so vits svc
1.0.0
영어 |中文简体
이 제한된 시간 업데이트 라운드 업데이트가 끝나고 창고가 아치형 상태에 들어갈 것입니다.
Visible F0 편집기, 스피커 믹스 타임 라인 편집기 및 기타 기능 (Onnx 모델이 사용되는 위치)을 포함하는 스튜디오 : Moevoicestudio
사용자 인터페이스가 크게 향상된 포크 : 34J/SO-VITS-SVC-FORK
클라이언트는 실시간 변환을 지원합니다 : W-Okada/Voice-Changer
이 프로젝트는 텍스트 음성 (TTS)이 아닌 노래 음성 변환 (SVC)에 중점을두기 때문에 VITS와 근본적으로 다릅니다. 이 프로젝트에서는 TTS 기능이 지원되지 않으며 VITS는 SVC 작업을 수행 할 수 없습니다. 이 두 프로젝트에 사용 된 모델은 서로 바꿀 수 없거나 보편적으로 적용 할 수 없다는 점에 유의해야합니다.
이 프로젝트의 목적은 개발자가 사랑하는 애니메이션 캐릭터가 노래 작업을 수행하도록하는 것이 었습니다. 개발자의 의도는 가상의 인물에만 초점을 맞추고 실제 개인과 관련이있는 모든 사람들과 관련된 모든 것이 개발자의 원래 의도에서 벗어난 것을 피하는 것이 었습니다.
이 프로젝트는 오픈 소스, 오프라인 노력 및 SVCDevelopteam의 모든 구성원과 관련된 다른 개발자 및 관리자 (이하 기여자라고 함)는 프로젝트를 통제 할 수 없습니다. 기고자는 데이터 세트 추출, 데이터 세트 처리, 컴퓨팅 지원, 교육 지원, 추론 등을 포함하되 이에 국한되지 않는 조직이나 개인에게 어떠한 형태의 지원도 제공하지 않았습니다. 기고자는 사용자가 프로젝트를 활용하는 목적을 알 수 없으며 알 수 없습니다. 따라서이 프로젝트의 교육을 통해 제작 된 AI 모델과 합성 오디오는 기고자와 관련이 없습니다. 사용에서 발생하는 모든 문제 나 결과는 사용자의 유일한 책임입니다.
이 프로젝트는 완전히 오프라인으로 실행되며 사용자 정보를 수집하거나 사용자 입력 데이터를 수집하지 않습니다. 따라서이 프로젝트의 기여자는 모든 사용자 입력 및 모델을 인식하지 않으므로 사용자 입력에 대해 책임을지지 않습니다.
이 프로젝트는 프레임 워크 역할을하며 그 자체로 음성 합성 기능을 가지고 있지 않습니다. 모든 기능은 사용자가 모델을 독립적으로 훈련시켜야합니다. 또한이 프로젝트는 모델과 함께 번들로 제공되지 않으며 2 차 분산 프로젝트는이 프로젝트의 기고자와 무관합니다.
노래 음성 변환 모델은 SoftVC 컨텐츠 인코더를 사용하여 소스 오디오에서 음성 기능을 추출합니다. 이 기능 벡터는 텍스트 기반 중간 표현으로 변환 할 필요없이 직접 VIT로 공급됩니다. 결과적으로 원래 오디오의 피치와 억양이 보존됩니다. 한편, 보코더는 NSF Hifigan으로 대체되어 사운드 중단 문제를 해결했습니다.
config.json 파일을 수정할 수 있습니다. speech_encoder 필드를 아래와 같이 "모델"섹션에 추가하십시오. "model": {
.........
"ssl_dim": 256,
"n_speakers": 200,
"speech_encoder":"vec256l9"
}
테스트를 바탕으로 프로젝트가 Python 3.8.9 에서 안정적으로 실행된다고 판단했습니다.
아래 목록에서 하나의 인코더를 선택해야합니다.
vec768l12 및 vec256l9 에는 인코더가 필요합니다
pretrain 디렉토리 아래에 배치하십시오또는 크기는 199MB에 불과하지만 동일한 효과가있는 다음 ContentVec을 다운로드하십시오.
checkpoint_best_legacy_500.pt 로 변경하고 pretrain 디렉토리에 배치하십시오. # contentvec
wget -P pretrain/ https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/hubert_base.pt -O checkpoint_best_legacy_500.pt
# Alternatively, you can manually download and place it in the hubert directory pretrain 디렉토리 아래에 배치하십시오 whisper-ppg 적합합니다whisper-ppg-large 적합합니다pretrain 디렉토리 아래에 배치하십시오 pretrain 디렉토리 아래에 배치하십시오 pretrain 디렉토리 아래에 배치하십시오 wavlmbase+ 에 적합합니다pretrain 디렉토리 아래에 배치하십시오 pretrain 디렉토리 아래에 배치하십시오 미리 훈련 된 모델 파일 : G_0.pth D_0.pth
logs/44k 디렉토리 아래에 배치하십시오 확산 모델 사전 조정 기본 모델 파일 : model_0.pt
logs/44k/diffusion 디렉토리에 넣으십시오SVC-Develop-Team (TBD) 또는 다른 곳에서 Sovits 미리 훈련 된 모델을 얻으십시오.
확산 모델 참조 확산 -SVC 확산 모델. 미리 훈련 된 확산 모델은 DDSP-SVC와 보편적입니다. 확산 -SVC의 리포로 이동하여 미리 훈련 된 확산 모델을 얻을 수 있습니다.
사전 예방 모델은 일반적으로 저작권 문제를 제기하지 않지만 경계를 유지하는 것이 필수적입니다. 저자와 미리 상담하거나 설명을 신중하게 검토하여 모델의 허용 가능한 사용을 확인하는 것이 좋습니다. 이를 통해 이용에 관한 지정된 지침 또는 제한을 준수하는 데 도움이됩니다.
NSF-HIFIGAN enhancer 또는 shallow diffusion 사용하는 경우 미리 훈련 된 NSF-Hifigan 모델을 다운로드해야합니다.
pretrain/nsf_hifigan 디렉토리 아래에 배치하십시오. # nsf_hifigan
wget -P pretrain/ https://github.com/openvpi/vocoders/releases/download/nsf-hifigan-v1/nsf_hifigan_20221211.zip
unzip -od pretrain/nsf_hifigan pretrain/nsf_hifigan_20221211.zip
# Alternatively, you can manually download and place it in the pretrain/nsf_hifigan directory
# URL: https://github.com/openvpi/vocoders/releases/tag/nsf-hifigan-v1 rmvpe F0 예측 변수를 사용하는 경우 사전 훈련 된 RMVPE 모델을 다운로드해야합니다.
rmvpe.zip model.pt 파일의 이름을 rmvpe.pt 로 바꾸고 pretrain 디렉토리 아래에 배치하십시오.pretrain 디렉토리 아래에 배치하십시오 FCPE (Fast Context-Base Pitch Estimator)는 실시간 음성 변환을 위해 설계된 전용 F0 예측 변수이며 향후 Sovits 실시간 음성 변환을위한 선호되는 F0 예측 변수가 될 것입니다.
fcpe F0 예측기를 사용하는 경우 사전 훈련 된 FCPE 모델을 다운로드해야합니다.
pretrain 디렉토리 아래에 배치하십시오 다음 파일 구조와 함께 dataset_raw 디렉토리에 데이터 세트를 배치하기 만하면됩니다.
dataset_raw
├───speaker0
│ ├───xxx1-xxx1.wav
│ ├───...
│ └───Lxx-0xx8.wav
└───speaker1
├───xx2-0xxx2.wav
├───...
└───xxx7-xxx007.wav
각 오디오 파일의 이름 형식에 대한 구체적인 제한 사항은 없습니다 ( 000001.wav ~ 999999.wav 와 같은 규칙 명명도 유효 함). 파일 유형은 'wav' '이어야합니다.
아래에 표시된대로 스피커 이름을 사용자 정의 할 수 있습니다.
dataset_raw
└───suijiSUI
├───1.wav
├───...
└───25788785-20221210-200143-856_01_(Vocals)_0_0.wav
교육 또는 사전 처리 중에 비디오 메모리 오버플로를 피하려면 오디오 클립의 길이를 제한하는 것이 좋습니다. 오디오를 "5s -15s"의 길이로 자르는 것이 좋습니다. 그러나 약간 긴 시간이 허용되지만 과도하게 긴 클립은 torch.cuda.OutOfMemoryError 와 같은 문제를 일으킬 수 있습니다.
슬라이싱 프로세스를 용이하게하려면 오디오 슬라이서 GUI 또는 오디오 슬라이서 클리를 사용할 수 있습니다.
일반적으로 Minimum Interval 만 조정하면됩니다. 음성 오디오의 경우 기본값은 일반적으로 충분하지만 노래를 부르는 경우 특정 요구 사항에 따라 약 100 또는 50 으로 조정할 수 있습니다.
슬라이스 후에는 지나치게 길거나 너무 짧은 오디오 클립을 제거하는 것이 좋습니다.
훈련에 Whisper-PPG 인코더를 사용하는 경우 오디오 클립이 30 대보다 짧아야합니다.
python resample.py 이 프로젝트에는 리 샘플링, 모노 및 음량 일치를위한 RESAPLE.PY 스크립트가 있지만 기본 음량 일치는 0DB와 일치하는 것입니다. 이로 인해 음질이 손상 될 수 있습니다. Python의 음량 일치 패키지 Pyloudnorm은 레벨을 제한하지 않지만 Sonic Boom으로 이어질 수 있습니다. 따라서 adobe audition for Loudness Matching과 같은 전문적인 사운드 처리 소프트웨어를 사용하는 것이 좋습니다. 음량 일치에 이미 다른 소프트웨어를 사용하고 있다면 매개 변수 -skip_loudnorm 실행 명령에 추가하십시오.
python resample.py --skip_loudnormpython preprocess_flist_config.py --speech_encoder vec768l12speech_encoder에는 다음 옵션이 있습니다
vec768l12
vec256l9
hubertsoft
whisper-ppg
cnhubertlarge
dphubert
whisper-ppg-large
wavlmbase+
speech_encoder 인수가 생략되면 기본값은 vec768l12 입니다.
음량 임베딩을 사용하십시오
음량 임베딩을 활성화하려면 --vol_aug 추가하십시오.
python preprocess_flist_config.py --speech_encoder vec768l12 --vol_aug음량 임베딩을 활성화 한 후, 훈련 된 모델은 입력 소스의 음량과 일치합니다. 그렇지 않으면 훈련 세트의 음량과 일치합니다.
keep_ckpts : 훈련 중에 이전 모델 수를 유지하십시오. 그들 모두를 유지하려면 0 으로 설정하십시오. 기본값은 3 입니다.
all_in_mem : 모든 데이터 세트를 RAM에로드하십시오. 일부 플랫폼의 디스크 IO가 너무 낮고 시스템 메모리가 데이터 세트보다 훨씬 큰 경우 활성화 할 수 있습니다.
batch_size : 단일 교육 세션을 위해 GPU에로드 된 데이터의 양은 GPU 메모리 용량보다 낮은 크기로 조정할 수 있습니다.
vocoder_name : 보코더를 선택하십시오. 기본값은 nsf-hifigan 입니다.
cache_all_data : 모든 데이터 세트를 RAM에로드하십시오. 일부 플랫폼의 디스크 IO가 너무 낮고 시스템 메모리가 데이터 세트보다 훨씬 큰 경우 활성화 할 수 있습니다.
duration : 훈련 중 오디오 슬라이스 기간은 비디오 메모리의 크기에 따라 조정할 수 있습니다. 참고 :이 값은 교육 세트에서 오디오의 최소 시간보다 적어야합니다!
batch_size : 단일 교육 세션을 위해 GPU에로드 된 데이터의 양은 비디오 메모리 용량보다 낮은 크기로 조정할 수 있습니다.
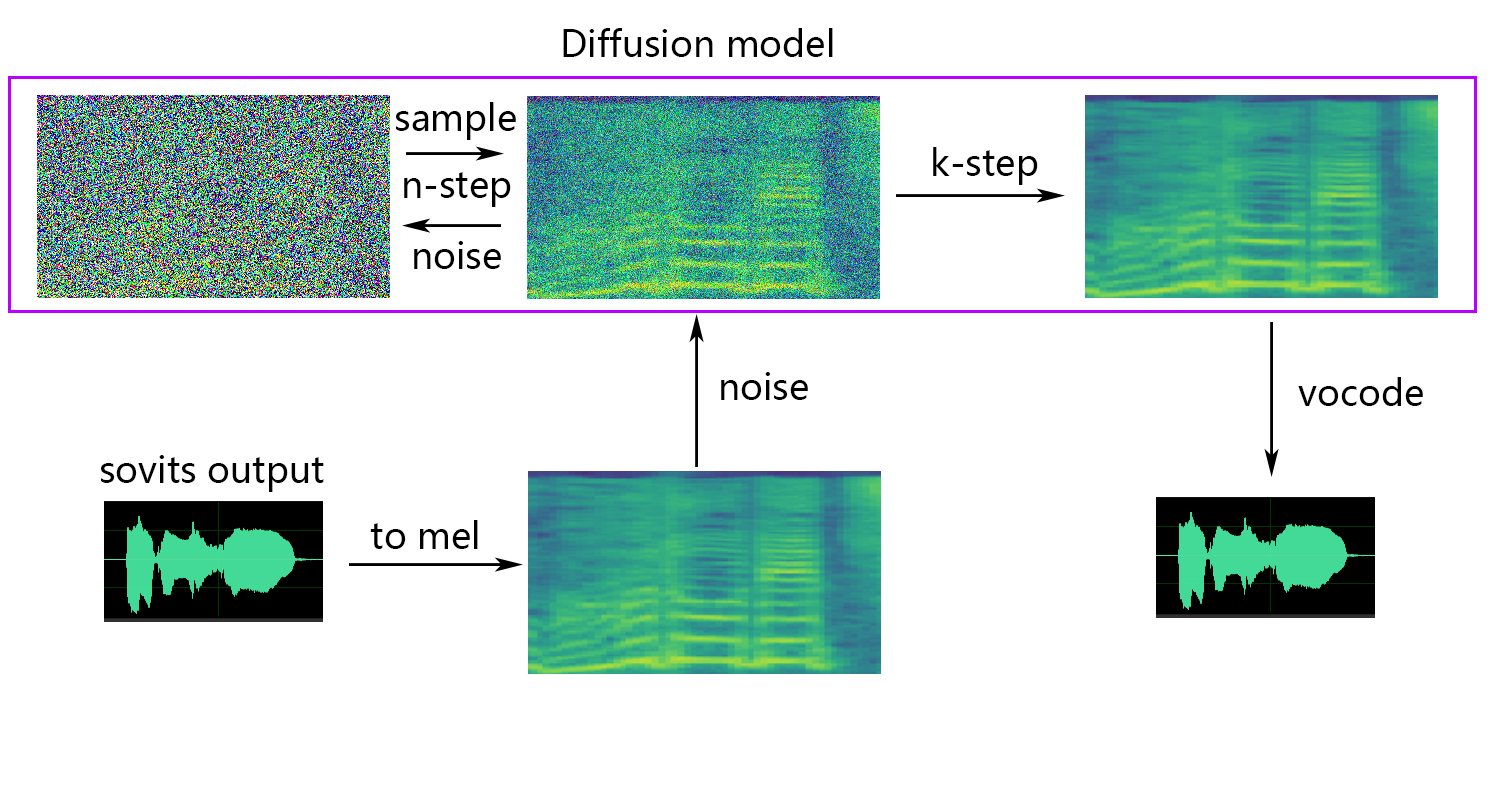
timesteps : 확산 모델의 총 단계 수는 기본값 1000입니다.
k_step_max : 교육 시간을 절약하기 위해 k_step_max 단계 확산 만 훈련 할 수 있습니다. 값은 timesteps 보다 적어야하며 0은 전체 확산 모델을 훈련시키는 것입니다. 참고 : 전체 확산 모델을 훈련시키지 않으면 사용할 수 없습니다. 유일한 _diffusion!
nsf-hifigan
nsf-snake-hifigan
python preprocess_hubert_f0.py --f0_predictor dioF0_Predictor에는 다음 옵션이 있습니다
crepe
dio
pm
harvest
rmvpe
fcpe
교육 세트가 너무 시끄 럽면 crepe 사용하여 F0을 처리하는 것이 좋습니다.
f0_predictor 매개 변수가 생략되면 기본값은 rmvpe 입니다.
얕은 확산 (선택 사항)을 원한다면 --use_diff 매개 변수를 추가해야합니다.
python preprocess_hubert_f0.py --f0_predictor dio --use_diff전처리 속도를 높이십시오
데이터 세트가 상당히 크면 다음과 같은 Param --num_processes 늘릴 수 있습니다.
python preprocess_hubert_f0.py --f0_predictor dio --num_processes 8둘 이상의 GPU가 있으면 모든 작업자가 다른 GPU에 할당됩니다.
위의 단계를 완료하면 데이터 세트 디렉토리에는 전처리 데이터가 포함되며 DataSet_Raw 폴더를 삭제할 수 있습니다.
python train.py -c configs/config.json -m 44k얕은 확산 기능이 필요한 경우 확산 모델을 훈련해야합니다. 확산 모델 훈련 방법은 다음과 같습니다.
python train_diff.py -c configs/diffusion.yaml 훈련 중에 모델 파일은 logs/44k 에 저장되고 확산 모델은 logs/44k/diffusion 으로 저장됩니다.
inference_main.py를 사용하십시오
# Example
python inference_main.py -m " logs/44k/G_30400.pth " -c " configs/config.json " -n "君の知らない物語-src.wav " -t 0 -s " nen "필수 매개 변수 :
-m | --model_path : 모델로가는 경로.-c | --config_path : 구성 파일의 경로.-n | --clean_names : raw 폴더에 위치한 WAV 파일 이름 목록.-t | --trans : 피치 시프트, 양수 및 음수 (세미 톤) 값을 지원합니다.-s | --spk_list : 변환에 사용할 스피커 ID를 선택하십시오.-cl | --clip : 강제 오디오 클리핑, 0으로 설정하여 비활성화 (기본값)로 설정하여 사용하여 0이 아닌 값 (초 기간)으로 설정합니다.선택적 매개 변수 : 다음 섹션을 참조하십시오
-lg | --linear_gradient : 2 초 만에 두 개의 오디오 슬라이스의 크로스 페이드 길이. 강제 슬라이싱 후 불연속 음성이있는 경우이 값을 조정할 수 있습니다. 그렇지 않으면 기본값 0을 사용하는 것이 좋습니다.-f0p | --f0_predictor : F0 예측 변수 선택, 옵션은 crepe , pm , dio , harvest , rmvpe , fcpe , 기본값은 pm 입니다 (참고 : F0 평균 풀링은 crepe 사용할 때 활성화됩니다).-a | --auto_predict_f0 : 자동 피치 예측, 노래 목소리를 변환 할 때 심각한 피치 문제를 일으킬 수 있으므로이를 활성화하지 마십시오.-cm | --cluster_model_path : 클러스터 모델 또는 기능 검색 인덱스 경로는 비워두면 이러한 모델의 기본 경로로 자동으로 설정됩니다. 훈련 클러스터 나 기능 검색이없는 경우 마음대로 작성하십시오.-cr | --cluster_infer_ratio : 클러스터링 체계 또는 기능 검색 범위의 비율은 0에서 1까지입니다. 훈련 클러스터링 모델이나 기능 검색이 없으면 기본값은 0입니다.-eh | --enhance : NSF_Hifigan Enhancer 사용 여부에 관계 없이이 옵션은 교육 세트가 거의없는 일부 모델의 음질 향상에 영향을 미치지 만 잘 훈련 된 모델에는 부정적인 영향을 미치므로 기본적으로 비활성화됩니다.-shd | --shallow_diffusion : 얕은 확산 사용 여부, 사용 후 전기 사운드 문제를 해결할 수 있습니다. 이 옵션은 기본적으로 비활성화됩니다. 이 옵션이 활성화되면 NSF_Hifigan Enhancer가 비활성화됩니다.-usm | --use_spk_mix : 동적 음성 퓨전 사용 여부-lea | --loudness_envelope_adjustment : 출력 음량 봉투의 융합 비율과 관련하여 입력 소스의 음량 봉투 조정. 1에 가까울수록 출력 음량 봉투가 더 많이 사용됩니다.-fr | --feature_retrieval : 기능 검색을 사용하든 클러스터링 모델을 사용하는 경우 비활성화되며 cm 및 cr 매개 변수는 기능 검색의 인덱스 경로 및 혼합 비율이됩니다.얕은 확산 설정 :
-dm | --diffusion_model_path : 확산 모델 경로-dc | --diffusion_config_path : 확산 구성 파일 경로-ks | --k_step : k_step의 수가 클수록 확산 모델의 결과에 가까워집니다. 기본값은 100입니다-od | --only_diffusion : 확산 모델을 사용하여 Sovits 모델을로드하지 않는 확산 모드 만 사용할지 여부 확산 모델 추론-se | --second_encoding : 얕은 확산 전에 원래 오디오에 추가 인코딩을 적용하는 것과 관련이 있습니다. 이 옵션은 다양한 결과를 얻을 수 있습니다. 때로는 긍정적이고 때로는 부정적입니다. whisper-ppg Speech Encoder를 사용하는 추론이있는 경우 --clip 25 및 -lg 로 설정해야합니다. 그렇지 않으면 제대로 추론하지 않습니다.
이전 결과에 만족하거나 다음과 같은 결과를 이해하지 못한 경우 건너 뛸 수 있으며 모델 사용에 영향을 미치지 않습니다. 언급 된 이러한 선택적 설정의 영향은 상대적으로 작으며 특정 데이터 세트에 약간의 영향을 줄 수 있지만 대부분의 경우 차이가 중요하지 않을 수 있습니다.
4.0 모델을 훈련하는 동안 F0 예측기도 훈련되어 음성 변환 중에 자동 피치 예측이 가능합니다. 그러나 결과가 만족스럽지 않으면 수동 피치 예측을 대신 사용할 수 있습니다. 노래 목소리를 변환 할 때는이 기능이 상당한 피치 이동을 일으킬 수 있으므로이 기능을 사용하지 않는 것이 좋습니다.
inference_main.py 에서 auto_predict_f0 true 로 설정하십시오.소개 :이 모델에서 구현 된 클러스터링 체계는 음색 누출을 줄이고 훈련 된 모델의 대상 음색과 유사성을 향상시키는 것을 목표로하지만 효과는 그다지 뚜렷하지 않을 수 있습니다. 그러나 클러스터링에만 의존하면 모델의 명확성을 줄이고 덜 구별 할 수 있습니다. 따라서이 모델에서 퓨전 방법이 채택되어 클러스터링 및 비 클러스터링 접근 방식 사이의 균형을 제어합니다. 이를 통해 "대상의 음색과 같은 사운드"와 "명확한 발음"사이의 트레이드 오프를 수동으로 조정하여 최적의 균형을 찾을 수 있습니다.
기존 단계에서 변경이 필요하지 않습니다. 추가 클러스터링 모델을 훈련 시키면 비교적 낮은 교육 비용이 발생합니다.
python cluster/train_cluster.py 실행하십시오. 출력 모델은 logs/44k/kmeans_10000.pt 로 저장됩니다.python cluster/train_cluster.py --gpu 실행하여 GPU를 사용하여 교육을받을 수 있습니다.inference_main.py 에서 cluster_model_path 지정하십시오. 지정되지 않은 경우 기본값은 logs/44k/kmeans_10000.pt 입니다.inference_main.py 에서 cluster_infer_ratio 지정합니다. 여기서 0 클러스터링을 전혀 사용하지 않는 것을 의미하며 1 클러스터링 만 사용하는 것을 의미하며 일반적으로 0.5 충분합니다.소개 : 클러스터링 체계와 마찬가지로 음색 누출이 줄어들 수 있으며, 발음은 클러스터링보다 약간 낫지 만 추론 속도를 줄입니다. 퓨전 방법을 사용함으로써, 피처 검색과 비 기능 검색 사이의 균형을 선형 제어하여 원하는 비율을 미세 조정할 수있게됩니다.
python train_index.py -c configs/config.json 모델의 출력은 logs/44k/feature_and_index.pkl 로됩니다
--feature_retrieval 먼저 공식화해야하고 클러스터링 모드는 기능 검색 모드로 자동 전환됩니다.inference_main.py 에서 cluster_model_path 지정하십시오. 지정되지 않은 경우 기본값은 logs/44k/feature_and_index.pkl 입니다.inference_main.py 에서 cluster_infer_ratio 지정합니다. 여기서 0 기능 검색을 전혀 사용하지 않는 것을 의미하며 1 기능 검색 만 사용하는 것을 의미하며 일반적으로 0.5 충분합니다. 생성 된 모델에는 추가 교육에 필요한 데이터가 포함되어 있습니다. 모델이 최종적이고 추가 교육에 사용되지 않는지 확인하면 파일 크기가 작은 파일 크기 (약 1/3)를 얻기 위해이 데이터를 제거하는 것이 안전합니다.
# Example
python compress_model.py -c= " configs/config.json " -i= " logs/44k/G_30400.pth " -o= " logs/44k/release.pth " 가제트/랩 기능의 안정적인 음색 혼합은 webUI.py 파일을 참조하십시오.
소개 :이 기능은 여러 모델을 하나의 모델 (볼록 조합 또는 다중 모델 매개 변수의 선형 조합)으로 결합하여 실제로 존재하지 않는 혼합 음성을 만들 수 있습니다.
메모:
model 필드가 동일해야합니다. 동적 목재 믹싱 소개는 spkmix.py 파일을 참조하십시오.
캐릭터 믹스 트랙 쓰기 규칙 :
역할 ID : [[시작 시간 1, 종료 시간 1, 시작 값 1, 시작 값 1], [시작 시간 2, 종료 시간 2, 시작 값 2]]]
시작 시간은 이전 시간의 종료 시간과 동일해야합니다. 첫 번째 시작 시간은 0이어야하고 마지막 종료 시간은 1이어야합니다 (시간 범위는 0 ~ 1).
사용하지 않은 역할의 경우 [[0., 1., 0., 0.]를 채우십시오.
융합 값은 임의로 채워질 수 있으며, 지정된 기간 내에 시작 값에서 최종 값으로의 선형 변화. 그만큼
내부 선형 조합은 자동으로 1 (볼록 조합 조건)으로 보장되므로 안전하게 사용할 수 있습니다.
동적 목재 믹싱을 활성화하는 것으로 추론 할 때 --use_spk_mix 매개 변수를 사용하십시오.
onnx_export.py를 사용하십시오
checkpoints 라는 폴더를 만들고 열 수 있습니다checkpoints 폴더에서 폴더를 만들어 프로젝트 후에 이름 지정 (예 : aziplayermodel.pth , Configuration 파일로 모델 이름을 config.json 으로 바꾸고 방금 만든 aziplayer 폴더에 배치하십시오.path = "NyaruTaffy" "NyaruTaffy" nyarutaffy"를 프로젝트 이름으로 수정하십시오. path = "aziplayer" − (onnx_export_speaker_mix를 혼합 할 수 있습니다.model.onnx 내보내는 모델 인 프로젝트 폴더에서 생성됩니다.참고 : Hubert Onnx 모델의 경우 Moess가 제공하는 모델을 사용하십시오. 현재, 그들은 스스로 수출 할 수 없습니다 (FairseQ의 Hubert는 많은 지원되지 않는 연산자와 오류를 유발하거나 입력/출력 모양에 문제를 일으킬 수있는 상수와 관련된 상수와 관련된 것들과 내보낼 때 결과가 포함되어 있습니다.)
| URL | 지정 | 제목 | 구현 소스 |
|---|---|---|---|
| 2106.06103 | vits (신시사이저) | 엔드 투 엔드 텍스트 음성 연사를위한 적대적 학습을 갖춘 조건부 변형 자동 인코더 | jaywalnut310/vits |
| 2111.02392 | SoftVC (음성 인코더) | 개선 된 음성 변환을위한 개별적이고 부드러운 음성 단위 비교 | Bshall/Hubert |
| 2204.09224 | ContentVec (음성 인코더) | ContentVec : 스피커를 분리하여 개선 된 자체 감독 음성 표현 | Auspicious3000/ContentVec |
| 2212.04356 | Whisper (Speech Encoder) | 대규모 약한 감독을 통한 강력한 음성 인식 | Openai/Whisper |
| 2110.13900 | Wavlm (음성 인코더) | WAVLM : 풀 스택 음성 처리를위한 대규모 자체 감독 사전 훈련 | Microsoft/UNILM/WAVLM |
| 2305.17651 | dphubert (음성 인코더) | DPHUBERT : 자체 감독 음성 모델의 공동 증류 및 가지 치기 | pyf98/dphubert |
| doi : 10.21437/interspeech.2017-68 | 수확 (F0 예측 변수) | 수확 : 음성 신호로 인한 고성능 기본 주파수 추정기 | Mmorise/World/Harvest |
| AES35-000039 | DIO (F0 예측 변수) | 노래 목소리와 연설의 보컬 폴드 진동의 기간 추출에 기초한 빠르고 신뢰할 수있는 F0 추정 방법 | mmorise/world/dio |
| 8461329 | 크레페 (F0 예측 변수) | 크레페 : 피치 추정을위한 컨볼 루션 표현 | Maxrmorrison/Torchcrepe |
| doi : 10.1016/j.wocn.2018.07.001 | Parselmouth (F0 예측 자) | Parselmouth 소개 : Praat에 대한 Python 인터페이스 | Yannickjadoul/Parselmouth |
| 2306.15412V2 | RMVPE (F0 예측 변수) | RMVPE : 다성 음악의 보컬 피치 추정을위한 강력한 모델 | 꿈에서 높은/rmvpe |
| 2010.05646 | Hifigan (보코더) | Hifi-gan : 효율적이고 고 충실도 음성 합성을위한 생성 적대적 네트워크 | jik876/hifi-gan |
| 1810.11946 | NSF (보코더) | 통계 파라 메트릭 음성 합성을위한 신경 소스 필터 기반 파형 모델 | OpenVPI/diffsinger/modules/nsf_hifigan |
| 2006.08195 | 뱀 (보코더) | 신경망은 정기적 인 기능과이를 해결하는 방법을 배우지 못합니다. | 에드워드 딕슨/뱀 |
| 2105.02446V3 | 얕은 확산 (후 프로세싱) | Diffsinger : 얕은 확산 메커니즘을 통한 노래 음성 합성 | CNCHTU/확산 -SVC |
| K- 평균 | 기능 K- 평균 클러스터링 (전처리) | 다변량 관찰의 분류 및 분석 방법 | 이 repo |
| 기능 Topk 검색 (사전 처리) | 검색 기반 음성 변환 | rvc-project/검색 기반-보이스-수정-부비 | |
| 속삭임 PPG | 속삭임 PPG | playvoice/whisper_ppg | |
| Bigvgan | Bigvgan | PlayVoice/So-Vits-SVC-5.0 |
어떤 이유로 저자는 원래 저장소를 삭제했습니다. 조직 구성원의 과실로 인해이 리포지토리의 재구성이 시작될 때 모든 파일 이이 저장소에 직접 재 설계 되었기 때문에 기고자 목록이 지워졌습니다. 이제 이전 기고자 목록을 readme.md에 추가하십시오.
일부 회원은 개인 소원에 따라 나열되지 않았습니다.
미스테오 | Xiaomiku01 | しぐれ | Tomogasukunai | Plachtaa | ZD 小达 | 凍聲響世 |
任何组织或者个人不得以丑化、污损, 或者利用信息技术手段伪造等方式侵害他人的肖像权。未经肖像权人同意, 不得制作、使用、公开肖像权人的肖像, 但是法律另有规定的除外。未经肖像权人同意 除外。未经肖像权人同意, 肖像作品权利人不得以发表、复制、发行、出租、展览等方式使用或者公开肖像权人的肖像。对自然人声音的保护, 参照适用肖像权保护的有关规定。
【名誉权】民事主体享有名誉权。任何组织或者个人不得以侮辱、诽谤等方式侵害他人的名誉权。
【作品侵害名誉权】行为人发表的文学、艺术作品以真人真事或者特定人为描述对象, 含有侮辱、诽谤内容, 侵害他人名誉权的, 受害人有权依法请求该行为人承担民事责任。行为人发表的文学、艺术作品不以特定人为描述对象 人发表的文学、艺术作品不以特定人为描述对象, 仅其中的情节与该特定人的情况相似的, 不承担民事责任。


