MockingBird
1.0.0
В то время как я больше не активно обновляю этот репо, вы можете найти меня постоянно продвигать эту технологию вперед на хорошую сторону и открытый исход. Я также строю оптимизированную и облачную версию: https://noiz.ai/, и она сейчас бесплатна, но не готова к коммерческому использованию.

Английский | 中文 | 中文 Linux
Китайский поддерживает мандарин и протестирован с несколькими наборами данных: Aidatatang_200ZH, MagicData, Aishell3, Data_aishell и и т. Д.
Pytorch работал на Pytorch, протестированный в версии 1.9.0 (последний в августе 2021 года), с GPU Tesla T4 и GTX 2060
Windows + Linux запускается как в ОС Windows, так и в ОС Linux (даже в M1OS M1)
Easy & Awesome Effect с только недавно обученным синтезатором, повторно используя предварительно проведенный кодер/Vocoder
WebServer готова обслуживать ваш результат с помощью удаленных звонков
Следуйте оригинальному репо, чтобы проверить, если вы готовы всей среды. ** Python 3.7 или выше ** необходимо для запуска инструментов.
Установите Pytorch.
Если вы получите
ERROR: Could not find a version that satisfies the requirement torch==1.9.0+cu102 (from versions: 0.1.2, 0.1.2.post1, 0.1.2.post2 )Эта ошибка, вероятно, связана Низкая версия Python, попробуйте использовать 3.9 и успешно установить
Установите ffmpeg.
Запустите pip install -r requirements.txt для установки оставшихся необходимых пакетов.
Рекомендуемая среда здесь
webrtcvad-wheelsэтоRepo Tag 0.0.1Pytorch1.9.0 with Torchvision0.10.0 and cudatoolkit10.2requirements.txtrequirements. txtбыл экспортирован несколько месяцев назад, так что он не работает с новыми версиями
Установите webrtcvad pip install webrtcvad-wheels (если вам нужно)
или
Установите зависимости с conda или mamba
conda env create -n env_name -f env.yml
mamba env create -n env_name -f env.yml
Создаст виртуальную среду, где установлены необходимые зависимости. Переключитесь на новую среду от conda activate env_name и наслаждайтесь этим.
Env.yml включает только необходимые зависимости для запуска проекта , временно без монотонического соглашения. Вы можете проверить официальный веб -сайт, чтобы установить версию GPU Pytorch.
Следующие шаги представляют собой обходной путь для непосредственного использования исходного
demo_toolbox.pyбез изменения кодов.Поскольку основная проблема возникает с пакетами pyqt5, используемыми в
demo_toolbox.py, не совместимых с чипами M1, были из тех, кто пытался на тренировках с чипом M1, либо этот человек может отказаться отdemo_toolbox.py, либо можно попробоватьweb.pyв Проект.
PyQt5 , с ссылкой здесь.Создайте и откройте терминал Rosetta, с REF здесь.
Используйте System Python для создания виртуальной среды для проекта
/usr/bin/python3 -m venv /PathToMockingBird/venv source /PathToMockingBird/venv/bin/activate
Обновите PIP и установите PyQt5
pip install --upgrade pip pip install pyqt5
pyworld и ctc-segmentationОбе пакеты кажутся уникальными для этого проекта и не рассматриваются в оригинальном проекте голоса в реальном времени. При установке с
pip installу обоих пакетов не хватает колес, поэтому программа пытается напрямую компилировать из C и не может найтиPython.h.
Установите pyworld
brew install python Python.h может поставляться с Python, установленным Brew
export CPLUS_INCLUDE_PATH=/opt/homebrew/Frameworks/Python.framework/Headers Python.h Нужно вручную добавить путь к переменным среды.
pip install pyworld , который должен сделать.
Установите ctc-segmentation
Тот же метод не относится к
ctc-segmentation, и необходимо скомпилировать его из исходного кода на GitHub.
git clone https://github.com/lumaku/ctc-segmentation.git
cd ctc-segmentation
source /PathToMockingBird/venv/bin/activate Если виртуальная среда не была развернута, активируйте ее.
cythonize -3 ctc_segmentation/ctc_segmentation_dyn.pyx
/usr/bin/arch -x86_64 python setup.py build сборки с x86 архитектура.
/usr/bin/arch -x86_64 python setup.py install --optimize=1 --skip-build SKIP с архитектурой x86.
/usr/bin/arch -x86_64 pip install torch torchvision torchaudio pip, установка PyTorch в качестве примера, формулируйте, что он установлен с x86 Architecture
pip install ffmpeg Установка ffmpeg
pip install -r requirements.txt .
Запустить проект на x86 Architecture. рефери
vim /PathToMockingBird/venv/bin/pythonM1 Создание исполняемого файла pythonM1 для обучения интерпретатора Python AT /PathToMockingBird/venv/bin .
Напишите в следующем контенте:
#!/usr/bin/env zsh
mydir=${0:a:h}
/usr/bin/arch -x86_64 $mydir/python "$@" chmod +x pythonM1 Установите файл в качестве исполняемого.
При использовании Pycharm IDE настройте интерпретатор проекта на pythonM1 (шаги здесь), если использование командной строки Python, run /PathToMockingBird/venv/bin/pythonM1 demo_toolbox.py
Обратите внимание, что мы используем предварительно проведенный энкодер/вокадер, но не синтезатор, поскольку оригинальная модель несовместима с китайскими символами. Это означает, что DEMO_CLI не работает в данный момент, поэтому требуются дополнительные модели синтезатора.
Вы можете либо обучить свои модели, либо использовать существующие:
Предварительная обработка с аудионами и спектрограммами MEL: python encoder_preprocess.py <datasets_root> Разрешение параметра --dataset {dataset} для поддержки наборов данных, которые вы хотите предварительно, предпринимайте. Будет использоваться только набор поездов этих наборов данных. Возможные названия: librispeech_other, voxceleb1, voxceleb2. Используйте запятую, чтобы соблюдать несколько наборов данных.
Обучить энкодер: python encoder_train.py my_run <datasets_root>/SV2TTS/encoder
Для обучения, энкодер использует Visdom. Вы можете отключить его с помощью
--no_visdom, но это приятно иметь. Запустите «Вишмон» в отдельном CLI/процессе, чтобы запустить ваш сервер Visdom.
Загрузить набор данных и Unzip: убедитесь, что вы можете получить доступ к всем .Wav в папке
Предварительная обработка с аудионами и спектрограммами MEL: python pre.py <datasets_root> Разрешение параметра --dataset {dataset} для поддержки Aidatatang_200ZH, MagicData, Aishell3, Data_aishell и т. Д.
Обучить синтезатор: python train.py --type=synth mandarin <datasets_root>/SV2TTS/synthesizer
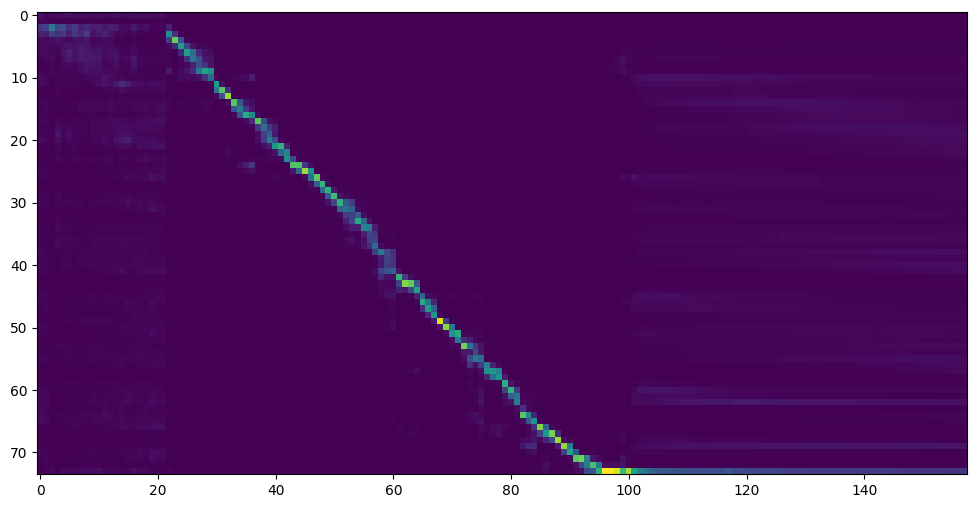
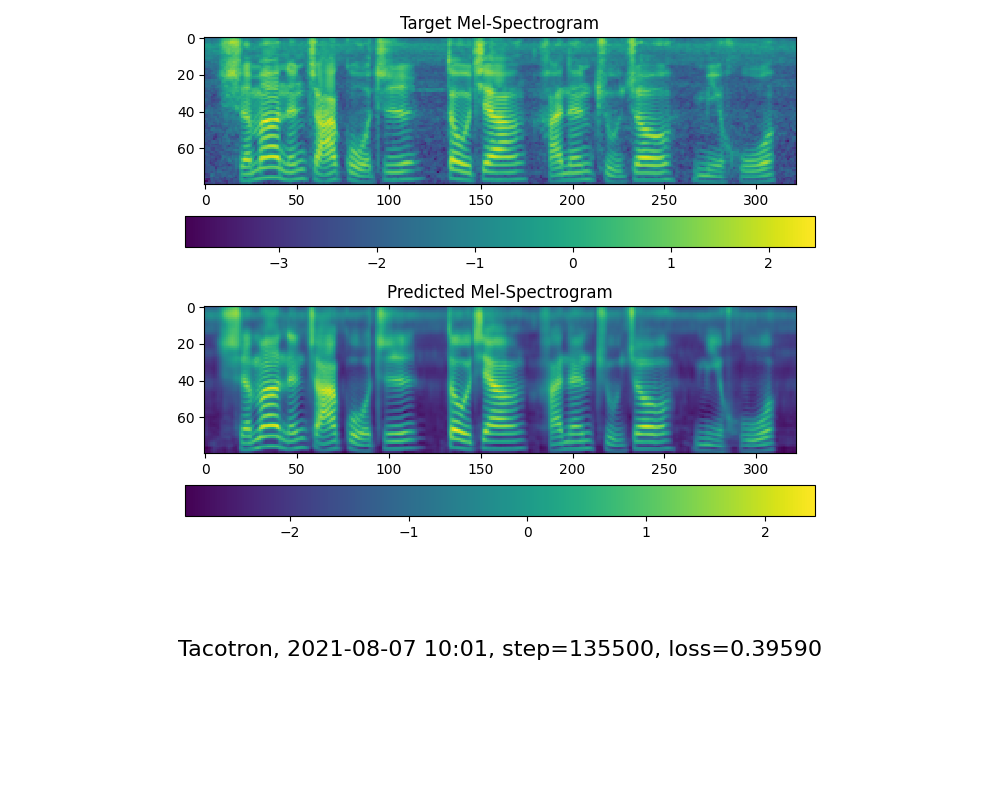
Перейдите к следующему шагу, когда вы видите линию внимания, показывают, и потеряйте ваши потребности в обучающей папке Synthesizer/ Saveed_models/ .
Благодаря сообществу, некоторые модели будут переданы:
| автор | Скачать ссылку | Предварительный просмотр видео | Информация |
|---|---|---|---|
| @author | https://pan.baidu.com/s/1ionvrxmki-t1nhqxkyty3g baidu 4j5d | 75K Шаги, обученные несколькими наборами данных | |
| @author | https://pan.baidu.com/s/1fmh9ilgkjll2piirtyduvw baidu code : Om7f | 25K Шаги, обученные несколькими наборами данных, работает только по версии 0.0.1 | |
| @Fawenyo | https://yisiou-my.sharepoint.com/:/g/personal/lawrence_cheng_fawenyo_onmicrosoft_com/ewfwdhzee-nng9twdkccccc4bc7bk2j9cbown0-_tk0nog? | Входной вывод | 200 тысяч шагов с местным акцентом на Тайване, работает только в соответствии с версией 0.0.1 |
| @miven | https://pan.baidu.com/s/1pi-hm3sn5wbechrryx-rcq код: 2021 https://www.aliyundrive.com/s/awpsbo8mcsp Код: z2m0 | https://www.bilibili.com/video/bv1uh411b7ad/ | работает только по версии 0.0.1 |
Примечание: Vocoder имеет небольшую разницу в действии, поэтому вам может не понадобиться тренировать новую.
Предварительная обработка данных: python vocoder_preprocess.py <datasets_root> -m <synthesizer_model_path>
<datasets_root>заменить на набор данных root ,<synthesizer_model_path>заменить на каталог ваших лучших обученных моделей Sythensizer, например, sythensizesersaved_modexxx
Train the Wavernn Vocoder: python vocoder_train.py mandarin <datasets_root>
Обучить hifigan vocoder python vocoder_train.py mandarin <datasets_root> hifigan
Затем вы можете попробовать запустить: python web.py и открыть его в браузере, по умолчанию как http://localhost:8080
Затем вы можете попробовать Toolbox: python demo_toolbox.py -d <datasets_root>
Затем вы можете попробовать команду: python gen_voice.py <text_file.txt> your_wav_file.wav вам может потребоваться установить CN2AN по «PIP установить CN2AN» для лучшего результата цифрового номера.
Этот репозиторий вытекает из голосования в реальном времени, который поддерживает только английский.
| URL | Обозначение | Заголовок | Источник реализации |
|---|---|---|---|
| 1803.09017 | GlobalStyleToken (синтезатор) | Стиль токены: неконтролируемое моделирование стиля, управление и передача в сквозном синтезе речи | Это репо |
| 2010.05646 | Hifi-Gan (Vocoder) | Генеративные состязательные сети для эффективного и высокого синтеза речи с высокой точностью | Это репо |
| 2106.02297 | Fre-Gan (Vocoder) | FRE-GAN: состязательный частотный синтез аудиозащиты | Это репо |
| 1806.04558 | SV2TTS | Передача обучения от проверки динамиков в синтез текста в речь. | Это репо |
| 1802.08435 | Wavernn (Vocoder) | Эффективный синтез нейронного звука | Fatchord/Wavernn |
| 1703.10135 | Такотрон (синтезатор) | Tacotron: к синтезу речевого речи. | Fatchord/Wavernn |
| 1710.10467 | GE2E (Encoder) | Обобщенная сквозная потеря для проверки спикеров | Это репо |
| Набор данных | Оригинальный источник | Альтернативные источники |
|---|---|---|
| Aidatatang_200ZH | OpenSlr | Google Drive |
| MagicData | OpenSlr | Google Drive (Dev Set) |
| Aishell3 | OpenSlr | Google Drive |
| data_aishell | OpenSlr |
После разказы Aidatatang_200ZH вам необходимо разкапливать все файлы под
aidatatang_200zhcorpustrain
<datasets_root> ? Если путь набора данных равен D:dataaidatatang_200zh , то <datasets_root> IS D:data
Обучить синтезатор: отрегулировать batch_size в synthesizer/hparams.py
//Before tts_schedule = [(2, 1e-3, 20_000, 12), # Progressive training schedule (2, 5e-4, 40_000, 12), # (r, lr, step, batch_size) (2, 2e-4, 80_000, 12), # (2, 1e-4, 160_000, 12), # r = reduction factor (# of mel frames (2, 3e-5, 320_000, 12), # synthesized for each decoder iteration) (2, 1e-5, 640_000, 12)], # lr = learning rate //After tts_schedule = [(2, 1e-3, 20_000, 8), # Progressive training schedule (2, 5e-4, 40_000, 8), # (r, lr, step, batch_size) (2, 2e-4, 80_000, 8), # (2, 1e-4, 160_000, 8), # r = reduction factor (# of mel frames (2, 3e-5, 320_000, 8), # synthesized for each decoder iteration) (2, 1e-5, 640_000, 8)], # lr = learning rate
Поезда-вокадер-предварительный synthesizer/hparams.py
//Before ### Data Preprocessing max_mel_frames = 900, rescale = True, rescaling_max = 0.9, synthesis_batch_size = 16, # For vocoder preprocessing and inference. //After ### Data Preprocessing max_mel_frames = 900, rescale = True, rescaling_max = 0.9, synthesis_batch_size = 8, # For vocoder preprocessing and inference.
Поездка на vocoder/wavernn/hparams.py вокаду
//Before # Training voc_batch_size = 100 voc_lr = 1e-4 voc_gen_at_checkpoint = 5 voc_pad = 2 //After # Training voc_batch_size = 6 voc_lr = 1e-4 voc_gen_at_checkpoint = 5 voc_pad =2
RuntimeError: Error(s) in loading state_dict for Tacotron: size mismatch for encoder.embedding.weight: copying a param with shape torch.Size([70, 512]) from checkpoint, the shape in current model is torch.Size([75, 512]).Пожалуйста, обратитесь к выпуску № 37
Отрегулируйте batch_size по мере необходимости, чтобы улучшить
the page file is too small to complete the operationПожалуйста, обратитесь к этому видео и измените виртуальную память на 100G (102400), например: когда файл помещен в диск D, виртуальная память диска D изменяется.
К вашему сведению, мое внимание пришло после 18 тыс. Шаг, а потеря стала ниже 0,4 после 50 тыс. Шагов.