so vits svc
1.0.0
英語|中文简体
この限られた時間の更新のラウンドは終わりに近づいています、倉庫はArchieve状態に入ります、知ってください
目に見えるF0エディタ、スピーカーミックスタイムラインエディター、およびその他の機能(ONNXモデルが使用される場所)を含むスタジオ:Moevoicestudio
ユーザーインターフェイスが大幅に改善されたフォーク:34J/so-vits-svc-fork
クライアントは、リアルタイムの変換をサポートします:W-Okada/Voice-Changer
このプロジェクトは、テキストからスピーチ(TTS)ではなく、音声変換(SVC)を歌うことに焦点を当てているため、VITSと根本的に異なります。このプロジェクトでは、TTS機能はサポートされておらず、VITSはSVCタスクを実行できません。これらの2つのプロジェクトで使用されているモデルは、交換可能でも普遍的に適用されないことに注意することが重要です。
このプロジェクトの目的は、開発者が愛するアニメキャラクターに歌のタスクを実行できるようにすることでした。開発者の意図は、架空のキャラクターのみに焦点を当て、実際の個人の関与を避けることでした。実際の個人に関連するものは、開発者の当初の意図から逸脱しています。
このプロジェクトは、オープンソース、オフラインの努力であり、SVCDevelopTeamのすべてのメンバー、および関係する他の開発者とメンテナー(以下、寄稿者と呼ばれる)は、プロジェクトを制御できません。貢献者は、データセット抽出、データセット処理、コンピューティングサポート、トレーニングサポート、推論などを含むがこれらに限定されない組織または個人にどんな形式の支援を提供していません。貢献者は、ユーザーがプロジェクトを利用する目的を認識しておらず、認識できません。したがって、このプロジェクトのトレーニングを通じて作成されたAIモデルと合成オーディオは、貢献者とは無関係です。使用から生じる問題や結果は、ユーザーの唯一の責任です。
このプロジェクトは完全にオフラインで実行され、ユーザー情報を収集したり、ユーザー入力データを収集したりしません。したがって、このプロジェクトへの貢献者は、すべてのユーザー入力とモデルを認識していないため、ユーザーの入力について責任を負いません。
このプロジェクトはフレームワークとしてのみ機能し、音声統合機能を単独ではありません。すべての機能により、ユーザーはモデルを個別にトレーニングする必要があります。さらに、このプロジェクトはモデルに束ねられておらず、二次分散プロジェクトはこのプロジェクトの貢献者とは無関係です。
Singing Voice Conversion Modelは、SoftVCコンテンツエンコーダーを使用して、ソースオーディオから音声機能を抽出します。これらの機能ベクトルは、テキストベースの中間表現への変換を必要とせずに、VITに直接供給されます。その結果、元のオーディオのピッチとイントネーションが保存されます。一方、ボコーダーは、音の中断の問題を解決するためにNSF Hifiganに置き換えられました。
config.jsonファイルに変更を加えることができます。以下に示すように、 speech_encoderフィールドを「モデル」セクションに追加します。 "model": {
.........
"ssl_dim": 256,
"n_speakers": 200,
"speech_encoder":"vec256l9"
}
テストに基づいて、 Python 3.8.9でプロジェクトが安定していると判断しました。
以下のリストから1つのエンコーダーを選択する必要があります
vec768l12およびvec256l9にはエンコーダーが必要です
pretrainディレクトリの下に置きますまたは、次のContentVecをダウンロードします。これはサイズが199MBですが、同じ効果があります。
checkpoint_best_legacy_500.ptに変更し、 pretrainディレクトリに配置します # contentvec
wget -P pretrain/ https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/hubert_base.pt -O checkpoint_best_legacy_500.pt
# Alternatively, you can manually download and place it in the hubert directory pretrainディレクトリの下に置きますwhisper-ppgに適合しますwhisper-ppg-large適合しますpretrainディレクトリの下に置きますpretrainディレクトリの下に置きますpretrainディレクトリの下に置きますwavlmbase+に適合しますpretrainディレクトリの下に置きますpretrainディレクトリの下に置きます事前に訓練されたモデルファイル: G_0.pth D_0.pth
logs/44kディレクトリの下に配置します拡散モデル事前削除ベースモデルファイル: model_0.pt
logs/44k/diffusionディレクトリに入れますSVC-Develop-Team(TBD)または他のどこからでも訓練を受けたモデルを入手してください。
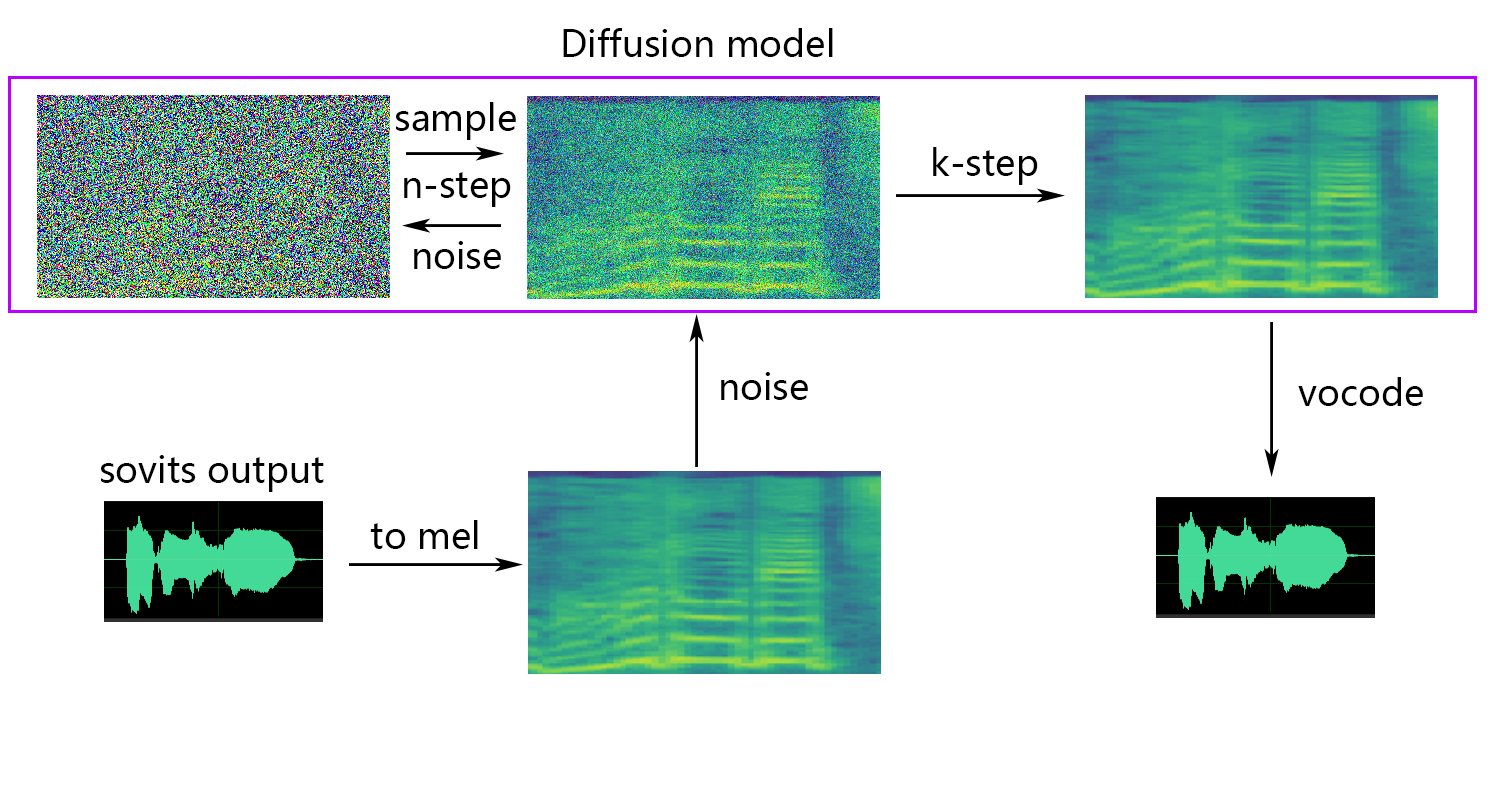
拡散モデルは、拡散SVC拡散モデルを参照します。事前に訓練された拡散モデルは、DDSP-SVCと普遍的です。 Diffusion-SVCのリポジトリにアクセスして、事前に訓練された拡散モデルを取得できます。
一般的には、事前に守られたモデルは著作権の懸念をもたらしませんが、警戒し続けることが不可欠です。著者と事前に相談するか、説明を慎重に確認して、モデルの許容される使用法を確認することをお勧めします。これにより、指定されたガイドラインまたはその利用に関する制限の遵守を確保するのに役立ちます。
NSF-HIFIGAN enhancerまたはshallow diffusionを使用している場合は、事前に訓練されたNSF-Hifiganモデルをダウンロードする必要があります。
pretrain/nsf_hifiganディレクトリの下に解凍して配置します # nsf_hifigan
wget -P pretrain/ https://github.com/openvpi/vocoders/releases/download/nsf-hifigan-v1/nsf_hifigan_20221211.zip
unzip -od pretrain/nsf_hifigan pretrain/nsf_hifigan_20221211.zip
# Alternatively, you can manually download and place it in the pretrain/nsf_hifigan directory
# URL: https://github.com/openvpi/vocoders/releases/tag/nsf-hifigan-v1 rmvpe F0予測子を使用している場合は、事前に訓練されたRMVPEモデルをダウンロードする必要があります。
rmvpe.zip 、およびmodel.ptファイルの名前をrmvpe.ptに変更し、 pretrainディレクトリの下に配置します。pretrainディレクトリの下に置きますFCPE(高速コンテキストベースピッチ推定器)は、リアルタイムの音声変換用に設計された専用のF0予測子であり、将来のソビットのリアルタイム音声変換の優先F0予測子になります(論文は書かれています)
fcpe F0予測子を使用している場合は、事前に訓練されたFCPEモデルをダウンロードする必要があります。
pretrainディレクトリの下に置きますデータセットを次のファイル構造でデータdataset_rawに配置するだけです。
dataset_raw
├───speaker0
│ ├───xxx1-xxx1.wav
│ ├───...
│ └───Lxx-0xx8.wav
└───speaker1
├───xx2-0xxx2.wav
├───...
└───xxx7-xxx007.wav
各オーディオファイルの名前の形式には具体的な制限はありません( 000001.wavから999999.wavなどの命名規則も有効です)が、ファイルタイプは「WAV」でなければなりません。
以下に示すように、スピーカーの名前をカスタマイズできます。
dataset_raw
└───suijiSUI
├───1.wav
├───...
└───25788785-20221210-200143-856_01_(Vocals)_0_0.wav
トレーニングや前処理中のビデオメモリオーバーフローを回避するには、オーディオクリップの長さを制限することをお勧めします。オーディオを「5S〜15S」の長さにカットすることをお勧めします。わずかに長い時間は受け入れられますが、過度に長いクリップがtorch.cuda.OutOfMemoryErrorなどの問題を引き起こす可能性があります。
スライスプロセスを容易にするには、Audio-Slicer-GuiまたはAudio-Slicer-Cliを使用できます
一般に、 Minimum Intervalのみを調整する必要があります。音声オーディオの場合、通常はデフォルト値で十分であり、オーディオを歌うには、特定の要件に応じて約100または50に調整できます。
スライス後、過度に長くまたは短すぎるオーディオクリップを削除することをお勧めします。
トレーニングにWhisper-PPGエンコーダーを使用している場合、オーディオクリップは30秒より短くする必要があります。
python resample.pyこのプロジェクトには、再サンプリング、モノ、ラウドネスマッチング用のResample.pyスクリプトがありますが、デフォルトのラウドネスマッチングは0dBに一致することです。これにより、音質に損傷を与える可能性があります。 PythonのラウドネスマッチングパッケージPyloudnormはレベルを制限しませんが、これはソニックブームにつながる可能性があります。したがって、ラウドネスマッチングのためのadobe auditionなど、プロのサウンド処理ソフトウェアの使用を検討することをお勧めします。既にラウドネスマッチングに他のソフトウェアを使用している場合は、parameter -skip_loudnorm実行コマンドに追加します。
python resample.py --skip_loudnormpython preprocess_flist_config.py --speech_encoder vec768l12Speech_Encoderには次のオプションがあります
vec768l12
vec256l9
hubertsoft
whisper-ppg
cnhubertlarge
dphubert
whisper-ppg-large
wavlmbase+
Speech_Encoder引数が省略されている場合、デフォルト値はvec768l12です
ラウドネス埋め込みを使用します
Loudness Embeddingを有効にしたい場合は、add --vol_aug :
python preprocess_flist_config.py --speech_encoder vec768l12 --vol_augラウドネスの埋め込みを有効にした後、訓練されたモデルは入力ソースのラウドネスと一致します。それ以外の場合は、トレーニングセットのラウドネスと一致します。
keep_ckpts :トレーニング中に以前のモデルの数を保持します。それらすべてを保持するために0に設定します。デフォルトは3です。
all_in_mem :すべてのデータセットをRAMにロードします。一部のプラットフォームのディスクIOが低すぎて、システムメモリがデータセットよりもはるかに大きい場合に有効にすることができます。
batch_size :単一のトレーニングセッションのためにGPUにロードされたデータの量は、GPUメモリ容量よりも低いサイズに調整できます。
vocoder_name :VoCoderを選択します。デフォルトはnsf-hifiganです。
cache_all_data :すべてのデータセットをRAMにロードします。一部のプラットフォームのディスクIOが低すぎて、システムメモリがデータセットよりもはるかに大きい場合に有効にすることができます。
duration :トレーニング中のオーディオスライスの期間は、ビデオメモリのサイズに応じて調整できます。注:この値は、トレーニングセットのオーディオの最小時間よりも短くなければなりません。
batch_size :単一のトレーニングセッションのためにGPUにロードされたデータの量は、ビデオメモリ容量よりも低いサイズに調整できます。
timesteps :拡散モデルのステップの総数。デフォルトは1000です。
k_step_max :トレーニングはk_step_maxステップ拡散のみをトレーニングできますトレーニング時間を節約するには、値はtimestepsよりも少ない必要があります。0は拡散モデル全体をトレーニングすることです。 only_diffusion!
nsf-hifigan
nsf-snake-hifigan
python preprocess_hubert_f0.py --f0_predictor dioF0_Predictorには次のオプションがあります
crepe
dio
pm
harvest
rmvpe
fcpe
トレーニングセットがノイズが大きすぎる場合は、 crepeを使用してF0を処理することをお勧めします
f0_predictorパラメーターが省略されている場合、デフォルト値はrmvpeです
浅い拡散(オプション)が必要な場合は、 --use_diffパラメーターを追加する必要があります。
python preprocess_hubert_f0.py --f0_predictor dio --use_diffプリプロセスをスピードアップします
データセットがかなり大きい場合は、そのようなPARAM --num_processesを増やすことができます。
python preprocess_hubert_f0.py --f0_predictor dio --num_processes 8複数のGPUを持っている場合、すべての労働者が異なるGPUに割り当てられます。
上記の手順を完了すると、DataSetディレクトリには前処理されたデータが含まれ、DataSet_Rawフォルダーを削除できます。
python train.py -c configs/config.json -m 44k浅い拡散関数が必要な場合は、拡散モデルを訓練する必要があります。拡散モデルトレーニング方法は次のとおりです。
python train_diff.py -c configs/diffusion.yamlトレーニング中、モデルファイルはlogs/44kに保存され、拡散モデルはlogs/44k/diffusionに保存されます
Inference_main.pyを使用してください
# Example
python inference_main.py -m " logs/44k/G_30400.pth " -c " configs/config.json " -n "君の知らない物語-src.wav " -t 0 -s " nen "必要なパラメーター:
-m | --model_path :モデルへのパス。-c | --config_path :構成ファイルへのパス。-n | --clean_names : rawフォルダーにあるWAVファイル名のリスト。-t | --trans :ピッチシフト、ポジティブおよびネガティブ(セミトーン)値をサポートします。-s | --spk_list :変換に使用するスピーカーIDを選択します。-cl | --clip :強制オーディオクリッピング、0に設定して無効にし(デフォルト)、ゼロ以外の値(秒単位の期間)に設定して有効にします。オプションのパラメーター:次のセクションを参照してください
-lg | --linear_gradient :秒単位で2つのオーディオスライスのクロスフェード長。強制スライス後に不連続な音声がある場合は、この値を調整できます。それ以外の場合は、0のデフォルト値を使用することをお勧めします。-f0p | --f0_predictor :F0予測子を選択し、オプションはcrepe 、 pm 、 dio 、 harvest 、 rmvpe 、 fcpe 、デフォルト値はpmです(注:F0平均プーリングはcrepeを使用する場合に有効になります)-a | --auto_predict_f0 :自動ピッチ予測、真剣なピッチの問題を引き起こす可能性があるため、歌声を変換するときにこれを有効にしないでください。-cm | --cluster_model_path :クラスターモデルまたは機能検索インデックスパスは、空白のままにすると、これらのモデルのデフォルトパスとして自動的に設定されます。トレーニングクラスターまたは機能の取得がない場合は、自由に記入してください。-cr | --cluster_infer_ratio :クラスタリングスキームまたは機能検索の割合は0〜1の範囲です。トレーニングクラスタリングモデルまたは機能検索がない場合、デフォルトは0です。-eh | --enhance :NSF_HIFIGANエンハンサーを使用するかどうかにかかわらず、このオプションは、トレーニングセットが少ない一部のモデルの音質エンハンスメントに特定の影響を与えますが、よく訓練されたモデルに悪影響を与えるため、デフォルトでは無効になります。-shd | --shallow_diffusion :浅い拡散を使用するかどうか。このオプションはデフォルトで無効になっています。このオプションを有効にすると、NSF_HIFIGANエンハンサーが無効になります-usm | --use_spk_mix :動的な音声融合を使用するかどうか-lea | --loudness_envelope_adjustment :出力ラウドネスエンベロープの融合比に関連する入力ソースのラウドネスエンベロープの調整。 1に近いほど、出力ラウドネスエンベロープが使用されます-fr | --feature_retrieval :クラスタリングモデルを使用する場合、機能検索を使用するかどうか、無効になり、 cmおよびcrパラメーターが機能検索のインデックスパスと混合比になります浅い拡散設定:
-dm | --diffusion_model_path :拡散モデルパス-dc | --diffusion_config_path :diffusion configファイルパス-ks | --k_step :k_stepsの数が多いほど、拡散モデルの結果に近づきます。デフォルトは100です-od | --only_diffusion :拡散モードのみを使用するかどうか、拡散モデルをロードして拡散モデル推論のみを使用します-se | --second_encoding :浅い拡散前に元のオーディオに追加のエンコードを適用することが含まれます。このオプションはさまざまな結果をもたらす可能性があります - 時には肯定的で、時には否定的です。whisper-ppg Speech Encoderを使用して推論する場合は、 --clipに、 -lgを1に設定する必要があります。それ以外の場合は、適切に推測できません。
以前の結果に満足している場合、または何が続くかを理解していると感じない場合は、スキップできれば、モデルの使用には影響しません。言及されたこれらのオプションの設定の影響は比較的少なく、特定のデータセットに何らかの影響を与える可能性がありますが、ほとんどの場合、違いは重要ではないかもしれません。
4.0モデルのトレーニング中に、F0予測子もトレーニングされます。これにより、音声変換中の自動ピッチ予測が可能になります。ただし、結果が満足のいくものでない場合は、代わりに手動のピッチ予測を使用できます。歌の声を変換するときは、この機能が重要なピッチシフトを引き起こす可能性があるため、この機能を有効にしないことをお勧めします。
auto_predict_f0 true in inference_main.pyに設定します。はじめに:このモデルに実装されているクラスタリングスキームは、音色の漏れを減らし、訓練されたモデルの標的の音色との類似性を高めることを目的としていますが、効果はあまり顕著ではないかもしれません。ただし、クラスタリングのみに依存すると、モデルの明確さを軽減し、それを明確にすることができません。したがって、クラスタリングアプローチと非クラスター化アプローチのバランスを制御するために、このモデルで融合方法が採用されています。これにより、最適なバランスを見つけるために、「ターゲットの音色のように聞こえる」と「明確な発音を持っている」とのトレードオフを手動で調整できます。
既存の手順に変更は必要ありません。追加のクラスタリングモデルをトレーニングするだけで、トレーニングコストが比較的低くなります。
python cluster/train_cluster.pyを実行します。出力モデルはlogs/44k/kmeans_10000.ptに保存されます。python cluster/train_cluster.py --gpuを実行してGPUを使用してトレーニングできますcluster_model_path inference_main.pyで指定します。指定されていない場合、デフォルトはlogs/44k/kmeans_10000.ptです。inference_main.pyでcluster_infer_ratio指定します。ここで、 0クラスタリングをまったく使用しないことを意味し、 1はクラスタリングのみを使用し、通常0.5で十分です。はじめに:クラスタリングスキームと同様に、音色の漏れを減らすことができ、発音はクラスタリングよりもわずかに優れていますが、推論速度が低下します。融合法を採用することにより、フィーチャの検索と非機能検索のバランスを直線的に制御し、目的の割合を微調整できるようになります。
python train_index.py -c configs/config.jsonモデルの出力はlogs/44k/feature_and_index.pklにあります
--feature_retrieval最初に策定する必要があり、クラスタリングモードは自動的に機能検索モードに切り替わります。cluster_model_path inference_main.pyで指定します。指定されていない場合、デフォルトはlogs/44k/feature_and_index.pklです。inference_main.pyでcluster_infer_ratio指定します。ここで、 0機能検索をまったく使用しないことを意味し、 1は機能検索のみを使用し、通常0.5で十分です。 生成されたモデルには、さらなるトレーニングに必要なデータが含まれています。モデルが最終的であり、さらなるトレーニングで使用されないことを確認する場合、これらのデータを削除してファイルサイズが小さくなる(約1/3)。
# Example
python compress_model.py -c= " configs/config.json " -i= " logs/44k/G_30400.pth " -o= " logs/44k/release.pth " ガジェット/ラボ機能の安定した音色ミキシングについては、 webUI.pyファイルを参照してください。
はじめに:この関数は、複数のモデルを1つのモデル(凸の組み合わせまたは複数のモデルパラメーターの線形組み合わせ)に結合して、現実に存在しない混合音声を作成できます
注記:
modelフィールドが同じであることを確認してください動的な音色ミキシングの紹介については、 spkmix.pyファイルを参照してください
キャラクターミックストラックライティングルール:
役割ID:[[開始時間1、終了時間1、値1、開始値1]、[開始時間2、終了時間2、開始値2]]]]]
開始時間は、前の時間の終了時間と同じでなければなりません。最初の開始時間は0でなければならず、最後の終了時間は1(時間の範囲は0〜1)でなければなりません。
すべての役割を記入する必要があります。未使用の役割については、[[0.、1.、0.、0。]を記入する必要があります。
融合値は任意に埋めることができ、線形変化は指定された期間内に開始値から最終値に変化します。
内部線形の組み合わせは自動的に1(凸の組み合わせ条件)であることが保証されるため、安全に使用できます
動的な音色ミキシングを有効にするために推論するときに--use_spk_mixパラメーターを使用します
onnx_export.pyを使用してください
checkpointsという名前のフォルダーを作成して開きますcheckpointsフォルダーにフォルダを作成し、プロジェクトにちなんで名前を付けます。たとえば、 aziplayermodel.pth 、構成ファイルをconfig.jsonとして変更し、作成したばかりのaziplayerフォルダーに配置しますpath = "NyaruTaffy" "NyaruTaffy"をonnx_export.pyの「nyarutaffy」をプロジェクト名に変更します。path path = "aziplayer"model.onnx 、プロジェクトフォルダーで生成されます。これは、エクスポートされたモデルです。注:Hubert ONNXモデルの場合、MoESSが提供するモデルを使用してください。現在、彼らは自分でエクスポートすることはできません(FairseqのHubertには、サポートされていない多くのオペレーターや、エラーを引き起こす可能性のある定数を含むものがあります。
| URL | 指定 | タイトル | 実装ソース |
|---|---|---|---|
| 2106.06103 | vits(シンセサイザー) | エンドツーエンドのテキストからスピーチのための敵対的な学習を備えた条件付き変動自動エンコーダー | jaywalnut310/vits |
| 2111.02392 | softvc(音声エンコーダー) | 音声変換の改善のための離散およびソフト音声ユニットの比較 | Bshall/Hubert |
| 2204.09224 | ContentVec(SpeechEncoder) | ContentVec:スピーカーを解き放つことによる自己監視のスピーチ表現の改善 | auspicious3000/contentvec |
| 2212.04356 | ささやき(音声エンコーダー) | 大規模な弱い監督による堅牢な音声認識 | Openai/Whisper |
| 2110.13900 | wavlm(音声エンコーダー) | WAVLM:フルスタック音声処理のための大規模な自己監督の事前トレーニング | Microsoft/unilm/wavlm |
| 2305.17651 | dphubert(音声エンコーダー) | DPHUBERT:自己教師の音声モデルの共同蒸留と剪定 | pyf98/dphubert |
| doi:10.21437/interspeech.2017-68 | 収穫(F0予測子) | 収穫:音声信号からの高性能基本周波数推定器 | Mmorise/World/Harvest |
| AES35-000039 | dio(F0予測子) | 歌声と音声の声の折り畳み振動の期間抽出に基づく高速で信頼性の高いF0推定方法 | mmorise/world/dio |
| 8461329 | クレープ(F0予測子) | クレープ:ピッチ推定のための畳み込み表現 | Maxrmorrison/Torchcrepe |
| doi:10.1016/j.wocn.2018.07.001 | パーセルマス(F0予測子) | Parselmouthの紹介:PraatへのPythonインターフェイス | Yannickjadoul/Parselmouth |
| 2306.15412v2 | RMVPE(F0予測子) | RMVPE:ポリフォニック音楽のボーカルピッチ推定のための堅牢なモデル | Dream-high/rmvpe |
| 2010.05646 | ヒフィガン(ボコーダー) | HIFI-GAN:効率的かつ高忠実度の音声合成のための生成官能ネットワーク | jik876/hifi-gan |
| 1810.11946 | NSF(ボコーダー) | 統計パラメトリック音声合成のためのニューラルソースフィルターベースの波形モデル | OpenVPI/diffsinger/modules/nsf_hifigan |
| 2006.08195 | ヘビ(ボコーダー) | ニューラルネットワークは定期的な機能とそれを修正する方法を学習できません | エドワードディクソン/ヘビ |
| 2105.02446v3 | 浅い拡散(後処理) | Diffsinger:浅い拡散メカニズムによる音声合成を歌います | cnchtu/diffusion-svc |
| k-means | 機能k-meansクラスタリング(前処理) | 多変量観測の分類と分析のためのいくつかの方法 | このレポ |
| 機能TOPK検索(プレプロセッシング) | 検索ベースの音声変換 | RVC-Project/取得ベースのVoice-Conversion-Webui | |
| ささやきppg | ささやきppg | playvoice/whisper_ppg | |
| Bigvgan | Bigvgan | playvoice/so-vits-svc-5.0 |
何らかの理由で、著者は元のリポジトリを削除しました。組織メンバーの過失により、すべてのファイルがこのリポジトリの再建の開始時にこのリポジトリに直接再アップロードされたため、貢献者リストがクリアされました。以前の貢献者リストをreadme.mdに追加します。
一部のメンバーは、個人的な希望に従ってリストされていません。
ミステオ | Xiaomiku01 | しぐれ | トモガスクナイ | Plachtaa | ZD小达 | 凍聲響世 |
任何组织或者个人不得以丑化、污损、或者利用信息技术手段伪造等方式侵害他人的肖像权。未经肖像权人同意、不得制作、使用、公开肖像权人的肖像、但是法律另有规定的除外。未经肖像权人同意、肖像作品权利人不得以发表、复制、发行、出租、展览等方式使用或者公开肖像权人的肖像。对自然人声音的保护、参照适用肖像权保护的有关规定。
【名誉权】民事主体享有名誉权。任何组织或者个人不得以侮辱、诽谤等方式侵害他人的名誉权。
【作品侵害名誉权】行为人发表的文学、艺术作品以真人真事或者特定人为描述对象、含有侮辱、诽谤内容、侵害他人名誉权的、受害人有权依法请求该行为人承担民事责任。行为人发表的文学、艺术作品不以特定人为描述对象、仅其中的情节与该特定人的情况相似的、不承担民事责任。


