MockingBird
1.0.0
Obwohl ich dieses Repo nicht mehr aktiv aktualisiere, können Sie diese Technologie kontinuierlich auf eine gute Seite und Open-Source-Vorwärtsfahrt bringen. Ich erstelle auch eine optimierte und cloud gehostete Version: https://noiz.ai/ und es ist kostenlos, aber jetzt nicht bereit für den Handel.

Englisch | 中文 | 中文 Linux
Chinese unterstützte Mandarin und wurde mit mehreren Datensätzen getestet: Aidatatang_200zh, MagicData, Aishell3, Data_aishell und etc.
Pytorch arbeitete für Pytorch, getestet in der Version von 1.9.0 (neueste im August 2021) mit GPU Tesla T4 und GTX 2060
Windows + Linux wird sowohl in Windows OS als auch in Linux -Betriebssystem ausgeführt (auch in M1 macOS)
Einfacher und großartiger Effekt mit nur neu ausgebildetem Synthesizer, indem der vorgezogene Encoder/Vocoder wiederverwendet wird
Webserver ist bereit , Ihr Ergebnis mit Remote -Anrufen zu bedienen
Folgen Sie dem ursprünglichen Repo, um zu testen, ob Sie die gesamte Umgebung fertig haben. ** Python 3.7 oder höher ** wird benötigt, um die Toolbox auszuführen.
Pytorch installieren.
Wenn Sie einen
ERROR: Could not find a version that satisfies the requirement torch==1.9.0+cu102 (from versions: 0.1.2, 0.1.2.post1, 0.1.2.post2 )Dieser Fehler ist wahrscheinlich auf a zurückzuführen Niedrige Version von Python, verwenden Sie 3.9 und es wird erfolgreich installiert
Installieren Sie FFMPEG.
Führen Sie pip install -r requirements.txt aus, um die verbleibenden erforderlichen Pakete zu installieren.
Die empfohlene Umgebung hier ist
Repo Tag 0.0.1webrtcvad-wheelsPytorch1.9.0 with Torchvision0.10.0 and cudatoolkit10.2requirements. txtrequirements.txtrequirements. txtwurde vor einigen Monaten exportiert, so dass es nicht mit neueren Versionen funktioniert
Installieren Sie die WEBRTCVAD pip install webrtcvad-wheels (falls Sie benötigen)
oder
Installieren Sie Abhängigkeiten mit conda oder mamba
conda env create -n env_name -f env.yml
mamba env create -n env_name -f env.yml
Erstellt bei Bedarf eine virtuelle Umgebung. Wechseln Sie in die neue Umgebung von conda activate env_name und genießen Sie sie.
Env.yml enthält nur die notwendigen Abhängigkeiten, um das Projekt vorübergehend ohne monotonische Ausrichtung durchzuführen. Sie können die offizielle Website überprüfen, um die GPU -Version von Pytorch zu installieren.
Die folgenden Schritte sind eine Problemumgehung, um die ursprüngliche
demo_toolbox.pyohne die Änderung von Codes direkt zu verwenden.Da das Hauptproblem mit den PYQT5 -Paketen in
demo_toolbox.pynicht mit M1 -Chips kompatibel ist, war ein einerdemo_toolbox.pyweb.pybei Trainingsmodellen mit dem M1 -Chip versuchen konnte das Projekt.
PyQt5 , mit Ref hier.Erstellen und öffnen Sie ein Rosetta -Terminal mit Ref hier.
Verwenden Sie System Python, um eine virtuelle Umgebung für das Projekt zu erstellen
/usr/bin/python3 -m venv /PathToMockingBird/venv source /PathToMockingBird/venv/bin/activate
Aktualisieren Sie PIP und installieren Sie PyQt5
pip install --upgrade pip pip install pyqt5
pyworld und ctc-segmentationBeide Pakete scheinen für dieses Projekt einzigartig zu sein und sind im ursprünglichen Echtzeit-Sprachkloning-Projekt nicht zu sehen. Bei der Installation mit
pip installfehlen bei beiden Paketen Räder, sodass das Programm versucht, direkt aus C -Code zu kompilieren undPython.hnicht zu finden.
Installieren Sie pyworld
brew install python Python.h kann mit Python von Brew eingeliefert werden
export CPLUS_INCLUDE_PATH=/opt/homebrew/Frameworks/Python.framework/Headers Der Filepath des brauinstallierten Python.h ist einzigartig für M1 MacOS und oben aufgeführt. Man muss den Weg zu den Umgebungsvariablen manuell hinzufügen.
pip install pyworld , die dies tun sollte.
Installieren Sie ctc-segmentation
Die gleiche Methode gilt nicht für
ctc-segmentationund muss ihn aus dem Quellcode auf GitHub kompilieren.
git clone https://github.com/lumaku/ctc-segmentation.git
cd ctc-segmentation
source /PathToMockingBird/venv/bin/activate Wenn die virtuelle Umgebung nicht bereitgestellt wurde, aktivieren Sie sie.
cythonize -3 ctc_segmentation/ctc_segmentation_dyn.pyx
/usr/bin/arch -x86_64 python setup.py build Build mit x86 Architektur.
/usr/bin/arch -x86_64 python setup.py install --optimize=1 --skip-build Installation mit x86 Architektur.
/usr/bin/arch -x86_64 pip install torch torchvision torchaudio PIP, in dem PyTorch als Beispiel installiert wird, dass es mit X86 -Architektur installiert ist
pip install ffmpeg Installieren Sie FFMPEG
pip install -r requirements.txt andere Anforderungen installieren.
Um das Projekt auf X86 -Architektur auszuführen. Ref.
vim /PathToMockingBird/venv/bin/pythonM1 Erstellen Sie eine ausführbare Datei pythonM1 , um Python -Interpreter bei /PathToMockingBird/venv/bin zu konditionieren.
Schreiben Sie in den folgenden Inhalt:
#!/usr/bin/env zsh
mydir=${0:a:h}
/usr/bin/arch -x86_64 $mydir/python "$@" chmod +x pythonM1 stellen die Datei als ausführbare Datei fest.
Wenn Sie Pycharm IDE verwenden, konfigurieren Sie Projekt -Interpreter mit pythonM1 (Schritte hier). Wenn Sie die Befehlszeile Python verwenden, run /PathToMockingBird/venv/bin/pythonM1 demo_toolbox.py
Beachten Sie, dass wir den vorgenannten Encoder/Vocoder verwenden, jedoch nicht den Synthesizer, da das ursprüngliche Modell mit den chinesischen Symbolen nicht kompatibel ist. Dies bedeutet, dass die Demo_Cli derzeit nicht funktioniert, sodass zusätzliche Synthesizer -Modelle erforderlich sind.
Sie können Ihre Modelle entweder trainieren oder vorhandene verwenden:
Precess mit den Audios und den MEL -Spektrogrammen: python encoder_preprocess.py <datasets_root> Ermöglichen von Parameter --dataset {dataset} um die Datensätze zu unterstützen, die Sie vorbereiten möchten. Es werden nur der Zugsatz dieser Datensätze verwendet. Mögliche Namen: librispeech_other, voxceleb1, voxceleb2. Verwenden Sie Komma, um mehrere Datensätze zu spergen.
Trainieren Sie den Encoder: python encoder_train.py my_run <datasets_root>/SV2TTS/encoder
Für das Training verwendet der Encoder Visom. Sie können es mit
--no_visdomdeaktivieren, aber es ist schön zu haben. Führen Sie "Visom" in einem separaten CLI/-Prozess aus, um Ihren Visdom -Server zu starten.
Download Dataset und Unzip: Stellen Sie sicher, dass Sie im Ordner auf alle .wav zugreifen können
Vorverarbeitet mit den Audios und den Mel -Spektrogrammen: python pre.py <datasets_root> Ermöglichen von Parameter --dataset {dataset} , um Aidatatang_200Zh zu unterstützen, MagicData, Aishell3, Data_aishell, usw., es ist nicht übergeben.
Train the Synthesizer: python train.py --type=synth mandarin <datasets_root>/SV2TTS/synthesizer
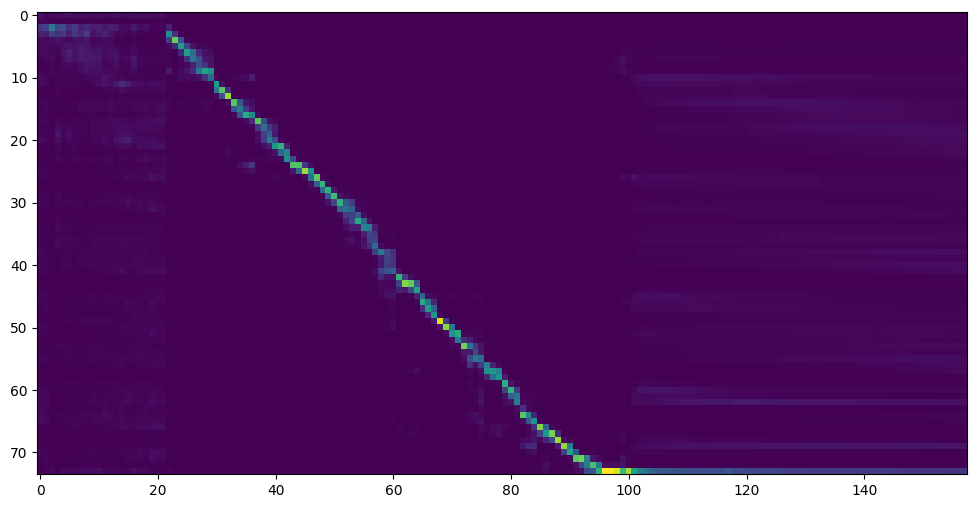
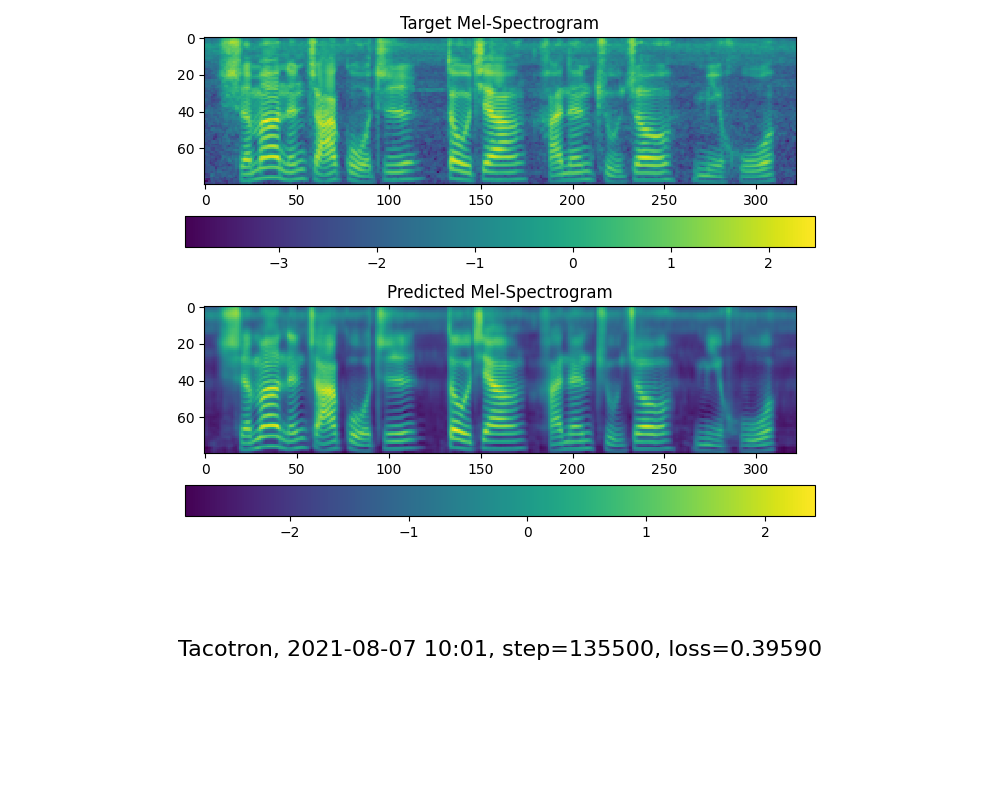
Gehen Sie mit dem nächsten Schritt, wenn Sie die Aufmerksamkeitszeilenshow und den Verlust sehen, um Ihren Bedarf im Trainingsordner Synthesizer/ Saved_Models/ zu erfüllen.
Dank der Community werden einige Modelle geteilt:
| Autor | Link herunterladen | Vorschau -Video | Info |
|---|---|---|---|
| @Autor | https://pan.baidu.com/s/1ionvrxmki-t1nhqxkyty3g Baidu 4j5d | 75K -Schritte, die von mehreren Datensätzen trainiert werden | |
| @Autor | https://pan.baidu.com/s/1fmh9ilgkjll2piirtyDuvw Baidu Code: Om7f | 25K -Schritte, die von mehreren Datensätzen trainiert werden, funktioniert nur unter Version 0.0.1 | |
| @Fawenyo | https://yisiou-my.sharepoint.com/:u:/g/personal/lawrence_cheng_fawenyo_onmicrosoft_com/ewfwdhzeee-nng9twdkkcccc4bc7bk2j9ccbown0-_tk0nog?e=n0gggc | Eingangsausgabe | 200k Schritte mit lokalem Akzent von Taiwan, funktioniert nur unter Version 0.0.1 |
| @Miven | https://pan.baidu.com/s/1pi-hm3sn5wbechrryx-rcq Code: 2021 https://www.aliyundrive.com/s/awpsbo8mcsp Code: Z2M0 | https://www.bilibili.com/video/bv1uh411b7ad/ | funktioniert nur unter Version 0.0.1 |
Hinweis: Der Vocoder hat einen geringen Unterschied in der Wirkung, sodass Sie möglicherweise keine neue trainieren müssen.
Preprocess die Daten vorbereiten: python vocoder_preprocess.py <datasets_root> -m <synthesizer_model_path>
<datasets_root>Ersetzen Sie durch Ihr Datensatzstamm ,<synthesizer_model_path>Ersetzen
Train the gernn vocoder: python vocoder_train.py mandarin <datasets_root>
Trainieren Sie den Hifigan Vocoder python vocoder_train.py mandarin <datasets_root> hifigan
Sie können dann versuchen zu rennen: python web.py und öffnen Sie es im Browser, Standard als http://localhost:8080
Sie können dann die Toolbox: python demo_toolbox.py -d <datasets_root> ausprobieren.
Sie können dann den Befehl versuchen: python gen_voice.py <text_file.txt> your_wav_file.wav Sie müssen möglicherweise CN2AN per "PIP install CN2AN" installieren, um ein besseres Ergebnis für digitale Zahlen zu erzielen.
Dieses Repository wird aus Echtzeit-Voice-Kloning gezogen, die nur Englisch unterstützen.
| URL | Bezeichnung | Titel | Implementierungsquelle |
|---|---|---|---|
| 1803.09017 | GlobalStyLetoken (Synthesizer) | Style Tokens: unbeaufsichtigte Modellierung, Steuerung und Übertragung in der End-to-End-Sprachsynthese | Dieses Repo |
| 2010.05646 | Hifi-Gan (Vocoder) | Generative kontroverse Netzwerke für eine effiziente und High -Fidelity -Sprachsynthese | Dieses Repo |
| 2106.02297 | Fre-gan (Vocoder) | Fre-Gan: Konsariale Frequenz-konsistente Audio-Synthese | Dieses Repo |
| 1806.04558 | SV2TTS | Übertragen Sie das Lernen von der Sprecherüberprüfung auf Multispeaker-Text-zu-Sprach-Synthese | Dieses Repo |
| 1802.08435 | Gernn (Vocoder) | Effiziente neuronale Audio -Synthese | Fatchord/Raernn |
| 1703.10135 | Tacotron (Synthesizer) | Tacotron: In Richtung End-to-End-Sprachsynthese | Fatchord/Raernn |
| 1710.10467 | GE2E (Encoder) | Verallgemeinerter End-to-End-Verlust für die Überprüfung der Sprecher | Dieses Repo |
| Datensatz | Originalquelle | Alternative Quellen |
|---|---|---|
| Aidatatang_200zh | Openslr | Google Drive |
| MagicData | Openslr | Google Drive (Dev Set) |
| Aishell3 | Openslr | Google Drive |
| Data_aishell | Openslr |
Nachdem Sie Aidatatang_200Zh entpeilt, müssen Sie alle Dateien unter
aidatatang_200zhcorpustrainentpacken
<datasets_root> ? Wenn der Dataset -Pfad D:dataaidatatang_200zh lautet, dann ist <datasets_root> D:data
Trainieren Sie den Synthesizer: Passen Sie die batch_size in synthesizer/hparams.py ein
//Before tts_schedule = [(2, 1e-3, 20_000, 12), # Progressive training schedule (2, 5e-4, 40_000, 12), # (r, lr, step, batch_size) (2, 2e-4, 80_000, 12), # (2, 1e-4, 160_000, 12), # r = reduction factor (# of mel frames (2, 3e-5, 320_000, 12), # synthesized for each decoder iteration) (2, 1e-5, 640_000, 12)], # lr = learning rate //After tts_schedule = [(2, 1e-3, 20_000, 8), # Progressive training schedule (2, 5e-4, 40_000, 8), # (r, lr, step, batch_size) (2, 2e-4, 80_000, 8), # (2, 1e-4, 160_000, 8), # r = reduction factor (# of mel frames (2, 3e-5, 320_000, 8), # synthesized for each decoder iteration) (2, 1e-5, 640_000, 8)], # lr = learning rate
Zug-Vocoder-Präzess der Daten: Passen Sie die batch_size in synthesizer/hparams.py
//Before ### Data Preprocessing max_mel_frames = 900, rescale = True, rescaling_max = 0.9, synthesis_batch_size = 16, # For vocoder preprocessing and inference. //After ### Data Preprocessing max_mel_frames = 900, rescale = True, rescaling_max = 0.9, synthesis_batch_size = 8, # For vocoder preprocessing and inference.
Zug-Vocoder-Trainer Der Vocoder: Passen Sie die batch_size in vocoder/wavernn/hparams.py
//Before # Training voc_batch_size = 100 voc_lr = 1e-4 voc_gen_at_checkpoint = 5 voc_pad = 2 //After # Training voc_batch_size = 6 voc_lr = 1e-4 voc_gen_at_checkpoint = 5 voc_pad =2
RuntimeError: Error(s) in loading state_dict for Tacotron: size mismatch for encoder.embedding.weight: copying a param with shape torch.Size([70, 512]) from checkpoint, the shape in current model is torch.Size([75, 512]).Bitte beachten Sie Ausgabe Nr. 37
Passen Sie die batch_size entsprechend an, um sich zu verbessern
the page file is too small to complete the operationBitte beziehen Sie sich auf dieses Video und ändern Sie den virtuellen Speicher auf 100G (102400), zum Beispiel: Wenn die Datei in der D -Diskette platziert wird, wird der virtuelle Speicher der D -Datenträger geändert.
Zu Ihrer Information, meine Aufmerksamkeit, nachdem 18.000 Schritte und der Verlust nach 50 K -Schritten niedriger als 0,4 lag.