so vits svc
1.0.0
Inglês |中文简体
Esta rodada de atualização de tempo limitada está chegando ao fim, o armazém entrará no estado de Archieve, por favor saiba
Um estúdio que contém editor F0 visível, editor de linha do tempo de mix de alto -falante e outros recursos (onde os modelos ONNX são usados): moevoicestudio
Um garfo com uma interface de usuário muito melhorada: 34J/SO-VITS-SVC-FORK
Um cliente suporta conversão em tempo real: W-Okada/Voice-Changer
Este projeto difere fundamentalmente dos Vits, pois se concentra no canto de conversão de voz (SVC) em vez de em fala em fala (TTS). Neste projeto, a funcionalidade TTS não é suportada e o VITs é incapaz de executar tarefas SVC. É importante observar que os modelos usados nesses dois projetos não são intercambiáveis ou universalmente aplicáveis.
O objetivo deste projeto era permitir que os desenvolvedores tivessem seus amados personagens de anime executarem tarefas de canto. A intenção dos desenvolvedores era se concentrar apenas em personagens fictícios e evitar qualquer envolvimento de indivíduos reais, qualquer coisa relacionada a indivíduos reais se desvia da intenção original do desenvolvedor.
Este projeto é um empreendimento de código aberto, offline e todos os membros do SVCDevelopTeam, bem como outros desenvolvedores e mantenedores envolvidos (a seguir denominados colaboradores), não têm controle sobre o projeto. Os colaboradores nunca forneceram nenhuma forma de assistência a qualquer organização ou indivíduo, incluindo, entre outros, extração do conjunto de dados, processamento de dados, suporte à computação, suporte ao treinamento, inferência e assim por diante. Os colaboradores não podem e não podem estar cientes dos propósitos para os quais os usuários utilizam o projeto. Portanto, quaisquer modelos de IA e áudio sintetizado produzidos através do treinamento deste projeto não estão relacionados aos colaboradores. Quaisquer problemas ou consequências decorrentes de seu uso são de responsabilidade exclusiva do usuário.
Este projeto é executado completamente offline e não coleta nenhuma informação do usuário nem coleta dados de entrada do usuário. Portanto, os colaboradores deste projeto não estão cientes de todas as entradas e modelos do usuário e, portanto, não são responsáveis por nenhuma entrada do usuário.
Este projeto serve apenas como uma estrutura e não possui funcionalidade de síntese de fala por si só. Todas as funcionalidades exigem que os usuários treinem os modelos de forma independente. Além disso, este projeto não vem com nenhum modelos, e quaisquer projetos distribuídos secundários são independentes dos colaboradores deste projeto.
O modelo de conversão de voz de canto usa o codificador SoftVC Content para extrair recursos de fala do áudio de origem. Esses vetores de características são alimentados diretamente em VITs sem a necessidade de conversão para uma representação intermediária baseada em texto. Como resultado, o tom e as entonações do áudio original são preservados. Enquanto isso, o vocoder foi substituído por NSF Hifigan para resolver o problema da interrupção do som.
config.json . Adicione o campo speech_encoder à seção "Modelo", como mostrado abaixo: "model": {
.........
"ssl_dim": 256,
"n_speakers": 200,
"speech_encoder":"vec256l9"
}
Com base em nossos testes, determinamos que o projeto é estável no Python 3.8.9 .
Você precisa selecionar um codificador na lista abaixo
vec768l12 e vec256l9 requerem o codificador
pretrainOu faça o download do seguinte contentvec, que tem apenas 199 MB de tamanho, mas tem o mesmo efeito:
checkpoint_best_legacy_500.pt e coloque -o no diretório pretrain # contentvec
wget -P pretrain/ https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/hubert_base.pt -O checkpoint_best_legacy_500.pt
# Alternatively, you can manually download and place it in the hubert directory pretrain whisper-ppgwhisper-ppg-largepretrain pretrain pretrain wavlmbase+pretrain pretrain Arquivos de modelo pré-treinados: G_0.pth D_0.pth
logs/44k Modelo de difusão Pré -treinar o arquivo do modelo base: model_0.pt
logs/44k/diffusionObtenha o modelo pré-treinado Sovits da equipe de desenvolvimento SVC (TBD) ou em qualquer outro lugar.
Modelo de difusão Referências do modelo de difusão de difusão-SVC. O modelo de difusão pré-treinado é universal com os DDSP-SVC. Você pode ir ao repositório da Difusão-SVC para obter o modelo de difusão pré-treinado.
Embora o modelo pré -treinamento normalmente não represente preocupações com direitos autorais, é essencial permanecer vigilante. É aconselhável consultar o autor de antemão ou revisar cuidadosamente a descrição para verificar o uso permitido do modelo. Isso ajuda a garantir a conformidade com quaisquer diretrizes ou restrições especificadas em relação à sua utilização.
Se você estiver usando o NSF-HIFIGAN enhancer ou shallow diffusion , precisará baixar o modelo NSF-Hifigan pré-treinado.
pretrain/nsf_hifigan # nsf_hifigan
wget -P pretrain/ https://github.com/openvpi/vocoders/releases/download/nsf-hifigan-v1/nsf_hifigan_20221211.zip
unzip -od pretrain/nsf_hifigan pretrain/nsf_hifigan_20221211.zip
# Alternatively, you can manually download and place it in the pretrain/nsf_hifigan directory
# URL: https://github.com/openvpi/vocoders/releases/tag/nsf-hifigan-v1 Se você estiver usando o preditor rmvpe F0, precisará baixar o modelo RMVPE pré-treinado.
rmvpe.zip , e renomeie o arquivo model.pt para rmvpe.pt e coloque -o no diretório pretrain .pretrain O FCPE (Fast Context-Base Pitch Estimator) é um preditor F0 dedicado projetado para conversão de voz em tempo real e se tornará o preditor F0 preferido para a conversão de voz em tempo real do Sovits no futuro. (O artigo está sendo escrito)
Se você estiver usando o Preditor fcpe F0, precisará baixar o modelo FCPE pré-treinado.
pretrain Basta colocar o conjunto de dados no diretório dataset_raw com a seguinte estrutura de arquivos:
dataset_raw
├───speaker0
│ ├───xxx1-xxx1.wav
│ ├───...
│ └───Lxx-0xx8.wav
└───speaker1
├───xx2-0xxx2.wav
├───...
└───xxx7-xxx007.wav
Não há restrições específicas no formato do nome para cada arquivo de áudio (convenções de nomeação como 000001.wav a 999999.wav também são válidas), mas o tipo de arquivo deve ser `wav```.
Você pode personalizar o nome do alto -falante, como mostrado abaixo:
dataset_raw
└───suijiSUI
├───1.wav
├───...
└───25788785-20221210-200143-856_01_(Vocals)_0_0.wav
Para evitar o excesso de memória de vídeo durante o treinamento ou o pré-processamento, é recomendável limitar a duração dos clipes de áudio. Cortar o áudio para um comprimento de "5s - 15s" é mais recomendado. Tempos um pouco mais longos são aceitáveis, no entanto, clipes excessivamente longos podem causar problemas como torch.cuda.OutOfMemoryError .
Para facilitar o processo de fatiamento, você pode usar o áudio-slicer-gui ou o áudio-slicer-cli
Em geral, apenas o Minimum Interval precisa ser ajustado. Para o áudio falado, o valor padrão geralmente é suficiente, enquanto para cantar áudio, ele pode ser ajustado para cerca de 100 ou até 50 , dependendo dos requisitos específicos.
Após o fatiamento, é recomendável remover os clipes de áudio que são excessivamente longos ou muito curtos.
Se você estiver usando o codificador Whisper-PPG para treinamento, os clipes de áudio devem ter mais de 30 anos.
python resample.py Embora este projeto tenha rerample. Isso pode causar danos à qualidade do som. Enquanto o pacote que corresponde à altura de Python, o pyloudnorm, não limita o nível, isso pode levar ao boom sônico. Portanto, é recomendável considerar o uso de software profissional de processamento de som, como adobe audition for Solendness correspondendo. Se você já está usando outro software para correspondência de volume, adicione o parâmetro -skip_loudnorm ao comando run:
python resample.py --skip_loudnormpython preprocess_flist_config.py --speech_encoder vec768l12discurso_encoder tem as seguintes opções
vec768l12
vec256l9
hubertsoft
whisper-ppg
cnhubertlarge
dphubert
whisper-ppg-large
wavlmbase+
Se o argumento de discurso_encoder for omitido, o valor padrão será vec768l12
Use a incorporação de volume
Adicione --vol_aug se você deseja ativar a incorporação de volume:
python preprocess_flist_config.py --speech_encoder vec768l12 --vol_augApós ativar a incorporação de volume, o modelo treinado corresponderá à sonoridade da fonte de entrada; Caso contrário, ele corresponderá à sonoridade do conjunto de treinamento.
keep_ckpts : mantenha o número de modelos anteriores durante o treinamento. Defina como 0 para manter todos eles. O padrão é 3 .
all_in_mem : carregue todo o conjunto de dados para RAM. Ele pode ser ativado quando o disco de algumas plataformas é muito baixo e a memória do sistema é muito maior que o seu conjunto de dados.
batch_size : A quantidade de dados carregados na GPU para uma única sessão de treinamento pode ser ajustada para um tamanho menor que a capacidade de memória da GPU.
vocoder_name : selecione um vocoder. O padrão é nsf-hifigan .
cache_all_data : carregue todo o conjunto de dados para RAM. Ele pode ser ativado quando o disco de algumas plataformas é muito baixo e a memória do sistema é muito maior que o seu conjunto de dados.
duration : A duração do fatiamento de áudio durante o treinamento pode ser ajustada de acordo com o tamanho da memória de vídeo, observe: esse valor deve ser menor que o tempo mínimo do áudio no conjunto de treinamento!
batch_size : A quantidade de dados carregados na GPU para uma única sessão de treinamento pode ser ajustada para um tamanho menor que a capacidade de memória de vídeo.
timesteps : o número total de etapas no modelo de difusão, que padrão é 1000.
k_step_max : o treinamento só pode treinar k_step_max etapa Difusão para economizar tempo de treinamento, observe que o valor deve ser menor que timesteps , 0 é treinar todo o modelo de difusão, observe: se você não treinar todo o modelo de difusão não poderá usar Somente_diffusion!
nsf-hifigan
nsf-snake-hifigan
python preprocess_hubert_f0.py --f0_predictor dioF0_Predictor tem as seguintes opções
crepe
dio
pm
harvest
rmvpe
fcpe
Se o conjunto de treinamento for muito barulhento, é recomendável usar crepe para lidar com F0
Se o parâmetro F0_Predictor for omitido, o valor padrão será rmvpe
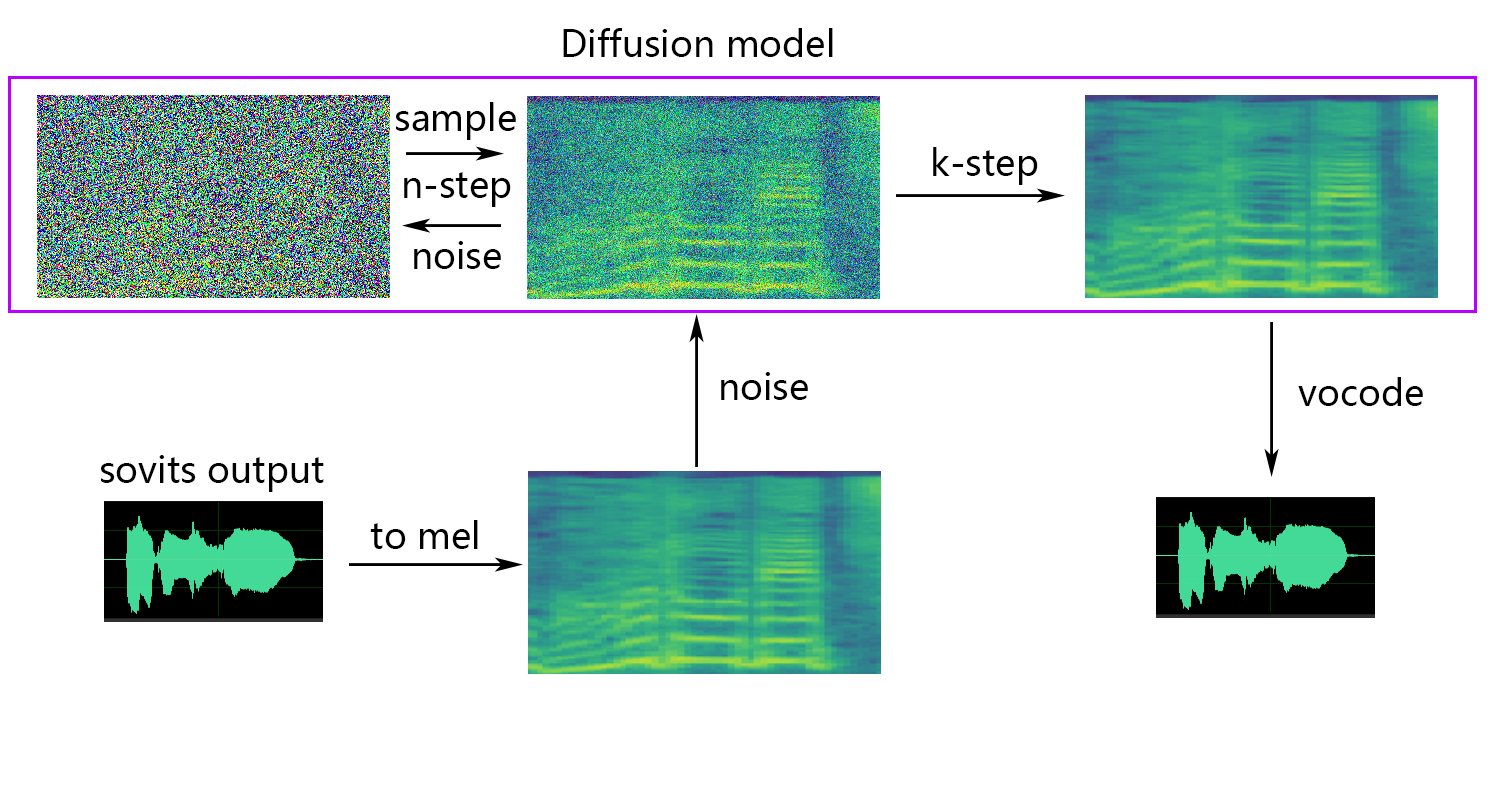
Se você deseja difusão superficial (opcional), precisa adicionar o parâmetro --use_diff , por exemplo:
python preprocess_hubert_f0.py --f0_predictor dio --use_diffAcelerar o pré -processo
Se o seu conjunto de dados for bastante grande, você pode aumentar o param --num_processes como esse:
python preprocess_hubert_f0.py --f0_predictor dio --num_processes 8Todo o trabalhador será atribuído a GPU diferente se você tiver mais de uma GPUs.
Após concluir as etapas acima, o diretório do conjunto de dados conterá os dados pré -processados e a pasta DataSET_RAW pode ser excluída.
python train.py -c configs/config.json -m 44kSe a função de difusão superficial for necessária, o modelo de difusão precisará ser treinado. O método de treinamento do modelo de difusão é o seguinte:
python train_diff.py -c configs/diffusion.yaml Durante o treinamento, os arquivos do modelo serão salvos no logs/44k , e o modelo de difusão será salvo para logs/44k/diffusion
Use inference_main.py
# Example
python inference_main.py -m " logs/44k/G_30400.pth " -c " configs/config.json " -n "君の知らない物語-src.wav " -t 0 -s " nen "Parâmetros necessários:
-m | --model_path : caminho para o modelo.-c | --config_path : caminho para o arquivo de configuração.-n | --clean_names : Uma lista de nomes de arquivos WAV localizados na pasta raw .-t | --trans : mudança de afinação, suporta valores positivos e negativos (semitóis).-s | --spk_list : selecione o ID do alto-falante a ser usado para conversão.-cl | --clip : o corte de áudio forçado, definido como 0 para desativar (padrão), configurando-o como um valor diferente de zero (duração em segundos) para ativar.Parâmetros opcionais: consulte a próxima seção
-lg | --linear_gradient : o comprimento cruzado desbotamento de duas fatias de áudio em segundos. Se houver uma voz descontínua após o fatiamento forçado, você poderá ajustar esse valor. Caso contrário, é recomendável usar o valor padrão de 0.-f0p | --f0_predictor : selecione um preditor F0, as opções são crepe , pm , dio , harvest , rmvpe , fcpe , o valor padrão é pm (nota: f0 sinuca será habilitada ao usar crepe )-a | --auto_predict_f0 : previsão automática de afinação, não permita isso ao converter vozes de canto, pois pode causar sérios problemas de afinação.-cm | --cluster_model_path : modelo de cluster ou caminho de recuperação de recursos, se deixado em branco, ele será definido automaticamente como o caminho padrão desses modelos. Se não houver um cluster de treinamento ou recuperação de recursos, preencha à vontade.-cr | --cluster_infer_ratio : a proporção do esquema de cluster ou recuperação de recursos varia de 0 a 1. Se não houver um modelo de cluster de treinamento ou recuperação de recursos, o padrão será 0.-eh | --enhance : Se você deve usar o NSF_Hifigan intensificador, essa opção tem um efeito de melhorar a qualidade do som para alguns modelos com poucos conjuntos de treinamento, mas tem efeito negativo em modelos bem treinados, por isso é desativado por padrão.-shd | --shallow_diffusion : se deve usar difusão superficial, que pode resolver alguns problemas de som elétricos após o uso. Esta opção está desativada por padrão. Quando esta opção estiver ativada, o NSF_hifigan intensificador será desativado-usm | --use_spk_mix : se deve usar a fusão dinâmica de voz-lea | --loudness_envelope_adjustment : O ajuste do envelope de volume da fonte de entrada em relação à taxa de fusão do envelope de sonoridade de saída. Quanto mais perto de 1, mais o envelope de sonoridade de saída é usado-fr | --feature_retrieval : Se você deve usar a recuperação de recursos se o modelo de agrupamento for usado, ele será desativado e os parâmetros cm e cr se tornarão o caminho do índice e a taxa de mistura da recuperação de recursosConfigurações de difusão superficial:
-dm | --diffusion_model_path : Caminho do modelo de difusão-dc | --diffusion_config_path : Difusão Caminho de arquivo de configuração-ks | --k_step : Quanto maior o número de k_steps, mais próximo é o resultado do modelo de difusão. O padrão é 100-od | --only_diffusion : se deve usar apenas o modo de difusão, que não carrega o modelo SOVITS para usar apenas a inferência do modelo de difusão-se | --second_encoding : que envolve a aplicação de uma codificação adicional ao áudio original antes da difusão superficial. Essa opção pode produzir resultados variados - às vezes positivos e às vezes negativos. Se inferir usando o codificador de fala whisper-ppg , você precisará definir --clip como 25 e -lg para 1. Caso contrário, ele não inferirá adequadamente.
Se você estiver satisfeito com os resultados anteriores, ou se não sentir que entende o que se segue, poderá ignorá -lo e isso não terá efeito no uso do modelo. O impacto dessas configurações opcionais mencionado é relativamente pequeno e, embora possa ter algum impacto em conjuntos de dados específicos, na maioria dos casos a diferença pode não ser significativa.
Durante o treinamento do modelo 4.0, um preditor de F0 também é treinado, o que permite a previsão automática de pitch durante a conversão de voz. No entanto, se os resultados não forem satisfatórios, a previsão de afinação manual poderá ser usada. Observe que, ao converter vozes de canto, é aconselhado a não ativar esse recurso, pois pode causar uma mudança significativa de tom.
auto_predict_f0 como true in inference_main.py .Introdução: O esquema de cluster implementado neste modelo tem como objetivo reduzir o vazamento de timbre e aprimorar a semelhança do modelo treinado com o timbre do alvo, embora o efeito não seja muito pronunciado. No entanto, confiar apenas no agrupamento pode reduzir a clareza do modelo e torná -lo menos distinto. Portanto, um método de fusão é adotado neste modelo para controlar o equilíbrio entre as abordagens de agrupamento e não agrupamento. Isso permite o ajuste manual do trade-off entre "soar como o timbre do alvo" e "têm uma enunciação clara" para encontrar um equilíbrio ideal.
Não são necessárias alterações nas etapas existentes. Basta treinar um modelo adicional de agrupamento, que incorre em custos de treinamento relativamente baixos.
python cluster/train_cluster.py . O modelo de saída será salvo em logs/44k/kmeans_10000.pt .python cluster/train_cluster.py --gpucluster_model_path em inference_main.py . Se não for especificado, o padrão é logs/44k/kmeans_10000.pt .cluster_infer_ratio em inference_main.py , onde 0 significa não usar o clustering, 1 significa apenas usar o cluster e geralmente 0.5 é suficiente.Introdução: Como no esquema de cluster, o vazamento de timbre pode ser reduzido, a enunciação é um pouco melhor do que o agrupamento, mas reduzirá a velocidade de inferência. Ao empregar o método de fusão, torna-se possível controlar linearmente o equilíbrio entre a recuperação de recursos e a recuperação não-rumores, permitindo o ajuste fino da proporção desejada.
python train_index.py -c configs/config.json A saída do modelo estará em logs/44k/feature_and_index.pkl
--feature_retrieval precisa ser formulado primeiro e o modo de cluster muda automaticamente para o modo de recuperação de recursos.cluster_model_path em inference_main.py . Se não for especificado, o padrão é logs/44k/feature_and_index.pkl .cluster_infer_ratio em inference_main.py , onde 0 significa não usar a recuperação de recursos, 1 significa apenas usar a recuperação de recursos e geralmente 0.5 é suficiente. O modelo gerado contém dados necessários para treinamento adicional. Se você confirmar que o modelo é final e não será usado em treinamento adicional, é seguro remover esses dados para obter um tamanho de arquivo menor (cerca de 1/3).
# Example
python compress_model.py -c= " configs/config.json " -i= " logs/44k/G_30400.pth " -o= " logs/44k/release.pth " Consulte o arquivo webUI.py para obter a mistura estável timbre do recurso de gadget/laboratório.
Introdução: Esta função pode combinar vários modelos em um modelo (combinação convexa ou combinação linear de múltiplos parâmetros do modelo) para criar voz mista que não existe na realidade
Observação:
model em config.json de todos os modelos a serem misturados são iguais Consulte o arquivo spkmix.py para uma introdução à mistura dinâmica do timbre
Regras de escrita de rastreamento de mix de personagens:
ID da função: [[Horário de início 1, horário de término 1, valor inicial 1, valor inicial 1], [Horário de início 2, horário de término 2, valor inicial 2]]
O horário de início deve ser o mesmo do horário final do anterior. O primeiro horário de início deve ser 0, e o último horário deve ser 1 (o tempo varia de 0 a 1).
Todas as funções devem ser preenchidas. Para funções não utilizadas, preencha [[0., 1., 0., 0.]]
O valor da fusão pode ser preenchido arbitrariamente, e a mudança linear do valor inicial para o valor final dentro do período de tempo especificado. O
A combinação linear interna será automaticamente garantida como 1 (condição de combinação convexa), para que possa ser usada com segurança
Use o parâmetro --use_spk_mix ao raciocinar para ativar a mistura dinâmica do timbre
Use onnx_export.py
checkpoints e abra -acheckpoints como pasta do projeto, nomeando -a após o seu projeto, por exemplo, aziplayermodel.pth , o arquivo de configuração como config.json e coloque -os na pasta aziplayer que você acabou de criar"NyaruTaffy" em path = "NyaruTaffy" em onnx_export.py para o nome do seu projeto, path = "aziplayer" (onnx_export_speaker_mix faz com que você possa misturar a voz do alto -falante)model.onnx será gerado na pasta do projeto, que é o modelo exportado.NOTA: Para os modelos Hubert Onnx, use os modelos fornecidos pela Moess. Atualmente, eles não podem ser exportados por conta própria (Hubert em Fairseq possui muitos operadores não suportados e coisas que envolvem constantes que podem causar erros ou resultar em problemas com a forma de entrada/saída e resultados quando exportados.)
| Url | Designação | Título | Fonte de implementação |
|---|---|---|---|
| 2106.06103 | Vits (Synthesizer) | AutoEncoder condicional de variação com aprendizado adversário para o texto de ponta a ponta a fala | JAYWALNUT310/VITS |
| 2111.02392 | SoftVC (codificador de fala) | Uma comparação de unidades de fala discreta e suave para melhorar a conversão de voz | Bshall/Hubert |
| 2204.09224 | Contentvec (codificador de fala) | Contentvec: uma representação de fala auto-supervisionada aprimorada por desvendar palestrantes | Auspicious3000/ContentVec |
| 2212.04356 | Whisper (codificador de fala) | Reconhecimento robusto de fala por meio de supervisão fraca em larga escala | Openai/sussurro |
| 2110.13900 | Wavlm (codificador de fala) | Wavlm: pré-treinamento auto-supervisionado em larga escala para processamento de fala de pilha completa | Microsoft/Unilm/Wavlm |
| 2305.17651 | Dphubert (codificador de fala) | Dphubert: Destilação e poda conjunta de modelos de fala auto-supervisionados | PYF98/DPHUBERT |
| Doi: 10.21437/interSpeech.2017-68 | Harvest (F0 Predictor) | Colheita: um estimador de frequência fundamental de alto desempenho dos sinais de fala | mmorise/mundo/colheita |
| AES35-000039 | DIO (Preditor F0) | Método de estimativa F0 rápido e confiável com base na extração de período da vibração da dobra vocal da voz e fala cantando | mmorise/mundo/dio |
| 8461329 | Crepe (preditor F0) | Crepe: uma representação convolucional para estimativa de afinação | Maxrmorrison/Torchcrepe |
| Doi: 10.1016/j.wocn.2018.07.001 | Parselmouth (preditor de f0) | Apresentando Parselmouth: uma interface Python para Praat | Yannickjadoul/Parselmouth |
| 2306.15412V2 | RMVPE (F0 Predictor) | RMVPE: um modelo robusto para estimativa de afinação vocal na música polifônica | Sonho-Alto/RMVPE |
| 2010.05646 | Hifigan (vocoder) | HIFI-GAN: Redes adversárias generativas para síntese de fala eficiente e de alta fidelidade | jik876/hifi-gan |
| 1810.11946 | NSF (vocoder) | Modelo de forma de onda baseada em filtro de origem neural para síntese estatística de fala paramétrica | OpenVPI/DIFFSINGER/MODULES/NSF_HIFIGAN |
| 2006.08195 | Cobra (vocoder) | As redes neurais não aprendem funções periódicas e como corrigi -las | Edwarddixon/Snake |
| 2105.02446V3 | Difusão superficial (pós -processamento) | Diffsinger: Síntese de voz cantando via mecanismo de difusão superficial | CNCHTU/difusão-SVC |
| K-means | Recurso K-Means Clustering (pré-processamento) | Alguns métodos para classificação e análise de observações multivariadas | Este repo |
| Recuperação de Topk (pré -processamento) | Conversão de voz baseada em recuperação | RVC-Projeto/Recuperação-Voice-Conversão-Webui | |
| sussurro ppg | sussurro ppg | Playvoice/sussurro_ppg | |
| bigvgan | bigvgan | PlayVoice/SO-VITS-SVC-5.0 |
Por alguma razão, o autor excluiu o repositório original. Devido à negligência dos membros da organização, a lista de colaboradores foi liberada porque todos os arquivos foram diretamente reiniciados a esse repositório no início da reconstrução deste repositório. Agora adicione uma lista de colaboradores anterior ao readme.md.
Alguns membros não foram listados de acordo com seus desejos pessoais.
Misto | Xiaomiku01 | しぐれ | Tomogasukunai | Plachtaa | ZD 小达 | 凍聲響世 |
任何组织或者个人不得以丑化、污损 , 或者利用信息技术手段伪造等方式侵害他人的肖像权。未经肖像权人同意 , 不得制作、使用、公开肖像权人的肖像 , 但是法律另有规定的除外。未经肖像权人同意 , 肖像作品权利人不得以发表、复制、发行、出租、展览等方式使用或者公开肖像权人的肖像。对自然人声音的保护 , 参照适用肖像权保护的有关规定。
【名誉权】民事主体享有名誉权。任何组织或者个人不得以侮辱、诽谤等方式侵害他人的名誉权。
【作品侵害名誉权】行为人发表的文学、艺术作品以真人真事或者特定人为描述对象 , 含有侮辱、诽谤内容 , 侵害他人名誉权的 , 受害人有权依法请求该行为人承担民事责任。行为人发表的文学、艺术作品不以特定人为描述对象 , 仅其中的情节与该特定人的情况相似的 , 不承担民事责任。


