so vits svc
1.0.0
Inglés |中文简体
Esta ronda de actualización de tiempo limitado está llegando a su fin, el almacén ingresará al Estado de Archieve, por favor, sepa
Un estudio que contiene editor visible de F0, editor de tiempo de mezcla de oradores y otras características (donde se utilizan los modelos ONNX): MoeVoicestudio
Una bifurcación con una interfaz de usuario muy mejorada: 34J/SO-VITS-SVC-Fork
Un cliente admite la conversión en tiempo real: w-okada/cambio de voz
Este proyecto difiere fundamentalmente de los VIT, ya que se centra en la conversión de voz de canto (SVC) en lugar de el texto a la voz (TTS). En este proyecto, la funcionalidad TTS no es compatible y VITS es incapaz de realizar tareas SVC. Es importante tener en cuenta que los modelos utilizados en estos dos proyectos no son intercambiables o universalmente aplicables.
El propósito de este proyecto era permitir a los desarrolladores que sus queridos personajes de anime realicen tareas de canto. La intención de los desarrolladores era centrarse únicamente en caracteres ficticios y evitar cualquier participación de individuos reales, cualquier cosa relacionada con personas reales se desvía de la intención original del desarrollador.
Este proyecto es un esfuerzo de código abierto y fuera de línea, y todos los miembros de SVCDevelopteam, así como otros desarrolladores y mantenedores involucrados (en adelante, denominados contribuyentes), no tienen control sobre el proyecto. Los contribuyentes nunca han proporcionado ninguna forma de asistencia a ninguna organización o individuo, incluida, entre otros, la extracción del conjunto de datos, el procesamiento del conjunto de datos, el soporte informático, el soporte de capacitación, la inferencia, etc. Los contribuyentes no son y no pueden conocer los fines para los que los usuarios utilizan el proyecto. Por lo tanto, los modelos de IA y el audio sintetizado producido a través de la capacitación de este proyecto no están relacionados con los contribuyentes. Cualquier problema o consecuencias derivadas de su uso es responsabilidad exclusiva del usuario.
Este proyecto se ejecuta completamente fuera de línea y no recopila ninguna información del usuario ni recopila datos de entrada del usuario. Por lo tanto, los contribuyentes a este proyecto no son conscientes de todas las entradas y modelos del usuario y, por lo tanto, no son responsables de ninguna entrada del usuario.
Este proyecto sirve solo como un marco y no posee la funcionalidad de síntesis del habla por sí mismo. Todas las funcionalidades requieren que los usuarios entrenen a los modelos de forma independiente. Además, este proyecto no viene incluido con ningún modelo, y los proyectos distribuidos secundarios son independientes de los contribuyentes de este proyecto.
El modelo de conversión de voz de canto utiliza el codificador de contenido SoftVC para extraer características del habla del audio de origen. Estos vectores de características se alimentan directamente en VIT sin la necesidad de conversión a una representación intermedia basada en texto. Como resultado, se conservan el tono y las entonaciones del audio original. Mientras tanto, el vocoder fue reemplazado por NSF Hifigan para resolver el problema de la interrupción del sonido.
config.json . Agregue el campo speech_encoder a la sección "Modelo" como se muestra a continuación: "model": {
.........
"ssl_dim": 256,
"n_speakers": 200,
"speech_encoder":"vec256l9"
}
Según nuestras pruebas, hemos determinado que el proyecto se ejecuta estable en Python 3.8.9 .
Debe seleccionar un codificador de la lista a continuación
vec768l12 y vec256l9 requieren el codificador
pretrainO descargue el siguiente contentvec, que tiene solo 199MB de tamaño pero tiene el mismo efecto:
checkpoint_best_legacy_500.pt y colóquelo en el directorio pretrain # contentvec
wget -P pretrain/ https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/hubert_base.pt -O checkpoint_best_legacy_500.pt
# Alternatively, you can manually download and place it in the hubert directory pretrain whisper-ppgwhisper-ppg-largepretrain pretrain pretrain wavlmbase+pretrain pretrain Archivos de modelo previamente capacitados: G_0.pth D_0.pth
logs/44k Archivo del modelo base de prepertinamiento del modelo de difusión: model_0.pt
logs/44k/diffusionObtenga SOVITS Modelo previamente capacitado del equipo de desarrollo SVC (TBD) o en cualquier otro lugar.
Modelo de difusión Referencias Modelo de difusión de difusión-SVC. El modelo de difusión previamente capacitado es universal con los DDSP-SVC. Puede ir al repositorio de difusión-SVC para obtener el modelo de difusión previamente capacitado.
Si bien el modelo previamente provocado generalmente no plantea preocupaciones de derechos de autor, es esencial permanecer vigilante. Es aconsejable consultar con el autor de antemano o revisar cuidadosamente la descripción para determinar el uso permitido del modelo. Esto ayuda a garantizar el cumplimiento de las pautas o restricciones especificadas con respecto a su utilización.
Si está utilizando el NSF-HIFIGAN enhancer o shallow diffusion , deberá descargar el modelo NSF-Hifigan previamente entrenado.
pretrain/nsf_hifigan # nsf_hifigan
wget -P pretrain/ https://github.com/openvpi/vocoders/releases/download/nsf-hifigan-v1/nsf_hifigan_20221211.zip
unzip -od pretrain/nsf_hifigan pretrain/nsf_hifigan_20221211.zip
# Alternatively, you can manually download and place it in the pretrain/nsf_hifigan directory
# URL: https://github.com/openvpi/vocoders/releases/tag/nsf-hifigan-v1 Si está utilizando el predictor rmvpe F0, deberá descargar el modelo RMVPE previamente capacitado.
rmvpe.zip , y cambie el nombre del archivo model.pt a rmvpe.pt y colóquelo en el directorio pretrain .pretrain FCPE (estimador de tono de base de contexto rápido) es un predictor F0 dedicado diseñado para la conversión de voz en tiempo real y se convertirá en el predictor F0 preferido para la conversión de voz en tiempo real en el futuro. (El documento se está escribiendo)
Si está utilizando el predictor fcpe F0, deberá descargar el modelo FCPE previamente capacitado.
pretrain Simplemente coloque el conjunto de datos en el directorio dataset_raw con la siguiente estructura del archivo:
dataset_raw
├───speaker0
│ ├───xxx1-xxx1.wav
│ ├───...
│ └───Lxx-0xx8.wav
└───speaker1
├───xx2-0xxx2.wav
├───...
└───xxx7-xxx007.wav
No hay restricciones específicas en el formato del nombre para cada archivo de audio (convenciones de nombres como 000001.wav a 999999.wav también son válidos), pero el tipo de archivo debe ser `wav``.
Puede personalizar el nombre del altavoz como se muestra a continuación:
dataset_raw
└───suijiSUI
├───1.wav
├───...
└───25788785-20221210-200143-856_01_(Vocals)_0_0.wav
Para evitar el desbordamiento de la memoria de video durante el entrenamiento o el preprocesamiento, se recomienda limitar la longitud de los clips de audio. Se recomienda cortar el audio a una longitud de "5s - 15s". Los tiempos un poco más largos son aceptables, sin embargo, los clips excesivamente largos pueden causar problemas como torch.cuda.OutOfMemoryError .
Para facilitar el proceso de corte, puede usar audio-etiqueta-guía o cli de audio-etiqueta
En general, solo el Minimum Interval debe ajustarse. Para el audio hablado, el valor predeterminado generalmente es suficiente, mientras que para cantar audio, se puede ajustar a alrededor de 100 o incluso 50 , dependiendo de los requisitos específicos.
Después de cortar, se recomienda eliminar los clips de audio que sean excesivamente largos o demasiado cortos.
Si está utilizando el codificador Whisper-PPG para el entrenamiento, los clips de audio deben menos que los 30.
python resample.py Aunque este proyecto tiene scripts reamither.py para la coincidencia de remuestreo, mono y volumen, la coincidencia predeterminada de volumen es coincidir con 0dB. Esto puede causar daños a la calidad del sonido. Si bien el paquete de emparejamiento de volumen de Python Pyloudnorm no limita el nivel, esto puede conducir al boom sónico. Por lo tanto, se recomienda considerar el uso de un software profesional de procesamiento de sonido, como adobe audition para la coincidencia de volumen. Si ya está utilizando otro software para la coincidencia de volumen, agregue el parámetro -skip_loudnorm al comando ejecutar:
python resample.py --skip_loudnormpython preprocess_flist_config.py --speech_encoder vec768l12Speech_encoder tiene las siguientes opciones
vec768l12
vec256l9
hubertsoft
whisper-ppg
cnhubertlarge
dphubert
whisper-ppg-large
wavlmbase+
Si se omite el argumento Speech_encoder, el valor predeterminado es vec768l12
Use la incrustación de volumen
Agregar --vol_aug si desea habilitar la incrustación de volumen:
python preprocess_flist_config.py --speech_encoder vec768l12 --vol_augDespués de habilitar la incrustación de volumen, el modelo entrenado coincidirá con el volumen de la fuente de entrada; De lo contrario, coincidirá con el volumen del set de entrenamiento.
keep_ckpts : mantenga el número de modelos anteriores durante el entrenamiento. Establecer en 0 para mantenerlos a todos. El valor predeterminado es 3 .
all_in_mem : Cargue todo el conjunto de datos a RAM. Se puede habilitar cuando el disco IO de algunas plataformas es demasiado baja y la memoria del sistema es mucho más grande que su conjunto de datos.
batch_size : la cantidad de datos cargados en la GPU para una sola sesión de entrenamiento se puede ajustar a un tamaño inferior a la capacidad de memoria de la GPU.
vocoder_name : seleccione un Vocoder. El valor predeterminado es nsf-hifigan .
cache_all_data : Cargue todo el conjunto de datos a RAM. Se puede habilitar cuando el disco IO de algunas plataformas es demasiado baja y la memoria del sistema es mucho más grande que su conjunto de datos.
duration : la duración del corte de audio durante el entrenamiento, se puede ajustar de acuerdo con el tamaño de la memoria de video, Nota: ¡Este valor debe ser menor que el tiempo mínimo del audio en el conjunto de capacitación!
batch_size : la cantidad de datos cargados en la GPU para una sola sesión de entrenamiento se puede ajustar a un tamaño inferior a la capacidad de memoria de video.
timesteps : el número total de pasos en el modelo de difusión, que predeterminan a 1000.
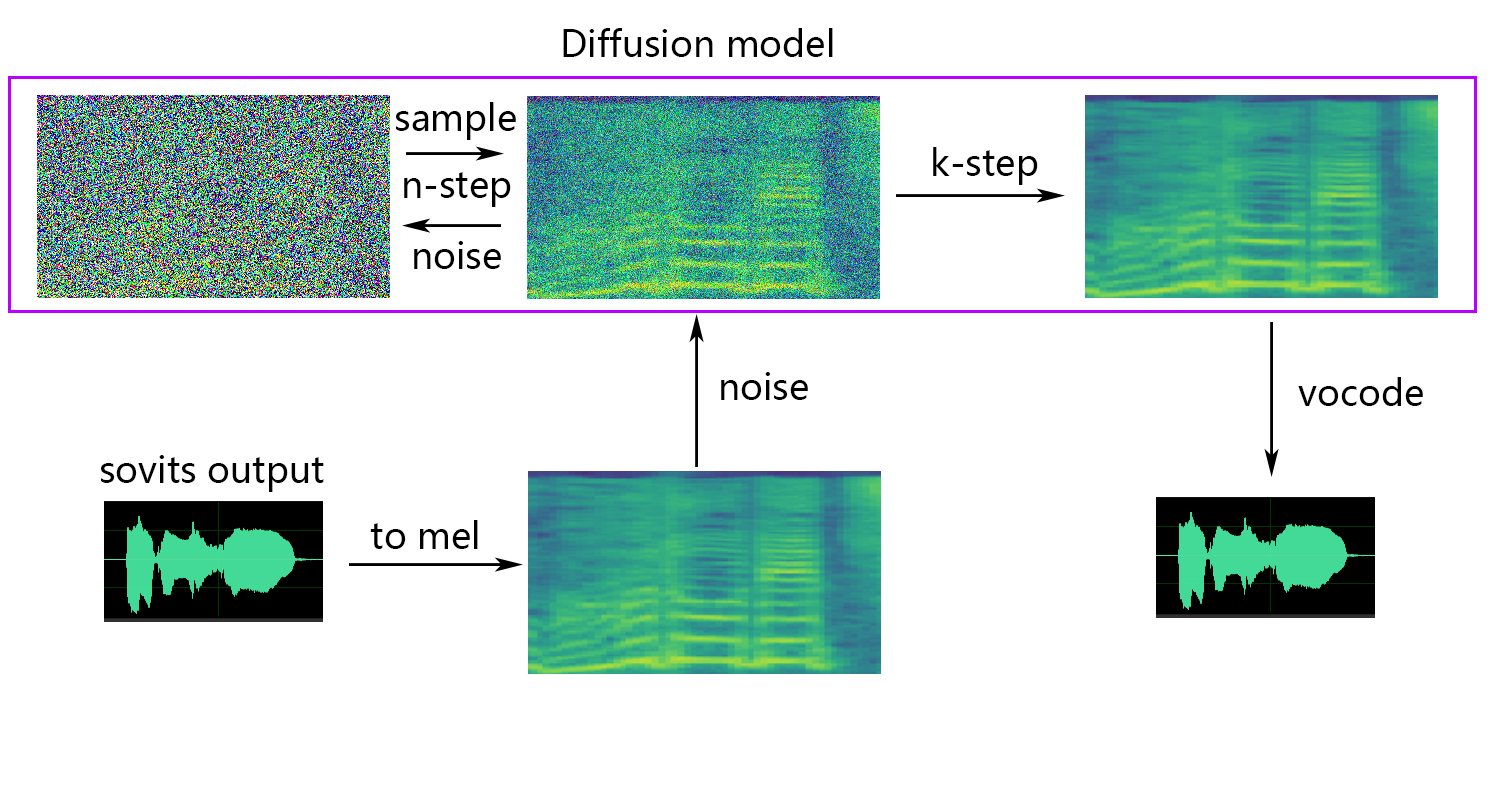
k_step_max : el entrenamiento solo puede entrenar la difusión del paso k_step_max para ahorrar tiempo de entrenamiento, tenga en cuenta que el valor debe ser menor que timesteps , 0 es entrenar todo el modelo de difusión, Nota: si no entrena todo el modelo de difusión solo_diffusion!
nsf-hifigan
nsf-snake-hifigan
python preprocess_hubert_f0.py --f0_predictor dioF0_Predictor tiene las siguientes opciones
crepe
dio
pm
harvest
rmvpe
fcpe
Si el conjunto de entrenamiento es demasiado ruidoso, se recomienda usar crepe para manejar F0
Si se omite el parámetro F0_Predictor, el valor predeterminado es rmvpe
Si desea difusión sin sentido (opcional), debe agregar el parámetro --use_diff , por ejemplo:
python preprocess_hubert_f0.py --f0_predictor dio --use_diffAcelerar el preprocesado
Si su conjunto de datos es bastante grande, puede aumentar el param --num_processes como ese:
python preprocess_hubert_f0.py --f0_predictor dio --num_processes 8Todo el trabajador será asignado a diferentes GPU si tiene más de una GPU.
Después de completar los pasos anteriores, el directorio del conjunto de datos contendrá los datos preprocesados, y la carpeta DataSET_RAW se puede eliminar.
python train.py -c configs/config.json -m 44kSi se necesita la función de difusión poco profunda, el modelo de difusión debe ser capacitado. El método de entrenamiento del modelo de difusión es el siguiente:
python train_diff.py -c configs/diffusion.yaml Durante la capacitación, los archivos del modelo se guardarán en logs/44k , y el modelo de difusión se guardará en logs/44k/diffusion
Use Inference_Main.py
# Example
python inference_main.py -m " logs/44k/G_30400.pth " -c " configs/config.json " -n "君の知らない物語-src.wav " -t 0 -s " nen "Parámetros requeridos:
-m | --model_path : ruta al modelo.-c | --config_path : ruta al archivo de configuración.-n | --clean_names : una lista de nombres de archivos WAV ubicados en la carpeta raw .-t | --trans : el cambio de tono, admite valores positivos y negativos (semitona).-s | --spk_list : seleccione la ID de altavoz para usar para la conversión.-cl | --clip : recorte de audio forzado, establecido en 0 para deshabilitar (predeterminado), configurarlo en un valor distinto de cero (duración en segundos) para habilitar.Parámetros opcionales: consulte la siguiente sección
-lg | --linear_gradient : la longitud de desvanecimiento cruzado de dos rodajas de audio en segundos. Si hay una voz discontinua después del corte forzado, puede ajustar este valor. De lo contrario, se recomienda utilizar el valor predeterminado de 0.-f0p | --f0_predictor : seleccione un predictor F0, las opciones son crepe , pm , dio , harvest , rmvpe , fcpe , el valor predeterminado es pm (nota: la agrupación media F0 se habilitará cuando se use crepe )-a | --auto_predict_f0 : Predicción automática de tono, no habilite esto al convertir las voces de canto, ya que puede causar serios problemas de tono.-cm | --cluster_model_path : modelo de clúster o ruta del índice de recuperación de características, si se deja en blanco, se establecerá automáticamente como la ruta predeterminada de estos modelos. Si no hay un grupo de entrenamiento o recuperación de características, complete a voluntad.-cr | --cluster_infer_ratio : la proporción de esquema de agrupación o recuperación de características varía de 0 a 1. Si no hay un modelo de agrupación de entrenamiento o recuperación de características, el valor predeterminado es 0.-eh | --enhance : si se debe usar NSF_Hifigan Enhancer, esta opción tiene cierto efecto en la mejora de la calidad del sonido para algunos modelos con pocos conjuntos de entrenamiento, pero tiene un efecto negativo en los modelos bien capacitados, por lo que está deshabilitado de forma predeterminada.-shd | --shallow_diffusion : si usar difusión superficial, que puede resolver algunos problemas de sonido eléctrico después de su uso. Esta opción está deshabilitada de forma predeterminada. Cuando esta opción está habilitada, NSF_HIFIGAN MOVERCER estará deshabilitado-usm | --use_spk_mix : si se debe usar Fusion Dynamic Voice-lea | --loudness_envelope_adjustment : el ajuste de la envoltura de volumen de la fuente de entrada en relación con la relación de fusión de la envoltura de volumen de salida. Cuanto más cerca de 1, más se usa el sobre de volumen de salida-fr | --feature_retrieval : si se debe usar la recuperación de características si se usa el modelo de agrupación, se deshabilitará, y los parámetros cm y cr se convertirán en la ruta del índice y la relación de mezcla de la recuperación de característicasConfiguración de difusión poco profunda:
-dm | --diffusion_model_path : ruta del modelo de difusión-dc | --diffusion_config_path : ruta del archivo de configuración de difusión-ks | --k_step : cuanto mayor sea el número de k_steps, más cerca estará al resultado del modelo de difusión. El valor predeterminado es 100-od | --only_diffusion : si usar solo el modo de difusión, que no carga el modelo Sovits para usar solo inferencia del modelo de difusión-se | --second_encoding : que implica aplicar una codificación adicional al audio original antes de la difusión superficial. Esta opción puede producir resultados variables, a veces positivos y a veces negativos. Si se infiere el uso de whisper-ppg Speech Coder, debe establecer --clip a 25 y -lg a 1. De lo contrario, no inferirá correctamente.
Si está satisfecho con los resultados anteriores, o si no siente que comprenda lo que sigue, puede omitirlo y no tendrá ningún efecto en el uso del modelo. El impacto de estas configuraciones opcionales mencionadas es relativamente pequeño, y aunque pueden tener algún impacto en conjuntos de datos específicos, en la mayoría de los casos la diferencia puede no ser significativa.
Durante el entrenamiento del modelo 4.0, un predictor F0 también está entrenado, lo que permite la predicción automática de tono durante la conversión de voz. Sin embargo, si los resultados no son satisfactorios, la predicción de tono manual se puede usar en su lugar. Tenga en cuenta que al convertir las voces de canto, se recomienda no habilitar esta característica, ya que puede causar un cambio significativo.
auto_predict_f0 en true en inference_main.py .Introducción: el esquema de agrupación implementado en este modelo tiene como objetivo reducir la fuga del timbre y mejorar la similitud del modelo entrenado al timbre del objetivo, aunque el efecto puede no ser muy pronunciado. Sin embargo, confiar únicamente en la agrupación puede reducir la claridad del modelo y hacer que suene menos distinto. Por lo tanto, se adopta un método de fusión en este modelo para controlar el equilibrio entre los enfoques de agrupación y no agrupación. Esto permite el ajuste manual de la compensación entre "sonar como el timbre del objetivo" y "tener una enunciación clara" para encontrar un equilibrio óptimo.
No se requieren cambios en los pasos existentes. Simplemente entrene un modelo de agrupación adicional, que incurre en costos de capacitación relativamente bajos.
python cluster/train_cluster.py . El modelo de salida se guardará en logs/44k/kmeans_10000.pt .python cluster/train_cluster.py --gpucluster_model_path en inference_main.py . Si no se especifica, el valor predeterminado es logs/44k/kmeans_10000.pt .cluster_infer_ratio en inference_main.py , donde 0 significa no usar la agrupación en absoluto, 1 significa solo usar agrupación, y generalmente 0.5 es suficiente.Introducción: al igual que con el esquema de agrupación, la fuga de timbre se puede reducir, la enunciación es ligeramente mejor que la agrupación, pero reducirá la velocidad de inferencia. Al emplear el método de fusión, es posible controlar linealmente el equilibrio entre la recuperación de características y la recuperación de no funciones, lo que permite ajustar la proporción deseada.
python train_index.py -c configs/config.json La salida del modelo estará en logs/44k/feature_and_index.pkl
--feature_retrieval debe formularse primero, y el modo de agrupación cambia automáticamente al modo de recuperación de características.cluster_model_path en inference_main.py . Si no se especifica, el valor predeterminado es logs/44k/feature_and_index.pkl .cluster_infer_ratio en inference_main.py , donde 0 significa no usar la recuperación de características, 1 significa solo usar la recuperación de características, y generalmente 0.5 es suficiente. El modelo generado contiene datos necesarios para una mayor capacitación. Si confirma que el modelo es final y no se usa en un entrenamiento adicional, es seguro eliminar estos datos para obtener un tamaño de archivo más pequeño (aproximadamente 1/3).
# Example
python compress_model.py -c= " configs/config.json " -i= " logs/44k/G_30400.pth " -o= " logs/44k/release.pth " Consulte el archivo webUI.py para ver la mezcla de timbre estable de la función Gadget/Lab.
Introducción: Esta función puede combinar múltiples modelos en un modelo (combinación convexa o combinación lineal de múltiples parámetros del modelo) para crear una voz mixta que no existe en la realidad
Nota:
model en config.json de todos los modelos a mixtos sean los mismos Consulte el archivo spkmix.py para obtener una introducción a la mezcla dinámica de timbre
Reglas de escritura de pista de mezcla de personajes:
ID de rol: [[Tiempo de inicio 1, Tiempo de finalización 1, Valor de inicio 1, Valor de inicio 1], [Tiempo de inicio 2, Tiempo de finalización 2, Valor de inicio 2]]
La hora de inicio debe ser la misma que la hora final del anterior. La primera hora de inicio debe ser 0, y la última hora de finalización debe ser 1 (el tiempo varía de 0 a 1).
Se deben completar todos los roles. Para roles no utilizados, llenar [[0., 1., 0., 0.]]
El valor de fusión se puede completar arbitrariamente, y el cambio lineal del valor de inicio al valor final dentro del período de tiempo especificado. El
La combinación lineal interna se garantizará automáticamente que sea 1 (condición de combinación convexa), por lo que se puede usar de manera segura de manera segura
Use el parámetro --use_spk_mix al razonar para habilitar la mezcla de timbre dinámico
Use onnx_export.py
checkpoints y ábrelocheckpoints como carpeta de su proyecto, nombrándola después de su proyecto, por ejemplo aziplayermodel.pth , el archivo de configuración como config.json , y colóquelos en la carpeta aziplayer que acaba de crear"NyaruTaffy" en path = "NyaruTaffy" en onnx_export.py a su nombre de proyecto, path = "aziplayer" (ONNX_EXPORT_SPEAKER_MIX ¿Puede mezclar la voz del altavoz)model.onnx en la carpeta de su proyecto, que es el modelo exportado.Nota: Para los modelos Hubert ONNX, utilice los modelos proporcionados por Moess. Actualmente, no se pueden exportar por su cuenta (Hubert en Fairseq tiene muchos operadores no compatibles y cosas que involucran constantes que pueden causar errores o dar problemas con la forma y los resultados de entrada/salida cuando se exportan).
| Url | Designación | Título | Fuente de implementación |
|---|---|---|---|
| 2106.06103 | Vits (sintetizador) | Autoencoder de variacional condicional con aprendizaje adversario para texto de extremo a extremo | jaywalnut310/vits |
| 2111.02392 | SoftVC (codificador del habla) | Una comparación de unidades de habla discretas y suaves para una conversión de voz mejorada | Bshall/Hubert |
| 2204.09224 | ContentVec (codificador del habla) | ContentVec: una mejor representación del habla auto-supervisada por altavoces desactivados | auspicious3000/contentvec |
| 2212.04356 | Whisper (codificador del discurso) | Reconocimiento de voz robusto a través de una supervisión débil a gran escala | OpenAi/susurro |
| 2110.13900 | WAVLM (codificador del habla) | WAVLM: pretruento auto-supervisado a gran escala para el procesamiento completo del habla de la pila | Microsoft/Unilm/Wavlm |
| 2305.17651 | Dphubert (codificador del habla) | Dphubert: destilación conjunta y poda de modelos de habla auto-supervisados | pyf98/dphubert |
| Doi: 10.21437/interspeech.2017-68 | Cosecha (predictor f0) | Cosecha: un estimador de frecuencia fundamental de alto rendimiento de las señales del habla | Mmorise/World/Harvest |
| AES35-000039 | Dio (predictor f0) | Método de estimación F0 rápido y confiable basado en la extracción del período de la vibración del plegamiento vocal de la voz del canto y el habla | mmorise/world/dio |
| 8461329 | Crepe (predictor f0) | CREPE: una representación convolucional para la estimación de tono | Maxrmorrison/Torchcrepe |
| Doi: 10.1016/j.wocn.2018.07.001 | Parselmouth (predictor f0) | Introducir a Parselmouth: una interfaz de Python para Praat | Yannickjadoul/Parselmouth |
| 2306.15412v2 | RMVPE (predictor F0) | RMVPE: un modelo robusto para la estimación de tono vocal en la música polifónica | Dream-High/Rmvpe |
| 2010.05646 | Hifigan (Vocoder) | Hifi-Gan: redes adversas generativas para la síntesis de habla eficiente y de alta fidelidad | jik876/hifi-gan |
| 1810.11946 | NSF (Vocoder) | Modelo de forma de onda basado en la fuente neuronal para la síntesis de discurso paramétrico estadístico | OpenVPI/Diffsinger/Modules/NSF_Hifigan |
| 2006.08195 | Serpiente (vocoder) | Las redes neuronales no aprenden funciones periódicas y cómo solucionarlo | Edwarddixon/serpiente |
| 2105.02446v3 | Difusión poco profunda (posprocesamiento) | Diffsinger: Síntesis de voz de canto a través del mecanismo de difusión poco profundo | CNCHTU/Difusión-SVC |
| K-medias | Funcionar K-Means Clustering (preprocesamiento) | Algunos métodos para la clasificación y análisis de observaciones multivariadas | Este repositorio |
| Recuperación de Topk de características (preprocesamiento) | Conversión de voz basada en la recuperación | Rvc-project/recuperación-voice-conversión-webui | |
| Whisper PPG | Whisper PPG | PlayVoice/Whisper_ppg | |
| bigvgan | bigvgan | PlayVoice/SO-VITS-SVC-5.0 |
Por alguna razón, el autor eliminó el repositorio original. Debido a la negligencia de los miembros de la organización, la lista de contribuyentes se eliminó porque todos los archivos se volvieron a cargar directamente a este repositorio al comienzo de la reconstrucción de este repositorio. Ahora agregue una lista de contribuyentes anterior a ReadMe.md.
Algunos miembros no han enumerado de acuerdo con sus deseos personales.
Misteo | Xiaomiku01 | しぐれ | Tomogasukunai | Plachtaa | ZD 小达 | 凍聲響世 |
任何组织或者个人不得以丑化、污损 , 或者利用信息技术手段伪造等方式侵害他人的肖像权。未经肖像权人同意 不得制作、使用、公开肖像权人的肖像 不得制作、使用、公开肖像权人的肖像 但是法律另有规定的除外。未经肖像权人同意 , 肖像作品权利人不得以发表、复制、发行、出租、展览等方式使用或者公开肖像权人的肖像。对自然人声音的保护 参照适用肖像权保护的有关规定。 参照适用肖像权保护的有关规定。
【名誉权】民事主体享有名誉权。任何组织或者个人不得以侮辱、诽谤等方式侵害他人的名誉权。
【作品侵害名誉权】行为人发表的文学、艺术作品以真人真事或者特定人为描述对象 , 含有侮辱、诽谤内容 侵害他人名誉权的 侵害他人名誉权的 受害人有权依法请求该行为人承担民事责任。行为人发表的文学、艺术作品不以特定人为描述对象 , 仅其中的情节与该特定人的情况相似的 不承担民事责任。 不承担民事责任。


