so vits svc
1.0.0
Английский |中文简体
Этот раунд обновления с ограниченным временем подходит к концу, склад войдет в состояние архива, пожалуйста, знайте
Студия, которая содержит видимый редактор F0, редактор сроков динамика и другие функции (где используются модели ONNX): Moevoicestudio
Вилка с значительно улучшенным пользовательским интерфейсом: 34J/SO-Vits-SVC-Fork
Клиент поддерживает конверсию в реальном времени: W-Okada/Voice-Cranger
Этот проект принципиально отличается от VIT, поскольку он фокусируется на преобразовании голоса (SVC), а не на рече (TTS). В этом проекте функциональность TTS не поддерживается, и VIT не способны выполнять задачи SVC. Важно отметить, что модели, используемые в этих двух проектах, не являются взаимозаменяемыми или универсально применимыми.
Цель этого проекта состояла в том, чтобы позволить разработчикам, чтобы их любимые аниме -персонажи выполняли певческие задачи. Намерение разработчиков состояло в том, чтобы сосредоточиться исключительно на вымышленных персонажах и избежать любого участия реальных людей, все, что связано с реальными людьми, отличается от первоначального намерения разработчика.
Этот проект представляет собой открытый, автономный усилитель, и все члены Svcdevelopteam, а также другие разработчики и сопровождающие (далее называемый участниками) не контролируют проект. Авторы никогда не оказывали никакой формы помощи какой -либо организации или физическим лицам, включая, помимо прочего, извлечение наборов данных, обработку наборов данных, поддержку вычислительной поддержки, поддержку обучения, вывод и так далее. Авторы не знают и не могут знать о целях, для которых пользователи используют проект. Таким образом, любые модели ИИ и синтезированный звук, произведенный посредством обучения этого проекта, не связаны с участниками. Любые вопросы или последствия, возникающие в результате их использования, являются единственной ответственностью пользователя.
Этот проект запускается полностью в автономном режиме и не собирает никакой пользовательской информации и не собирает пользовательские входные данные. Следовательно, участники этого проекта не знают обо всех пользовательских вводах и моделях и, следовательно, не несут ответственности за какой -либо пользовательский ввод.
Этот проект служит только структурой и сама по себе не обладает функциональностью синтеза речи. Все функциональные возможности требуют, чтобы пользователи могли самостоятельно обучать модели. Кроме того, этот проект не связан с какими -либо моделями, и любые вторичные распределенные проекты не зависят от участников этого проекта.
Модель преобразования по пению использует энкодер содержимого содержимого для извлечения речевых функций из исходного аудио. Эти векторы функций напрямую подаются в VIT без необходимости преобразования в текстовое промежуточное представление. В результате сохраняются высота и интонации оригинального звука. Между тем, вокадер был заменен NSF Hifigan, чтобы решить проблему прерывания звука.
config.json . Добавьте поле speech_encoder в раздел «Модель», как показано ниже: "model": {
.........
"ssl_dim": 256,
"n_speakers": 200,
"speech_encoder":"vec256l9"
}
Основываясь на нашем тестировании, мы определили, что проект работает стабильно на Python 3.8.9 .
Вам нужно выбрать один энкодер из списка ниже
vec768l12 и vec256l9 требуют энкодера
pretrainИли загрузите следующий ContentVec, который имеет размер всего 199 МБ, но имеет такой же эффект:
checkpoint_best_legacy_500.pt и поместите его в каталог pretrain # contentvec
wget -P pretrain/ https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/hubert_base.pt -O checkpoint_best_legacy_500.pt
# Alternatively, you can manually download and place it in the hubert directory pretrain whisper-ppgwhisper-ppg-largepretrain pretrain pretrain wavlmbase+pretrain pretrain Предварительно обученные файлы модели: G_0.pth D_0.pth
logs/44k Диффузионная модель предварительная базовая модель Файл модели: model_0.pt
logs/44k/diffusionПолучите предварительную модель Sovits от SVC-Develop-Team (TBD) или где-либо еще.
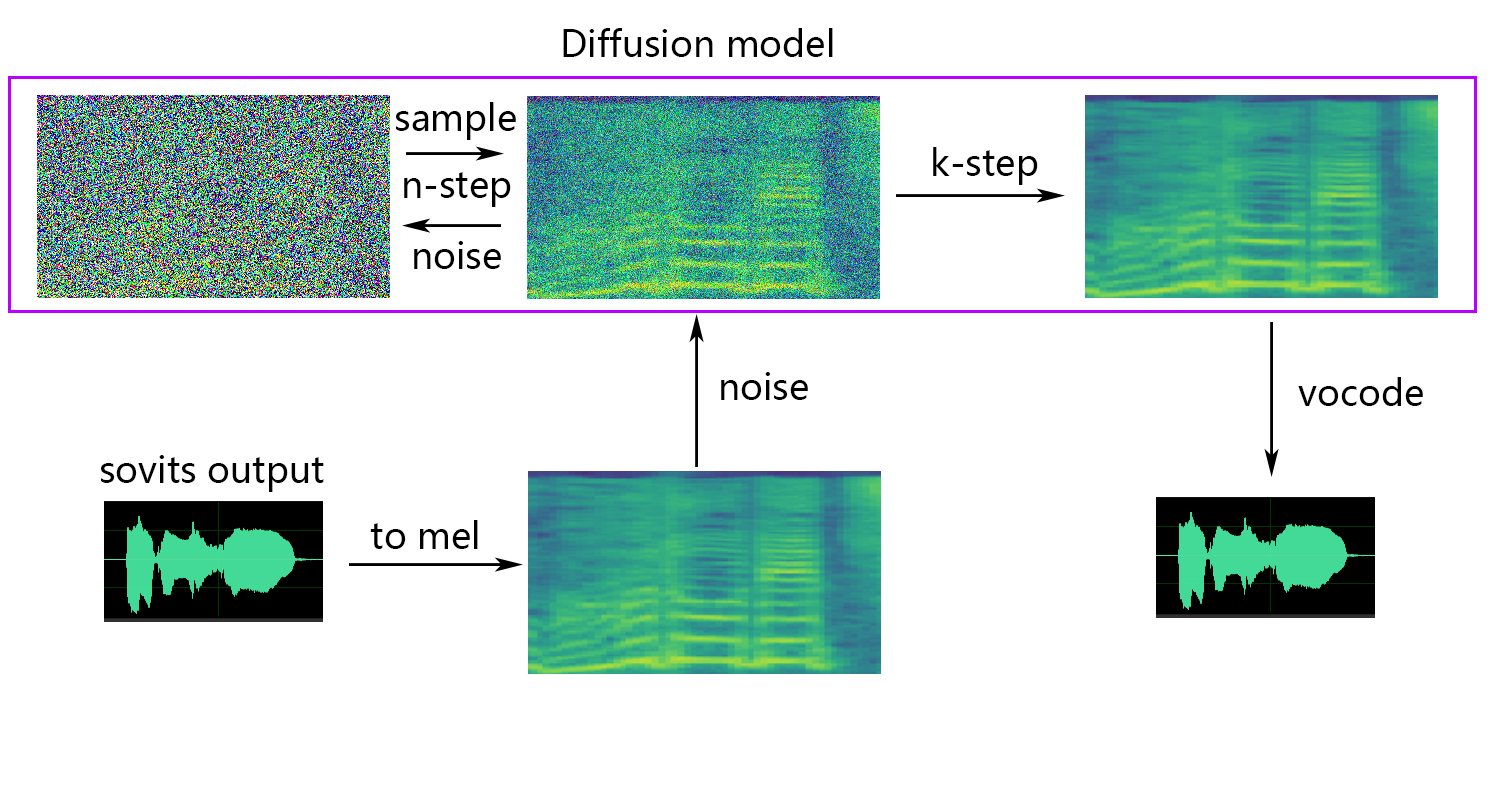
Диффузионная модель ссылок диффузионной диффузионной модели SVC. Предварительно обученная диффузионная модель универсальна с DDSP-SVC. Вы можете перейти в репо диффузион-SVC, чтобы получить предварительно обученную диффузионную модель.
В то время как предварительно подготовленная модель, как правило, не ставит за проблемы с авторским правом, важно оставаться бдительным. Желательно проконсультироваться с автором заранее или тщательно просмотреть описание, чтобы выяснить допустимое использование модели. Это помогает обеспечить соблюдение любых указанных руководящих принципов или ограничений, касающихся его использования.
Если вы используете NSF-HIFIGAN enhancer или shallow diffusion , вам нужно будет загрузить предварительно обученную модель NSF-Hifigan.
pretrain/nsf_hifigan # nsf_hifigan
wget -P pretrain/ https://github.com/openvpi/vocoders/releases/download/nsf-hifigan-v1/nsf_hifigan_20221211.zip
unzip -od pretrain/nsf_hifigan pretrain/nsf_hifigan_20221211.zip
# Alternatively, you can manually download and place it in the pretrain/nsf_hifigan directory
# URL: https://github.com/openvpi/vocoders/releases/tag/nsf-hifigan-v1 Если вы используете предиктор rmvpe F0, вам нужно будет загрузить предварительно обученную модель RMVPE.
rmvpe.zip , и переименовать файл model.pt в rmvpe.pt и поместите его в каталог pretrain .pretrain FCPE (Fast Context-Base Pitch Ortant) является выделенным предиктором F0, предназначенным для преобразования голоса в реальном времени, и станет предпочтительным предиктором F0 для преобразования голоса в реальном времени в реальном времени (статья написана).
Если вы используете предиктор fcpe F0, вам нужно будет загрузить предварительно обученную модель FCPE.
pretrain Просто поместите набор данных в каталог dataset_raw со следующей структурой файла:
dataset_raw
├───speaker0
│ ├───xxx1-xxx1.wav
│ ├───...
│ └───Lxx-0xx8.wav
└───speaker1
├───xx2-0xxx2.wav
├───...
└───xxx7-xxx007.wav
Не существует конкретных ограничений на формат имени для каждого аудиофайла (соглашения именования, такие как 000001.wav до 999999.wav , также действительны), но тип файла должен быть `Wav``.
Вы можете настроить имя динамика, как показано ниже:
dataset_raw
└───suijiSUI
├───1.wav
├───...
└───25788785-20221210-200143-856_01_(Vocals)_0_0.wav
Чтобы избежать переполнения видео памяти во время обучения или предварительной обработки, рекомендуется ограничить длину аудиоклипов. Резать звук до длины «5S - 15S» более рекомендуется. Немного больше времени приемлемо, однако, чрезмерно длинные клипы могут вызвать такие проблемы, как torch.cuda.OutOfMemoryError .
Чтобы облегчить процесс нарезки, вы можете использовать Audio-Slicer-Gui или Audio-Slicer-Cli
В общем, только Minimum Interval должен быть скорректирован. Для разговорного звука, как правило, достаточного значения по умолчанию, в то время как для пения аудио, его можно скорректировать примерно до 100 или даже 50 , в зависимости от конкретных требований.
После нарезки рекомендуется удалить любые аудио -зажимы, которые чрезмерно длинные или слишком короткие.
Если вы используете энкодер Whisper-PPG для обучения, аудиоклипы должны короче 30-х годов.
python resample.py Хотя этот проект имеет сценарии Resample.py для повторной выборки, моно и громкости, сопоставление громкости по умолчанию состоит в том, чтобы соответствовать 0DB. Это может нанести ущерб качеству звука. В то время как пакет сопоставления громкости Python Pyloudnorm не ограничивает уровень, это может привести к звуковому буму. Поэтому рекомендуется рассмотреть возможность использования профессионального программного обеспечения для обработки звука, например, adobe audition для сопоставления громкости. Если вы уже используете другое программное обеспечение для сопоставления громкости, добавьте параметр -skip_loudnorm в команду Run:
python resample.py --skip_loudnormpython preprocess_flist_config.py --speech_encoder vec768l12spirt_encoder имеет следующие варианты
vec768l12
vec256l9
hubertsoft
whisper-ppg
cnhubertlarge
dphubert
whisper-ppg-large
wavlmbase+
Если аргумент speek_encoder опущен, значение по умолчанию - vec768l12
Используйте громкость
Добавить --vol_aug если вы хотите включить встраивание громкости:
python preprocess_flist_config.py --speech_encoder vec768l12 --vol_augПосле включения громкости встраивалось, обученная модель будет соответствовать громкости источника ввода; В противном случае это будет соответствовать громкости тренировочного набора.
keep_ckpts : сохраните количество предыдущих моделей во время обучения. Установите 0 чтобы сохранить их всех. По умолчанию 3 .
all_in_mem : загрузить весь набор данных в ОЗУ. Он может быть включен, когда диск в iO некоторых платформ слишком низкий, а системная память намного больше , чем ваш набор данных.
batch_size : объем данных, загруженных в GPU для одного учебного сеанса, может быть скорректирован до размера ниже, чем емкость памяти графического процессора.
vocoder_name : выберите Vocoder. По умолчанию nsf-hifigan .
cache_all_data : загрузить весь набор данных в ОЗУ. Он может быть включен, когда диск в iO некоторых платформ слишком низкий, а системная память намного больше , чем ваш набор данных.
duration : продолжительность нарезки аудио во время обучения может быть скорректирована в соответствии с размером видео памяти, примечание: это значение должно быть меньше, чем минимальное время аудио в учебном наборе!
batch_size : объем данных, загруженных в GPU для одного учебного сеанса, может быть скорректирован до размера ниже, чем емкость видео памяти.
timesteps : общее количество шагов в диффузионной модели, которые по умолчанию по умолчанию до 1000.
k_step_max : Обучение может обучать только диффузию шага k_step_max для сохранения времени обучения, обратите внимание, что значение должно быть меньше, чем timesteps , 0 - это тренировка всей диффузионной модели, примечание: если вы не тренируете всю диффузионную модель. только_диффузия!
nsf-hifigan
nsf-snake-hifigan
python preprocess_hubert_f0.py --f0_predictor diof0_predictor имеет следующие варианты
crepe
dio
pm
harvest
rmvpe
fcpe
Если учебный набор слишком шумный, рекомендуется использовать crepe для обработки F0
Если параметр f0_predictor опущен, значение по умолчанию равно rmvpe
Если вы хотите мелкую диффузию (необязательно), вам необходимо добавить параметр -например, параметр --use_diff :
python preprocess_hubert_f0.py --f0_predictor dio --use_diffУскорить преприцесс
Если ваш набор данных довольно большой, вы можете увеличить такую Param --num_processes :
python preprocess_hubert_f0.py --f0_predictor dio --num_processes 8Весь работник будет назначен на другой графический процессор, если у вас есть более одного графического процессора.
После завершения вышеуказанных шагов в каталоге набора данных будет содержать предварительно обработанные данные, а папка DateSet_Raw может быть удалена.
python train.py -c configs/config.json -m 44kЕсли необходима неглубокая диффузионная функция, необходимо обучить диффузионную модель. Метод обучения диффузионной модели заключается в следующем:
python train_diff.py -c configs/diffusion.yaml Во время обучения файлы модели будут сохранены в logs/44k , а диффузионная модель будет сохранена в logs/44k/diffusion
Используйте sepence_main.py
# Example
python inference_main.py -m " logs/44k/G_30400.pth " -c " configs/config.json " -n "君の知らない物語-src.wav " -t 0 -s " nen "Требуемые параметры:
-m | --model_path : путь к модели.-c | --config_path : Путь к файлу конфигурации.-n | --clean_names : список имен файлов wav, расположенных в папке raw .-t | --trans : сдвиг шага, поддерживает положительные и отрицательные (полутоновые) значения.-s | --spk_list : выберите идентификатор динамика для использования для преобразования.-cl | --clip : принудительное вырезка звука, установите на 0, чтобы отключить (по умолчанию), установив его на ненулевое значение (продолжительность за считанные секунды) для включения.Дополнительные параметры: см. Следующий раздел
-lg | --linear_gradient : длина поперечного исчезновения двух аудиосексовки за секунды. Если есть прерывистый голос после принудительного разрезания, вы можете настроить это значение. В противном случае рекомендуется использовать значение по умолчанию 0.-f0p | --f0_predictor : выберите предиктор F0, параметры- crepe , pm , dio , harvest , rmvpe , fcpe , значение по умолчанию pm (примечание: среднее объединение F0 будет включено при использовании crepe )-a | --auto_predict_f0 : автоматическое прогнозирование высоты тона, не включайте это при преобразовании поющих голосов, поскольку это может вызвать серьезные проблемы с высокой высоты.-cm | --cluster_model_path : модель кластера или путь индекса поиска функций, если его оставить пустым, он будет автоматически устанавливать как путь по умолчанию этих моделей. Если нет учебного кластера или поиска функций, заполните по желанию.-cr | --cluster_infer_ratio : доля схемы кластеризации или поиска функций находится в диапазоне от 0 до 1. Если нет учебной модели кластеризации или поиска функций, по умолчанию 0.-eh | --enhance : использовать ли NSF_HIFIGAN Enhancer, этот вариант оказывает определенное влияние на улучшение качества звука для некоторых моделей с небольшим количеством обучающих наборов, но оказывает негативное влияние на хорошо обученные модели, поэтому он отключен по умолчанию.-shd | --shallow_diffusion : использовать ли неглубокую диффузию, которая может решить некоторые проблемы с электрическим звуком после использования. Эта опция отключена по умолчанию. Когда эта опция включена, NSF_HIFIGAN ENHANCER будет отключен-usm | --use_spk_mix : использовать ли динамическое голосовое слияние-lea | --loudness_envelope_adjustment : Регулировка конверта громкости источника входного источника по отношению к соотношению слияния выходной громкости. Чем ближе к 1, тем больше используется конверт выходной громкости-fr | --feature_retrieval : использовать ли поиск функций, если используется модель кластеризации, она будет отключена, а параметры cm и cr станут путем индекса и соотношение смешивания поиска функцийНастройки мелкой диффузии:
-dm | --diffusion_model_path : путь диффузионной модели-dc | --diffusion_config_path : путь файла конфигурации диффузии-ks | --k_step : чем больше количество k_steps, тем ближе он к результату диффузионной модели. По умолчанию 100-od | --only_diffusion : использовать только режим диффузии, который не загружает модель Sovits, чтобы использовать только вывод модели диффузии-se | --second_encoding : который включает в себя применение дополнительного кодирования к исходному аудио перед мелкой диффузией. Этот вариант может дать различные результаты - иногда положительные, а иногда и отрицательные. Если вывод с использованием речевого энкодера whisper-ppg вам необходимо установить --clip до 25 и -lg до 1. В противном случае он не выведет должным образом.
Если вы довольны предыдущими результатами, или если вы не чувствуете, что понимаете, что следует, вы можете пропустить его, и это не повлияет на использование модели. Влияние этих дополнительных упомянутых настроек относительно невелико, и, хотя они могут оказать некоторое влияние на конкретные наборы данных, в большинстве случаев разница может быть не значительной.
Во время обучения модели 4.0 также обучается предиктор F0, который позволяет автоматическому прогнозированию шага во время преобразования голоса. Однако, если результаты не являются удовлетворительными, вместо этого можно использовать прогноз ручного тона. Обратите внимание, что при преобразовании поющих голосов рекомендуется не включать эту функцию, поскольку она может привести к значительному изменению высоты тона.
auto_predict_f0 в true in inference_main.py .Введение: Схема кластеризации, реализованная в этой модели, направлена на снижение утечки тембр и повышение сходства обученной модели с тембром цели, хотя эффект может быть не очень выраженным. Тем не менее, полагаться исключительно на кластеризацию может снизить ясность модели и сделать ее менее отчетливой. Следовательно, в этой модели принимается метод слияния для контроля баланса между подходами кластеризации и не кластеризации. Это позволяет ручной корректировке компромисса между «звучанием как тембр цели» и «иметь четкое изложение», чтобы найти оптимальный баланс.
На существующих шагах не требуется изменений. Просто тренируйте дополнительную модель кластеризации, которая полагает относительно низкие затраты на обучение.
python cluster/train_cluster.py . Выходная модель будет сохранена в logs/44k/kmeans_10000.pt .python cluster/train_cluster.py --gpucluster_model_path in inference_main.py . Если не указано, по умолчанию есть logs/44k/kmeans_10000.pt .cluster_infer_ratio in inference_main.py , где 0 означает, что вообще не использует кластеризацию, 1 означает только использование кластеризации, и обычно достаточное 0.5 .ВВЕДЕНИЕ: Как и в случае схемы кластеризации, утечка тембра может быть уменьшена, произведение немного лучше, чем кластеризация, но это снизит скорость вывода. Используя метод слияния, становится возможным линейно контролировать баланс между поиском объекта и поиском нефтепризы, что позволяет точно настраивать желаемую пропорцию.
python train_index.py -c configs/config.json Вывод модели будет в logs/44k/feature_and_index.pkl
--feature_retrieval , а режим кластеризации автоматически переключается на режим поиска функций.cluster_model_path in inference_main.py . Если не указано, по умолчанию есть logs/44k/feature_and_index.pkl .cluster_infer_ratio in inference_main.py , где 0 означает, что вообще не использует поиск функций, 1 означает только использование поиска функций, и обычно достаточное 0.5 . Сгенерированная модель содержит данные, которые необходимы для дальнейшего обучения. Если вы подтвердите, что модель является окончательной и не используется при дальнейшем обучении, безопасно удалить эти данные, чтобы получить меньший размер файла (около 1/3).
# Example
python compress_model.py -c= " configs/config.json " -i= " logs/44k/G_30400.pth " -o= " logs/44k/release.pth " Обратитесь к файлу webUI.py для стабильного микширования тембре гаджета/лаборатории.
Введение: эта функция может объединить несколько моделей в одну модель (выпуклое комбинация или линейная комбинация нескольких параметров модели) для создания смешанного голоса, который не существует в реальности
Примечание:
model полей в config.json из всех моделей, которые будут смешаны, одинаковы Обратитесь к файлу spkmix.py для введения в динамическое микширование Timbre
Правила написания дорожного движения персонажей:
Идентификатор роли: [[время начала 1, время окончания 1, начальное значение 1, начальное значение 1], [время начала 2, время окончания 2, начальное значение 2]]
Время начала должно быть таким же, как и время окончания предыдущего. Первое время начала должно быть 0, а последнее время окончания должно быть 1 (время составляет от 0 до 1).
Все роли должны быть заполнены. Для неиспользованных ролей заполните [[0., 1., 0., 0.]]
Значение слияния может быть заполнено произвольно, а линейное изменение от начального значения до конечного значения в течение указанного периода времени. А
Внутренняя линейная комбинация будет автоматически гарантированно будет 1 (выпуклое условие комбинации), поэтому ее можно безопасно использовать
Используйте параметр --use_spk_mix рассуждении, чтобы включить динамическое смешивание Timbre Paramer
Используйте onnx_export.py
checkpoints и откройте ееcheckpoints в качестве папки проекта, назвав ее после вашего проекта, например, aziplayermodel.pth , файл конфигурации как config.json , и поместите их в только только что созданный папку aziplayer"NyaruTaffy" в path = "NyaruTaffy" в onnx_export.py на имя вашего проекта, path = "aziplayer" (Onnx_export_speaker_mix заставляет вас смешать голос динамика)model.onnx будет генерироваться в папке проекта, которая является экспортированной моделью.Примечание. Для моделей Hubert Onnx, пожалуйста, используйте модели, предоставленные Moess. В настоящее время они не могут быть экспортированы сами по себе (у Хуберта в Fairseq есть много неподдерживаемых операторов и вещей, связанных с константами, которые могут вызвать ошибки или привести к проблемам с формой ввода/вывода и приведены при экспорте.)
| URL | Обозначение | Заголовок | Источник реализации |
|---|---|---|---|
| 2106.06103 | Vits (синтезатор) | Условный вариационный автоэкодер с состязательным обучением для сквозного текста в речь | jaywalnut310/vits |
| 2111.02392 | Softvc (речевой энкодер) | Сравнение дискретных и мягких речевых единиц для улучшения преобразования голоса | Bshall/Hubert |
| 2204.09224 | ContentVec (речевой энкодер) | ContentVec: улучшенное самоотверженное речевое представление с помощью ораторов распутывания | ABSPICOIL3000/ContentVec |
| 2212.04356 | Шепот (речевой энкодер) | Надежное распознавание речи посредством крупномасштабного слабого надзора | Openai/Whisper |
| 2110.13900 | Wavlm (речевой энкодер) | Wavlm: крупномасштабное самоотверженное предварительное обучение для полной обработки речи. | Microsoft/Unilm/Wavlm |
| 2305.17651 | Dphubert (речевой энкодер) | Dphubert: суставная дистилляция и обрезка самоотверженных речевых моделей | PYF98/Dphubert |
| Doi: 10.21437/Interspeech.2017-68 | Урожай (предиктор F0) | Урожай: высокопроизводительная оценка фундаментальной частоты из речевых сигналов | Mmorise/World/Harvest |
| AES35-000039 | Dio (F0 Predictor) | Быстрый и надежный метод оценки F0 на основе периода извлечения вибрации вокальной складки пения голоса и речи | Mmorise/World/Dio |
| 8461329 | Креп (предиктор F0) | Креп: сверточное представление для оценки высоты тона | maxrmorrison/touchcrepe |
| Doi: 10.1016/j.wocn.2018.07.001 | Парсельмут (предиктор F0) | Представляем Parselmouth: интерфейс Python To Praat | Янникджадул/Парсельмут |
| 2306.15412V2 | RMVPE (предиктор F0) | RMVPE: надежная модель оценки вокала в полифонической музыке | Сон-высокий/rmvpe |
| 2010.05646 | Hifigan (Vocoder) | Hifi-Gan: Генеративные состязательные сети для эффективного и высокой верности речи | Jik876/Hifi-Gan |
| 1810.11946 | NSF (Vocoder) | Модель сигнала на основе нейронных источников для статистической параметрической речи Синтез речи | openvpi/diffsinger/modules/nsf_hifigan |
| 2006.08195 | Змея (вокадер) | Нейронные сети не могут изучать периодические функции и как их исправить | Эдварддиксон/змея |
| 2105.02446V3 | Мелкая диффузия (постобработка) | Diffsinger: петь голосовой синтез с помощью механизма мелкого диффузии | CNCHTU/Diffusion-SVC |
| K-Means | Особенность кластеризации K-средних (предварительная обработка) | Некоторые методы классификации и анализа многомерных наблюдений | Это репо |
| Функция поиска Topk (предварительная обработка) | Преобразование голоса на основе поиска | RVC-проект/поиск на основе Voice-Conversion-Webui | |
| Шепот PPG | Шепот PPG | Playvoice/Whisper_ppg | |
| Бигвган | Бигвган | Playvoice/So-Vits-SVC-5.0 |
По какой -то причине автор удалил первоначальный репозиторий. Из -за небрежности членов организации список участников был очищен, потому что все файлы были непосредственно загружены в этот репозиторий в начале реконструкции этого хранилища. Теперь добавьте предыдущий список участников в readme.md.
Некоторые участники не перечислены в соответствии с их личными пожеланиями.
Мистио | Xiaomiku01 | しぐれ | Томогасукунай | Плахтаа | zd 小达 | 凍聲響世 |
任何组织或者个人不得以丑化、污损 , 或者利用信息技术手段伪造等方式侵害他人的肖像权。未经肖像权人同意 不得制作、使用、公开肖像权人的肖像 , 但是法律另有规定的除外。未经肖像权人同意 , 肖像作品权利人不得以发表、复制、发行、出租、展览等方式使用或者公开肖像权人的肖像。对自然人声音的保护 参照适用肖像权保护的有关规定。
【名誉权】民事主体享有名誉权。任何组织或者个人不得以侮辱、诽谤等方式侵害他人的名誉权。
【作品侵害名誉权】行为人发表的文学、艺术作品以真人真事或者特定人为描述对象 , 含有侮辱、诽谤内容 侵害他人名誉权的 , 受害人有权依法请求该行为人承担民事责任。行为人发表的文学、艺术作品不以特定人为描述对象 , 仅其中的情节与该特定人的情况相似的 不承担民事责任。


