MockingBird
1.0.0
私はもはやこのリポジトリを積極的に更新していませんが、この技術を継続的に前進させて良い側面とオープンソースに進めていることがわかります。また、最適化されたクラウドホストバージョンのhttps://noiz.ai/を構築していますが、無料ですが、現在は商品使用の準備ができていません。

英語| 中文| 中文linux
中国語はマンダリンをサポートし、複数のデータセットでテストしました:aidatatang_200ZH、MagicData、Aishell3、Data_aishellなど。
PytorchはPytorchで働いており、1.9.0のバージョン(2021年8月に最新)で、GPU Tesla T4とGTX 2060でテストしました
Windows + LinuxはWindows OSとLinux OSの両方で実行されます(M1 MacOSでも)
前提条件のエンコーダー/ボコーダーを再利用することにより、新しく訓練されたシンセサイザーのみで簡単で素晴らしい効果
Webサーバーは、リモート通話で結果を提供する準備ができています
元のリポジトリに従って、すべての環境の準備ができているかどうかをテストしてください。 **ツールボックスを実行するには、Python 3.7以降**が必要です。
Pytorchをインストールします。
ERROR: Could not find a version that satisfies the requirement torch==1.9.0+cu102 (from versions: 0.1.2, 0.1.2.post1, 0.1.2.post2 )このエラーはおそらく次のとおりです。 Pythonの低いバージョン、3.9を使用してみてください。
ffmpegをインストールします。
pip install -r requirements.txtを実行して、残りの必要なパッケージをインストールします。
ここで推奨される環境は、
Repo Tag 0.0.1Pytorch1.9.0 with Torchvision0.10.0 and cudatoolkit10.2requirements.txtwebrtcvad-wheelsrequirements. txtは数か月前にエクスポートされたため、新しいバージョンでは動作しません
webrtcvad pip install webrtcvad-wheels (必要な場合)
または
condaまたはmambaに依存関係をインストールします
conda env create -n env_name -f env.yml
mamba env create -n env_name -f env.yml
必要な依存関係がインストールされている場合、仮想環境を作成します。 conda activate env_nameて楽しんでください。
env.ymlには、一時的に単調なアライインなしで一時的にプロジェクトを実行するために必要な依存関係のみが含まれます。公式ウェブサイトをチェックして、PytorchのGPUバージョンをインストールできます。
次の手順は、コードを変更せずに元の
demo_toolbox.pyを直接使用する回避策です。主要な問題は
web.pydemo_toolbox.pyで使用されているPyqt5パッケージがM1チップと互換性がないことに伴うため、M1チップでモデルをトレーニングすることを試みることができましたdemo_toolbox.pyプロジェクト。
PyQt5をインストールし、こちらを参照してください。Rosettaターミナルを作成して開きます。ここで参照してください。
System Pythonを使用して、プロジェクトの仮想環境を作成します
/usr/bin/python3 -m venv /PathToMockingBird/venv source /PathToMockingBird/venv/bin/activate
PIPをアップグレードしてPyQt5をインストールします
pip install --upgrade pip pip install pyqt5
pyworldとctc-segmentationをインストールしますどちらのパッケージもこのプロジェクトに固有のようであり、元のリアルタイム音声クローニングプロジェクトには見られません。
pip installでインストールすると、両方のパッケージにはホイールがなく、プログラムはCコードから直接コンパイルしようとし、Python.h見つけることができませんでした。
pyworldをインストールします
brew install python Python.hは、brewによってインストールされたpythonを添えて付属しています
export CPLUS_INCLUDE_PATH=/opt/homebrew/Frameworks/Python.framework/Headers brew-inestaled Python.hのFilepathはM1 macosに固有のものであり、上記のリストです。環境変数にパスを手動で追加する必要があります。
pip install pyworldする必要があります。
ctc-segmentationをインストールします
同じ方法は
ctc-segmentationには適用されず、GitHubのソースコードからコンパイルする必要があります。
git clone https://github.com/lumaku/ctc-segmentation.git
cd ctc-segmentation
source /PathToMockingBird/venv/bin/activate仮想環境が展開されていない場合は、それをアクティブにします。
cythonize -3 ctc_segmentation/ctc_segmentation_dyn.pyx
/usr/bin/arch -x86_64 python setup.py buildビルド。
/usr/bin/arch -x86_64 python setup.py install --optimize=1 --skip-buildインストール。
/usr/bin/arch -x86_64 pip install torch torchvision torchaudioピップPyTorchインストール例として、x86アーキテクチャでインストールされていることを明確に示します
pip install ffmpegインストールffmpeg
pip install -r requirements.txtその他の要件をインストールします。
x86アーキテクチャでプロジェクトを実行します。 ref。
vim /PathToMockingBird/venv/bin/pythonM1実行可能ファイルpythonM1を作成して/PathToMockingBird/venv/binでpythonインタープリターを条件付けます。
次のコンテンツを書いてください。
#!/usr/bin/env zsh
mydir=${0:a:h}
/usr/bin/arch -x86_64 $mydir/python "$@" chmod +x pythonM1ファイルを実行可能ファイルとして設定します。
Pycharm IDEを使用する場合、プロジェクトインタープリターをpythonM1に構成します(こちらの手順)、コマンドラインPythonを使用する場合、Run /PathToMockingBird/venv/bin/pythonM1 demo_toolbox.py
元のモデルは中国のシンボルと互換性がないため、シンセサイザーではなく、前処理されたエンコーダ/ボコーダーを使用していることに注意してください。これは、DEMO_CLIが現時点では機能していないことを意味するため、追加のシンセサイザーモデルが必要です。
モデルをトレーニングするか、既存のモデルを使用できます。
オーディオとMELスペクトログラムを使用したプリプロセス: python encoder_preprocess.py <datasets_root> parameter --dataset {dataset}プレップロケスをサポートすることをサポートします。これらのデータセットの列車セットのみが使用されます。可能な名前:Librispeech_other、voxceleb1、voxceleb2。コンマを使用して、複数のデータセットを激化させます。
エンコーダーのトレーニング: python encoder_train.py my_run <datasets_root>/SV2TTS/encoder
トレーニングのために、エンコーダーはVisomを使用します。
--no_visdomで無効にすることができますが、持っているのはいいことです。別のCLI/プロセスで「Visdom」を実行して、Visom Serverを起動します。
データセットとUNZIPをダウンロード:フォルダのすべての.WAVにアクセスできることを確認してください
オーディオとMELスペクトログラムを備えたプリプロセス: python pre.py <datasets_root> aving parameter --dataset {dataset}がadatatang_200zh、magicdata、aishell3、data_aishellなどをサポートします。
シンセサイザーのトレーニング: python train.py --type=synth mandarin <datasets_root>/SV2TTS/synthesizer
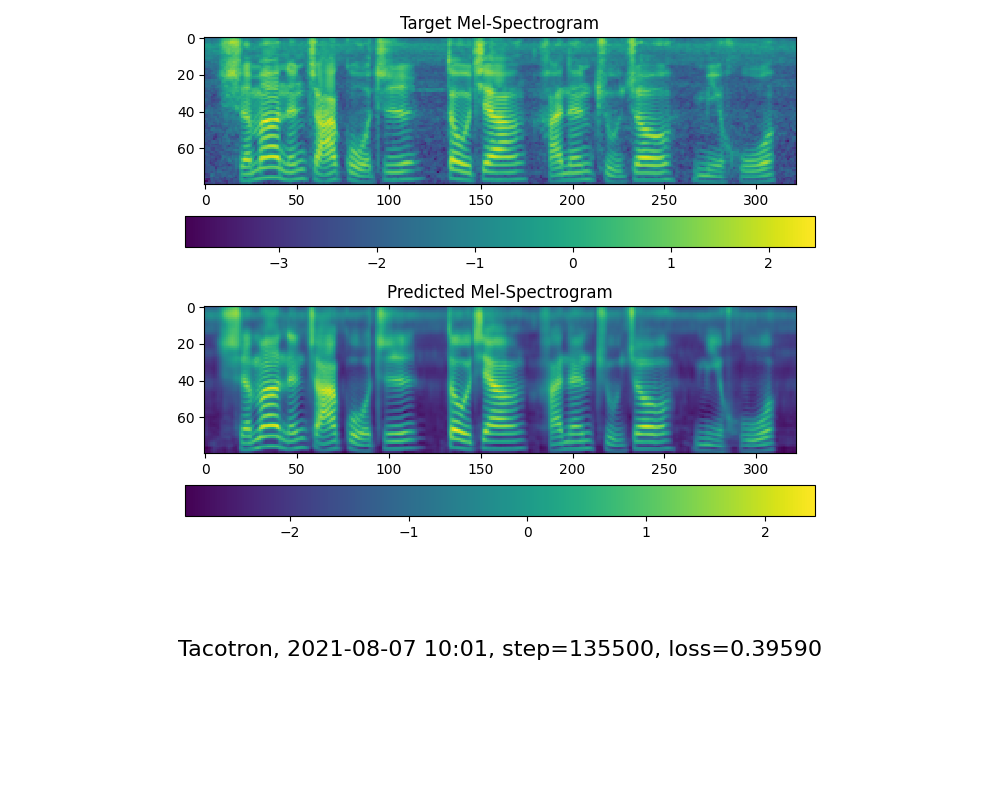
トレーニングフォルダーシンセサイザー/ saved_models/のトレーニングであなたのニーズを満たしている注意ラインショーと損失を確認したら、次のステップに進みます。
コミュニティのおかげで、一部のモデルが共有されます:
| 著者 | ダウンロードリンク | プレビュービデオ | 情報 |
|---|---|---|---|
| @著者 | https://pan.baidu.com/s/1ionvrxmki-t1nhqxkyty3g baidu 4j5d | 複数のデータセットで訓練された75Kステップ | |
| @著者 | https://pan.baidu.com/s/1fmh9ilgkjll2piirtyduvw baiduコード:om7f | 複数のデータセットで訓練された25kステップ、バージョン0.0.1でのみ機能します | |
| @Fawenyo | https://yisiou-my.sharepoint.com/:u:u/personal/lawrence_cheng_fawenyo_onmicrosoft_com/ewfwdhzee-nng9twdkckccccccccccccc4bc7bk2j9cbown0-_tk0nog?e = n0gggcc | 入力出力 | 台湾のローカルアクセントを備えた200kステップ、バージョン0.0.1でのみ機能します |
| @miven | https://pan.baidu.com/s/1pi-hm3sn5wbechrryx-rcqコード:2021 https://www.aliyundrive.com/s/awpsbo8mcspコード:Z2M0 | https://www.bilibili.com/video/bv1uh411b7ad/ | バージョン0.0.1でのみ機能します |
注:Vocoderには効果がほとんどないため、新しいものをトレーニングする必要がない場合があります。
データを事前に処理する: python vocoder_preprocess.py <datasets_root> -m <synthesizer_model_path>
<datasets_root>データセットルートに置き換えます<synthesizer_model_path>
wavernn vocoderをトレーニング: python vocoder_train.py mandarin <datasets_root>
Hifigan vocoder python vocoder_train.py mandarin <datasets_root> hifigan訓練します
その後、実行してください: python web.pyを実行して、 http://localhost:8080としてデフォルトでブラウザーで開くことができます
その後、ツールボックスを試すことができます: python demo_toolbox.py -d <datasets_root>
次に、コマンドを試すことができます: python gen_voice.py <text_file.txt> your_wav_file.wav 「PIPインストールCN2AN」でCN2ANをインストールする必要がある場合があります。
このリポジトリは、英語のみをサポートするリアルタイムボイスクローニングからフォークされています。
| URL | 指定 | タイトル | 実装ソース |
|---|---|---|---|
| 1803.09017 | GlobalStyletoken(シンセサイザー) | スタイルトークン:エンドツーエンドの音声合成における監視されていないスタイルのモデリング、制御、転送 | このレポ |
| 2010.05646 | hifi-gan(ボコーダー) | 効率的かつ高忠実度の音声合成のための生成敵対的ネットワーク | このレポ |
| 2106.02297 | Fre-Gan(ボコーダー) | Fre-Gan:敵対的な周波数一貫性のあるオーディオ合成 | このレポ |
| 1806.04558 | sv2tts | スピーカーの検証からマルチスピーカーのテキストからスピーチの合成に学習を転送します | このレポ |
| 1802.08435 | wavernn(ボコーダー) | 効率的なニューラルオーディオ合成 | Fatchord/Wavernn |
| 1703.10135 | タコトロン(シンセサイザー) | タコトロン:エンドツーエンドの音声合成に向けて | Fatchord/Wavernn |
| 1710.10467 | GE2E(エンコーダ) | スピーカー検証のための一般的なエンドツーエンド損失 | このレポ |
| データセット | 元のソース | 代替ソース |
|---|---|---|
| aidatatang_200zh | openslr | Googleドライブ |
| MagicData | openslr | Googleドライブ(開発セット) |
| aishell3 | openslr | Googleドライブ |
| data_aishell | openslr |
aidatatang_200zhを解凍した後、
aidatatang_200zhcorpustrainの下のすべてのファイルを解凍する必要があります
<datasets_root>とは何ですか?データセットパスがD:dataaidatatang_200zhの場合、 <datasets_root>はD:data
シンセサイザーのトレーニング: synthesizer/hparams.pyのbatch_sizeを調整します
//Before tts_schedule = [(2, 1e-3, 20_000, 12), # Progressive training schedule (2, 5e-4, 40_000, 12), # (r, lr, step, batch_size) (2, 2e-4, 80_000, 12), # (2, 1e-4, 160_000, 12), # r = reduction factor (# of mel frames (2, 3e-5, 320_000, 12), # synthesized for each decoder iteration) (2, 1e-5, 640_000, 12)], # lr = learning rate //After tts_schedule = [(2, 1e-3, 20_000, 8), # Progressive training schedule (2, 5e-4, 40_000, 8), # (r, lr, step, batch_size) (2, 2e-4, 80_000, 8), # (2, 1e-4, 160_000, 8), # r = reduction factor (# of mel frames (2, 3e-5, 320_000, 8), # synthesized for each decoder iteration) (2, 1e-5, 640_000, 8)], # lr = learning rate
トレーニングボコーダープロセスデータ: synthesizer/hparams.pyのbatch_sizeを調整します
//Before ### Data Preprocessing max_mel_frames = 900, rescale = True, rescaling_max = 0.9, synthesis_batch_size = 16, # For vocoder preprocessing and inference. //After ### Data Preprocessing max_mel_frames = 900, rescale = True, rescaling_max = 0.9, synthesis_batch_size = 8, # For vocoder preprocessing and inference.
トレーニングボコーダートレインボコーダー: vocoder/wavernn/hparams.pyのbatch_sizeを調整します
//Before # Training voc_batch_size = 100 voc_lr = 1e-4 voc_gen_at_checkpoint = 5 voc_pad = 2 //After # Training voc_batch_size = 6 voc_lr = 1e-4 voc_gen_at_checkpoint = 5 voc_pad =2
RuntimeError: Error(s) in loading state_dict for Tacotron: size mismatch for encoder.embedding.weight: copying a param with shape torch.Size([70, 512]) from checkpoint, the shape in current model is torch.Size([75, 512]).#37を参照してください
改善するために、必要に応じてbatch_sizeを調整します
the page file is too small to complete the operation場合はどうなりますかこのビデオを参照して、仮想メモリを100g(102400)に変更してください。たとえば、ファイルをDディスクに配置すると、Dディスクの仮想メモリが変更されます。
参考までに、私の注意は18Kステップ後に来て、5万段のステップ後に損失が0.4未満になりました。