MockingBird
1.0.0
Si bien ya no actualizo activamente este repositorio, puede encontrarme empujando continuamente a esta tecnología hacia el lado bueno y el código abierto. También estoy construyendo una versión optimizada y alojada en la nube: https://noiz.ai/ y está gratuita pero no está listo para uso comercial ahora.

Inglés | 中文 | 中文 Linux
Mandarina compatible con chino y probado con múltiples conjuntos de datos: Aidatatang_200zh, MagicData, Aishell3, Data_aishell, etc.
Pytorch trabajó para Pytorch, probado en la versión de 1.9.0 (último en agosto de 2021), con GPU Tesla T4 y GTX 2060
Windows + Linux se ejecuta tanto en Windows OS como en el sistema operativo Linux (incluso en M1 MacOS)
Efecto fácil e impresionante con solo un sintetizador recién entrenado, reutilizando el codificador/vocoder previamente
Servidor web listo para servir su resultado con llamadas remotas
Siga el repositorio original para probar si tiene todo el entorno listo. ** Se necesita Python 3.7 o superior ** para ejecutar la caja de herramientas.
Instale Pytorch.
Si recibe un
ERROR: Could not find a version that satisfies the requirement torch==1.9.0+cu102 (from versions: 0.1.2, 0.1.2.post1, 0.1.2.post2 )Este error probablemente se deba a un Versión baja de Python, intente usar 3.9 y se instalará correctamente
Instale ffmpeg.
Ejecute pip install -r requirements.txt para instalar los paquetes necesarios restantes.
El entorno recomendado aquí es
Repo Tag 0.0.1Pytorch1.9.0 with Torchvision0.10.0 and cudatoolkit10.2webrtcvad-wheelsrequirements.txtrequirements. txtse exportó hace unos meses, por lo que no funciona con versiones más nuevas.
Instale Webrtcvad pip install webrtcvad-wheels (si lo necesita)
o
Instalar dependencias con conda o mamba
conda env create -n env_name -f env.yml
mamba env create -n env_name -f env.yml
creará un entorno virtual cuando se instalen las dependencias necesarias. Cambie al nuevo entorno por conda activate env_name y disfrútalo.
Env.yml solo incluye las dependencias necesarias para ejecutar el proyecto, temporalmente sin alineación monotónica. Puede consultar el sitio web oficial para instalar la versión GPU de Pytorch.
Los siguientes pasos son una solución para usar directamente el
demo_toolbox.pyoriginal sin el cambio de códigos.Dado que el problema principal viene con los paquetes PYQT5 utilizados en
demo_toolbox.pyno compatible con chips M1, fueron uno para intentar los modelos de entrenamiento con el chip M1, ya sea que esa persona puede renunciar ademo_toolbox.py, o uno puede probar elweb.pyen el proyecto.
PyQt5 , con REF aquí.Crear y abrir una terminal de Rosetta, con Ref aquí.
Use System Python para crear un entorno virtual para el proyecto
/usr/bin/python3 -m venv /PathToMockingBird/venv source /PathToMockingBird/venv/bin/activate
Actualice PIP e instale PyQt5
pip install --upgrade pip pip install pyqt5
pyworld y ctc-segmentationAmbos paquetes parecen ser únicos para este proyecto y no se ven en el proyecto original de clonación de voz en tiempo real. Al instalar con
pip install, ambos paquetes carecen de ruedas, por lo que el programa intenta compilar directamente del código C y no pudo encontrarPython.h.
Instalar pyworld
brew install python Python.h puede venir con Python instalado por Brew
export CPLUS_INCLUDE_PATH=/opt/homebrew/Frameworks/Python.framework/Headers El filepath de Python.h instalado por la cerveza es exclusivo de M1 MacOS y enumerado anteriormente. Uno necesita agregar manualmente el camino a las variables de entorno.
pip install pyworld que debería hacer.
Instale ctc-segmentation
El mismo método no se aplica a
ctc-segmentation, y uno necesita compilarlo desde el código fuente en GitHub.
git clone https://github.com/lumaku/ctc-segmentation.git
cd ctc-segmentation
source /PathToMockingBird/venv/bin/activate Si el entorno virtual no se ha implementado, activarlo.
cythonize -3 ctc_segmentation/ctc_segmentation_dyn.pyx
/usr/bin/arch -x86_64 python setup.py build Build Build with X86 Architecture.
/usr/bin/arch -x86_64 python setup.py install --optimize=1 --skip-build install con arquitectura x86.
/usr/bin/arch -x86_64 pip install torch torchvision torchaudio Pip Instalación de PyTorch como ejemplo, articule que está instalado con la arquitectura x86
pip install ffmpeg install FFMPEG
pip install -r requirements.txt Instale otros requisitos.
Para ejecutar el proyecto en la arquitectura x86. árbitro.
vim /PathToMockingBird/venv/bin/pythonM1 Cree un archivo ejecutable pythonM1 para condicionar el intérprete de python at /PathToMockingBird/venv/bin .
Escribe en el siguiente contenido:
#!/usr/bin/env zsh
mydir=${0:a:h}
/usr/bin/arch -x86_64 $mydir/python "$@" chmod +x pythonM1 Establezca el archivo como ejecutable.
Si usa PyCharm IDE, configure el intérprete del proyecto en pythonM1 (pasos aquí), si se usa la línea de comandos Python, run /PathToMockingBird/venv/bin/pythonM1 demo_toolbox.py
Tenga en cuenta que estamos utilizando el codificador/vocoder previo a la aparición pero no el sintetizador, ya que el modelo original es incompatible con los símbolos chinos. Significa que la demo_cli no funciona en este momento, por lo que se requieren modelos de sintetizador adicionales.
Puede entrenar a sus modelos o usar los existentes:
Preprocesos con los Audios y los espectrogramas MEL: python encoder_preprocess.py <datasets_root> Permitir el parámetro --dataset {dataset} para admitir los conjuntos de datos que desea preprocess. Solo se utilizará el conjunto de trenes de estos conjuntos de datos. Posibles nombres: Librispeech_other, VoxCeleb1, VoxCeleb2. Use coma para ampliar múltiples conjuntos de datos.
Entrena el codificador: python encoder_train.py my_run <datasets_root>/SV2TTS/encoder
Para el entrenamiento, el codificador usa Visdom. Puede deshabilitarlo con
--no_visdom, pero es bueno tenerlo. Ejecute "Visdom" en un CLI/proceso separado para iniciar su servidor Visdom.
Descargar DataSet y Unzip: asegúrese de poder acceder a todos .wav en la carpeta
Preprocesos con los Audios y los espectrogramas MEL: python pre.py <datasets_root> Permitir el parámetro --dataset {dataset} para admitir Aidatatang_200zh, MagicData, Aishell3, data_aishell, etc.IFIT este parámetro no se pasa, la DataSet predeterminada será Aidatatang_200zh.
Train the Synthesizer: python train.py --type=synth mandarin <datasets_root>/SV2TTS/synthesizer
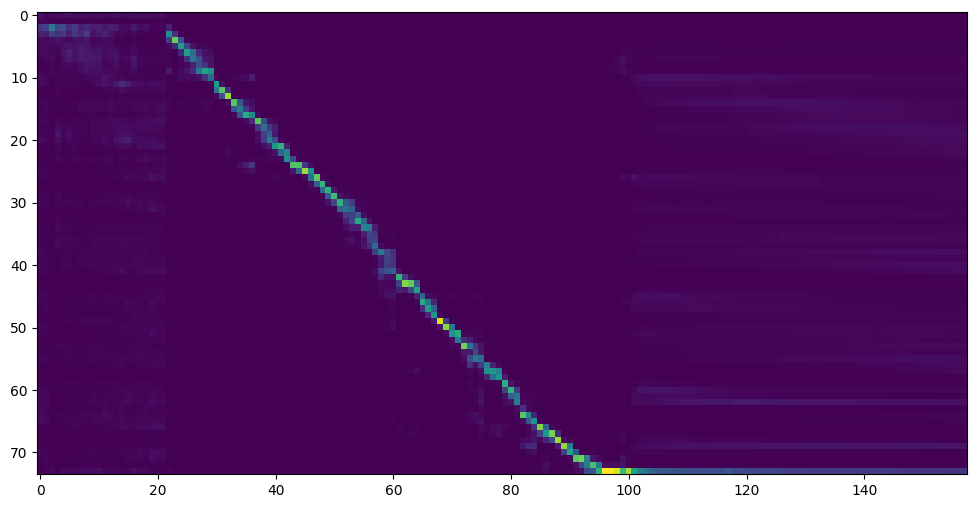
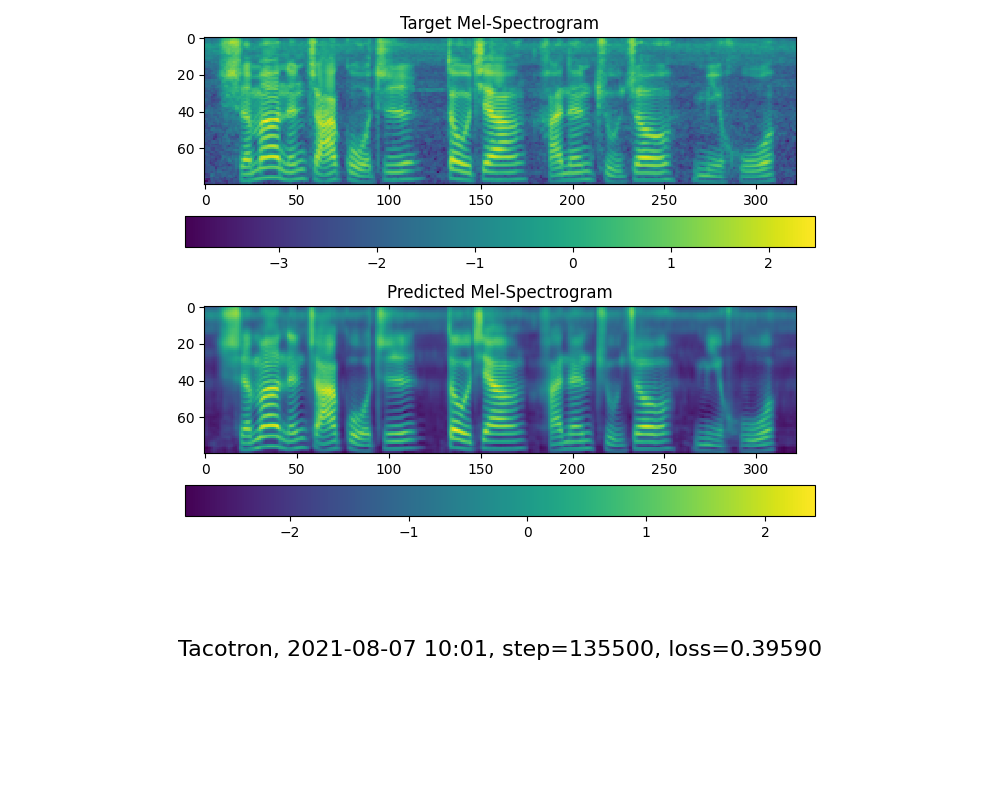
Vaya al siguiente paso cuando vea la línea de atención que muestra y la pérdida satisface sus necesidades en el sintetizador de carpetas de entrenamiento/ saved_models/ .
Gracias a la comunidad, se compartirán algunos modelos:
| autor | Enlace de descarga | Video de vista previa | Información |
|---|---|---|---|
| @autor | https://pan.baidu.com/s/1ionvrxmki-t1nhqxkyty3g baidu 4j5d | 75k pasos entrenados por múltiples conjuntos de datos | |
| @autor | https://pan.baidu.com/s/1fmh9ilgkjll2piirtyduvw Baidu Code : OM7F | 25k pasos entrenados por múltiples conjuntos de datos, solo funciona bajo la versión 0.0.1 | |
| @Fawenyo | https://yisiou-my.sharepoint.com/:u:/g/personal/lawrence_cheng_fawenyo_onmicrosoft_com/ewfwdhzee-ng9twdkckccc4bc7bk2j9ccbown0-_tk0nog?e=n0gggccc | salida de entrada | 200k pasos con acento local de Taiwán, solo funciona bajo la versión 0.0.1 |
| @miven | https://pan.baidu.com/s/1pi-hm3sn5wbechrryx-rcq Código: 2021 https://www.aliyundrive.com/s/AWPSBO8MCSP: Z2M0 | https://www.bilibili.com/video/bv1uh411b7ad/ | Solo funciona bajo la versión 0.0.1 |
Nota: Vocoder tiene poca diferencia en efecto, por lo que es posible que no necesite entrenar una nueva.
Preprocese los datos: python vocoder_preprocess.py <datasets_root> -m <synthesizer_model_path>
<datasets_root>Reemplace con su conjunto de datos Root,<synthesizer_model_path>Reemplace con el directorio de sus mejores modelos capacitados de Sythensizer, por ejemplo, Sythensizersaved_Modexxx
Entrena el Vocoder de Wavernn: python vocoder_train.py mandarin <datasets_root>
Entrena el Vocoder Hifigan python vocoder_train.py mandarin <datasets_root> hifigan
Luego puede intentar ejecutar: python web.py y abrirlo en el navegador, predeterminado como http://localhost:8080
Luego puede probar la caja de herramientas: python demo_toolbox.py -d <datasets_root>
Luego puede probar el comando: python gen_voice.py <text_file.txt> your_wav_file.wav Es posible que deba instalar cn2an por "pip install cn2an" para un mejor resultado de número digital.
Este repositorio está bifurcado de la clonación de voz en tiempo real que solo admite inglés.
| Url | Designación | Título | Fuente de implementación |
|---|---|---|---|
| 1803.09017 | GlobalStyletoken (Synthesizer) | Tokens de estilo: modelado de estilo no supervisado, control y transferencia en síntesis de habla de extremo a extremo | Este repositorio |
| 2010.05646 | Hifi-Gan (Vocoder) | Redes adversas generativas para la síntesis de habla eficiente y de alta fidelidad | Este repositorio |
| 2106.02297 | Fre-Gange (Vocoder) | Fre-Gange: síntesis de audio consistente con la frecuencia adversa | Este repositorio |
| 1806.04558 | Sv2tts | Transferir el aprendizaje de la verificación del hablante a la síntesis de texto a voz de múltiples | Este repositorio |
| 1802.08435 | Wavernn (Vocoder) | Síntesis de audio neuronal eficiente | Fatchord/Wavernn |
| 1703.10135 | Tacotrón (sintetizador) | Tacotron: Hacia la síntesis de discurso de extremo a extremo | Fatchord/Wavernn |
| 1710.10467 | GE2E (codificador) | Pérdida generalizada de extremo a extremo para la verificación del altavoz | Este repositorio |
| Conjunto de datos | Fuente original | Fuentes alternativas |
|---|---|---|
| Aidatatang_200zh | Openslr | Google Drive |
| Data mágica | Openslr | Google Drive (conjunto de desarrollo) |
| Aishell3 | Openslr | Google Drive |
| data_aishell | Openslr |
Después de unzip aidatatang_200zh, debe descomponer todos los archivos bajo
aidatatang_200zhcorpustrain
<datasets_root> ? Si la ruta del conjunto de datos es D:dataaidatatang_200zh , entonces <datasets_root> es D:data
Entrena el sintetizador: ajuste el lote_size en synthesizer/hparams.py
//Before tts_schedule = [(2, 1e-3, 20_000, 12), # Progressive training schedule (2, 5e-4, 40_000, 12), # (r, lr, step, batch_size) (2, 2e-4, 80_000, 12), # (2, 1e-4, 160_000, 12), # r = reduction factor (# of mel frames (2, 3e-5, 320_000, 12), # synthesized for each decoder iteration) (2, 1e-5, 640_000, 12)], # lr = learning rate //After tts_schedule = [(2, 1e-3, 20_000, 8), # Progressive training schedule (2, 5e-4, 40_000, 8), # (r, lr, step, batch_size) (2, 2e-4, 80_000, 8), # (2, 1e-4, 160_000, 8), # r = reduction factor (# of mel frames (2, 3e-5, 320_000, 8), # synthesized for each decoder iteration) (2, 1e-5, 640_000, 8)], # lr = learning rate
Vocoder de trenes- Presupresión de los datos: Ajuste el lote_size en synthesizer/hparams.py
//Before ### Data Preprocessing max_mel_frames = 900, rescale = True, rescaling_max = 0.9, synthesis_batch_size = 16, # For vocoder preprocessing and inference. //After ### Data Preprocessing max_mel_frames = 900, rescale = True, rescaling_max = 0.9, synthesis_batch_size = 8, # For vocoder preprocessing and inference.
Train Vo Vocoder Train The Vocoder: Ajuste el lote_size en vocoder/wavernn/hparams.py
//Before # Training voc_batch_size = 100 voc_lr = 1e-4 voc_gen_at_checkpoint = 5 voc_pad = 2 //After # Training voc_batch_size = 6 voc_lr = 1e-4 voc_gen_at_checkpoint = 5 voc_pad =2
RuntimeError: Error(s) in loading state_dict for Tacotron: size mismatch for encoder.embedding.weight: copying a param with shape torch.Size([70, 512]) from checkpoint, the shape in current model is torch.Size([75, 512]).Consulte el problema #37
Ajuste el lote_size según corresponda para mejorar
the page file is too small to complete the operationConsulte este video y cambie la memoria virtual a 100G (102400), por ejemplo: cuando el archivo se coloca en el disco D, se cambia la memoria virtual del disco D.
FYI, mi atención llegó después de que 18k pasos y la pérdida se redujo a 0.4 después de 50k pasos.