MockingBird
1.0.0
على الرغم من أنني لم أعد أقوم بتحديث هذا الريبو بنشاط ، إلا أنه يمكنك أن تجدني دفع هذه التقنية باستمرار إلى جانب جيد ومصدر مفتوح. أنا أيضًا أقوم ببناء نسخة مستضافة محسّنة ومستضافة: https://noiz.ai/ وهي مجانية ولكنها ليست جاهزة للاستخدام التجاري الآن.

الإنجليزية | 中文 | 中文 Linux
الماندرين الصيني المدعوم واختباره مع مجموعات بيانات متعددة: Aidatatang_200ZH ، MagicData ، Aishell3 ، Data_aishell ، وما إلى ذلك.
عملت Pytorch في Pytorch ، التي تم اختبارها في إصدار 1.9.0 (الأحدث في أغسطس 2021) ، مع GPU Tesla T4 و GTX 2060
يعمل Windows + Linux في كل من نظام التشغيل Windows و Linux OS (حتى في M1 MacOS)
تأثير سهل ورائع مع مزج تم توليفه تم تدريبه حديثًا ، عن طريق إعادة استخدام المشفر/المتفرج المسبق
خادم ويب جاهز لتقديم نتائجك مع الاتصال عن بُعد
اتبع الريبو الأصلي لاختبار إذا كنت جاهزًا للبيئة. ** Python 3.7 أو أعلى ** مطلوب لتشغيل صندوق الأدوات.
تثبيت Pytorch.
إذا حصلت على
ERROR: Could not find a version that satisfies the requirement torch==1.9.0+cu102 (from versions: 0.1.2, 0.1.2.post1, 0.1.2.post2 )نسخة منخفضة من Python ، حاول استخدام 3.9 وسيتم تثبيتها بنجاح
تثبيت FFMPEG.
قم بتشغيل pip install -r requirements.txt لتثبيت الحزم الضرورية المتبقية.
البيئة
webrtcvad-wheelsبها هنا هيRepo Tag 0.0.1Pytorch1.9.0 with Torchvision0.10.0 and cudatoolkit10.2requirements.txtrequirements. txtتم تصديرrequirements. txtقبل بضعة أشهر ، لذلك لا يعمل مع إصدارات أحدث
تثبيت Webrtcvad pip install webrtcvad-wheels (إذا كنت بحاجة)
أو
تثبيت التبعيات مع conda أو mamba
conda env create -n env_name -f env.yml
mamba env create -n env_name -f env.yml
سيخلق بيئة افتراضية عند تثبيت التبعيات اللازمة. قم بالتبديل إلى البيئة الجديدة بواسطة conda activate env_name واستمتع بها.
يتضمن Env.Yml التبعيات اللازمة فقط لتشغيل المشروع-مؤقتًا دون محاذاة رتابة. يمكنك التحقق من الموقع الرسمي لتثبيت إصدار GPU من Pytorch.
الخطوات التالية هي حل بديل لاستخدام
demo_toolbox.pyالأصلي دون تغيير الرموز.نظرًا لأن المشكلة الرئيسية تأتي مع حزم PYQT5 المستخدمة في
demo_toolbox.pyغير متوافق مع رقائق M1 ، كانت واحدة لمحاولة على نماذج التدريب باستخدام شريحة M1 ، إما أن يتخلى هذا الشخص عنdemo_toolbox.py، أو يمكن للمرء تجربةweb.py. المشروع.
PyQt5 ، مع المرجع هنا.إنشاء وفتح محطة Rosetta ، مع المرجع هنا.
استخدم نظام Python لإنشاء بيئة افتراضية للمشروع
/usr/bin/python3 -m venv /PathToMockingBird/venv source /PathToMockingBird/venv/bin/activate
ترقية PIP وتثبيت PyQt5
pip install --upgrade pip pip install pyqt5
pyworld و ctc-segmentationيبدو أن كلتا الحزمتين فريدة لهذا المشروع ولا يتم رؤيتها في مشروع استنساخ الصوت الأصلي في الوقت الفعلي. عند التثبيت مع
pip install، تفتقر كلا الحزمان إلى عجلات ، لذا يحاول البرنامج تجميعها مباشرة من رمز C ولم يتمكن من العثور علىPython.h.
تثبيت pyworld
brew install python Python.h يمكن أن يأتي مع Python مثبتة بواسطة Brew
export CPLUS_INCLUDE_PATH=/opt/homebrew/Frameworks/Python.framework/Headers filepath من Python.h . يحتاج المرء إلى إضافة المسار يدويًا إلى متغيرات البيئة.
pip install pyworld التي ينبغي أن تفعل.
تثبيت ctc-segmentation
لا تنطبق نفس الطريقة على
ctc-segmentation، ويحتاج المرء إلى تجميعه من الرمز المصدر على Github.
git clone https://github.com/lumaku/ctc-segmentation.git
cd ctc-segmentation
source /PathToMockingBird/venv/bin/activate إذا لم يتم نشر البيئة الافتراضية ، تنشطها.
cythonize -3 ctc_segmentation/ctc_segmentation_dyn.pyx
/usr/bin/arch -x86_64 python setup.py build build with x86 Architecture.
/usr/bin/arch -x86_64 python setup.py install --optimize=1 --skip-build تثبيت مع بنية X86.
/usr/bin/arch -x86_64 pip install torch torchvision torchaudio pip تثبيت PyTorch كمثال على ذلك ، يعبر عن تثبيته مع بنية x86
pip install ffmpeg تثبيت FFMPEG
pip install -r requirements.txt تثبيت متطلبات أخرى.
لتشغيل المشروع على X86 Architecture. المرجع.
vim /PathToMockingBird/venv/bin/pythonM1 إنشاء ملف قابل للتنفيذ pythonM1 لشرط المترجم Python في /PathToMockingBird/venv/bin .
اكتب في المحتوى التالي:
#!/usr/bin/env zsh
mydir=${0:a:h}
/usr/bin/arch -x86_64 $mydir/python "$@" chmod +x pythonM1 قم بتعيين الملف على أنه قابل للتنفيذ.
في حالة استخدام Pycharm IDE ، قم بتكوين مترجم المشروع إلى pythonM1 (الخطوات هنا) ، إذا كان استخدام سطر الأوامر Python ، Run /PathToMockingBird/venv/bin/pythonM1 demo_toolbox.py
لاحظ أننا نستخدم التشفير/المتفرجات المسبق ولكن ليس المزج ، لأن النموذج الأصلي غير متوافق مع الرموز الصينية. وهذا يعني أن demo_cli لا يعمل في هذه اللحظة ، لذلك مطلوب نماذج مزج إضافية.
يمكنك إما تدريب النماذج الخاصة بك أو استخدام النماذج الموجودة:
المعالجة المسبقة مع Audios و MELPLICTORGRAMS: python encoder_preprocess.py <datasets_root> السماح للمعلمة --dataset {dataset} لدعم مجموعات البيانات التي تريد المعالجة المسبقة. سيتم استخدام مجموعة القطار فقط من مجموعات البيانات هذه. الأسماء الممكنة: Librispeech_other ، voxceleb1 ، voxceleb2. استخدام الفاصلة لسباحة مجموعات البيانات المتعددة.
تدريب الترميز: python encoder_train.py my_run <datasets_root>/SV2TTS/encoder
للتدريب ، يستخدم المشفر Visdom. يمكنك تعطيله
--no_visdom، لكن من الجيد أن يكون لديك. قم بتشغيل "Visdom" في عملية CLI/عملية منفصلة لبدء خادم Visdom الخاص بك.
قم بتنزيل DataSet و Unzip: تأكد من أنه يمكنك الوصول إلى كل .wav في المجلد
المعالجة المسبقة مع Audios و MELPLICTORGRAMS: python pre.py <datasets_root> السماح للمعلمة --dataset {dataset} لدعم Aidatatang_200ZH ، MagicData ، Aishell3 ، Data_aishell ، إلخ.
تدريب المخلف: python train.py --type=synth mandarin <datasets_root>/SV2TTS/synthesizer
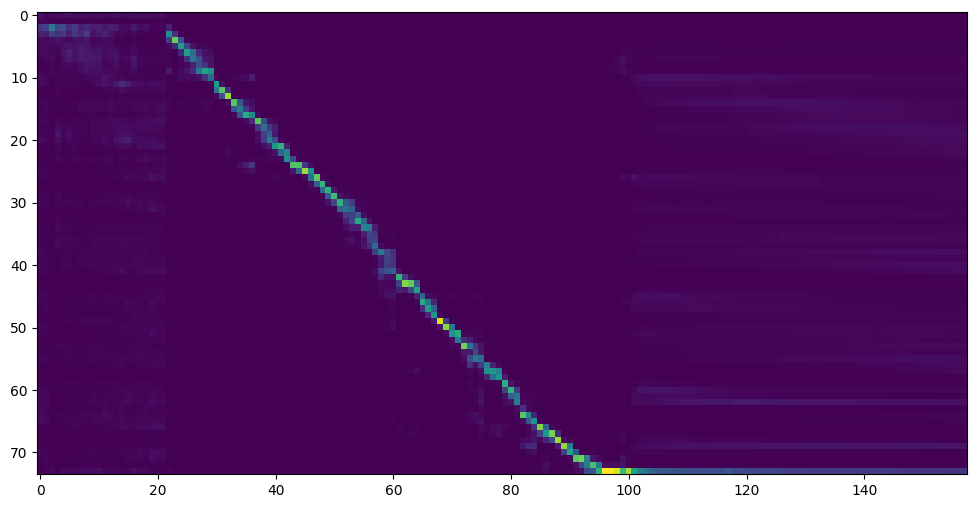
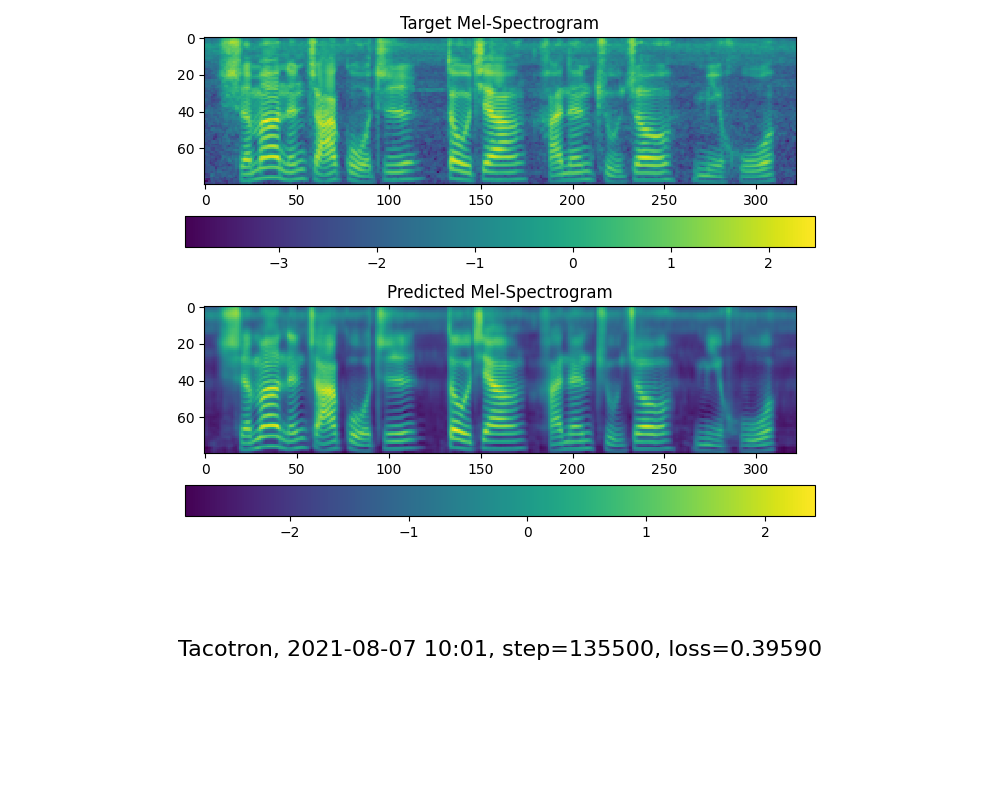
انتقل إلى الخطوة التالية عندما ترى عرض خط الانتباه والخسارة تلبي احتياجاتك في مزج مجلد التدريب/ Save_Models/ .
بفضل المجتمع ، سيتم مشاركة بعض النماذج:
| مؤلف | الرابط تنزيل | معاينة الفيديو | معلومات |
|---|---|---|---|
| @مؤلف | https://pan.baidu.com/s/1ionvrxmki-t1nhqxkyty3g baidu 4j5d | 75 ألف خطوة تدربها مجموعات بيانات متعددة | |
| @مؤلف | https://pan.baidu.com/s/1fmh9ilgkjll2piirtyduvw رمز baidu : om7f | 25K خطوة تدربها مجموعات بيانات متعددة ، تعمل فقط تحت الإصدار 0.0.1 | |
| fawenyo | https://yisiou-my.sharepoint.com/:u:/g/personal/lawrence_cheng_fawenyo_onmicrosoft_com/ewfwdhzee-nng9twdkccc4bc7bk2j9ccbown0nog؟ | إخراج الإدخال | 200k خطوة مع لهجة تايوان المحلية ، يعمل فقط تحت الإصدار 0.0.1 |
| miven | https://pan.baidu.com/s/1pi-hm3sn5wbechrryx-rcq الكود: 2021 https://www.aliyundrive.com/s/awpsbo8mcsp الرمز: Z2M0 | https://www.bilibili.com/video/bv1uh411b7ad/ | يعمل فقط تحت الإصدار 0.0.1 |
ملاحظة: لدى Vocoder فرقًا كبيرًا في الواقع ، لذلك قد لا تحتاج إلى تدريب واحدة جديدة.
المعالجة المسبقة للبيانات: python vocoder_preprocess.py <datasets_root> -m <synthesizer_model_path>
<datasets_root>استبدل بجذر مجموعة البيانات الخاصة بك ,<synthesizer_model_path>استبدال مع دليل أفضل نماذج مدربة من Sythensizer ، على سبيل المثال sythensizersaved_modexxx
تدريب Wavernn Vocoder: python vocoder_train.py mandarin <datasets_root>
تدريب Hifigan Vocoder python vocoder_train.py mandarin <datasets_root> hifigan
يمكنك بعد ذلك محاولة التشغيل: python web.py وفتحه في المتصفح ، افتراضيًا مثل http://localhost:8080
يمكنك بعد ذلك تجربة مربع الأدوات: python demo_toolbox.py -d <datasets_root>
يمكنك بعد ذلك تجربة الأمر: python gen_voice.py <text_file.txt> your_wav_file.wav قد تحتاج إلى تثبيت CN2AN بواسطة "PIP تثبيت CN2AN" للحصول على نتيجة رقمية أفضل.
هذا المستودع متشعب من تشييد الصناديق في الوقت الفعلي والذي يدعم اللغة الإنجليزية فقط.
| عنوان URL | تعيين | عنوان | مصدر التنفيذ |
|---|---|---|---|
| 1803.09017 | GlobalStySteroken (Synthesizer) | الرموز النمطية: نمذجة النمذجة غير الخاضعة للرقابة والتحكم والنقل في تخليق الكلام من طرف إلى طرف | هذا الريبو |
| 2010.05646 | HIFI-GAN (VOCODER) | شبكات الخصومة التوليدية لتوليف خطاب فعال وعالي الإخلاص | هذا الريبو |
| 2106.02297 | FRE-VAN (VOCODER) | FRE-VAN: تخليق الصوت المتسق للترددات العدائية | هذا الريبو |
| 1806.04558 | SV2TTS | نقل التعلم من التحقق من مكبر الصوت إلى توليف النص إلى كلام متعدد النطاقات | هذا الريبو |
| 1802.08435 | Wavernn (Vocoder) | تخليق الصوت العصبي الفعال | Fatchord/Wavernn |
| 1703.10135 | تاكوترون (مزج) | تاكوترون: نحو تخليق الكلام من شوط إلى النهاية | Fatchord/Wavernn |
| 1710.10467 | GE2E (تشفير) | خسارة معممة من طرف إلى طرف للتحقق من المتحدثين | هذا الريبو |
| مجموعة البيانات | المصدر الأصلي | مصادر بديلة |
|---|---|---|
| Aidatatang_200zh | openslr | محرك Google |
| MagicData | openslr | Google Drive (مجموعة DEV) |
| Aishell3 | openslr | محرك Google |
| data_aishell | openslr |
بعد unsip Aidatatang_200ZH ، تحتاج إلى فك ضغط جميع الملفات بموجب
aidatatang_200zhcorpustrain
<datasets_root> ؟ إذا كان مسار مجموعة البيانات D:dataaidatatang_200zh ، فإن <datasets_root> هو D:data
تدريب المزيج : اضبط batch_size في synthesizer/hparams.py
//Before tts_schedule = [(2, 1e-3, 20_000, 12), # Progressive training schedule (2, 5e-4, 40_000, 12), # (r, lr, step, batch_size) (2, 2e-4, 80_000, 12), # (2, 1e-4, 160_000, 12), # r = reduction factor (# of mel frames (2, 3e-5, 320_000, 12), # synthesized for each decoder iteration) (2, 1e-5, 640_000, 12)], # lr = learning rate //After tts_schedule = [(2, 1e-3, 20_000, 8), # Progressive training schedule (2, 5e-4, 40_000, 8), # (r, lr, step, batch_size) (2, 2e-4, 80_000, 8), # (2, 1e-4, 160_000, 8), # r = reduction factor (# of mel frames (2, 3e-5, 320_000, 8), # synthesized for each decoder iteration) (2, 1e-5, 640_000, 8)], # lr = learning rate
المعالجة المفرطة في القطار البيانات : اضبط batch_size في synthesizer/hparams.py
//Before ### Data Preprocessing max_mel_frames = 900, rescale = True, rescaling_max = 0.9, synthesis_batch_size = 16, # For vocoder preprocessing and inference. //After ### Data Preprocessing max_mel_frames = 900, rescale = True, rescaling_max = 0.9, synthesis_batch_size = 8, # For vocoder preprocessing and inference.
Train Vocoder-Train the Vocoder : اضبط Batch_size في vocoder/wavernn/hparams.py
//Before # Training voc_batch_size = 100 voc_lr = 1e-4 voc_gen_at_checkpoint = 5 voc_pad = 2 //After # Training voc_batch_size = 6 voc_lr = 1e-4 voc_gen_at_checkpoint = 5 voc_pad =2
RuntimeError: Error(s) in loading state_dict for Tacotron: size mismatch for encoder.embedding.weight: copying a param with shape torch.Size([70, 512]) from checkpoint, the shape in current model is torch.Size([75, 512]).يرجى الرجوع إلى العدد رقم 37
اضبط batch_size حسب الاقتضاء للتحسين
the page file is too small to complete the operationيرجى الرجوع إلى هذا الفيديو وتغيير الذاكرة الافتراضية إلى 100 جرام (102400) ، على سبيل المثال: عندما يتم وضع الملف في القرص D ، يتم تغيير الذاكرة الافتراضية للقرص D.
لمعلوماتك ، جاء انتباهي بعد 18 ألف خطوة وأصبحت الخسارة أقل من 0.4 بعد 50 ألف خطوة.