so vits svc
1.0.0
Anglais |中文简体
Cette série de mise à jour à durée limitée touche à sa fin, l'entrepôt entrera dans l'État d'Archieve, sachez
Un studio qui contient un éditeur F0 visible, un éditeur de chronologie de mix de haut-parleur et d'autres fonctionnalités (où les modèles ONNX sont utilisés): MoevoiceStudio
Une fourche avec une interface utilisateur considérablement améliorée: 34J / SO-VITS-SVC-FORK
Un client prend en charge la conversion en temps réel: W-Okada / Changer vocal
Ce projet diffère fondamentalement des VITS, car il se concentre sur la conversion vocale chanteuse (SVC) plutôt que sur le texte-parole (TTS). Dans ce projet, la fonctionnalité TTS n'est pas prise en charge et VITS est incapable d'effectuer des tâches SVC. Il est important de noter que les modèles utilisés dans ces deux projets ne sont pas interchangeables ou universellement applicables.
Le but de ce projet était de permettre aux développeurs de faire effectuer leurs personnages d'anime bien-aimés. L'intention des développeurs était de se concentrer uniquement sur les personnages fictifs et d'éviter toute implication de vrais individus, tout ce qui concerne les personnes réelles s'écarte de l'intention initiale du développeur.
Ce projet est une source open-source, hors ligne, et tous les membres de SVCDevelobeam, ainsi que d'autres développeurs et maintenants impliqués (ci-après dénommés contributeurs), n'ont aucun contrôle sur le projet. Les contributeurs n'ont jamais fourni aucune forme d'assistance à aucune organisation ou individu, y compris, mais sans s'y limiter, l'extraction de l'ensemble de données, le traitement de l'ensemble de données, le support informatique, la prise en charge de la formation, l'inférence, etc. Les contributeurs ne sont pas et ne peuvent pas être conscients des objectifs pour lesquels les utilisateurs utilisent le projet. Par conséquent, tous les modèles d'IA et l'audio synthétisé produit par la formation de ce projet ne sont pas liés aux contributeurs. Tout problème ou conséquence résultant de son utilisation est la seule responsabilité de l'utilisateur.
Ce projet est exécuté complètement hors ligne et ne collecte aucune information utilisateur ni ne recueille des données d'entrée utilisateur. Par conséquent, les contributeurs à ce projet ne sont pas conscients de toutes les entrées et modèles de l'utilisateur et ne sont donc pas responsables de toute entrée utilisateur.
Ce projet sert uniquement de cadre et ne possède pas de fonctionnalité de synthèse de la parole en soi. Toutes les fonctionnalités obligent les utilisateurs à former les modèles indépendamment. En outre, ce projet n'est pas livré avec des modèles, et tous les projets distribués secondaires sont indépendants des contributeurs de ce projet.
Le modèle de conversion vocale chantant utilise l'encodeur de contenu SoftVC pour extraire les fonctionnalités de la parole de l'audio source. Ces vecteurs de caractéristiques sont directement introduits dans des VITS sans avoir besoin de conversion en une représentation intermédiaire basée sur le texte. En conséquence, la hauteur et les intonations de l'audio d'origine sont conservées. Pendant ce temps, le vocodeur a été remplacé par NSF Hifigan pour résoudre le problème de l'interruption sonore.
config.json . Ajoutez le champ speech_encoder à la section "modèle" comme indiqué ci-dessous: "model": {
.........
"ssl_dim": 256,
"n_speakers": 200,
"speech_encoder":"vec256l9"
}
Sur la base de nos tests, nous avons déterminé que le projet s'exécute stable sur Python 3.8.9 .
Vous devez sélectionner un encodeur dans la liste ci-dessous
vec768l12 et vec256l9 nécessitent le codeur
pretrainOu téléchargez le contenu suivant, qui n'a que 199 Mo de taille mais qui a le même effet:
checkpoint_best_legacy_500.pt et placez-le dans le répertoire pretrain # contentvec
wget -P pretrain/ https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/hubert_base.pt -O checkpoint_best_legacy_500.pt
# Alternatively, you can manually download and place it in the hubert directory pretrain whisper-ppgwhisper-ppg-largepretrain pretrain pretrain wavlmbase+pretrain pretrain Fichiers du modèle pré-formé: G_0.pth D_0.pth
logs/44k Modèle de diffusion Fichier de modèle de base de pré-élaction: model_0.pt
logs/44k/diffusionObtenez le modèle pré-formé SOVITS à partir de SVC-Developing-Team (TBD) ou ailleurs.
Modèle de diffusion références au modèle de diffusion de diffusion-SVC. Le modèle de diffusion pré-formé est universel avec les DDSP-SVC. Vous pouvez aller au dépôt de diffusion-SVC pour obtenir le modèle de diffusion pré-formé.
Bien que le modèle pré-entraîné ne pose généralement pas de préoccupations de droits d'auteur, il est essentiel de rester vigilant. Il est conseillé de consulter l'auteur au préalable ou de passer attentivement la description pour déterminer l'utilisation autorisée du modèle. Cela permet de garantir la conformité à toutes les directives ou restrictions spécifiées concernant son utilisation.
Si vous utilisez le NSF-HIFIGAN enhancer ou shallow diffusion , vous devrez télécharger le modèle NSF-HIFIGAN pré-formé.
pretrain/nsf_hifigan # nsf_hifigan
wget -P pretrain/ https://github.com/openvpi/vocoders/releases/download/nsf-hifigan-v1/nsf_hifigan_20221211.zip
unzip -od pretrain/nsf_hifigan pretrain/nsf_hifigan_20221211.zip
# Alternatively, you can manually download and place it in the pretrain/nsf_hifigan directory
# URL: https://github.com/openvpi/vocoders/releases/tag/nsf-hifigan-v1 Si vous utilisez le prédicteur rmvpe F0, vous devrez télécharger le modèle RMVPE pré-formé.
rmvpe.zip , et renommez le fichier model.pt à rmvpe.pt et placez-le sous le répertoire pretrain .pretrain FCPE (Fast Context-Base Pitch Estimator) est un prédicteur F0 dédié conçu pour la conversion vocale en temps réel et deviendra le prédicteur F0 préféré pour la conversion vocale en temps réel à l'avenir. (L'article est écrit)
Si vous utilisez le prédicteur fcpe F0, vous devrez télécharger le modèle FCPE pré-formé.
pretrain Placez simplement l'ensemble de données dans le répertoire dataset_raw avec la structure de fichier suivante:
dataset_raw
├───speaker0
│ ├───xxx1-xxx1.wav
│ ├───...
│ └───Lxx-0xx8.wav
└───speaker1
├───xx2-0xxx2.wav
├───...
└───xxx7-xxx007.wav
Il n'y a pas de restrictions spécifiques sur le format du nom pour chaque fichier audio (conventions de dénomination telles que 000001.wav à 999999.wav sont également valides), mais le type de fichier doit être `` wav``.
Vous pouvez personnaliser le nom de l'orateur comme indiqué ci-dessous:
dataset_raw
└───suijiSUI
├───1.wav
├───...
└───25788785-20221210-200143-856_01_(Vocals)_0_0.wav
Pour éviter le débordement de la mémoire vidéo pendant la formation ou le prétraitement, il est recommandé de limiter la durée des clips audio. La coupe de l'audio à une longueur de "5s - 15s" est plus recommandée. Les temps légèrement plus longs sont acceptables, cependant, des clips excessivement longs peuvent entraîner des problèmes tels que torch.cuda.OutOfMemoryError .
Pour faciliter le processus de tranchage, vous pouvez utiliser audio-licer-Gui ou audio-Slicer-CLI
En général, seul l' Minimum Interval doit être ajusté. Pour l'audio parlé, la valeur par défaut suffit généralement, tandis que pour chanter l'audio, il peut être ajusté à environ 100 ou même 50 , selon les exigences spécifiques.
Après tranchage, il est recommandé de supprimer tous les clips audio excessivement longs ou trop courts.
Si vous utilisez Encodeur Whisper-PPG pour la formation, les clips audio doivent être plus courts que 30 s.
python resample.py Bien que ce projet ait des scripts Resample.py pour le rééchantillonnage, le mono et la correspondance du volume, la correspondance par défaut de la volume est de correspondre à 0 dB. Cela peut endommager la qualité sonore. Bien que le package de correspondance de l'intensité de Python, Pyloudnorm ne limite le niveau, cela peut conduire à la flèche sonore. Par conséquent, il est recommandé d'envisager d'utiliser un logiciel de traitement sonore professionnel, tel que adobe audition pour la correspondance de l'intensité. Si vous utilisez déjà d'autres logiciels pour la correspondance du volume, ajoutez le paramètre -skip_loudnorm à la commande RUN:
python resample.py --skip_loudnormpython preprocess_flist_config.py --speech_encoder vec768l12Speech_encoder a les options suivantes
vec768l12
vec256l9
hubertsoft
whisper-ppg
cnhubertlarge
dphubert
whisper-ppg-large
wavlmbase+
Si l'argument Speech_Encoder est omis, la valeur par défaut est vec768l12
Utilisez l'intégration de l'intégration
Ajouter --vol_aug si vous souhaitez permettre une incorporation de volume:
python preprocess_flist_config.py --speech_encoder vec768l12 --vol_augAprès avoir activé l'incorporation du volume, le modèle formé correspondra à l'intensité de la source d'entrée; Sinon, cela correspondra à l'intensité de l'ensemble d'entraînement.
keep_ckpts : gardez le nombre de modèles précédents pendant la formation. Réglé sur 0 pour les garder tous. La valeur par défaut est 3 .
all_in_mem : Chargez tout ensemble de données vers RAM. Il peut être activé lorsque le disque IO de certaines plates-formes est trop faible et que la mémoire système est beaucoup plus grande que votre ensemble de données.
batch_size : La quantité de données chargées au GPU pour une seule session de formation peut être ajustée à une taille inférieure à la capacité de mémoire du GPU.
vocoder_name : sélectionnez un vocoder. La valeur par défaut est nsf-hifigan .
cache_all_data : Chargez tout ensemble de données vers RAM. Il peut être activé lorsque le disque IO de certaines plates-formes est trop faible et que la mémoire système est beaucoup plus grande que votre ensemble de données.
duration : La durée du tranchage audio pendant la formation peut être ajustée en fonction de la taille de la mémoire vidéo, Remarque: Cette valeur doit être inférieure au temps minimum de l'audio dans l'ensemble de formation!
batch_size : La quantité de données chargée au GPU pour une seule session de formation peut être ajustée à une taille inférieure à la capacité de mémoire vidéo.
timesteps : le nombre total d'étapes du modèle de diffusion, qui par défaut est à 1000.
k_step_max : La formation ne peut entraîner que la diffusion k_step_max étape pour économiser le temps de formation, notez que la valeur doit être inférieure aux timesteps , 0 est de former l'intégralité du modèle de diffusion, Remarque: Si vous ne formez pas l'intégralité du modèle de diffusion ne pourra pas utiliser Only_diffusion!
nsf-hifigan
nsf-snake-hifigan
python preprocess_hubert_f0.py --f0_predictor dioF0_Predictor a les options suivantes
crepe
dio
pm
harvest
rmvpe
fcpe
Si l'ensemble de formation est trop bruyant, il est recommandé d'utiliser crepe pour gérer F0
Si le paramètre F0_Predictor est omis, la valeur par défaut est rmvpe
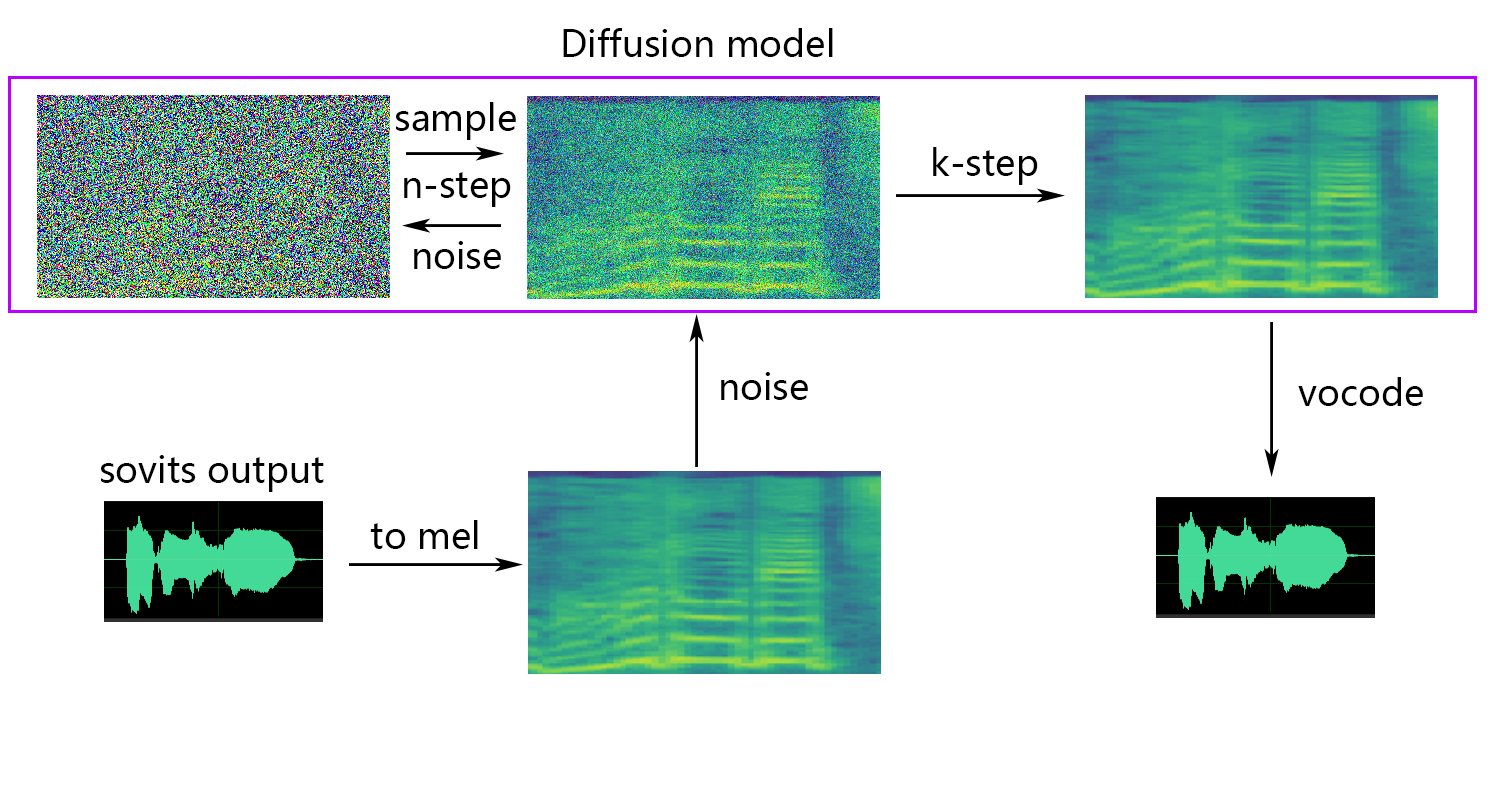
Si vous voulez une diffusion peu profonde (facultative), vous devez ajouter le paramètre --use_diff , par exemple:
python preprocess_hubert_f0.py --f0_predictor dio --use_diffAccélérer le prétraitement
Si votre ensemble de données est assez grand, vous pouvez augmenter le param --num_processes comme ça:
python preprocess_hubert_f0.py --f0_predictor dio --num_processes 8Tout le travailleur sera affecté à différents GPU si vous avez plus d'un GPU.
Après avoir terminé les étapes ci-dessus, le répertoire de jeu de données contiendra les données prétraitées et le dossier DataSet_RAW peut être supprimé.
python train.py -c configs/config.json -m 44kSi la fonction de diffusion peu profonde est nécessaire, le modèle de diffusion doit être formé. La méthode de formation du modèle de diffusion est la suivante:
python train_diff.py -c configs/diffusion.yaml Pendant la formation, les fichiers du modèle seront enregistrés sur logs/44k , et le modèle de diffusion sera enregistré dans logs/44k/diffusion
Utiliser Inference_Main.py
# Example
python inference_main.py -m " logs/44k/G_30400.pth " -c " configs/config.json " -n "君の知らない物語-src.wav " -t 0 -s " nen "Paramètres requis:
-m | --model_path : chemin vers le modèle.-c | --config_path : chemin vers le fichier de configuration.-n | --clean_names : une liste des noms de fichiers WAV situés dans le dossier raw .-t | --trans : Pitch Shift, prend en charge les valeurs positives et négatives (semiton).-s | --spk_list : Sélectionnez l'ID de haut-parleur à utiliser pour la conversion.-cl | --clip : Coupage audio forcé, réglé sur 0 pour désactiver (par défaut), en le définissant sur une valeur non nulle (durée en secondes) pour activer.Paramètres facultatifs: voir la section suivante
-lg | --linear_gradient : La longueur de la fonte des croix de deux tranches audio en secondes. S'il y a une voix discontinue après le tranchage forcé, vous pouvez ajuster cette valeur. Sinon, il est recommandé d'utiliser la valeur par défaut de 0.-f0p | --f0_predictor : Sélectionnez un prédicteur F0, les options sont crepe , pm , dio , harvest , rmvpe , fcpe , la valeur par défaut est pm (Remarque: F0 Le regroupement moyen sera activé lors de l'utilisation crepe )-a | --auto_predict_f0 : Prédiction de hauteur automatique, ne le permettez pas lors de la conversion de voix de chant car cela peut provoquer de graves problèmes de hauteur.-cm | --cluster_model_path : modèle de cluster ou chemin d'index de récupération de fonctionnalité, s'il est laissé vide, il sera automatiquement défini comme chemin par défaut de ces modèles. S'il n'y a pas de cluster de formation ou de récupération de fonctionnalités, remplissez à volonté.-cr | --cluster_infer_ratio : la proportion de schéma de clustering ou de récupération de fonctionnalités varie de 0 à 1. S'il n'y a pas de modèle de clustering ou de récupération de fonctionnalité, la valeur par défaut est 0.-eh | --enhance : Que ce soit pour utiliser NSF_HIFIGAN Enhancer, cette option a un certain effet sur l'amélioration de la qualité du son pour certains modèles avec quelques ensembles de formation, mais a un effet négatif sur des modèles bien formés, il est donc désactivé par défaut.-shd | --shallow_diffusion : s'il faut utiliser une diffusion peu profonde, qui peut résoudre certains problèmes de son électrique après utilisation. Cette option est désactivée par défaut. Lorsque cette option est activée, NSF_HIFigan Enhancer sera désactivé-usm | --use_spk_mix : s'il faut utiliser la fusion vocale dynamique-lea | --loudness_envelope_adjustment : le réglage de l'enveloppe de résistance de la source d'entrée par rapport au rapport de fusion de l'enveloppe de volume de sortie. Plus la plus proche de 1, plus l'enveloppe de volume de sortie est utilisée-fr | --feature_retrieval : CONSILLE À UTILISER LA RÉTENSITION DES FONCTIONS Si le modèle de clustering est utilisé, il sera désactivé, et les paramètres cm et cr deviendront le chemin d'index et le rapport de mélange de la récupération des fonctionnalitésParamètres de diffusion peu profonde:
-dm | --diffusion_model_path : chemin du modèle de diffusion-dc | --diffusion_config_path : chemin de fichier de configuration de diffusion-ks | --k_step : Plus le nombre de k_steps est grand, plus il est proche du résultat du modèle de diffusion. La valeur par défaut est 100-od | --only_diffusion : s'il faut utiliser uniquement le mode de diffusion, qui ne charge pas le modèle SoVits pour utiliser uniquement l'inférence du modèle de diffusion-se | --second_encoding : qui implique d'appliquer un codage supplémentaire à l'audio d'origine avant la diffusion peu profonde. Cette option peut donner des résultats variables - parfois positifs et parfois négatifs. Si l'inférence à l'aide de l'encodeur de la parole whisper-ppg , vous devez définir --clip sur 25 et -lg à 1. Sinon, il ne parviendra pas à déduire correctement.
Si vous êtes satisfait des résultats précédents, ou si vous ne pensez pas que vous comprenez ce qui suit, vous pouvez le sauter et cela n'aura aucun effet sur l'utilisation du modèle. L'impact de ces paramètres facultatifs mentionnés est relativement faible, et bien qu'ils puissent avoir un certain impact sur des ensembles de données spécifiques, dans la plupart des cas, la différence peut ne pas être significative.
Au cours de la formation du modèle 4.0, un prédicteur F0 est également formé, ce qui permet une prédiction de hauteur automatique pendant la conversion vocale. Cependant, si les résultats ne sont pas satisfaisants, la prédiction manuelle peut être utilisée à la place. Veuillez noter que lors de la conversion des voix de chant, il est conseillé de ne pas activer cette fonctionnalité car elle peut provoquer un changement de hauteur important.
auto_predict_f0 sur true in inference_main.py .Introduction: Le schéma de clustering implémenté dans ce modèle vise à réduire les fuites du timbre et à améliorer la similitude du modèle formé avec le timbre de la cible, bien que l'effet puisse ne pas être très prononcé. Cependant, s'appuyer uniquement sur le regroupement peut réduire la clarté du modèle et le rendre moins distinct. Par conséquent, une méthode de fusion est adoptée dans ce modèle pour contrôler l'équilibre entre les approches de clustering et de non-cluster. Cela permet un ajustement manuel du compromis entre "Sonner comme le timbre de la cible" et "avoir une énonciation claire" pour trouver un équilibre optimal.
Aucune modification n'est requise dans les étapes existantes. Formez simplement un modèle de clustering supplémentaire, qui entraîne des coûts de formation relativement bas.
python cluster/train_cluster.py . Le modèle de sortie sera enregistré dans logs/44k/kmeans_10000.pt .python cluster/train_cluster.py --gpucluster_model_path dans inference_main.py . Si ce n'est pas spécifié, la valeur par défaut est logs/44k/kmeans_10000.pt .cluster_infer_ratio dans inference_main.py , où 0 signifie ne pas utiliser de clustering du tout, 1 signifie uniquement utiliser le clustering, et généralement 0.5 est suffisant.Introduction: Comme pour le schéma de clustering, la fuite du timbre peut être réduite, l'énonciation est légèrement meilleure que le regroupement, mais elle réduira la vitesse d'inférence. En utilisant la méthode de fusion, il devient possible de contrôler linéairement l'équilibre entre la récupération des fonctionnalités et la récupération non-fonctionnement, permettant un réglage fin de la proportion souhaitée.
python train_index.py -c configs/config.json La sortie du modèle sera en logs/44k/feature_and_index.pkl
--feature_retrieval doit être formulé en premier, et le mode de clustering passe automatiquement au mode de récupération des fonctionnalités.cluster_model_path dans inference_main.py . S'il n'est pas spécifié, la valeur par défaut est logs/44k/feature_and_index.pkl .cluster_infer_ratio dans inference_main.py , où 0 signifie ne pas utiliser du tout la récupération des fonctionnalités, 1 signifie uniquement utiliser la récupération des fonctionnalités, et généralement 0.5 est suffisant. Le modèle généré contient des données nécessaires pour une formation plus approfondie. Si vous confirmez que le modèle est définitif et ne pas être utilisé dans une formation plus approfondie, il est sûr de supprimer ces données pour obtenir une taille de fichier plus petite (environ 1/3).
# Example
python compress_model.py -c= " configs/config.json " -i= " logs/44k/G_30400.pth " -o= " logs/44k/release.pth " Reportez-vous au fichier webUI.py pour le mélange de timbre stable de la fonction Gadget / Lab.
Introduction: Cette fonction peut combiner plusieurs modèles en un seul modèle (combinaison convexe ou combinaison linéaire de plusieurs paramètres de modèle) pour créer une voix mixte qui n'existe pas en réalité
Note:
model dans config.json de tous les modèles à mixer sont les mêmes Reportez-vous au fichier spkmix.py pour une introduction au mélange dynamique du timbre
Règles d'écriture de piste de mixage de personnages:
ID de rôle: [[Heure de début 1, heure de fin 1, valeur de démarrage 1, valeur de démarrage 1], [heure de début 2, heure de fin 2, valeur de démarrage 2]]
L'heure de début doit être la même que l'heure de fin de la précédente. La première heure de début doit être 0 et la dernière heure de fin doit être 1 (l'heure varie de 0 à 1).
Tous les rôles doivent être remplis. Pour les rôles inutilisés, remplissez [[0., 1., 0., 0.]]
La valeur de fusion peut être remplie arbitrairement et le passage linéaire de la valeur de début à la valeur finale dans le délai spécifié. Le
La combinaison linéaire interne sera automatiquement garantie d'être 1 (condition de combinaison convexe), donc il peut être utilisé en toute sécurité
Utilisez le paramètre --use_spk_mix lors du raisonnement pour activer le mélange dynamique du timbre
Utiliser onnx_export.py
checkpoints et ouvrez-lecheckpoints comme dossier de projet, en le nommant après votre projet, par exemple aziplayermodel.pth , le fichier de configuration comme config.json , et les placer dans le dossier aziplayer que vous venez de créer"NyaruTaffy" dans path = "NyaruTaffy" dans onnx_export.py au nom de votre projet, path = "aziplayer" (onnx_export_speaker_mix fait que vous pouvez mélanger la voix du haut-parleur)model.onnx sera généré dans votre dossier de projet, qui est le modèle exporté.Remarque: Pour les modèles Hubert Onnx, veuillez utiliser les modèles fournis par Moess. Actuellement, ils ne peuvent pas être exportés seuls (Hubert à Fairseq possède de nombreux opérateurs non pris en charge et des choses impliquant des constantes qui peuvent entraîner des erreurs ou entraîner des problèmes avec la forme d'entrée / sortie et les résultats lorsqu'ils sont exportés.)
| URL | Désignation | Titre | Source d'implémentation |
|---|---|---|---|
| 2106.06103 | VITS (synthétiseur) | Autoencodeur variationnel conditionnel avec apprentissage contradictoire pour le texte à la fin à la fin à la fin de bout | Jaywalnut310 / VITS |
| 2111.02392 | Softvc (encodeur de discours) | Une comparaison des unités de discours discrètes et souples pour une meilleure conversion vocale | Bshall / Hubert |
| 2204.09224 | Contentvec (Encodeur de discours) | Contentvec: une représentation de la parole auto-supervisée améliorée en démêlant les locuteurs | Inuspicious3000 / Contentvec |
| 2212.04356 | Whisper (Encodeur de discours) | Reconnaissance de la parole robuste via une faible supervision faible | Openai / Whisper |
| 2110.13900 | Wavlm (encodeur de la parole) | WAVLM: pré-formation auto-supervisée à grande échelle pour le traitement de la parole complète de la pile | Microsoft / unilm / wavlm |
| 2305.17651 | DPHUBERT (Encodeur de discours) | DPHUBERT: Distillation conjointe et élagage des modèles de vocation auto-supervisés | pyf98 / dphubert |
| Doi: 10.21437 / intersegesech.2017-68 | Récolte (prédicteur F0) | Récolte: un estimateur de fréquence fondamental à haute performance des signaux de la parole | mmorise / monde / récolte |
| AES35-000039 | Dio (prédicteur F0) | Méthode d'estimation F0 rapide et fiable basée sur l'extraction de la période de la vibration du pli vocal de la voix et de la parole chantante | mmorise / monde / dio |
| 8461329 | Crêpe (prédicteur F0) | Crêpe: une représentation convolutionnelle pour l'estimation de la hauteur | maxrmorrison / torchcrepe |
| Doi: 10.1016 / j.wocn.2018.07.001 | Parselmouth (prédicteur F0) | Présentation de Parselmouth: une interface Python à Praat | Yannickjadoul / Parselmouth |
| 2306.15412v2 | RMVPE (prédicteur F0) | RMVPE: un modèle robuste pour l'estimation de la hauteur vocale dans la musique polyphonique | Dream-High / RMVPE |
| 2010.05646 | Hifigan (vocoder) | Hifi-gan: réseaux adversaires génératifs pour une synthèse de parole efficace et haute fidélité | Jik876 / Hifi-gan |
| 1810.11946 | NSF (Vocoder) | Modèle de forme d'onde basé sur le filtre à source neuronal pour la synthèse de la parole paramétrique statistique | openvpi / diffsinger / modules / nsf_hifigan |
| 2006.08195 | Serpent (vocodeur) | Les réseaux de neurones ne parviennent pas à apprendre les fonctions périodiques et comment le réparer | Edwarddixon / Snake |
| 2105.02446v3 | Diffusion peu profonde (post-traitement) | Diffsinger: Singing vocal Synthesis via un mécanisme de diffusion superficiel | Cnchtu / diffusion-svc |
| K-means | Caractéristiques du clustering K-means (prétraitement) | Quelques méthodes de classification et d'analyse des observations multivariées | Ce repo |
| Caractéristique de la récupération de Topk (prétraitement) | Conversion vocale basée sur la récupération | RVC-Project / Retrieval-Based-Voice-Conversion-Webui | |
| chuchoter ppg | chuchoter ppg | Playvoice / whisper_ppg | |
| bigvgan | bigvgan | PlayVoice / so-vits-svc-5.0 |
Pour une raison quelconque, l'auteur a supprimé le référentiel d'origine. En raison de la négligence des membres de l'organisation, la liste des contributeurs a été effacée car tous les fichiers ont été directement reversés dans ce référentiel au début de la reconstruction de ce référentiel. Ajoutez maintenant une liste de contributeurs précédents à Readme.md.
Certains membres n'ont pas répertorié selon leurs souhaits personnels.
Mât | Xiaomiku01 | しぐれ | Tomogasukunai | Plachtaa | ZD 小达 | 凍聲響世 |
任何组织或者个人不得以丑化、污损 , 或者利用信息技术手段伪造等方式侵害他人的肖像权。未经肖像权人同意 , 不得制作、使用、公开肖像权人的肖像 , 但是法律另有规定的除外。未经肖像权人同意 , 肖像作品权利人不得以发表、复制、发行、出租、展览等方式使用或者公开肖像权人的肖像。对自然人声音的保护 , 参照适用肖像权保护的有关规定。
【名誉权】民事主体享有名誉权。任何组织或者个人不得以侮辱、诽谤等方式侵害他人的名誉权。
【作品侵害名誉权】行为人发表的文学、艺术作品以真人真事或者特定人为描述对象 , 含有侮辱、诽谤内容 , 侵害他人名誉权的 , 受害人有权依法请求该行为人承担民事责任。行为人发表的文学、艺术作品不以特定人为描述对象 , 仅其中的情节与该特定人的情况相似的 , 不承担民事责任。


