MockingBird
1.0.0
더 이상이 저장소를 적극적으로 업데이트하지는 않지만이 기술을 계속해서 좋은 편과 오픈 소스로 추진할 수 있습니다. 또한 최적화 된 클라우드 호스팅 버전 인 https://noiz.ai/를 구축하고 있으며 무료이지만 현재 상업적으로 사용할 준비가되지 않았습니다.

영어 | 中文 | Linux
중국어는 만다린을 지원하고 여러 데이터 세트로 테스트했습니다 : Aidatatang_200ZH, MagicData, Aishell3, Data_aishell 등
Pytorch는 Pytorch에서 근무했으며 1.9.0 (2021 년 8 월 최신)으로 테스트했으며 GPU Tesla T4 및 GTX 2060으로 테스트했습니다.
Windows + Linux는 Windows OS 및 Linux OS에서 실행됩니다 (M1 MACOS에서도)
새로 훈련 된 신디사이저만으로 쉽고 멋진 효과를냅니다.
Webserver는 원격 통화로 결과를 제공 할 준비가되었습니다
모든 환경을 준비했는지 테스트하려면 원래 리포를 따라 테스트하십시오. ** Toolbox를 실행하려면 Python 3.7 이상 **가 필요합니다.
Pytorch를 설치하십시오.
ERROR: Could not find a version that satisfies the requirement torch==1.9.0+cu102 (from versions: 0.1.2, 0.1.2.post1, 0.1.2.post2 )이 오류는 아마도 낮은 버전의 Python, 3.9를 사용해 보면 성공적으로 설치됩니다.
FFMPEG를 설치하십시오.
pip install -r requirements.txt 실행하여 나머지 필요한 패키지를 설치하려면 TXT를 실행하십시오.
여기에서 권장되는 환경은
Pytorch1.9.0 with Torchvision0.10.0 and cudatoolkit10.2requirements.txtwebrtcvad-wheelsRepo Tag 0.0.1Pytorch1.9.0입니다requirements. txt몇 달 전에 수출되었으므로 최신 버전에서는 작동하지 않습니다.
webrtcvad pip install webrtcvad-wheels (필요한 경우)
또는
conda 또는 mamba 로 종속성을 설치하십시오
conda env create -n env_name -f env.yml
mamba env create -n env_name -f env.yml
필요한 종속성이 설치된 경우 가상 환경을 만듭니다. conda activate env_name 하고 즐기십시오.
ENV.YML에는 단조 적 정렬없이 일시적으로 프로젝트를 실행하는 데 필요한 종속성 만 포함됩니다. 공식 웹 사이트를 확인하여 GPU 버전의 Pytorch를 설치할 수 있습니다.
다음 단계는 코드를 변경하지 않고 원래
demo_toolbox.py직접 사용하는 해결 방법입니다.주요 문제는
demo_toolbox.pydemo_toolbox.py사용되는 PYQT5 패키지와 함께 제공되므로 M1 칩과 호환되지 않는 패키지는 M1 칩web.py사용하여 교육 모델을 시도 할 수있는 것이 었습니다. 프로젝트.
PyQt5 설치하십시오.여기에 참조와 함께 Rosetta 터미널을 만들고 열십시오.
시스템 파이썬을 사용하여 프로젝트의 가상 환경을 만듭니다.
/usr/bin/python3 -m venv /PathToMockingBird/venv source /PathToMockingBird/venv/bin/activate
PIP 업그레이드 및 PyQt5 설치하십시오
pip install --upgrade pip pip install pyqt5
pyworld 및 ctc-segmentation 설치하십시오두 패키지 모두이 프로젝트에 고유 한 것으로 보이며 원래 실시간 음성 복제 프로젝트에서는 볼 수 없습니다.
pip install로 설치할 때 두 패키지 모두 휠이 부족하여 프로그램은 C 코드에서 직접 컴파일하려고 시도하고Python.h찾을 수 없습니다.
pyworld 설치하십시오
brew install python Python.h Brew가 설치 한 Python과 함께 제공됩니다.
export CPLUS_INCLUDE_PATH=/opt/homebrew/Frameworks/Python.framework/Headers Installed Python.h 의 FilePath는 M1 MACOS에 고유하며 위에 나열되어 있습니다. 환경 변수에 대한 경로를 수동으로 추가해야합니다.
pip install pyworld 해야합니다.
ctc-segmentation 설치하십시오
동일한 방법
ctc-segmentation에는 적용되지 않으며 GitHub의 소스 코드에서 컴파일해야합니다.
git clone https://github.com/lumaku/ctc-segmentation.git
cd ctc-segmentation
source /PathToMockingBird/venv/bin/activate 가상 환경이 배포되지 않으면 활성화하십시오.
cythonize -3 ctc_segmentation/ctc_segmentation_dyn.pyx
/usr/bin/arch -x86_64 python setup.py build 빌드 x86 아키텍처.
/usr/bin/arch -x86_64 python setup.py install --optimize=1 --skip-build 설치.
/usr/bin/arch -x86_64 pip install torch torchvision torchaudio 우트 핍 PyTorch 설치 예를 들어, x86 아키텍처로 설치되어 있음을 설명하십시오.
pip install ffmpeg 설치 FFMPEG
pip install -r requirements.txt 기타 요구 사항을 설치합니다.
X86 아키텍처에서 프로젝트를 실행합니다. 심판
vim /PathToMockingBird/venv/bin/pythonM1 /PathToMockingBird/venv/bin 에서 python 통역사를 조정하기 위해 실행 파일 pythonM1 만듭니다.
다음 내용으로 작성하십시오.
#!/usr/bin/env zsh
mydir=${0:a:h}
/usr/bin/arch -x86_64 $mydir/python "$@" chmod +x pythonM1 파일을 실행 파일로 설정합니다.
Pycharm IDE를 사용하는 경우 프로젝트 인터프리터를 pythonM1 (여기 단계)으로 구성, 명령 줄 Python을 사용하는 경우 run /PathToMockingBird/venv/bin/pythonM1 demo_toolbox.py
원래 모델은 중국 기호와 호환되지 않기 때문에 사전에 사전 처리 된 인코더/보코더를 사용하고 있지만 신디사이저는 사용하지 않습니다. 이는 현재 Demo_cli가 작동하지 않으므로 추가 신디사이저 모델이 필요합니다.
모델을 훈련 시키거나 기존 모델을 사용할 수 있습니다.
오디오 및 MEL 스펙트로 그램으로 전제 : python encoder_preprocess.py <datasets_root> 매개 변수 허용 --dataset {dataset} 가 준비하려는 데이터 세트를 지원하도록 허용합니다. 이 데이터 세트의 열차 세트 만 사용됩니다. 가능한 이름 : librispeech_other, Voxceleb1, Voxceleb2. 쉼표를 사용하여 여러 데이터 세트를 지출하십시오.
Encoder : python encoder_train.py my_run <datasets_root>/SV2TTS/encoder
훈련을 위해 인코더는 볼 수 있습니다.
--no_visdom으로 비활성화 할 수 있지만 사용하는 것이 좋습니다. 별도의 CLI/프로세스에서 "Visdom"을 실행하여 Visdom Server를 시작하십시오.
데이터 세트 및 압축 해제 다운로드 : 폴더의 모든 .wav에 액세스 할 수 있는지 확인하십시오.
오디오 및 MEL 스펙트로 그램으로 전제 : python pre.py <datasets_root> 허용 매개 변수 허용 --dataset {dataset} Aidatatang_200ZH, MagicData, Aishell3, Data_aishell 등을 지원합니다.
신디사이저를 훈련시킵니다 : python train.py --type=synth mandarin <datasets_root>/SV2TTS/synthesizer
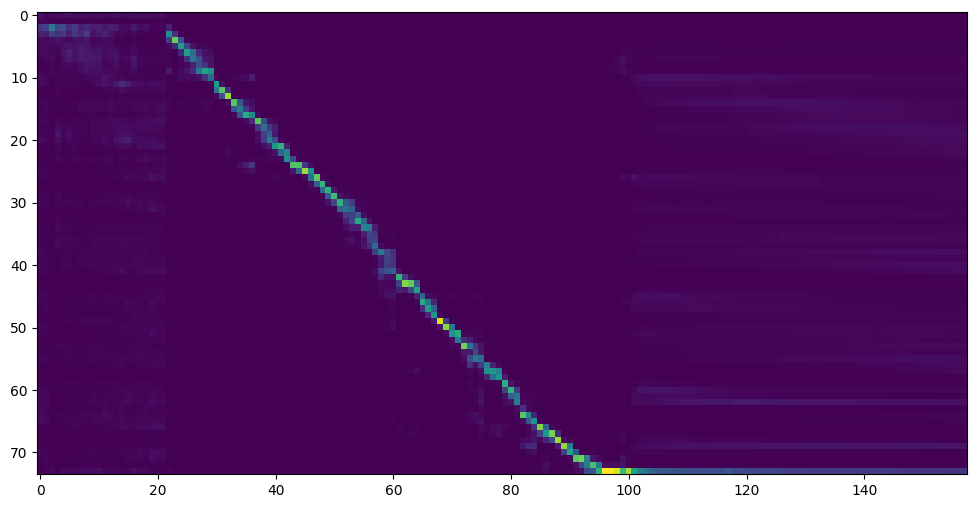
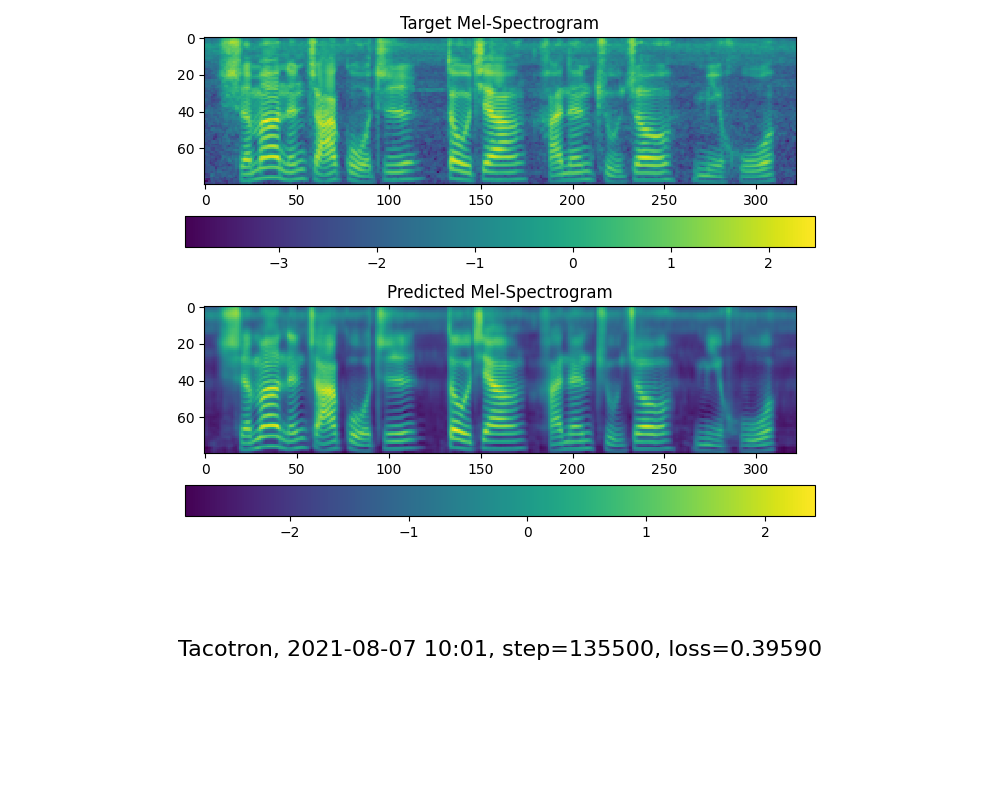
주의 라인 쇼와 손실이 훈련 폴더 신디사이저/ Saved_Models 에서 필요에 맞는 다음 단계로 이동하십시오.
커뮤니티 덕분에 일부 모델은 공유됩니다.
| 작가 | 링크 다운로드 | 비디오 미리보기 | 정보 |
|---|---|---|---|
| @작가 | https://pan.baidu.com/s/1ionvrxmki-t1nhqxky3g baidu 4j5d | 다중 데이터 세트에 의해 훈련 된 75k 단계 | |
| @작가 | https://pan.baidu.com/s/1fmh9ilgkjll2piirtyduvw baidu 코드 : om7f | 다중 데이터 세트로 교육을받은 25k 단계는 버전 0.0.1에 따라 작동합니다. | |
| @fawenyo | https://yisiou-my.sharepoint.com/:u:/g/personal/lawrence_cheng_fawenyo_onmicrosoft_com/ewfwdhzee-nng9twdkccccccc4bc7bk2j9ccbown0-_tk0nog?e=n0gggc | 입력 출력 | 대만의 현지 악센트가있는 200k 단계는 버전 0.0.1에 따라 작동합니다. |
| @miven | https://pan.baidu.com/s/1pi-hm3sn5wbechrryx-rcq 코드 : 2021 https://www.aliyundrive.com/s/awpsbo8mcsp 코드 : Z2M0 | https://www.bilibili.com/video/bv1uh411b7ad/ | 버전 0.0.1에서만 작동합니다 |
참고 : 프로 코더는 효과가 거의 없으므로 새로운 훈련을받을 필요가 없습니다.
데이터를 전제로 작성하십시오 : python vocoder_preprocess.py <datasets_root> -m <synthesizer_model_path>
<datasets_root>데이터 세트 루트로 바꾸십시오<synthesizer_model_path>예를 들어 Sythensizersaved_modexxx , 예 : Sythensizer의 가장 잘 훈련 된 모델의 디렉토리로 교체하십시오.
Wavernn 보코더를 훈련시킵니다 : python vocoder_train.py mandarin <datasets_root>
Hifigan 보보 python vocoder_train.py mandarin <datasets_root> hifigan 훈련시킵니다
그런 다음 실행하려고 시도 할 수 있습니다 : python web.py 브라우저에서 http://localhost:8080 으로 기본값을 열 수 있습니다.
그런 다음 Toolbox : python demo_toolbox.py -d <datasets_root> 시도 할 수 있습니다.
그런 다음 명령을 시도 할 python gen_voice.py <text_file.txt> your_wav_file.wav 있습니다.
이 저장소는 영어 만 지원하는 실시간 음성 클로닝에서 포크됩니다.
| URL | 지정 | 제목 | 구현 소스 |
|---|---|---|---|
| 1803.09017 | GlobalStyletoken (신시사이저) | 스타일 토큰 : 감독되지 않은 스타일 모델링, 제어 및 엔드 투 엔드 음성 합성 전송 | 이 repo |
| 2010.05646 | Hifi-gan (보코더) | 효율적이고 높은 충실도 음성 합성을위한 생성 적대 네트워크 | 이 repo |
| 2106.02297 | 프리건 (보코더) | FRE-GAN : 대적 주파수 일관성 오디오 합성 | 이 repo |
| 1806.04558 | SV2TTS | 스피커 검증에서 멀티 스피커 텍스트 음성 연사 합성으로 학습을 전송합니다 | 이 repo |
| 1802.08435 | wavernn (보코더) | 효율적인 신경 오디오 합성 | Fatchord/Wavernn |
| 1703.10135 | 타코트론 (신시사이저) | 타코트론 : 엔드 투 엔드 언어 합성을 향해 | Fatchord/Wavernn |
| 1710.10467 | GE2E (인코더) | 스피커 검증을위한 일반화 된 엔드 투 엔드 손실 | 이 repo |
| 데이터 세트 | 원래 소스 | 대체 출처 |
|---|---|---|
| Aidatatang_200ZH | Openslr | 구글 드라이브 |
| MagicData | Openslr | Google 드라이브 (Dev Set) |
| Aishell3 | Openslr | 구글 드라이브 |
| data_aishell | Openslr |
Aidatatang_200ZH를 압축 한 후
aidatatang_200zhcorpustrain의 모든 파일을 압축해야합니다.
<datasets_root> 이란 무엇입니까? 데이터 세트 경로가 D:dataaidatatang_200zh 인 경우 <datasets_root> 는 D:data 입니다.
신디사이저를 훈련시킵니다 : Batch_size를 synthesizer/hparams.py 에서 조정하십시오
//Before tts_schedule = [(2, 1e-3, 20_000, 12), # Progressive training schedule (2, 5e-4, 40_000, 12), # (r, lr, step, batch_size) (2, 2e-4, 80_000, 12), # (2, 1e-4, 160_000, 12), # r = reduction factor (# of mel frames (2, 3e-5, 320_000, 12), # synthesized for each decoder iteration) (2, 1e-5, 640_000, 12)], # lr = learning rate //After tts_schedule = [(2, 1e-3, 20_000, 8), # Progressive training schedule (2, 5e-4, 40_000, 8), # (r, lr, step, batch_size) (2, 2e-4, 80_000, 8), # (2, 1e-4, 160_000, 8), # r = reduction factor (# of mel frames (2, 3e-5, 320_000, 8), # synthesized for each decoder iteration) (2, 1e-5, 640_000, 8)], # lr = learning rate
Train Vocoder 준비 데이터 데이터 : Batch_size를 synthesizer/hparams.py 에서 조정하십시오
//Before ### Data Preprocessing max_mel_frames = 900, rescale = True, rescaling_max = 0.9, synthesis_batch_size = 16, # For vocoder preprocessing and inference. //After ### Data Preprocessing max_mel_frames = 900, rescale = True, rescaling_max = 0.9, synthesis_batch_size = 8, # For vocoder preprocessing and inference.
보코더 트레인을 기차로 트레이닝하십시오. 보코더 : vocoder/wavernn/hparams.py 에서 batch_size를 조정하십시오
//Before # Training voc_batch_size = 100 voc_lr = 1e-4 voc_gen_at_checkpoint = 5 voc_pad = 2 //After # Training voc_batch_size = 6 voc_lr = 1e-4 voc_gen_at_checkpoint = 5 voc_pad =2
RuntimeError: Error(s) in loading state_dict for Tacotron: size mismatch for encoder.embedding.weight: copying a param with shape torch.Size([70, 512]) from checkpoint, the shape in current model is torch.Size([75, 512]).이슈 #37을 참조하십시오
개선하기 위해 적절하게 Batch_size를 조정하십시오
the page file is too small to complete the operation 어떨까요?이 비디오를 참조하고 가상 메모리를 100G (102400)로 변경하십시오. 예 : 파일이 d 디스크에 배치되면 d 디스크의 가상 메모리가 변경됩니다.
참고로, 18k 단계 후에 주목을 받았으며 50k 단계 후에 손실이 0.4보다 낮아졌습니다.