MockingBird
1.0.0
雖然我不再積極更新此倉庫,但您會發現我不斷將這項技術向前推向良好的一面和開源。我還構建了一個優化的雲託管版本:https://noiz.ai/,它是免費的,但現在還沒有準備好進行一次性使用。

英語| 中文| 中文linux
中國支持普通話並通過多個數據集進行了測試:aidatang_200zh,magicdata,aishell3,data_aishell等。
Pytorch在Pytorch工作,以1.9.0版(2021年8月的最新版本)進行了測試,其中GPU Tesla T4和GTX 2060
Windows + Linux在Windows OS和Linux OS中運行(甚至在M1 MacOS中)
僅通過重複使用驗證的編碼器/vocoder,便於新訓練的合成器輕鬆且令人敬畏的效果
Web服務器準備通過遠程呼叫為您的結果服務
請按照原始存儲庫進行測試,以便您準備好所有環境。 ** python 3.7或更高**運行工具箱。
安裝Pytorch。
如果您遇到
ERROR: Could not find a version that satisfies the requirement torch==1.9.0+cu102 (from versions: 0.1.2, 0.1.2.post1, 0.1.2.post2 )此錯誤可能是由於低版本的Python ,嘗試使用3.9,它將成功安裝
安裝FFMPEG。
運行pip install -r requirements.txt以安裝剩餘的必要軟件包。
此處的推薦環境是
Repo Tag 0.0.1Pytorch1.9.0 with Torchvision0.10.0 and cudatoolkit10.2requirements.txtwebrtcvad-wheels因為requirements. txt是幾個月前出口的,因此它與較新版本不起作用
安裝WebRTCVAD pip install webrtcvad-wheels (如果需要)
或者
使用conda或mamba安裝依賴項
conda env create -n env_name -f env.yml
mamba env create -n env_name -f env.yml
將在安裝必要的依賴項的情況下創建一個虛擬環境。通過conda activate env_name切換到新環境並享受它。
Env.yml僅包括運行項目的必要依賴項,而無需單調對準。您可以檢查官方網站以安裝GPU版本的Pytorch。
以下步驟是一個解決方法,可以直接使用原始的
demo_toolbox.py,而無需更改代碼。由於主要問題與
demo_toolbox.pydemo_toolbox.pyweb.py的pyqt5軟件包有關項目。
PyQt5 ,在此處使用參考。創建並在此處使用Ref打開Rosetta終端。
使用系統python為項目創建虛擬環境
/usr/bin/python3 -m venv /PathToMockingBird/venv source /PathToMockingBird/venv/bin/activate
升級PIP並安裝PyQt5
pip install --upgrade pip pip install pyqt5
pyworld和ctc-segmentation這兩個軟件包似乎都是該項目獨有的,並且在原始的實時語音克隆項目中沒有看到。使用
pip install安裝時,兩個軟件包都缺少車輪,因此該程序試圖直接從C代碼編譯,並且找不到Python.h。
安裝pyworld
brew install python Python.h可以隨附Brew安裝的Python
export CPLUS_INCLUDE_PATH=/opt/homebrew/Frameworks/Python.framework/Headers brew-installed Python.h的filepath是m1 macos獨有的,上面列出。需要手動將路徑添加到環境變量中。
pip install pyworld 。
安裝ctc-segmentation
相同的方法不適用於
ctc-segmentation,並且需要從GitHub上的源代碼進行編譯。
git clone https://github.com/lumaku/ctc-segmentation.git
cd ctc-segmentation
source /PathToMockingBird/venv/bin/activate如果尚未部署虛擬環境,請激活它。
cythonize -3 ctc_segmentation/ctc_segmentation_dyn.pyx
/usr/bin/arch -x86_64 python setup.py build構建使用x86架構。
/usr/bin/arch -x86_64 python setup.py install --optimize=1 --skip-build instuct in x86體系結構。
/usr/bin/arch -x86_64 pip install torch torchvision torchaudio pip安裝PyTorch的例子,表明它已安裝了x86架構
pip install ffmpeg安裝FFMPEG
pip install -r requirements.txt安裝其他要求。
在X86架構上運行該項目。參考。
vim /PathToMockingBird/venv/bin/pythonM1創建一個可執行文件pythonM1 ,以調理python解釋器在/PathToMockingBird/venv/bin 。
在以下內容中寫入:
#!/usr/bin/env zsh
mydir=${0:a:h}
/usr/bin/arch -x86_64 $mydir/python "$@" chmod +x pythonM1將文件設置為可執行文件。
如果使用Pycharm IDE,請將項目解釋器配置為pythonM1 (此處的步驟),如果使用命令行Python,run /PathToMockingBird/venv/bin/pythonM1 demo_toolbox.py
請注意,由於原始模型與中國符號不相容,因此我們使用的編碼器/Vocoder,但不使用合成器。這意味著目前demo_cli不起作用,因此需要其他合成模型。
您可以訓練模型或使用現有模型:
使用音頻和MEL頻譜圖的預處理: python encoder_preprocess.py <datasets_root>允許參數--dataset {dataset}來支持要預處理的數據集。僅使用這些數據集的火車組。可能的名稱:librispeech_other,voxceleb1,voxceleb2。使用逗號串起多個數據集。
訓練編碼器: python encoder_train.py my_run <datasets_root>/SV2TTS/encoder
對於培訓,編碼器使用vign。您可以使用
--no_visdom將其禁用,但是很高興。在單獨的CLI/進程中運行“ vive”以啟動您的vive服務器。
下載數據集和解壓縮:確保您可以在文件夾中訪問所有.wav
使用音頻和MEL頻譜圖的預處理: python pre.py <datasets_root>允許參數--dataset {dataset}支持AIDATATATANG_200ZH,MAIGHDATA,AISHELL3,DATA_AISHELL 3,DATA_AISHELL等。
訓練合成器: python train.py --type=synth mandarin <datasets_root>/SV2TTS/synthesizer
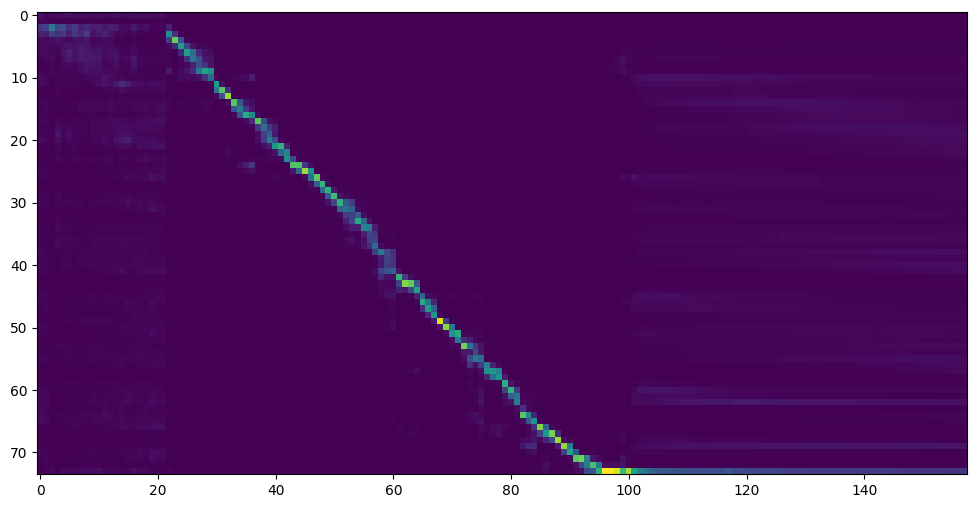
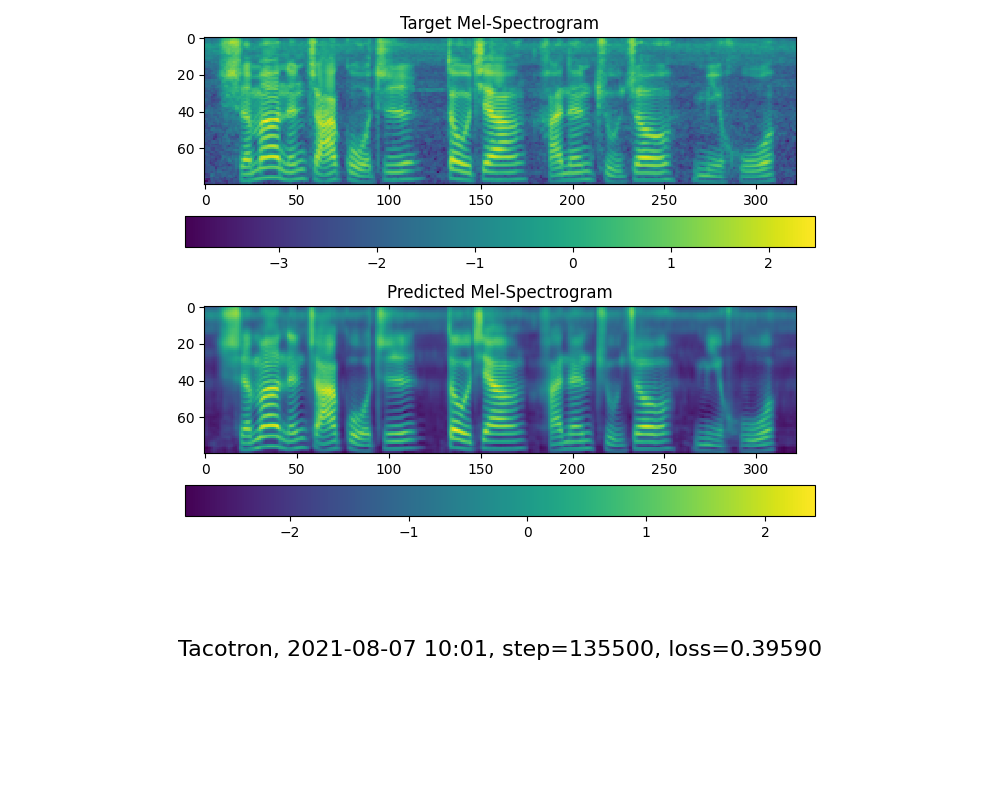
當您看到注意線顯示和損失滿足您在訓練文件夾合成器/ saved_models/中的需求時,請轉到下一步。
多虧了社區,將分享一些模型:
| 作者 | 下載鏈接 | 預覽視頻 | 資訊 |
|---|---|---|---|
| @作者 | https://pan.baidu.com/s/1ionvrxmki-t1nhqxkyty3g baidu 4j5d | 由多個數據集訓練的75K步驟 | |
| @作者 | https://pan.baidu.com/s/1fmh9ilgkjll2piirtyduvw baidu代碼:OM7F | 由多個數據集訓練的25K步驟,僅在版本0.0.1下工作 | |
| @fawenyo | https://yisiou-my.sharepoint.com/:u:u:/g/personal/lawrence_cheng_fawenyo_onmicrosoft_comcom/ewfwdhzee-nng9twdkckckcckcc4bc7bc7bk2j9ccbk2j9ccbown0-ccbown0-_tk0nog?ee = n00gggc | 輸入輸出 | 台灣當地口音的200k步驟,僅在0.0.1版中工作 |
| @miven | https://pan.baidu.com/s/1pi-hm3sn5wbechrryx-rcq代碼:2021 https://www.aliyundrive.com/s/awpsbo8mcsps代碼:z2m0 | https://www.bilibili.com/video/bv1uh411b7ad/ | 僅在0.0.1版本下工作 |
注意:Vocoder的效果差異很小,因此您可能不需要培訓新的差異。
預處理數據: python vocoder_preprocess.py <datasets_root> -m <synthesizer_model_path>
<datasets_root>用數據集root,<synthesizer_model_path>替換為sythensizer最佳訓練型號的目錄,例如sythensizersaved_modexxx
訓練Wavernn Vocoder: python vocoder_train.py mandarin <datasets_root>
訓練hifigan vocoder python vocoder_train.py mandarin <datasets_root> hifigan
然後,您可以嘗試運行: python web.py並在瀏覽器中打開,默認為http://localhost:8080
然後,您可以嘗試工具箱: python demo_toolbox.py -d <datasets_root>
然後,您可以嘗試命令: python gen_voice.py <text_file.txt> your_wav_file.wav您可能需要通過“ PIP INSTALS CN2AN”安裝CN2AN,以獲得更好的數字數字結果。
該存儲庫是從僅支持英語的實時訪問中分配的。
| URL | 指定 | 標題 | 實現來源 |
|---|---|---|---|
| 1803.09017 | 全球風格(合成器) | 樣式令牌:無監督的樣式建模,控制和轉移端到端語音綜合 | 這個存儲庫 |
| 2010.05646 | Hifi-Gan(Vocoder) | 生成的對抗網絡,可高效且高保真語音綜合 | 這個存儲庫 |
| 2106.02297 | Fre-Gan(Vocoder) | Fre-GAN:對抗頻率一致的音頻綜合 | 這個存儲庫 |
| 1806.04558 | SV2TTS | 從說話者驗證轉移到多言揚聲器文本到語音綜合 | 這個存儲庫 |
| 1802.08435 | Wavernn(Vocoder) | 有效的神經音頻綜合 | fatchord/wavernn |
| 1703.10135 | TACOTRON(合成器) | TACOTRON:朝向端到端語音合成 | fatchord/wavernn |
| 1710.10467 | GE2E(編碼器) | 演講者驗證的全身端到端損失 | 這個存儲庫 |
| 數據集 | 原始來源 | 替代來源 |
|---|---|---|
| AIDATATANG_200ZH | Openslr | Google Drive |
| MagicData | Openslr | Google Drive(開發設置) |
| aishell3 | Openslr | Google Drive |
| data_aishell | Openslr |
UNZIP AIDATATANG_200ZH之後,您需要在
aidatatang_200zhcorpustrain下解壓縮所有文件
<datasets_root> ?如果數據集路徑為D:dataaidatatang_200zh ,則<datasets_root> D:data
訓練合成器:在synthesizer/hparams.py中調整批次_size
//Before tts_schedule = [(2, 1e-3, 20_000, 12), # Progressive training schedule (2, 5e-4, 40_000, 12), # (r, lr, step, batch_size) (2, 2e-4, 80_000, 12), # (2, 1e-4, 160_000, 12), # r = reduction factor (# of mel frames (2, 3e-5, 320_000, 12), # synthesized for each decoder iteration) (2, 1e-5, 640_000, 12)], # lr = learning rate //After tts_schedule = [(2, 1e-3, 20_000, 8), # Progressive training schedule (2, 5e-4, 40_000, 8), # (r, lr, step, batch_size) (2, 2e-4, 80_000, 8), # (2, 1e-4, 160_000, 8), # r = reduction factor (# of mel frames (2, 3e-5, 320_000, 8), # synthesized for each decoder iteration) (2, 1e-5, 640_000, 8)], # lr = learning rate
訓練vocoder-preprocess數據:調整synthesizer/hparams.py中的batch_size
//Before ### Data Preprocessing max_mel_frames = 900, rescale = True, rescaling_max = 0.9, synthesis_batch_size = 16, # For vocoder preprocessing and inference. //After ### Data Preprocessing max_mel_frames = 900, rescale = True, rescaling_max = 0.9, synthesis_batch_size = 8, # For vocoder preprocessing and inference.
Train Vocoder-Train the Vocoder:調整vocoder/wavernn/hparams.py中的batch_size
//Before # Training voc_batch_size = 100 voc_lr = 1e-4 voc_gen_at_checkpoint = 5 voc_pad = 2 //After # Training voc_batch_size = 6 voc_lr = 1e-4 voc_gen_at_checkpoint = 5 voc_pad =2
RuntimeError: Error(s) in loading state_dict for Tacotron: size mismatch for encoder.embedding.weight: copying a param with shape torch.Size([70, 512]) from checkpoint, the shape in current model is torch.Size([75, 512]).請參考第37期
調整適當改進的批次_size
the page file is too small to complete the operation請參閱此視頻,然後將虛擬內存更改為100G(102400),例如:將文件放置在D磁盤中時,更改了D磁盤的虛擬內存。
僅供參考,我的注意力是在18k步驟和50k步驟後損失低於0.4之後。