็ยิ่งใกล้กับผลลัพธ์ของโมเดลการแพร่กระจาย ค่าเริ่มต้นคือ 100-od | --only_diffusion : ไม่ว่าจะใช้เฉพาะโหมดการแพร่กระจายซึ่งไม่โหลดโมเดล Sovits เพื่อใช้การอนุมานแบบจำลองการแพร่กระจายเท่านั้น-se | --second_encoding : ซึ่งเกี่ยวข้องกับการใช้การเข้ารหัสเพิ่มเติมกับเสียงดั้งเดิมก่อนการแพร่กระจายแบบตื้น ตัวเลือกนี้สามารถให้ผลลัพธ์ที่แตกต่างกัน - บางครั้งบวกและบางครั้งก็เป็นลบ หากการอนุมานโดยใช้เครื่องเข้ารหัสเสียงเพลง whisper-ppg คุณจะต้องตั้งค่า --clip เป็น 25 และ -lg เป็น 1 มิฉะนั้นมันจะล้มเหลวในการอนุมานอย่างถูกต้อง
หากคุณพอใจกับผลลัพธ์ก่อนหน้านี้หรือหากคุณไม่รู้สึกว่าคุณเข้าใจสิ่งต่อไปนี้คุณสามารถข้ามไปได้และจะไม่มีผลต่อการใช้แบบจำลอง ผลกระทบของการตั้งค่าที่เป็นตัวเลือกเหล่านี้ที่กล่าวถึงมีขนาดค่อนข้างเล็กและในขณะที่พวกเขาอาจมีผลกระทบต่อชุดข้อมูลเฉพาะในกรณีส่วนใหญ่ความแตกต่างอาจไม่สำคัญ
ในระหว่างการฝึกอบรมรุ่น 4.0 ตัวทำนาย F0 ได้รับการฝึกฝนเช่นกันซึ่งช่วยให้สามารถทำนายพิทช์อัตโนมัติในระหว่างการแปลงด้วยเสียง อย่างไรก็ตามหากผลลัพธ์ไม่เป็นที่น่าพอใจสามารถใช้การทำนายระดับเสียงด้วยตนเองแทนได้ โปรดทราบว่าเมื่อแปลงเสียงร้องเพลงขอแนะนำว่าจะไม่เปิดใช้งานคุณสมบัตินี้เนื่องจากอาจทำให้เกิดการขยับอย่างมีนัยสำคัญ
auto_predict_f0 เป็น true in inference_main.pyบทนำ: รูปแบบการจัดกลุ่มที่ใช้ในแบบจำลองนี้มีวัตถุประสงค์เพื่อลดการรั่วไหลของเสียงต่ำและเพิ่มความคล้ายคลึงกันของแบบจำลองที่ผ่านการฝึกอบรมกับเสียงต่ำของเป้าหมายแม้ว่าผลกระทบอาจไม่เด่นชัดมากนัก อย่างไรก็ตามการพึ่งพาการจัดกลุ่มเพียงอย่างเดียวสามารถลดความชัดเจนของโมเดลและทำให้ฟังดูแตกต่างกันน้อยลง ดังนั้นวิธีการฟิวชั่นจึงถูกนำมาใช้ในรูปแบบนี้เพื่อควบคุมความสมดุลระหว่างวิธีการจัดกลุ่มและวิธีการไม่รวมกลุ่ม สิ่งนี้ช่วยให้การปรับเปลี่ยนการแลกเปลี่ยนระหว่าง "เสียงเหมือนเสียงต่ำของเป้าหมาย" และ "มีการออกเสียงชัดเจน" เพื่อค้นหาสมดุลที่เหมาะสมที่สุด
ไม่จำเป็นต้องมีการเปลี่ยนแปลงในขั้นตอนที่มีอยู่ เพียงฝึกอบรมรูปแบบการจัดกลุ่มเพิ่มเติมซึ่งมีค่าใช้จ่ายในการฝึกอบรมค่อนข้างต่ำ
python cluster/train_cluster.py รูปแบบเอาต์พุตจะถูกบันทึกไว้ใน logs/44k/kmeans_10000.ptpython cluster/train_cluster.py --gpucluster_model_path ใน inference_main.py หากไม่ได้ระบุค่าเริ่มต้นคือ logs/44k/kmeans_10000.ptcluster_infer_ratio ใน inference_main.py โดยที่ 0 หมายถึงการไม่ใช้การจัดกลุ่มเลย 1 หมายถึงการใช้การจัดกลุ่มเท่านั้นและโดยปกติ 0.5 เพียงพอบทนำ: เช่นเดียวกับรูปแบบการจัดกลุ่มการรั่วไหลของเสียงต่ำสามารถลดลงการออกเสียงดีกว่าการจัดกลุ่มเล็กน้อย แต่จะลดความเร็วในการอนุมาน ด้วยการใช้วิธีการฟิวชั่นมันเป็นไปได้ที่จะควบคุมความสมดุลระหว่างการดึงคุณสมบัติและการดึงข้อมูลที่ไม่ใช่คุณสมบัติเป็นเส้นตรงทำให้สามารถปรับสัดส่วนที่ต้องการได้อย่างละเอียด
python train_index.py -c configs/config.json เอาต์พุตของรุ่นจะอยู่ใน logs/44k/feature_and_index.pkl
--feature_retrieval จำเป็นต้องได้รับการกำหนดก่อนและโหมดการจัดกลุ่มจะเปลี่ยนเป็นโหมดการดึงคุณสมบัติโดยอัตโนมัติcluster_model_path ใน inference_main.py หากไม่ได้ระบุค่าเริ่มต้นคือ logs/44k/feature_and_index.pklcluster_infer_ratio ใน inference_main.py โดยที่ 0 หมายถึงการไม่ใช้การดึงคุณสมบัติเลย 1 หมายถึงการใช้การดึงคุณสมบัติเท่านั้นและโดยปกติ 0.5 เพียงพอ โมเดลที่สร้างขึ้นมีข้อมูลที่จำเป็นสำหรับการฝึกอบรมเพิ่มเติม หากคุณยืนยันว่าโมเดลนั้นเป็นที่สิ้นสุดและไม่ได้ใช้ในการฝึกอบรมเพิ่มเติมจะปลอดภัยที่จะลบข้อมูลเหล่านี้เพื่อให้ได้ขนาดไฟล์ที่เล็กลง (ประมาณ 1/3)
# Example
python compress_model.py -c= " configs/config.json " -i= " logs/44k/G_30400.pth " -o= " logs/44k/release.pth " อ้างถึงไฟล์ webUI.py สำหรับการผสม Timbre ที่เสถียรของคุณสมบัติ Gadget/Lab
บทนำ: ฟังก์ชั่นนี้สามารถรวมโมเดลหลายรุ่นเข้าด้วย
บันทึก:
model ใน config.json ของทุกรุ่นที่จะผสมจะเหมือนกัน อ้างถึงไฟล์ spkmix.py สำหรับการแนะนำการผสมเสียงต่ำแบบไดนามิก
กฎการเขียนแทร็กผสมอักขระ:
ID บทบาท: [[เวลาเริ่มต้น 1, เวลาสิ้นสุด 1, ค่าเริ่มต้น 1, ค่าเริ่มต้น 1], [เวลาเริ่มต้น 2, เวลาสิ้นสุด 2, ค่าเริ่มต้น 2]]
เวลาเริ่มต้นจะต้องเหมือนกันกับเวลาสิ้นสุดของคนก่อนหน้า เวลาเริ่มต้นแรกจะต้องเป็น 0 และเวลาสุดท้ายจะต้องเป็น 1 (ช่วงเวลาตั้งแต่ 0 ถึง 1)
บทบาททั้งหมดจะต้องกรอกสำหรับบทบาทที่ไม่ได้ใช้เติม [[0. , 1. , 0. , 0]]
ค่าฟิวชั่นสามารถกรอกได้โดยพลการและการเปลี่ยนแปลงเชิงเส้นจากค่าเริ่มต้นเป็นค่าสุดท้ายภายในระยะเวลาที่กำหนด ที่
การรวมกันเชิงเส้นภายในจะรับประกันได้ว่าเป็น 1 (เงื่อนไขการรวมกันของนูน) ดังนั้นจึงสามารถใช้งานได้อย่างปลอดภัย
ใช้พารามิเตอร์ --use_spk_mix เมื่อการให้เหตุผลเพื่อเปิดใช้งานการผสมเสียงต่ำแบบไดนามิก
ใช้ onnx_export.py
checkpoints และเปิดมันcheckpoints เป็นโฟลเดอร์โครงการของคุณตั้งชื่อตามโครงการของคุณเช่น aziplayermodel.pth ไฟล์กำหนดค่าเป็น config.json และวางไว้ในโฟลเดอร์ aziplayer ที่คุณเพิ่งสร้าง"NyaruTaffy" ใน path = "NyaruTaffy" ใน onnx_export.py ชื่อโครงการของคุณ path = "aziplayer" (onnx_export_speaker_mix ทำให้คุณสามารถผสมเสียงของลำโพง)model.onnx จะถูกสร้างขึ้นในโฟลเดอร์โครงการของคุณซึ่งเป็นโมเดลที่ส่งออกหมายเหตุ: สำหรับรุ่น Hubert Onnx โปรดใช้โมเดลที่จัดทำโดย Moess ขณะนี้พวกเขาไม่สามารถส่งออกด้วยตนเอง (Hubert ใน Fairseq มีผู้ให้บริการที่ไม่ได้รับการสนับสนุนจำนวนมากและสิ่งที่เกี่ยวข้องกับค่าคงที่ที่อาจทำให้เกิดข้อผิดพลาดหรือส่งผลให้เกิดปัญหากับรูปร่างอินพุต/เอาต์พุตและผลลัพธ์เมื่อส่งออก)
| url | การกำหนด | ชื่อ | แหล่งที่มา |
|---|---|---|---|
| 2106.06103 | VITS (synthesizer) | AutoEncoder แบบแปรผันตามเงื่อนไขพร้อมการเรียนรู้ที่เป็นปฏิปักษ์สำหรับการพูดแบบ text-to-end | jaywalnut310/vits |
| 2111.02392 | softvc (encoder คำพูด) | การเปรียบเทียบหน่วยคำพูดที่ไม่ต่อเนื่องและอ่อนนุ่มสำหรับการเปลี่ยนเสียงที่ดีขึ้น | Bshall/Hubert |
| 2204.09224 | ContentVec (SPEECH ENCODER) | ContentVec: การเป็นตัวแทนการพูดที่เป็นผู้ดูแลตนเองที่ได้รับการปรับปรุงโดยผู้พูด disentangling | ASUCICITY3000/ContentVec |
| 2212.04356 | Whisper (encoder คำพูด) | การรับรู้การพูดที่แข็งแกร่งผ่านการกำกับดูแลที่อ่อนแอขนาดใหญ่ | Openai/Whisper |
| 2110.13900 | WAVLM (SPEECH ENCODER) | WAVLM: การฝึกอบรมก่อนการดูแลตนเองขนาดใหญ่สำหรับการประมวลผลคำพูดแบบเต็มสแต็ก | Microsoft/unilm/wavlm |
| 2305.17651 | Dphubert (SPEECH ENCODER) | Dphubert: การกลั่นร่วมและการตัดแต่งแบบจำลองการพูดตนเอง | pyf98/dphubert |
| ดอย: 10.21437/interspeech.2017-68 | Harvest (F0 Predictor) | การเก็บเกี่ยว: ตัวประมาณค่าความถี่พื้นฐานประสิทธิภาพสูงจากสัญญาณเสียงพูด | mmorise/world/harvest |
| AES35-000039 | DIO (F0 Predictor) | วิธีการประมาณค่า F0 ที่รวดเร็วและเชื่อถือได้ขึ้นอยู่กับการสกัดระยะเวลาของการสั่นสะเทือนแบบพับเสียงของเสียงร้องและการพูด | MMORISE/WORLD/DIO |
| 8461329 | เครป (ตัวทำนาย F0) | Crepe: การเป็นตัวแทนของการประเมินระดับเสียง | maxrmorrison/torchcrepe |
| ดอย: 10.1016/j.wocn.2018.07.001 | Parselmouth (F0 Predictor) | แนะนำ Parselmouth: A Python Interface to Praat | Yannickjadoul/Parselmouth |
| 2306.15412V2 | RMVPE (F0 Predictor) | RMVPE: โมเดลที่แข็งแกร่งสำหรับการประมาณระดับเสียงร้องในดนตรีโพลีโฟนิก | ความฝันสูง/rmvpe |
| 2010.05646 | Hifigan (Vocoder) | HIFI-GAN: เครือข่ายฝ่ายตรงข้ามที่เกิดขึ้นสำหรับการสังเคราะห์การพูดที่มีประสิทธิภาพและมีความซื่อสัตย์สูง | jik876/hifi-gan |
| 2353.11946 | NSF (Vocoder) | โมเดลรูปคลื่นที่ใช้ระบบประสาทกรองสำหรับการสังเคราะห์พารามิเตอร์เชิงสถิติ | openvpi/diffsinger/modules/nsf_hifigan |
| 2006.08195 | งู (Vocoder) | เครือข่ายประสาทไม่สามารถเรียนรู้ฟังก์ชั่นเป็นระยะและวิธีการแก้ไข | Edwarddixon/Snake |
| 2105.02446V3 | การแพร่กระจายแบบตื้น (การประมวลผลหลัง) | Diffsinger: การร้องเพลงสังเคราะห์ด้วยเสียงผ่านกลไกการแพร่กระจายแบบตื้น | Cnchtu/diffusion-SVC |
| k-means | คุณสมบัติการจัดกลุ่ม k-mean (การประมวลผลล่วงหน้า) | บางวิธีสำหรับการจำแนกประเภทและการวิเคราะห์การสังเกตหลายตัวแปร | repo นี้ |
| ฟีเจอร์ Topk Retrieval (การประมวลผลล่วงหน้า) | การแปลงด้วยเสียงแบบดึงข้อมูล | RVC-Project/Retrieval-based-voice-conversion-webui | |
| กระซิบ ppg | กระซิบ ppg | playvoice/whisper_ppg | |
| Bigvgan | Bigvgan | playvoice/so-vits-svc-5.0 |
ด้วยเหตุผลบางอย่างผู้เขียนจึงลบที่เก็บเดิม เนื่องจากความประมาทเลินเล่อของสมาชิกองค์กรรายชื่อผู้สนับสนุนจึงถูกล้างเนื่องจากไฟล์ทั้งหมดถูกอัปโหลดโดยตรงไปยังที่เก็บนี้ในตอนต้นของการสร้างที่เก็บนี้ ตอนนี้เพิ่มรายการผู้สนับสนุนก่อนหน้านี้ใน readme.md
สมาชิกบางคนยังไม่ได้ระบุตามความปรารถนาส่วนตัวของพวกเขา
Misteo | Xiaomiku01 | しぐれ | Tomogasukunai | Plachtaa | ZD 小达 | 凍聲響世 |
任何组织或者个人不得以丑化、污损, 或者利用信息技术手段伪造等方式侵害他人的肖像权。未经肖像权人同意, 不得制作、使用、公开肖像权人的肖像, 但是法律另有规定的除外。未经肖像权人同意, 肖像作品权利人不得以发表、复制、发行、出租、展览等方式使用或者公开肖像权人的肖像。对自然人声音的保护, 参照适用肖像权保护的有关规定。
【名誉权】民事主体享有名誉权。任何组织或者个人不得以侮辱、诽谤等方式侵害他人的名誉权。
【作品侵害名誉权】行为人发表的文学、艺术作品以真人真事或者特定人为描述对象, 含有侮辱、诽谤内容, 侵害他人名誉权的, 受害人有权依法请求该行为人承担民事责任。行为人发表的文学、艺术作品不以特定人为描述对象, 仅其中的情节与该特定人的情况相似的, 不承担民事责任。


