MockingBird
1.0.0
ในขณะที่ฉันไม่ได้อัปเดต repo นี้อีกต่อไปคุณสามารถพบว่าฉันผลักดันเทคโนโลยีนี้ไปยังด้านที่ดีและโอเพนซอร์ซอย่างต่อเนื่อง ฉันยังกำลังสร้างเวอร์ชันที่ได้รับการปรับปรุงและโฮสต์บนคลาวด์: https://noiz.ai/ และฟรี แต่ยังไม่พร้อมสำหรับการใช้งานเชิงพาณิชย์ตอนนี้

ภาษาอังกฤษ | 中文 | 中文 Linux
จีน ที่รองรับภาษาจีนกลางและทดสอบด้วยชุดข้อมูลหลายชุด: AIDATATANG_200ZH, MagicData, Aishell3, Data_aishell และอื่น ๆ
Pytorch ทำงานให้กับ Pytorch ทดสอบในรุ่น 1.9.0 (ล่าสุดในเดือนสิงหาคม 2564) โดยมี GPU Tesla T4 และ GTX 2060
Windows + Linux ทำงานทั้ง Windows OS และ Linux OS (แม้ใน M1 MacOS)
เอฟเฟกต์ ง่ายและยอดเยี่ยม ด้วยซินธิไซเซอร์ที่ได้รับการฝึกฝนมาใหม่เท่านั้น
เว็บเซิร์ฟเวอร์พร้อม ที่จะให้บริการผลลัพธ์ของคุณด้วยการโทรจากระยะไกล
ติดตาม repo ดั้งเดิมเพื่อทดสอบว่าคุณมีสภาพแวดล้อมทั้งหมดพร้อมหรือไม่ ** Python 3.7 หรือสูงกว่า ** เป็นสิ่งจำเป็นในการเรียกใช้กล่องเครื่องมือ
ติดตั้ง pytorch
หากคุณได้รับ
ERROR: Could not find a version that satisfies the requirement torch==1.9.0+cu102 (from versions: 0.1.2, 0.1.2.post1, 0.1.2.post2 )ข้อผิดพลาดนี้อาจเป็นเพราะ Python รุ่นต่ำลองใช้ 3.9 และจะติดตั้งได้สำเร็จ
ติดตั้ง ffmpeg
เรียกใช้ pip install -r requirements.txt เพื่อติดตั้งแพ็คเกจที่จำเป็นที่เหลืออยู่
สภาพแวดล้อมที่แนะนำที่นี่คือ
Repo Tag 0.0.1Pytorch1.9.0 with Torchvision0.10.0 and cudatoolkit10.2requirements.txtwebrtcvad-wheelsเนื่องจากrequirements. txtถูกส่งออกเมื่อไม่กี่เดือนที่ผ่านมาดังนั้นจึงไม่ทำงานกับเวอร์ชันใหม่กว่า
ติดตั้ง webrtcvad pip install webrtcvad-wheels (ถ้าคุณต้องการ)
หรือ
ติดตั้งการพึ่งพาด้วย conda หรือ mamba
conda env create -n env_name -f env.yml
mamba env create -n env_name -f env.yml
จะสร้างสภาพแวดล้อมเสมือนจริงที่ติดตั้งการพึ่งพาที่จำเป็น เปลี่ยนไปใช้สภาพแวดล้อมใหม่โดย conda activate env_name และสนุกกับมัน
env.yml รวมถึงการพึ่งพาที่จำเป็นในการเรียกใช้โครงการ, ชั่วคราวโดยไม่ต้องลงนามแบบโมโนโทนิก คุณสามารถตรวจสอบเว็บไซต์อย่างเป็นทางการเพื่อติดตั้ง Pytorch เวอร์ชัน GPU
ขั้นตอนต่อไปนี้เป็นวิธีแก้ปัญหาที่จะใช้
demo_toolbox.pyดั้งเดิมโดยตรงโดยไม่ต้องเปลี่ยนรหัสเนื่องจากปัญหาสำคัญมาพร้อมกับแพ็คเกจ PYQT5 ที่ใช้ใน
demo_toolbox.pyไม่เข้ากันกับชิป M1 เป็นdemo_toolbox.pyในweb.pyพยายามฝึกอบรมกับชิป M1 โครงการ.
PyQt5 พร้อมอ้างอิงที่นี่สร้างและเปิดเทอร์มินัล Rosetta พร้อมอ้างอิงที่นี่
ใช้ระบบ Python เพื่อสร้างสภาพแวดล้อมเสมือนจริงสำหรับโครงการ
/usr/bin/python3 -m venv /PathToMockingBird/venv source /PathToMockingBird/venv/bin/activate
อัพเกรด PIP และติดตั้ง PyQt5
pip install --upgrade pip pip install pyqt5
pyworld และ ctc-segmentationแพ็คเกจทั้งสองดูเหมือนจะไม่ซ้ำกันในโครงการนี้และไม่เห็นในโครงการโคลนเสียงแบบเรียลไทม์ดั้งเดิม เมื่อติดตั้งด้วย
pip installแพ็คเกจทั้งสองจึงไม่มีล้อดังนั้นโปรแกรมจึงพยายามรวบรวมโดยตรงจากรหัส C และไม่พบPython.h
ติดตั้ง pyworld
brew install python Python.h สามารถมาพร้อมกับ Python ที่ติดตั้งโดย Brew
export CPLUS_INCLUDE_PATH=/opt/homebrew/Frameworks/Python.framework/Headers filepath ของ Python.h ที่ติดตั้งด้วยเบียร์ซึ่งเป็นเอกลักษณ์ของ M1 macOS และรายการด้านบน เราต้องเพิ่มเส้นทางไปยังตัวแปรสภาพแวดล้อมด้วยตนเอง
pip install pyworld ที่ควรทำ
ติดตั้ง ctc-segmentation
วิธีเดียวกันไม่ได้ใช้กับ
ctc-segmentationและหนึ่งจำเป็นต้องรวบรวมจากซอร์สโค้ดบน GitHub
git clone https://github.com/lumaku/ctc-segmentation.git
cd ctc-segmentation
source /PathToMockingBird/venv/bin/activate หากสภาพแวดล้อมเสมือนยังไม่ได้รับการปรับใช้ให้เปิดใช้งาน
cythonize -3 ctc_segmentation/ctc_segmentation_dyn.pyx
/usr/bin/arch -x86_64 python setup.py build build ด้วยสถาปัตยกรรม x86
/usr/bin/arch -x86_64 python setup.py install --optimize=1 --skip-build ด้วยสถาปัตยกรรม x86
/usr/bin/arch -x86_64 pip install torch torchvision torchaudio Pip ติดตั้ง PyTorch เป็นตัวอย่างแสดงให้เห็นว่ามันติดตั้งด้วยสถาปัตยกรรม x86
pip install ffmpeg ติดตั้ง ffmpeg
pip install -r requirements.txt ติดตั้งข้อกำหนดอื่น ๆ
เพื่อเรียกใช้โครงการบนสถาปัตยกรรม x86 อ้างอิง
vim /PathToMockingBird/venv/bin/pythonM1 สร้างไฟล์ที่ใช้งานได้ pythonM1 เพื่อเงื่อนไข Python Interpreter AT /PathToMockingBird/venv/bin
เขียนในเนื้อหาต่อไปนี้:
#!/usr/bin/env zsh
mydir=${0:a:h}
/usr/bin/arch -x86_64 $mydir/python "$@" chmod +x pythonM1 ตั้งค่าไฟล์เป็นปฏิบัติการ
หากใช้ Pycharm IDE กำหนดค่า Project Interpreter เป็น pythonM1 (ขั้นตอนที่นี่) หากใช้ Python บรรทัดคำสั่ง Run /PathToMockingBird/venv/bin/pythonM1 demo_toolbox.py
โปรดทราบว่าเรากำลังใช้ตัวเข้ารหัส/Vocoder ที่ผ่านการฝึกอบรม แต่ไม่ใช่ซินธิไซเซอร์เนื่องจากโมเดลดั้งเดิมไม่เข้ากันกับสัญลักษณ์จีน หมายความว่า DEMO_CLI ไม่ทำงานในขณะนี้ดังนั้นจึงจำเป็นต้องใช้โมเดลซินธิไซเซอร์เพิ่มเติม
คุณสามารถฝึกอบรมโมเดลของคุณหรือใช้โมเดลที่มีอยู่:
ประมวลผลล่วงหน้าด้วยเสียงและ mel spectrograms: python encoder_preprocess.py <datasets_root> การอนุญาตให้พารามิเตอร์ --dataset {dataset} เพื่อรองรับชุดข้อมูลที่คุณต้องการประมวลผลล่วงหน้า เฉพาะชุดรถไฟของชุดข้อมูลเหล่านี้เท่านั้น ชื่อที่เป็นไปได้: librispeech_other, voxceleb1, voxceleb2 ใช้เครื่องหมายจุลภาคเพื่อขยายชุดข้อมูลหลายชุด
ฝึกอบรม encoder: python encoder_train.py my_run <datasets_root>/SV2TTS/encoder
สำหรับการฝึกอบรม encoder ใช้ Visdom คุณสามารถปิดการใช้งานได้ด้วย
--no_visdomแต่ก็ดีที่มี เรียกใช้ "visdom" ใน CLI/กระบวนการแยกต่างหากเพื่อเริ่มต้นเซิร์ฟเวอร์ VISDOM ของคุณ
ดาวน์โหลดชุดข้อมูลและ UNZIP: ตรวจสอบให้แน่ใจว่าคุณสามารถเข้าถึง. wav ทั้งหมดในโฟลเดอร์
ประมวลผลล่วงหน้าด้วยเสียงและ mel spectrograms: python pre.py <datasets_root> การอนุญาตพารามิเตอร์ --dataset {dataset} เพื่อสนับสนุน Aidatatang_200zh, MagicData, aishell3, data_aishell ฯลฯ หากพารามิเตอร์นี้ไม่ผ่านดาต้า
ฝึกอบรม synthesizer: python train.py --type=synth mandarin <datasets_root>/SV2TTS/synthesizer
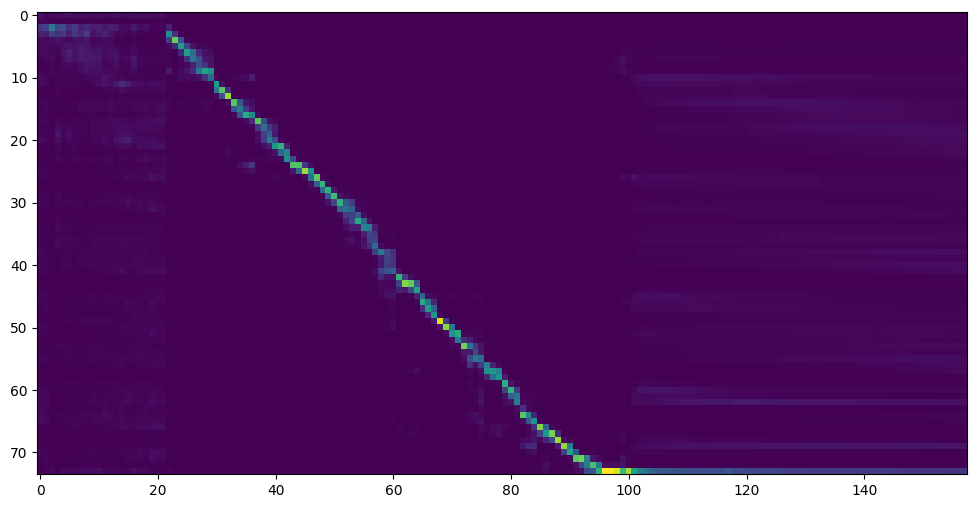
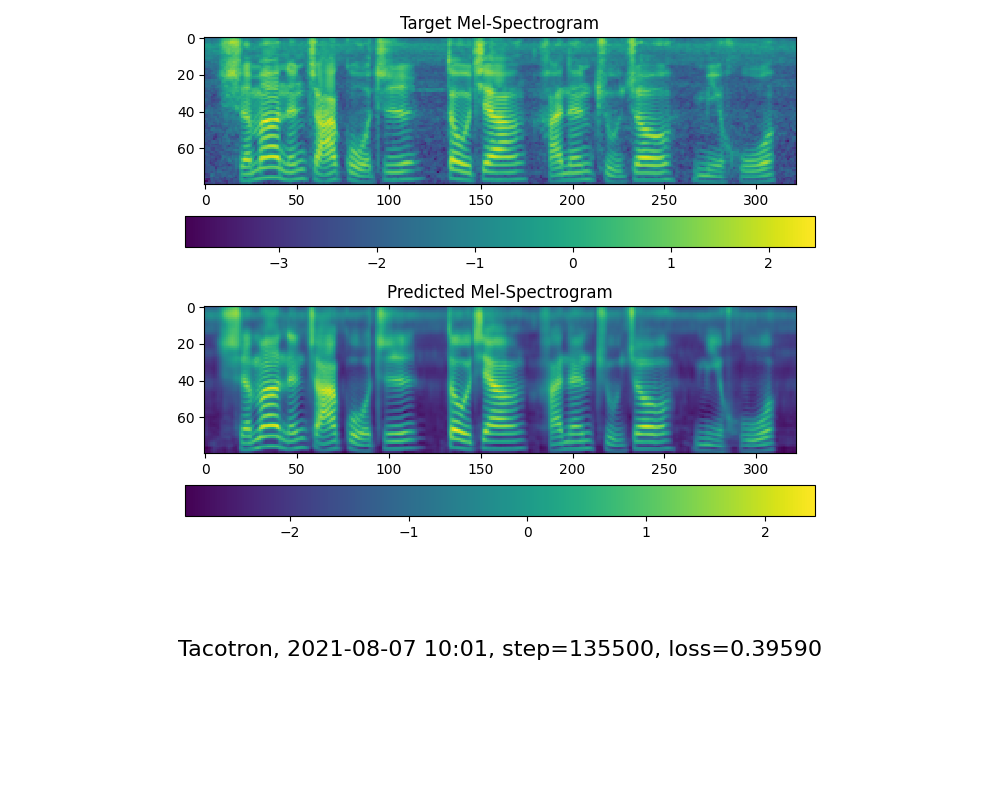
ไปที่ขั้นตอนต่อไปเมื่อคุณเห็นการแสดงสายความสนใจและการสูญเสียตอบสนองความต้องการของคุณในการฝึกอบรมโฟลเดอร์ synthesizer/ saved_models/
ขอบคุณชุมชนบางรุ่นจะถูกแบ่งปัน:
| ผู้เขียน | ลิงค์ดาวน์โหลด | ตัวอย่างวิดีโอ | ข้อมูล |
|---|---|---|---|
| @ผู้เขียน | https://pan.baidu.com/s/1ionvrxmki-t1nhqxkyty3g Baidu 4J5d | ขั้นตอน 75K ได้รับการฝึกฝนโดยชุดข้อมูลหลายชุด | |
| @ผู้เขียน | https://pan.baidu.com/s/1fmh9ilgkjll2piirtyduvw รหัส Baidu: OM7F | ขั้นตอน 25K ที่ผ่านการฝึกอบรมโดยชุดข้อมูลหลายชุดทำงานภายใต้เวอร์ชัน 0.0.1 เท่านั้น | |
| @Fawenyo | https://yisiou-my.sharepoint.com/:u:/g/personal/lawrence_cheng_fawenyo_onmicrosoft_com/ewfwdhzee-nng9twdkckcc4bc7bk2j9ccbown0-_tk0nog? | เอาต์พุตอินพุต | ขั้นตอน 200k ด้วยสำเนียงท้องถิ่นของไต้หวันทำงานภายใต้เวอร์ชัน 0.0.1 เท่านั้น |
| @miven | https://pan.baidu.com/s/1pi-hm3sn5wbechrryx-rcq รหัส: 2021 https://www.aliyundrive.com/s/awpsbo8mcsp รหัส: z2m0 | https://www.bilibili.com/video/bv1uh411b7ad/ | ใช้งานได้ภายใต้เวอร์ชัน 0.0.1 เท่านั้น |
หมายเหตุ: Vocoder มีความแตกต่างเล็กน้อยดังนั้นคุณอาจไม่จำเป็นต้องฝึกใหม่
ล่วงหน้าข้อมูล: python vocoder_preprocess.py <datasets_root> -m <synthesizer_model_path>
<datasets_root>แทนที่ด้วยรูทชุดข้อมูลของคุณ,<synthesizer_model_path>แทนที่ด้วยไดเรกทอรีของรุ่นที่ผ่านการฝึกอบรมที่ดีที่สุดของคุณของ Sythensizer เช่น sythensizersaved_modexxx
ฝึกอบรม WAVERNN VOCODER: python vocoder_train.py mandarin <datasets_root>
ฝึก Hifigan Vocoder python vocoder_train.py mandarin <datasets_root> hifigan
จากนั้นคุณสามารถลองรัน: python web.py และเปิดในเบราว์เซอร์, ค่าเริ่มต้นเป็น http://localhost:8080
จากนั้นคุณสามารถลองใช้กล่องเครื่องมือ: python demo_toolbox.py -d <datasets_root>
จากนั้นคุณสามารถลองใช้คำสั่ง: python gen_voice.py <text_file.txt> your_wav_file.wav คุณอาจต้องติดตั้ง CN2AN โดย "PIP Install CN2AN" เพื่อผลลัพธ์หมายเลขดิจิตอลที่ดีขึ้น
ที่เก็บนี้ถูกแยกจากการโคลนนิ่งแบบเรียลไทม์ซึ่งสนับสนุนภาษาอังกฤษเท่านั้น
| url | การกำหนด | ชื่อ | แหล่งที่มา |
|---|---|---|---|
| 1803.09017 | globalstyletkok (synthesizer) | Tokens Style: การสร้างแบบจำลองสไตล์ที่ไม่ได้รับการควบคุมการควบคุมและถ่ายโอนในการสังเคราะห์คำพูดแบบ end-to-end | repo นี้ |
| 2010.05646 | Hifi-Gan (Vocoder) | เครือข่ายฝ่ายตรงข้ามแบบกำเนิดสำหรับการสังเคราะห์คำพูดที่มีประสิทธิภาพและมีความซื่อสัตย์สูง | repo นี้ |
| 2106.02297 | Fre-Gan (Vocoder) | Fre-Gan: การสังเคราะห์เสียงที่สอดคล้องกับความถี่ที่สอดคล้องกัน | repo นี้ |
| 1806.04558 | SV2TTS | ถ่ายโอนการเรียนรู้จากการตรวจสอบลำโพงไปยังการสังเคราะห์ข้อความหลายข้อความเป็นคำพูด | repo นี้ |
| 1802.08435 | Wavernn (Vocoder) | การสังเคราะห์เสียงประสาทที่มีประสิทธิภาพ | Fatchord/Wavernn |
| 1703.10135 | Tacotron (synthesizer) | Tacotron: ไปสู่การสังเคราะห์การพูดแบบ end-to-end | Fatchord/Wavernn |
| 1710.10467 | ge2e (encoder) | การสูญเสียแบบ end-to-end ทั่วไปสำหรับการตรวจสอบผู้พูด | repo นี้ |
| ชุดข้อมูล | ต้นฉบับ | แหล่งข้อมูลทางเลือก |
|---|---|---|
| Aidatatang_200ZH | openslr | Google Drive |
| วิเศษ | openslr | Google Drive (ชุด Dev) |
| aishell3 | openslr | Google Drive |
| data_aishell | openslr |
หลังจาก UNZIP AIDATATANG_200ZH คุณต้องคลายซิปไฟล์ทั้งหมดภายใต้
aidatatang_200zhcorpustrain
<datasets_root> คืออะไร? หากพา ธ ชุดข้อมูลคือ D:dataaidatatang_200zh ดังนั้น <datasets_root> คือ D:data
ฝึกอบรม synthesizer: ปรับ batch_size ใน synthesizer/hparams.py
//Before tts_schedule = [(2, 1e-3, 20_000, 12), # Progressive training schedule (2, 5e-4, 40_000, 12), # (r, lr, step, batch_size) (2, 2e-4, 80_000, 12), # (2, 1e-4, 160_000, 12), # r = reduction factor (# of mel frames (2, 3e-5, 320_000, 12), # synthesized for each decoder iteration) (2, 1e-5, 640_000, 12)], # lr = learning rate //After tts_schedule = [(2, 1e-3, 20_000, 8), # Progressive training schedule (2, 5e-4, 40_000, 8), # (r, lr, step, batch_size) (2, 2e-4, 80_000, 8), # (2, 1e-4, 160_000, 8), # r = reduction factor (# of mel frames (2, 3e-5, 320_000, 8), # synthesized for each decoder iteration) (2, 1e-5, 640_000, 8)], # lr = learning rate
รถไฟ Vocoder-preprocess ข้อมูล: ปรับ batch_size ใน synthesizer/hparams.py
//Before ### Data Preprocessing max_mel_frames = 900, rescale = True, rescaling_max = 0.9, synthesis_batch_size = 16, # For vocoder preprocessing and inference. //After ### Data Preprocessing max_mel_frames = 900, rescale = True, rescaling_max = 0.9, synthesis_batch_size = 8, # For vocoder preprocessing and inference.
รถไฟ Vocoder-train The Vocoder: ปรับ batch_size ใน vocoder/wavernn/hparams.py
//Before # Training voc_batch_size = 100 voc_lr = 1e-4 voc_gen_at_checkpoint = 5 voc_pad = 2 //After # Training voc_batch_size = 6 voc_lr = 1e-4 voc_gen_at_checkpoint = 5 voc_pad =2
RuntimeError: Error(s) in loading state_dict for Tacotron: size mismatch for encoder.embedding.weight: copying a param with shape torch.Size([70, 512]) from checkpoint, the shape in current model is torch.Size([75, 512]).โปรดดูที่ปัญหา #37
ปรับ batch_size ตามความเหมาะสมเพื่อปรับปรุง
the page file is too small to complete the operationโปรดดูวิดีโอนี้และเปลี่ยนหน่วยความจำเสมือนเป็น 100G (102400) ตัวอย่างเช่น: เมื่อวางไฟล์ไว้ในดิสก์ D หน่วยความจำเสมือนของดิสก์ D จะเปลี่ยนไป
FYI ความสนใจของฉันเกิดขึ้นหลังจากขั้นตอน 18K และการสูญเสียต่ำกว่า 0.4 หลังจากขั้นตอน 50K