so vits svc
1.0.0
英语|中文简体
这一轮限时更新即将结束,仓库将进入拱门状态,请知道
一个包含可见F0编辑器,扬声器混音时间表编辑器和其他功能的工作室(使用ONNX型号):MoevoiceStudio
具有大大改进的用户界面的叉子:34J/so-vits-svc-fork
客户支持实时转换:W-OKADA/语音改变者
该项目从根本上与VIT不同,因为它专注于唱歌语音转换(SVC),而不是文本到语音(TTS)。在此项目中,不支持TTS功能,VIT无法执行SVC任务。重要的是要注意,这两个项目中使用的模型不可互换或普遍适用。
该项目的目的是使开发人员能够让他们心爱的动漫角色执行歌唱任务。开发商的意图是只专注于虚构的角色,避免真正的个人参与,与真实个人有关的任何事物都偏离了开发人员的最初意图。
该项目是一个开源,离线努力,以及SVCDevelopteam的所有成员,以及其他所涉及的开发人员和维护者(以下称为贡献者),对该项目没有控制权。贡献者从未向任何组织或个人提供任何形式的帮助,包括但不限于数据集提取,数据集处理,计算支持,培训支持,推理等。贡献者没有也不能意识到用户使用该项目的目的。因此,通过该项目训练产生的任何AI模型和合成的音频都与贡献者无关。用户使用的任何问题或后果都是用户的全部责任。
该项目完全离线运行,不会收集任何用户信息或收集用户输入数据。因此,该项目的贡献者并不了解所有用户输入和模型,因此对任何用户输入概不负责。
该项目仅作为框架,并且不具有语音合成功能。所有功能都要求用户独立训练模型。此外,该项目并未与任何模型捆绑在一起,任何二级分布式项目都与该项目的贡献者无关。
Singing语音转换模型使用SOFTVC内容编码器从源音频中提取语音功能。这些特征向量直接被馈入VIT,而无需转换为基于文本的中间表示。结果,保留了原始音频的音高和音调。同时,Vocoder被NSF Hifigan取代,以解决声音中断的问题。
config.json文件进行修改。如下所示,将speech_encoder字段添加到“模型”部分: "model": {
.........
"ssl_dim": 256,
"n_speakers": 200,
"speech_encoder":"vec256l9"
}
根据我们的测试,我们确定该项目在Python 3.8.9上运行稳定。
您需要从下面的列表中选择一个编码器
vec768l12和vec256l9需要编码器
pretrain目录下或下载以下contentvec,大小仅为199MB,但效果相同:
checkpoint_best_legacy_500.pt并将其放在pretrain目录中 # contentvec
wget -P pretrain/ https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/hubert_base.pt -O checkpoint_best_legacy_500.pt
# Alternatively, you can manually download and place it in the hubert directory pretrain目录下whisper-ppgwhisper-ppg-largepretrain目录下pretrain目录下pretrain目录下wavlmbase+pretrain目录下pretrain目录下预训练的模型文件: G_0.pth D_0.pth
logs/44k目录下扩散模型预处理基本模型文件: model_0.pt
logs/44k/diffusion目录中从SVC-developem-Team(TBD)或其他任何地方获取Sovits预训练的模型。
扩散模型参考扩散-SVC扩散模型。预先训练的扩散模型与DDSP-SVC是通用的。您可以转到扩散-SVC的存储库以获取预训练的扩散模型。
虽然验证的模型通常不会引起版权问题,但保持警惕至关重要。建议事先与作者咨询或仔细查看描述,以确定模型的允许用法。这有助于确保遵守有关其利用的任何指定准则或限制。
如果您使用的是NSF-HIFIGAN enhancer或shallow diffusion ,则需要下载预训练的NSF-Hifigan模型。
pretrain/nsf_hifigan目录下 # nsf_hifigan
wget -P pretrain/ https://github.com/openvpi/vocoders/releases/download/nsf-hifigan-v1/nsf_hifigan_20221211.zip
unzip -od pretrain/nsf_hifigan pretrain/nsf_hifigan_20221211.zip
# Alternatively, you can manually download and place it in the pretrain/nsf_hifigan directory
# URL: https://github.com/openvpi/vocoders/releases/tag/nsf-hifigan-v1 如果您使用的是rmvpe F0预测器,则需要下载预训练的RMVPE模型。
rmvpe.zip pretrain并将model.pt rmvpe.ptpretrain目录下FCPE(快速上下文基量估计器)是一个专门的F0预测器,专为实时语音转换而设计,并将成为未来Sovits实时语音转换的首选F0预测指标。(正在撰写论文)
如果您使用的是fcpe F0预测器,则需要下载预训练的FCPE模型。
pretrain目录下只需将数据集放在dataset_raw目录中,并具有以下文件结构:
dataset_raw
├───speaker0
│ ├───xxx1-xxx1.wav
│ ├───...
│ └───Lxx-0xx8.wav
└───speaker1
├───xx2-0xxx2.wav
├───...
└───xxx7-xxx007.wav
每个音频文件的名称格式没有特定的限制(命名惯例,例如000001.wav至999999.wav也有效),但是文件类型必须为``wav''。
您可以自定义扬声器的名称,如下所示:
dataset_raw
└───suijiSUI
├───1.wav
├───...
└───25788785-20221210-200143-856_01_(Vocals)_0_0.wav
为了避免在训练或预处理过程中进行视频记忆溢出,建议限制音频剪辑的长度。建议将音频切成“ 5s -15s”的长度。但是,稍长的时间是可以接受的,但是,剪辑过长可能会引起诸如torch.cuda.OutOfMemoryError之类的问题。
为了促进切片过程,您可以使用音频 - 缝合器或音频式CLI
通常,只需要调整Minimum Interval 。对于口语音频,默认值通常就足够了,而对于唱歌音频,可以根据特定要求将其调整为100甚至50 。
切片后,建议删除任何过长或太短的音频剪辑。
如果您使用Whisper-PPG编码器进行培训,则音频剪辑必须短于30s。
python resample.py尽管此项目具有重新采样脚本。这可能会损害音质。虽然Python的响度匹配包pylodnorm并没有限制水平,但这可能导致声音繁荣。因此,建议考虑使用专业的声音处理软件,例如adobe audition进行响度匹配。如果您已经在使用其他软件进行响度匹配,请将参数-skip_loudnorm添加到运行命令:
python resample.py --skip_loudnormpython preprocess_flist_config.py --speech_encoder vec768l12secement_encoder有以下选项
vec768l12
vec256l9
hubertsoft
whisper-ppg
cnhubertlarge
dphubert
whisper-ppg-large
wavlmbase+
如果省略了specy_encoder参数,则默认值为vec768l12
使用响度嵌入
添加--vol_aug如果要启用响度嵌入:
python preprocess_flist_config.py --speech_encoder vec768l12 --vol_aug启用响度嵌入后,训练有素的模型将与输入源的响度相匹配。否则,它将与训练集的响度相匹配。
keep_ckpts :在训练过程中保留先前型号的数量。设置为0以保持全部。默认值为3 。
all_in_mem :将所有数据集加载到RAM。当某些平台的磁盘IO太低并且系统内存比数据集大得多时,可以启用它。
batch_size :单个培训会话加载到GPU的数据量可以调整到小于GPU内存容量的大小。
vocoder_name :选择一个vocoder。默认值为nsf-hifigan 。
cache_all_data :将所有数据集加载到RAM。当某些平台的磁盘IO太低并且系统内存比数据集大得多时,可以启用它。
duration :可以根据视频记忆的大小来调整训练期间音频切片的持续时间,请注意:此值必须小于训练集中音频的最小时间!
batch_size :单个培训会话加载到GPU的数据量可以调整到低于视频记忆容量的大小。
timesteps :扩散模型中的步骤总数,默认为1000。
k_step_max :训练只能训练k_step_max步骤扩散以节省训练时间,请注意,该值必须小于timesteps ,0是训练整个扩散模型,请注意:如果不训练整个扩散模型,则无法使用唯一的_ -Diffusion!
nsf-hifigan
nsf-snake-hifigan
python preprocess_hubert_f0.py --f0_predictor dioF0_predictor具有以下选项
crepe
dio
pm
harvest
rmvpe
fcpe
如果训练集太嘈杂,建议使用crepe处理F0
如果省略了f0_predictor参数,则默认值为rmvpe
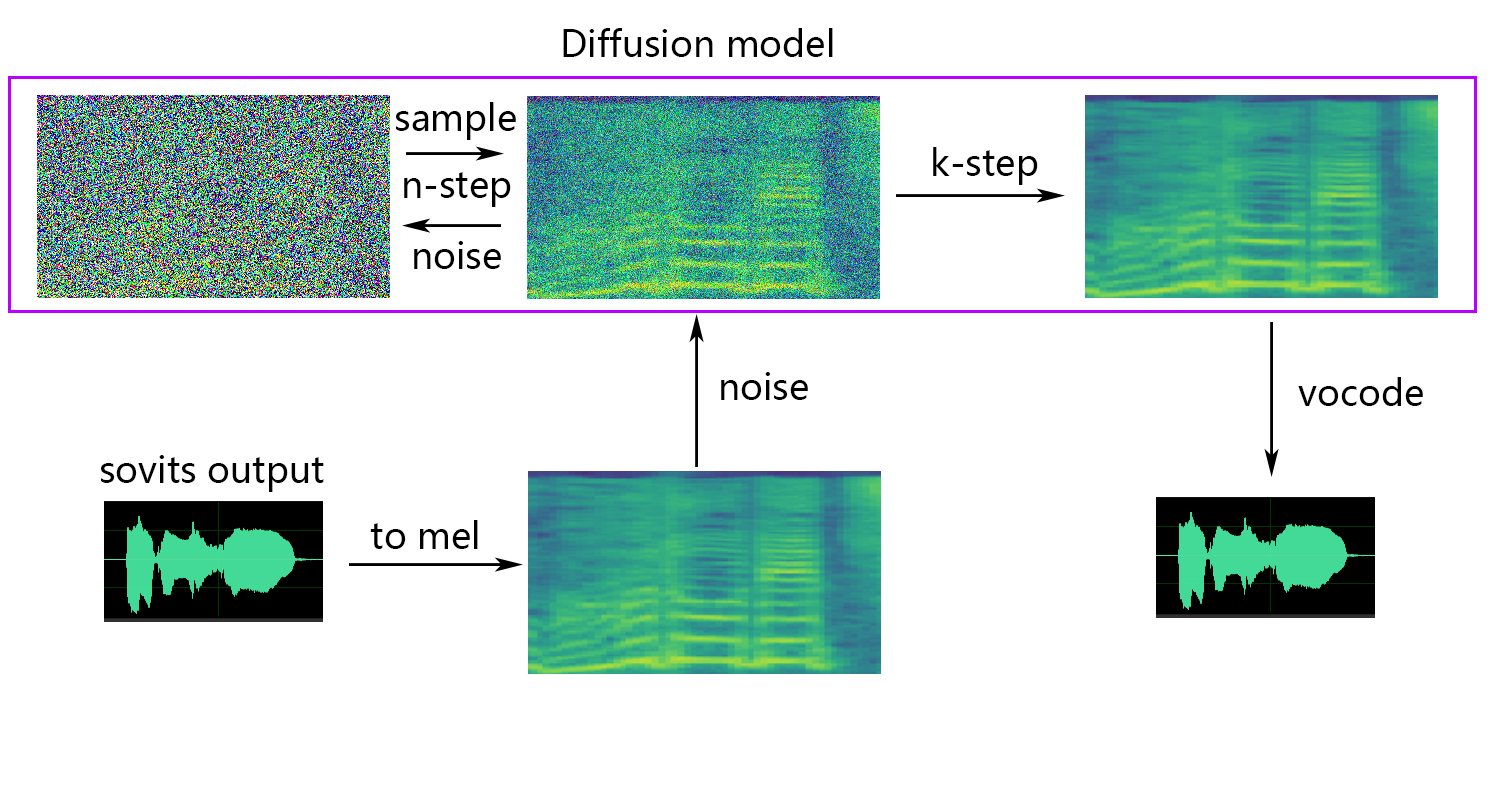
如果要浅扩散(可选),则需要添加--use_diff参数,例如:
python preprocess_hubert_f0.py --f0_predictor dio --use_diff加快预处理的速度
如果您的数据集很大,则可以增加param --num_processes这样:
python preprocess_hubert_f0.py --f0_predictor dio --num_processes 8如果您有一个以上的GPU,则所有工人将被分配给其他GPU。
完成上述步骤后,数据集目录将包含预处理数据,并且可以删除数据集_RAW文件夹。
python train.py -c configs/config.json -m 44k如果需要浅扩散函数,则需要训练扩散模型。扩散模型训练方法如下:
python train_diff.py -c configs/diffusion.yaml在培训期间,模型文件将保存到logs/44k ,扩散模型将保存到logs/44k/diffusion
使用inperion_main.py
# Example
python inference_main.py -m " logs/44k/G_30400.pth " -c " configs/config.json " -n "君の知らない物語-src.wav " -t 0 -s " nen "必需参数:
-m | --model_path :模型的路径。-c | --config_path :配置文件的路径。-n | --clean_names :位于raw文件夹中的WAV文件名的列表。-t | --trans :俯仰转移,支持正(半元素)值。-s | --spk_list :选择用于转换的扬声器ID。-cl | --clip :强制音频剪辑,将其设置为0 to禁用(默认值),将其设置为非零值(秒为秒)以启用。可选参数:请参阅下一部分
-lg | --linear_gradient :两秒钟内两个音频切片的交叉褪色长度。如果强迫切片后有不连续的声音,则可以调整此值。否则,建议使用默认值为0。-f0p | --f0_predictor :选择一个F0预测器,选项是crepe , pm , dio , harvest , rmvpe , fcpe ,默认值为pm (注意:使用crepe时F0平均池将启用)-a | --auto_predict_f0 :自动音调预测,在转换唱歌声音时不要启用这一点,因为它可能会导致严重的音调问题。-cm | --cluster_model_path :群集模型或功能检索索引路径,如果剩余空白,它将自动设置为这些模型的默认路径。如果没有培训集群或功能检索,请随意填写。-cr | --cluster_infer_ratio :聚类方案的比例或特征检索范围为0到1。如果没有训练聚类模型或功能检索,则默认值为0。-eh | --enhance :是否使用NSF_HIFIGAN增强器,此选项对某些训练集很少的模型对声音质量增强有一定的影响,但对训练有素的模型具有负面影响,因此默认情况下将其禁用。-shd | --shallow_diffusion :是否使用浅扩散,可以在使用后解决一些电气问题。此选项默认情况下是禁用的。启用此选项后,将禁用NSF_HIFIGAN增强器-usm | --use_spk_mix :是否使用动态语音融合-lea | --loudness_envelope_adjustment :与输出响应比率相关的输入源的响度信封的调整。接近1的距-fr | --feature_retrieval :如果使用聚类模型,将被禁用, cm和cr参数将成为索引路径和功能检索的混合率,是否使用特征检索。浅扩散设置:
-dm | --diffusion_model_path :扩散模型路径-dc | --diffusion_config_path :扩散配置文件路径-ks | --k_step :k_steps的数量越大,与扩散模型的结果越接近。默认值为100-od | --only_diffusion :是否仅使用扩散模式,该模式不加载Sovits模型仅使用扩散模型推断-se | --second_encoding :涉及在浅散布之前对原始音频进行附加编码。此选项可以产生不同的结果 - 有时是正面的,有时有时为负。如果使用whisper-ppg语音编码器进行推断,则需要将--clip设置为25和-lg至1。否则,它将无法正确推断。
如果您对先前的结果感到满意,或者您不理解以下内容,则可以跳过它,并且对模型的使用不会影响。提到的这些可选设置的影响相对较小,尽管它们可能会对特定数据集产生一定的影响,但在大多数情况下,差异可能并不显着。
在训练4.0型号的过程中,还对F0预测变量进行了训练,这可以在语音转换过程中自动预测。但是,如果结果不满意,则可以使用手动音高预测。请注意,在转换唱歌声音时,建议不要启用此功能,因为它可能会导致大幅变化。
auto_predict_f0设置为true in inference_main.py 。简介:该模型中实施的聚类方案旨在减少音色泄漏,并增强受过训练的模型与目标音色的相似性,尽管效果可能不是很明显。但是,仅依靠聚类可以降低模型的清晰度,并使其听起来不那么明显。因此,在此模型中采用了一种融合方法来控制聚类和非聚类方法之间的平衡。这允许手动调整“听起来像目标音色”和“具有清晰的发音”之间的权衡,以找到最佳的平衡。
在现有步骤中无需更改。只需培训额外的聚类模型,该模型会产生相对较低的培训成本。
python cluster/train_cluster.py 。输出模型将保存在logs/44k/kmeans_10000.pt中。python cluster/train_cluster.py --gpuinference_main.py中指定cluster_model_path 。如果未指定,则默认值为logs/44k/kmeans_10000.pt 。inference_main.py中指定cluster_infer_ratio ,其中0表示完全不使用群集, 1仅表示使用群集,通常0.5就足够了。简介:与聚类方案一样,可以减少音色泄漏,发音比聚类略好,但它会降低推理速度。通过采用融合方法,可以线性地控制特征检索和非功能检索之间的平衡,从而对所需比例进行微调。
python train_index.py -c configs/config.json该模型的输出将在logs/44k/feature_and_index.pkl中
--feature_retrieval需要先配制 - 聚类模式自动切换到功能检索模式。inference_main.py中指定cluster_model_path 。如果未指定,则默认值为logs/44k/feature_and_index.pkl 。inference_main.py中指定cluster_infer_ratio ,其中0表示完全不使用特征检索, 1仅表示仅使用特征检索,通常0.5就足够了。 生成的模型包含进一步培训所需的数据。如果您确认该模型是最终的,而不是在进一步的培训中使用,则可以删除这些数据以获取较小的文件大小(约1/3)。
# Example
python compress_model.py -c= " configs/config.json " -i= " logs/44k/G_30400.pth " -o= " logs/44k/release.pth " 请参阅webUI.py文件,以获取小工具/实验室功能的稳定音色混合。
简介:此功能可以将多个模型组合为一个模型(凸组合或多个模型参数的线性组合),以创建现实中不存在的混合语音
笔记:
model字段是相同的请参阅spkmix.py文件,以获取动态音色混合的简介
角色混合轨道写作规则:
角色ID:[[开始时间1,结束时间1,开始值1,启动值1],[开始时间2,结束时间2,开始值2]]
开始时间必须与上一个时间的结束时间相同。第一个开始时间必须为0,最后一个结束时间必须为1(时间为0到1)。
所有角色都必须填补。对于未使用的角色,填充[[0.,1。,0.,0。]]
融合值可以任意填充,并在指定的时间段内将线性从启动值变为最终值。这
内部线性组合将自动保证为1(凸组合条件),因此可以安全使用
推理时,请使用--use_spk_mix参数启用动态音色混合
使用onnx_export.py
checkpoints的文件夹并将其打开checkpoints文件夹中创建一个文件夹,在项目之后命名,例如aziplayerconfig.json model.pth aziplayerpath = "NyaruTaffy" "NyaruTaffy" nyarutaffy”在onnx_export.py中的“ nyarutaffy”为您的项目名称, path = "aziplayer" (onnx_export_speaker_mix可以使您的语音混合使用)model.onnx ,即导出的模型。注意:对于Hubert ONNX型号,请使用Moess提供的型号。目前,他们无法自行出口(Fairseq中的Hubert有许多不支持的操作员,并且涉及常数可能导致错误或导致输入时出现问题的常数问题。)
| URL | 指定 | 标题 | 实现来源 |
|---|---|---|---|
| 2106.06103 | VIT(合成器) | 端到端文本到语音的对抗性学习的条件变异自动编码器 | jaywalnut310/vits |
| 2111.02392 | SOFTVC(语音编码器) | 比较离散语音和软言语单元以改善语音转换 | Bshall/Hubert |
| 2204.09224 | ContentVec(语音编码器) | ContentVec:通过解开演讲者的改进的自我监督语音表示 | auspious3000/contentvec |
| 2212.04356 | 耳语(语音编码器) | 通过大规模的弱监督识别强大的语音识别 | Openai/窃窃私语 |
| 2110.13900 | WAVLM(语音编码器) | WAVLM:大规模自我监督的预培训,用于完整的堆栈语音处理 | Microsoft/Unilm/wavlm |
| 2305.17651 | Dphubert(语音编码) | Dphubert:自我监督语音模型的联合蒸馏和修剪 | pyf98/dphubert |
| doi:10.21437/Interspeech.2017-68 | 收获(F0预测指标) | 收获:来自语音信号的高性能基本频率估计器 | mmorise/世界/收获 |
| AES35-000039 | DIO(F0预测指标) | 基于歌声和语音的声带振动的周期提取的快速和可靠的F0估计方法 | mmorise/world/dio |
| 8461329 | Crepe(F0预测指标) | 可丽饼:卷积表示音高估计 | MAXRMORRISON/TORCHCREPE |
| doi:10.1016/j.wocn.2018.07.001 | Parselmouth(F0预测指标) | 介绍Parselmouth:Praat的Python界面 | Yannickjadoul/Parselmouth |
| 2306.15412v2 | RMVPE(F0预测指标) | rmvpe:多形音乐中声音估算的强大模型 | 梦幻/rmvpe |
| 2010.05646 | Hifigan(Vocoder) | HIFI-GAN:生成的对抗网络,可高效且高保真语音综合 | JIK876/HIFI-GAN |
| 1810.11946 | NSF(Vocoder) | 基于神经源过滤器的统计参数语音综合波形模型 | OpenVPI/DIFFSINGER/模块/NSF_HIFIGAN |
| 2006.08195 | 蛇(Vocoder) | 神经网络无法学习定期功能以及如何修复它 | Edwarddixon/Snake |
| 2105.02446v3 | 浅扩散(后处理) | DIFFSINGER:通过浅扩散机制唱歌声音综合 | CNCHTU/扩散-SVC |
| k均值 | 功能K-均值聚类(预处理) | 一些分类和分析多元观察的方法 | 这个存储库 |
| 功能TOPK检索(预处理) | 基于检索的语音转换 | RVC项目/基于基于检索的Voice Conversion-webui | |
| 耳语ppg | 耳语ppg | PlayVoice/hisper_ppg | |
| Bigvgan | Bigvgan | PlayVoice/so-Vits-SVC-5.0 |
由于某种原因,作者删除了原始存储库。由于组织成员的疏忽,因此清除了贡献者列表,因为在此存储库重建开始时,所有文件均直接重新上传到该存储库。现在,将以前的贡献列表添加到readme.md。
一些成员尚未按照他们的个人意愿列出。
米斯特 | 小米01 | しぐれ | tomogasukunai | Plachtaa | ZD小达 | 冻声响世 |
任何组织或者个人不得以丑化、污损,或者利用信息技术手段伪造等方式侵害他人的肖像权。未经肖像权人同意,不得制作、使用、公开肖像权人的肖像,但是法律另有规定的除外。未经肖像权人同意,肖像作品权利人不得以发表、复制、发行、出租、展览等方式使用或者公开肖像权人的肖像。对自然人声音的保护,参照适用肖像权保护的有关规定。,参照适用肖像权保护的有关规定。
【名誉权】民事主体享有名誉权。任何组织或者个人不得以侮辱、诽谤等方式侵害他人的名誉权。
【作品侵害名誉权】行为人发表的文学、艺术作品以真人真事或者特定人为描述对象,含有侮辱、诽谤内容,侵害他人名誉权的,受害人有权依法请求该行为人承担民事责任。行为人发表的文学、艺术作品不以特定人为描述对象,仅其中的情节与该特定人的情况相似的,不承担民事责任。,不承担民事责任。


