MockingBird
1.0.0
Bien que je ne mette plus activement à mettre à jour activement ce dépôt, vous pouvez me trouver en continu en poussant cette technologie vers un bon côté et une open source. Je construis également une version optimisée et hébergée par le cloud: https://noiz.ai/ et c'est gratuit mais pas prêt pour un usage commercial maintenant.

Anglais | 中文 | 中文 Linux
Mandarin pris en charge chinois et testé avec plusieurs ensembles de données: aidatatang_200zh, magicdata, Aishell3, data_aishell, etc.
Pytorch a travaillé pour Pytorch, testé dans la version de 1.9.0 (dernier en août 2021), avec GPU Tesla T4 et GTX 2060
Windows + Linux s'exécute dans le système d'exploitation Windows et Linux (même dans M1 MacOS)
Effet facile et génial avec seulement un synthétiseur nouvellement formé, en réutilisant le codeur / vocodeur pré-entraîné
Webserver prêt à servir votre résultat avec des appels à distance
Suivez le dépôt d'origine pour tester si vous êtes prêt à tout environnement. ** Python 3.7 ou plus ** est nécessaire pour exécuter la boîte à outils.
Installez Pytorch.
Si vous obtenez une
ERROR: Could not find a version that satisfies the requirement torch==1.9.0+cu102 (from versions: 0.1.2, 0.1.2.post1, 0.1.2.post2 )Cette erreur est probablement due à un Version basse de Python, essayez d'utiliser 3.9 et il s'installera avec succès
Installez FFMPEG.
Exécutez pip install -r requirements.txt pour installer les packages nécessaires restants.
L'environnement recommandé ici est
Repo Tag 0.0.1Pytorch1.9.0 with Torchvision0.10.0 and cudatoolkit10.2requirements.txtwebrtcvad-wheelspourrequirements. txta été exporté il y a quelques mois, donc cela ne fonctionne pas avec des versions plus récentes
Installez webrtcvad pip install webrtcvad-wheels (si vous en avez besoin)
ou
Installez les dépendances avec conda ou mamba
conda env create -n env_name -f env.yml
mamba env create -n env_name -f env.yml
Créera un environnement virtuel lorsque les dépendances nécessaires sont installées. Passez au nouvel environnement par conda activate env_name et profitez-en.
Env.yml ne comprend que les dépendances nécessaires pour exécuter le projet , temporairement sans aligne monotone. Vous pouvez consulter le site officiel pour installer la version GPU de Pytorch.
Les étapes suivantes sont une solution de contournement pour utiliser directement
demo_toolbox.pyoriginal sans la modification des codes.Étant donné que le problème majeur est livré avec les packages PYQT5 utilisés dans
demo_toolbox.pynon compatibles avec les puces M1, ont été des modèles de formation avec la puce M1, soit cette personne peut renoncerdemo_toolbox.py, soit on peut essayer leweb.pydans Le projet.
PyQt5 , avec ref.Créez et ouvrez un terminal Rosetta, avec ref.
Utilisez System Python pour créer un environnement virtuel pour le projet
/usr/bin/python3 -m venv /PathToMockingBird/venv source /PathToMockingBird/venv/bin/activate
Améliorer PIP et installer PyQt5
pip install --upgrade pip pip install pyqt5
pyworld et ctc-segmentationLes deux packages semblent être uniques à ce projet et ne sont pas vus dans le projet de clonage vocal en temps réel. Lors de l'installation avec
pip install, les deux packages manquent de roues, le programme essaie donc de compiler directement à partir du code C et n'a pas pu trouverPython.h.
Installer pyworld
brew install python Python.h peut venir avec Python installé par Brew
export CPLUS_INCLUDE_PATH=/opt/homebrew/Frameworks/Python.framework/Headers Le fil de file Python.h est unique à M1 MacOS et répertorié ci-dessus. Il faut ajouter manuellement le chemin des variables d'environnement.
pip install pyworld qui devrait faire.
Installer ctc-segmentation
La même méthode ne s'applique pas à
ctc-segmentation, et il faut le compiler à partir du code source sur GitHub.
git clone https://github.com/lumaku/ctc-segmentation.git
cd ctc-segmentation
source /PathToMockingBird/venv/bin/activate si l'environnement virtuel n'a pas été déployé, activez-le.
cythonize -3 ctc_segmentation/ctc_segmentation_dyn.pyx
/usr/bin/arch -x86_64 python setup.py build build avec architecture x86.
/usr/bin/arch -x86_64 python setup.py install --optimize=1 --skip-build install with x86 architecture.
/usr/bin/arch -x86_64 pip install torch torchvision torchaudio pip installer PyTorch à titre d'exemple, articulez qu'il est installé avec une architecture x86
pip install ffmpeg installer ffmpeg
pip install -r requirements.txt installer d'autres exigences.
Pour exécuter le projet sur l'architecture x86. Réf.
vim /PathToMockingBird/venv/bin/pythonM1 Créez un fichier exécutable pythonM1 pour conditionner l'interpréteur python at /PathToMockingBird/venv/bin .
Écrivez dans le contenu suivant:
#!/usr/bin/env zsh
mydir=${0:a:h}
/usr/bin/arch -x86_64 $mydir/python "$@" chmod +x pythonM1 Définissez le fichier comme exécutable.
Si vous utilisez PyCharm IDE, configurez l'interprète de projet sur pythonM1 (étapes ici), si vous utilisez la ligne de commande python, exécuter /PathToMockingBird/venv/bin/pythonM1 demo_toolbox.py
Notez que nous utilisons le codeur / vocodeur pré-entraîné mais pas le synthétiseur, car le modèle original est incompatible avec les symboles chinois. Cela signifie que Demo_cli ne fonctionne pas en ce moment, donc des modèles de synthétiseur supplémentaires sont nécessaires.
Vous pouvez soit former vos modèles ou utiliser ceux existants:
Prétraitement avec l'audios et les spectrogrammes MEL: python encoder_preprocess.py <datasets_root> Autoriser le paramètre --dataset {dataset} pour prendre en charge les ensembles de données que vous souhaitez prétraiter. Seul l'ensemble de train de ces ensembles de données sera utilisé. Noms possibles: LibRispenech_other, Voxceleb1, Voxceleb2. Utilisez des virgules pour spirer plusieurs ensembles de données.
Former l'encodeur: python encoder_train.py my_run <datasets_root>/SV2TTS/encoder
Pour la formation, l'encodeur utilise Visdom. Vous pouvez le désactiver avec
--no_visdom, mais c'est bien d'avoir. Exécutez "Visdom" dans un CLI / processus séparé pour démarrer votre serveur Visdom.
Téléchargez un ensemble de données et unzip: assurez-vous que vous pouvez accéder à tous les .wav dans le dossier
Prétraitement avec les audios et les spectrogrammes MEL: python pre.py <datasets_root> Autoriser le paramètre --dataset {dataset} pour prendre en charge Aidatatang_200ZH, MagicData, Aishell3, Data_aishell, etc. Si ce paramètre n'est pas passé, l'ensemble de données par défaut sera Aidatatang_200zh.
Train le synthétiseur: python train.py --type=synth mandarin <datasets_root>/SV2TTS/synthesizer
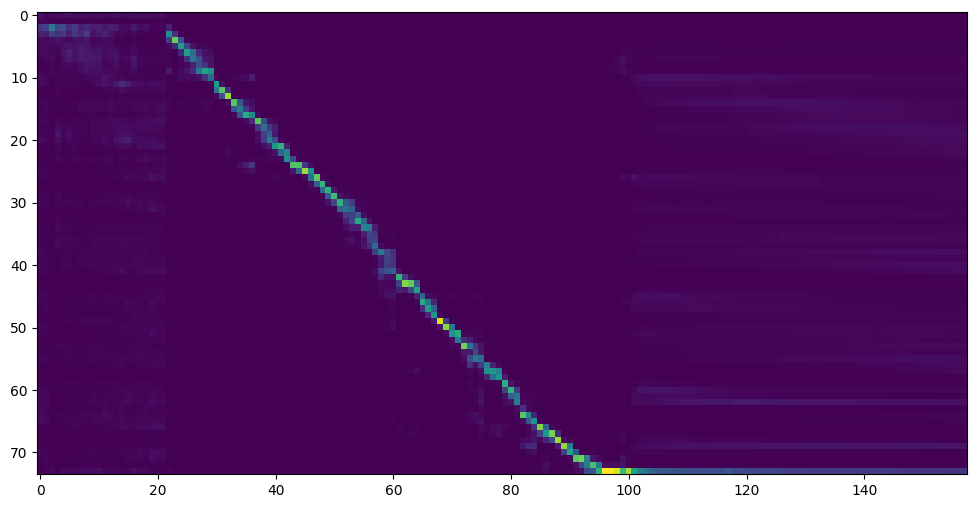
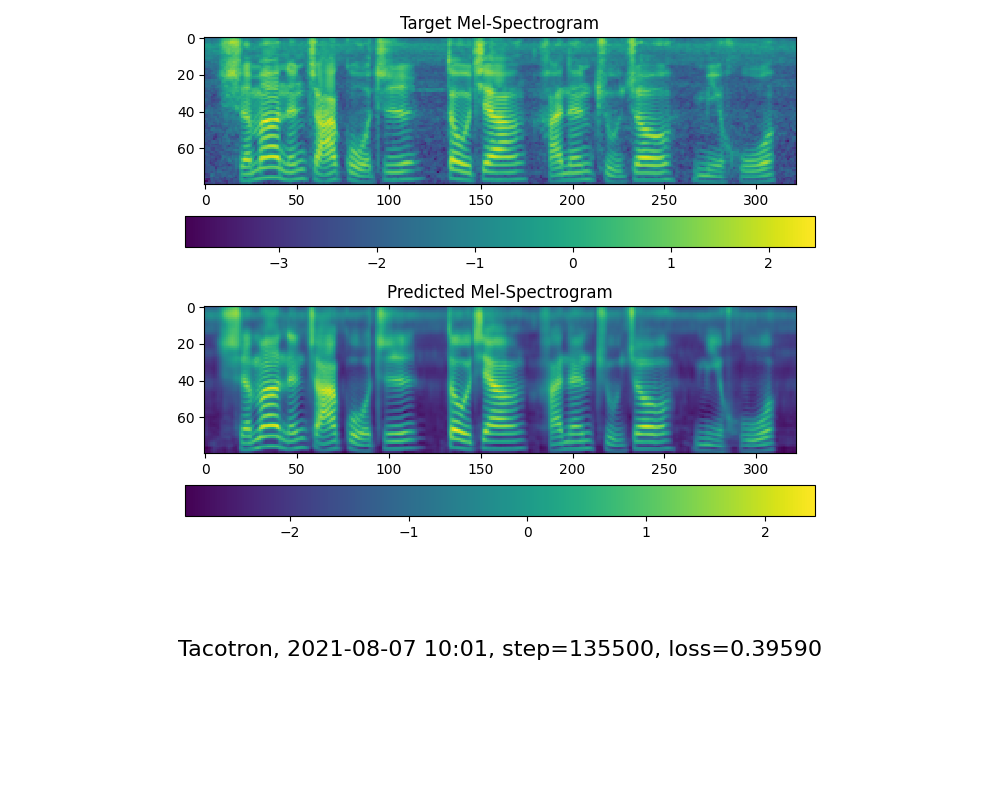
Accédez à l'étape suivante lorsque vous voyez la ligne d'attention Show and Loss répondre à vos besoins dans le dossier de formation Synthesizer / SAVED_Models / .
Grâce à la communauté, certains modèles seront partagés:
| auteur | Lien de téléchargement | Aperçu de la vidéo | Info |
|---|---|---|---|
| @auteur | https://pan.baidu.com/s/1ionvrxmki-t1nhqxkyty3g baidu 4j5d | 75k étapes formées par plusieurs ensembles de données | |
| @auteur | https://pan.baidu.com/s/1fmh9ilgkjll2piirtyduvw baidu Code: OM7f | 25K étapes formées par plusieurs ensembles de données, ne fonctionne que sous la version 0.0.1 | |
| @Fawenyo | https://yisiou-my.sharepoint.com/:u:/g/personal/lawrence_cheng_fawenyo_onmicrosoft_com/ewfwdhzee-ng9twdkckcc4bc7bk2j9ccbown0-_tk0nog?e=n0gggccc | sortie d'entrée | 200K étapes avec l'accent local de Taiwan, ne fonctionne que sous la version 0.0.1 |
| @miven | https://pan.baidu.com/s/1pi-hm3sn5wbechrryx-rcq Code: 2021 https://www.aliyundrive.com/s/awpsbo8mcsp Code: Z2M0 | https://www.bilibili.com/video/bv1uh411b7ad/ | Fonctionne uniquement sous la version 0.0.1 |
Remarque: Vocoder a peu de différence en vigueur, vous n'aurez peut-être pas besoin d'en former un nouveau.
Prétrangez les données: python vocoder_preprocess.py <datasets_root> -m <synthesizer_model_path>
<datasets_root>Remplacez par la racine de votre ensemble de données ,<synthesizer_model_path>Remplacez par le répertoire de vos modèles les mieux formés de Sythensizer, par exemple SythenSizeSaved_Modexxx
Train the wavernn vocoder: python vocoder_train.py mandarin <datasets_root>
Former le Vocoder Hifigan python vocoder_train.py mandarin <datasets_root> hifigan
Vous pouvez ensuite essayer d'exécuter: python web.py et l'ouvrir dans le navigateur, par défaut comme http://localhost:8080
Vous pouvez ensuite essayer la boîte à outils: python demo_toolbox.py -d <datasets_root>
Vous pouvez ensuite essayer la commande: python gen_voice.py <text_file.txt> your_wav_file.wav Vous devrez peut-être installer CN2AN par "PIP installe CN2AN" pour un meilleur résultat numérique.
Ce référentiel est issu de la clonage en temps réel qui ne prend en charge que l'anglais.
| URL | Désignation | Titre | Source d'implémentation |
|---|---|---|---|
| 1803.09017 | GlobalStyleToken (synthétiseur) | Tokens de style: modélisation, contrôle et transfert de style non supervisé dans la synthèse de la parole de bout en bout | Ce repo |
| 2010.05646 | Hifi-gan (vocoder) | Réseaux adversaires génératifs pour une synthèse de parole efficace et haute fidélité | Ce repo |
| 2106.02297 | Fre-gan (vocodeur) | Fre-Gan: synthèse audio cohérente adversaire en fréquence | Ce repo |
| 1806.04558 | Sv2tts | Transférer l'apprentissage de la vérification des conférenciers à la synthèse de texte-vocation multippeaker | Ce repo |
| 1802.08435 | Wavernn (vocoder) | Synthèse audio neuronale efficace | fatchord / wavernn |
| 1703.10135 | Tacotron (synthétiseur) | Tacotron: Vers la synthèse de la parole de bout en bout | fatchord / wavernn |
| 1710.10467 | GE2E (Encodeur) | Perte généralisée de bout en bout pour la vérification des orateurs | Ce repo |
| Ensemble de données | Source d'origine | Sources alternatives |
|---|---|---|
| aidatatang_200zh | OpenSLR | Google Drive |
| magie | OpenSLR | Google Drive (Set Dev) |
| Aishell3 | OpenSLR | Google Drive |
| data_aishell | OpenSLR |
Après unzip aidatatang_200zh, vous devez dézip tous les fichiers sous
aidatatang_200zhcorpustrain
<datasets_root> ? Si le chemin du jeu de données est D:dataaidatatang_200zh , alors <datasets_root> est D:data
Former le synthétiseur: ajustez le Batch_Size dans synthesizer/hparams.py
//Before tts_schedule = [(2, 1e-3, 20_000, 12), # Progressive training schedule (2, 5e-4, 40_000, 12), # (r, lr, step, batch_size) (2, 2e-4, 80_000, 12), # (2, 1e-4, 160_000, 12), # r = reduction factor (# of mel frames (2, 3e-5, 320_000, 12), # synthesized for each decoder iteration) (2, 1e-5, 640_000, 12)], # lr = learning rate //After tts_schedule = [(2, 1e-3, 20_000, 8), # Progressive training schedule (2, 5e-4, 40_000, 8), # (r, lr, step, batch_size) (2, 2e-4, 80_000, 8), # (2, 1e-4, 160_000, 8), # r = reduction factor (# of mel frames (2, 3e-5, 320_000, 8), # synthesized for each decoder iteration) (2, 1e-5, 640_000, 8)], # lr = learning rate
Train Vocoder-Preprocess Les données: Ajustez le Batch_Size dans synthesizer/hparams.py
//Before ### Data Preprocessing max_mel_frames = 900, rescale = True, rescaling_max = 0.9, synthesis_batch_size = 16, # For vocoder preprocessing and inference. //After ### Data Preprocessing max_mel_frames = 900, rescale = True, rescaling_max = 0.9, synthesis_batch_size = 8, # For vocoder preprocessing and inference.
Train Vocoder-Train the Vocoder: Ajustez le Batch_Size dans vocoder/wavernn/hparams.py
//Before # Training voc_batch_size = 100 voc_lr = 1e-4 voc_gen_at_checkpoint = 5 voc_pad = 2 //After # Training voc_batch_size = 6 voc_lr = 1e-4 voc_gen_at_checkpoint = 5 voc_pad =2
RuntimeError: Error(s) in loading state_dict for Tacotron: size mismatch for encoder.embedding.weight: copying a param with shape torch.Size([70, 512]) from checkpoint, the shape in current model is torch.Size([75, 512]).Veuillez vous référer au problème n ° 37
Ajustez le Batch_Size, le cas échéant pour améliorer
the page file is too small to complete the operationVeuillez vous référer à cette vidéo et modifier la mémoire virtuelle en 100g (102400), par exemple: lorsque le fichier est placé sur le disque D, la mémoire virtuelle du disque D est modifiée.
Pour info, mon attention est intervenue après 18 000 marches et la perte est devenue inférieure à 0,4 après 50 km.