MockingBird
1.0.0
Embora eu não atualize mais ativamente esse repositório, você pode me encontrar continuamente empurrando essa tecnologia para a frente para um bom lado e o código aberto. Também estou construindo uma versão otimizada e hospedada em nuvem: https://noiz.ai/ e está gratuito, mas não está pronto para uso comércio agora.

Inglês | 中文 | 中文 Linux
Chinês apoiou mandarim e testado com vários conjuntos de dados: AidatAng_200zh, MagicData, Aishell3, Data_aishell e etc.
Pytorch trabalhou para Pytorch, testado na versão do 1.9.0 (mais recente em agosto de 2021), com GPU Tesla T4 e GTX 2060
Windows + Linux é executado no sistema operacional Windows e Linux (mesmo no M1 MacOS)
Efeito fácil e incrível com apenas sintetizador recém-treinado, reutilizando o codificador/vocoder pré-treinado
SERVER WEB PRONTO PARA SERVIR SEU RESULTADO COM CHAMADA REMOTA
Siga o repositório original para testar se você preparou todo o ambiente. ** Python 3.7 ou superior ** É necessário para executar a caixa de ferramentas.
Instale o pytorch.
Se você receber um
ERROR: Could not find a version that satisfies the requirement torch==1.9.0+cu102 (from versions: 0.1.2, 0.1.2.post1, 0.1.2.post2 )Esse erro é provavelmente devido a um versão baixa do Python, tente usar 3.9 e instalará com sucesso
Instale o FFMPEG.
Execute pip install -r requirements.txt para instalar os pacotes necessários restantes.
O ambiente recomendado aqui é
Repo Tag 0.0.1Pytorch1.9.0 with Torchvision0.10.0 and cudatoolkit10.2requirements.txtwebrtcvad-wheelsporquerequirements. txtfoi exportado há alguns meses, por isso não funciona com versões mais recentes
Instale o webrtcvad pip install webrtcvad-wheels (se precisar)
ou
Instale dependências com conda ou mamba
conda env create -n env_name -f env.yml
mamba env create -n env_name -f env.yml
criará um ambiente virtual quando as dependências necessárias são instaladas. Mude para o novo ambiente por conda activate env_name e aproveite.
O Env.yML inclui apenas as dependências necessárias para executar o projeto, temporariamente sem alinhamento monotônico. Você pode verificar o site oficial para instalar a versão GPU do Pytorch.
As etapas a seguir são uma solução alternativa para usar diretamente o
demo_toolbox.pyoriginal sem a alteração dos códigos.Como a questão principal vem com os pacotes PYQT5 usados em
demo_toolbox.pynão compatíveis com chips M1, foram os que tentavam em treinamento de modelos com o chip M1, ou essa pessoa pode abandonardemo_toolbox.pyou se pode experimentar oweb.pyem o projeto.
PyQt5 , com referência aqui.Crie e abra um terminal Rosetta, com a referência aqui.
Use o System Python para criar um ambiente virtual para o projeto
/usr/bin/python3 -m venv /PathToMockingBird/venv source /PathToMockingBird/venv/bin/activate
Atualize o PIP e instale PyQt5
pip install --upgrade pip pip install pyqt5
pyworld e ctc-segmentationAmbos os pacotes parecem exclusivos deste projeto e não são vistos no projeto de clonagem de voz em tempo real original. Ao instalar com
pip install, ambos os pacotes não possuem rodas para que o programa tenta compilar diretamente do código C e não conseguiu encontrarPython.h.
Instale pyworld
brew install python Python.h pode vir com o python instalado pela Brew
Exportar cplus_include_path =/opt/homebrew Python.h export CPLUS_INCLUDE_PATH=/opt/homebrew/Frameworks/Python.framework/Headers É preciso adicionar manualmente o caminho às variáveis do ambiente.
pip install pyworld que deve fazer.
Instale ctc-segmentation
O mesmo método não se aplica à
ctc-segmentatione é necessário compilá-lo com o código-fonte no GitHub.
git clone https://github.com/lumaku/ctc-segmentation.git
cd ctc-segmentation
source /PathToMockingBird/venv/bin/activate Se o ambiente virtual não tiver sido implantado, ativá -lo.
cythonize -3 ctc_segmentation/ctc_segmentation_dyn.pyx
/usr/bin/arch -x86_64 python setup.py build build com arquitetura x86.
/usr/bin/arch -x86_64 python setup.py install --optimize=1 --skip-build com arquitetura x86.
/usr/bin/arch -x86_64 pip install torch torchvision torchaudio pip instalando PyTorch como exemplo, articular que está instalado com a arquitetura x86
pip install ffmpeg install ffmpeg
pip install -r requirements.txt Instale outros requisitos.
Para executar o projeto na arquitetura x86. Ref.
vim /PathToMockingBird/venv/bin/pythonM1 Crie um arquivo executável pythonM1 para condicionar o intérprete de python em /PathToMockingBird/venv/bin .
Escreva no seguinte conteúdo:
#!/usr/bin/env zsh
mydir=${0:a:h}
/usr/bin/arch -x86_64 $mydir/python "$@" chmod +x pythonM1 Defina o arquivo como executável.
Se estiver usando o PyCharm IDE, configure o intérprete do projeto para pythonM1 (etapas aqui), se estiver usando a linha de comando python, run /PathToMockingBird/venv/bin/pythonM1 demo_toolbox.py
Observe que estamos usando o codificador/vocoder pré -treinado, mas não o sintetizador, pois o modelo original é incompatível com os símbolos chineses. Isso significa que o Demo_Cli não está funcionando neste momento, portanto, são necessários modelos de sintetizador adicionais.
Você pode treinar seus modelos ou usar os existentes:
Pré -processo com os áudios e os espectrogramas MEL: python encoder_preprocess.py <datasets_root> permitindo o parâmetro --dataset {dataset} para suportar os conjuntos de dados que você deseja pré -processar. Somente o conjunto de trem desses conjuntos de dados será usado. Nomes possíveis: LibriPispeech_Other, VoxceleB1, VoxceleB2. Use vírgula para espalhar vários conjuntos de dados.
Treine o codificador: python encoder_train.py my_run <datasets_root>/SV2TTS/encoder
Para o treinamento, o codificador usa o visdom. Você pode desativá -lo com
--no_visdom, mas é bom ter. Execute "Visdom" em uma CLI/processo separado para iniciar seu servidor Visdom.
Faça o download do conjunto de dados e descompactação: verifique se você pode acessar todos .wav in pasta
Pré -processar com os áudios e os espectrogramas MEL: python pre.py <datasets_root> permitindo parâmetro --dataset {dataset} para apoiar a AIDATANG_200ZH, MagicData, Aishell3, Data_Aishell, etc. Se esse parâmetro não for passado.
Treine o sintetizador: python train.py --type=synth mandarin <datasets_root>/SV2TTS/synthesizer
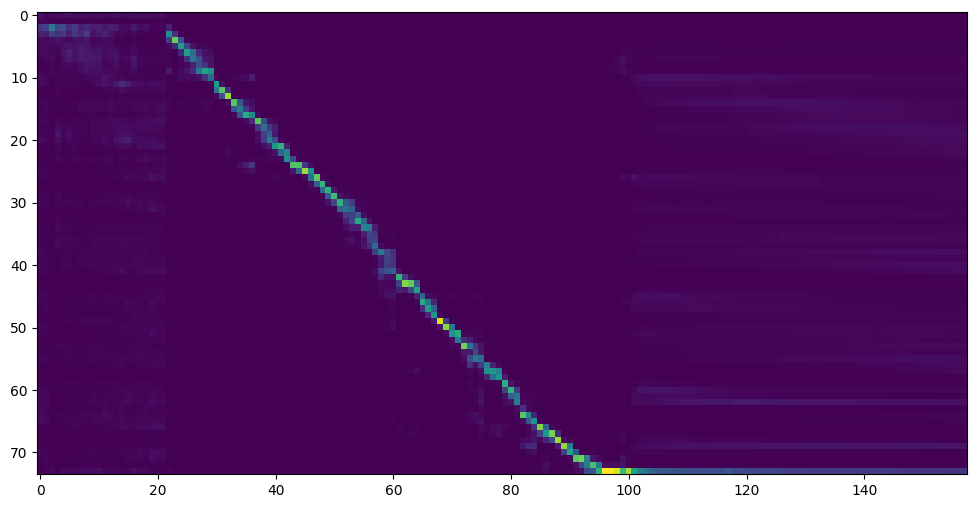
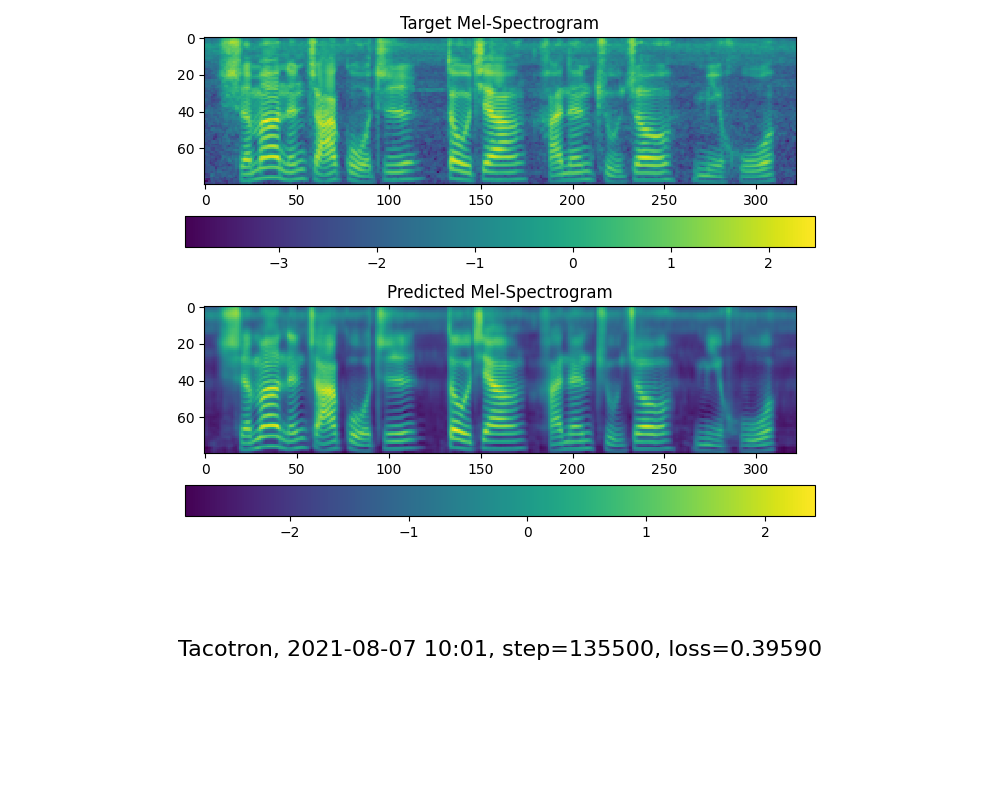
Vá para a próxima etapa quando vir a linha de atenção e a perda e a perda atende à sua necessidade na pasta Synthesizer/ saved_models/ .
Graças à comunidade, alguns modelos serão compartilhados:
| autor | Baixar link | Visualizar vídeo | Informações |
|---|---|---|---|
| @autor | https://pan.baidu.com/s/1ionvrxmki-t1nhqxkyty3g Baidu 4J5D | 75 mil passos treinados por vários conjuntos de dados | |
| @autor | https://pan.baidu.com/s/1fmh9ilgkjll2piirtyduvw Código Baidu: OM7f | 25k etapas treinadas por vários conjuntos de dados, funciona apenas na versão 0.0.1 | |
| @Fawenyo | Https://yisiou-my.sharepoint.com/:u:/g/personal/lawrence_cheng_fawenyo_onmicrosoft_com/ewfwdhzee-nng9twdkckcc4bc7bkgkgcbbown0-_tk0noge-ng. | saída de entrada | 200k etapas com sotaque local de Taiwan, só funciona na versão 0.0.1 |
| @miven | https://pan.baidu.com/s/1pi-hm3sn5wbechrryx-rcq Código: 2021 https://www.aliyundrive.com/s/awpsbo8mcsp: z2m0 | https://www.bilibili.com/video/bv1uh411b7ad/ | Funciona apenas na versão 0.0.1 |
NOTA: O vocoder tem pouca diferença em vigor, portanto, talvez você não precise treinar um novo.
Pré -processo Os dados: python vocoder_preprocess.py <datasets_root> -m <synthesizer_model_path>
<datasets_root>Substitua pelo seu conjunto de dados ROOT ,<synthesizer_model_path>Substitua pelo diretório de seus melhores modelos treinados de SyThensizer, por exemplo, SyThensizerSaved_modexxx
Treine o vocoder wavernn: python vocoder_train.py mandarin <datasets_root>
Treine o vocoder hifigan python vocoder_train.py mandarin <datasets_root> hifigan
Você pode então tentar executar: python web.py e abri -lo no navegador, padrão como http://localhost:8080
Você pode experimentar a caixa de ferramentas: python demo_toolbox.py -d <datasets_root>
Em seguida, você pode tentar o comando: python gen_voice.py <text_file.txt> your_wav_file.wav pode ser necessário instalar o cn2an por "pip install cn2an" para melhor resultado digital.
Este repositório é bifurcado a partir de clonagem de voz em tempo real, que só suporta inglês.
| Url | Designação | Título | Fonte de implementação |
|---|---|---|---|
| 1803.09017 | Globalstyletoken (Synthesizer) | Tokens de estilo: modelagem de estilo não supervisionada, controle e transferência na síntese de fala de ponta a ponta | Este repo |
| 2010.05646 | HIFI-GAN (vocoder) | Redes adversárias generativas para síntese de fala eficiente e de alta fidelidade | Este repo |
| 2106.02297 | Fre-Gan (vocoder) | Fre-Gan: síntese de áudio consistente de frequência adversária | Este repo |
| 1806.04558 | Sv2tts | Transfira o aprendizado da verificação do alto-falante para a síntese de texto para fala multispica. | Este repo |
| 1802.08435 | Wavernn (vocoder) | Síntese de áudio neural eficiente | Fatchord/Wavernn |
| 1703.10135 | Tacotron (sintetizador) | Tacotron: em direção à síntese de fala de ponta a ponta | Fatchord/Wavernn |
| 1710.10467 | GE2E (codificador) | Perda de ponta a ponta generalizada para verificação do alto-falante | Este repo |
| Conjunto de dados | Fonte original | Fontes alternativas |
|---|---|---|
| AIDATATANG_200ZH | OpenSlr | Google Drive |
| MagicData | OpenSlr | Google Drive (conjunto de dev) |
| Aishell3 | OpenSlr | Google Drive |
| data_aishell | OpenSlr |
Após o Unzip Aidatatang_200zh, você precisa descompactar todos os arquivos sob
aidatatang_200zhcorpustrain
<datasets_root> ? Se o caminho do conjunto de dados for D:dataaidatatang_200zh , então <datasets_root> é D:data
Treine o sintetizador: Ajuste o batch_size no synthesizer/hparams.py
//Before tts_schedule = [(2, 1e-3, 20_000, 12), # Progressive training schedule (2, 5e-4, 40_000, 12), # (r, lr, step, batch_size) (2, 2e-4, 80_000, 12), # (2, 1e-4, 160_000, 12), # r = reduction factor (# of mel frames (2, 3e-5, 320_000, 12), # synthesized for each decoder iteration) (2, 1e-5, 640_000, 12)], # lr = learning rate //After tts_schedule = [(2, 1e-3, 20_000, 8), # Progressive training schedule (2, 5e-4, 40_000, 8), # (r, lr, step, batch_size) (2, 2e-4, 80_000, 8), # (2, 1e-4, 160_000, 8), # r = reduction factor (# of mel frames (2, 3e-5, 320_000, 8), # synthesized for each decoder iteration) (2, 1e-5, 640_000, 8)], # lr = learning rate
Treine Vocoder synthesizer/hparams.py Preprocess
//Before ### Data Preprocessing max_mel_frames = 900, rescale = True, rescaling_max = 0.9, synthesis_batch_size = 16, # For vocoder preprocessing and inference. //After ### Data Preprocessing max_mel_frames = 900, rescale = True, rescaling_max = 0.9, synthesis_batch_size = 8, # For vocoder preprocessing and inference.
Trem vocoder-trep the vocoder: Ajuste o batch_size no vocoder/wavernn/hparams.py
//Before # Training voc_batch_size = 100 voc_lr = 1e-4 voc_gen_at_checkpoint = 5 voc_pad = 2 //After # Training voc_batch_size = 6 voc_lr = 1e-4 voc_gen_at_checkpoint = 5 voc_pad =2
RuntimeError: Error(s) in loading state_dict for Tacotron: size mismatch for encoder.embedding.weight: copying a param with shape torch.Size([70, 512]) from checkpoint, the shape in current model is torch.Size([75, 512]).Consulte a edição #37
Ajuste o batch_size conforme apropriado para melhorar
the page file is too small to complete the operationConsulte este vídeo e altere a memória virtual para 100g (102400), por exemplo: quando o arquivo é colocado no disco D, a memória virtual do disco D é alterada.
Para sua informação, minha atenção veio depois de 18 mil passos e a perda ficou inferior a 0,4 após 50 mil passos.