MockingBird
1.0.0
Meskipun saya tidak lagi secara aktif memperbarui repo ini, Anda dapat menemukan saya terus mendorong teknologi ini ke depan ke sisi yang baik dan open-source. Saya juga membangun versi yang dioptimalkan dan dioptimalkan cloud: https://noiz.ai/ dan itu gratis tetapi tidak siap untuk digunakan secara komersial sekarang.

Bahasa Inggris | 中文 | 中文 Linux
Mandarin didukung Cina dan diuji dengan beberapa set data: AidATATANG_200ZH, MAGICDATA, AISHELL3, DATA_AISHELL, dan dll.
Pytorch bekerja untuk Pytorch, diuji dalam versi 1.9.0 (terbaru pada Agustus 2021), dengan GPU Tesla T4 dan GTX 2060
Windows + Linux dijalankan di kedua OS Windows dan Linux OS (bahkan di M1 MacOS)
Efek Mudah & Luar Biasa dengan hanya synthesizer yang baru terlatih, dengan menggunakan kembali encoder/vocoder pretrained
Server web siap melayani hasil Anda dengan panggilan jarak jauh
Ikuti repo asli untuk menguji jika Anda menyiapkan semua lingkungan. ** Python 3.7 atau lebih tinggi ** diperlukan untuk menjalankan kotak alat.
Instal Pytorch.
Jika Anda mendapatkan
ERROR: Could not find a version that satisfies the requirement torch==1.9.0+cu102 (from versions: 0.1.2, 0.1.2.post1, 0.1.2.post2 )Kesalahan ini mungkin disebabkan oleh a Versi rendah Python, coba gunakan 3.9 dan akan berhasil menginstal
Instal FFMPEG.
Jalankan pip install -r requirements.txt untuk menginstal paket yang diperlukan.
Lingkungan yang direkomendasikan di sini adalah
Repo Tag 0.0.1Pytorch1.9.0 with Torchvision0.10.0 and cudatoolkit10.2requirements.txtwebrtcvad-wheelskarenarequirements. txtdiekspor beberapa bulan yang lalu, jadi tidak berfungsi dengan versi yang lebih baru
Instal WebRTCVAD pip install webrtcvad-wheels (jika Anda butuhkan)
atau
Pasang dependensi dengan conda atau mamba
conda env create -n env_name -f env.yml
mamba env create -n env_name -f env.yml
akan menciptakan lingkungan virtual jika dependensi yang diperlukan diinstal. Beralih ke lingkungan baru dengan conda activate env_name dan nikmati.
Env.yml hanya mencakup dependensi yang diperlukan untuk menjalankan proyek, sementara tanpa monotonik-align. Anda dapat memeriksa situs web resmi untuk menginstal versi GPU Pytorch.
Langkah -langkah berikut adalah solusi untuk secara langsung menggunakan
demo_toolbox.pyasli tanpa mengubah kode.Karena masalah utama dilengkapi dengan paket PYQT5 yang digunakan dalam
demo_toolbox.pytidak kompatibel dengan chip M1, adalah salah satu yang mencoba pada model pelatihan dengan chip M1, baik orang tersebut dapat melupakandemo_toolbox.py, atau orang dapat mencobaweb.pydi dalam Proyek.
PyQt5 , dengan Ref di sini.Buat dan buka terminal Rosetta, dengan Ref di sini.
Gunakan sistem python untuk menciptakan lingkungan virtual untuk proyek
/usr/bin/python3 -m venv /PathToMockingBird/venv source /PathToMockingBird/venv/bin/activate
Tingkatkan PIP dan instal PyQt5
pip install --upgrade pip pip install pyqt5
pyworld dan ctc-segmentationKedua paket tampaknya unik untuk proyek ini dan tidak terlihat dalam proyek kloning suara real-time asli. Saat menginstal dengan
pip install, kedua paket tidak memiliki roda sehingga program mencoba untuk secara langsung mengkompilasi dari kode C dan tidak dapat menemukanPython.h.
Instal pyworld
brew install python Python.h bisa datang dengan python dipasang oleh brew
export CPLUS_INCLUDE_PATH=/opt/homebrew/Frameworks/Python.framework/Headers filepath dari Python.h yang dipasang oleh minuman unik untuk macO M1 dan tercantum di atas. Seseorang perlu menambahkan jalur ke variabel lingkungan secara manual.
pip install pyworld yang harus dilakukan.
Instal ctc-segmentation
Metode yang sama tidak berlaku untuk
ctc-segmentation, dan orang perlu mengkompilasinya dari kode sumber pada github.
git clone https://github.com/lumaku/ctc-segmentation.git
cd ctc-segmentation
source /PathToMockingBird/venv/bin/activate jika lingkungan virtual belum digunakan, aktifkan.
cythonize -3 ctc_segmentation/ctc_segmentation_dyn.pyx
/usr/bin/arch -x86_64 python setup.py build build dengan arsitektur x86.
/usr/bin/arch -x86_64 python setup.py install --optimize=1 --skip-build Instal dengan arsitektur x86.
/usr/bin/arch -x86_64 pip install torch torchvision torchaudio pip menginstal PyTorch sebagai contoh, artikulat bahwa ia diinstal dengan arsitektur x86
pip install ffmpeg Instal FFMPEG
pip install -r requirements.txt menginstal persyaratan lainnya.
Untuk menjalankan proyek pada arsitektur x86. Ref.
vim /PathToMockingBird/venv/bin/pythonM1 Buat file yang dapat dieksekusi pythonM1 untuk mengkondisikan interpreter python at /PathToMockingBird/venv/bin .
Tulis di konten berikut:
#!/usr/bin/env zsh
mydir=${0:a:h}
/usr/bin/arch -x86_64 $mydir/python "$@" chmod +x pythonM1 Atur file sebagai dapat dieksekusi.
Jika menggunakan Pycharm IDE, konfigurasikan interpreter proyek ke pythonM1 (langkah -langkah di sini), jika menggunakan baris perintah python, run /PathToMockingBird/venv/bin/pythonM1 demo_toolbox.py
Perhatikan bahwa kami menggunakan encoder/vocoder pretrained tetapi tidak synthesizer, karena model aslinya tidak kompatibel dengan simbol Cina. Ini berarti demo_cli tidak berfungsi pada saat ini, jadi model synthesizer tambahan diperlukan.
Anda dapat melatih model Anda atau menggunakan yang sudah ada:
Preprocess dengan audios dan spektrogram MEL: python encoder_preprocess.py <datasets_root> memungkinkan parameter --dataset {dataset} untuk mendukung dataset yang ingin Anda preprocess. Hanya set kereta dataset ini yang akan digunakan. Nama yang mungkin: librispeech_other, voxceleb1, voxceleb2. Gunakan koma untuk memegangi banyak set data.
Latih Encoder: python encoder_train.py my_run <datasets_root>/SV2TTS/encoder
Untuk pelatihan, encoder menggunakan Visdom. Anda dapat menonaktifkannya dengan
--no_visdom, tetapi menyenangkan untuk dimiliki. Jalankan "visdom" dalam proses CLI/terpisah untuk memulai server Visdom Anda.
Unduh dataset dan unzip: Pastikan Anda dapat mengakses semua .wav di folder
Preprocess dengan audios dan spektrogram MEL: python pre.py <datasets_root> memungkinkan parameter --dataset {dataset} untuk mendukung AIDATATATANG_200ZH, MagicData, Aishell3, Data_Aishell, dll. Jika parameter ini tidak disahkan, dataset default akan menjadi payasaet akan ada di dataset yang default akan ada puah.
Latih synthesizer: python train.py --type=synth mandarin <datasets_root>/SV2TTS/synthesizer
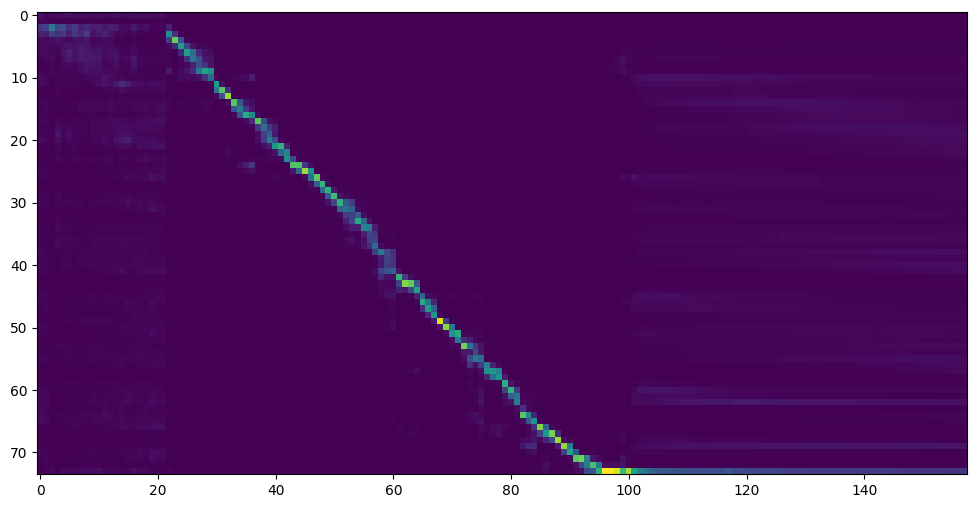
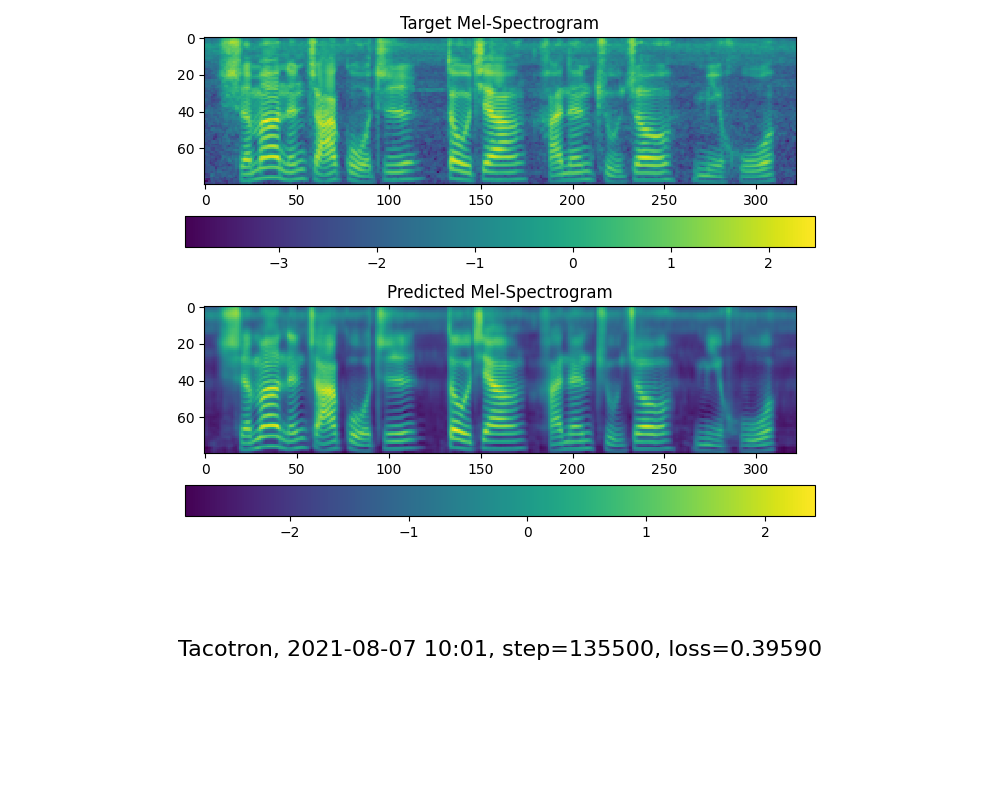
Pergi ke langkah berikutnya ketika Anda melihat perhatian dan kehilangan garis perhatian memenuhi kebutuhan Anda di folder pelatihan synthesizer/ saved_models/ .
Terima kasih kepada masyarakat, beberapa model akan dibagikan:
| pengarang | Tautan unduh | Pratinjau video | Info |
|---|---|---|---|
| @pengarang | https://pan.baidu.com/s/1ionvrxmki-t1nhqxkyty3g baidu 4j5d | Langkah 75K yang dilatih oleh banyak set data | |
| @pengarang | https://pan.baidu.com/s/1fmh9ilgkjll2piirtyduvw baidu kode : Om7f | 25K Langkah Dilatih oleh Beberapa Dataset, Hanya Bekerja Di Bawah Versi 0.0.1 | |
| @Fawenyo | https://yisiou-my.sharepoint.com/:u:/g/personal/lawrence_cheng_fawenyo_onmicrosoft_com/ewfwdhzee-nng9twdkcccccccc4bc7bk2j9ccbown0-_tk0nog?e=n0bc7bk2j.crown0-_tk0nog?e=n0bc7bkbown0-_tk0nog ?e=n0bc7bk | input output | Langkah 200K dengan aksen lokal Taiwan, hanya bekerja di bawah versi 0.0.1 |
| @Miven | https://pan.baidu.com/s/1pi-hm3sn5wbechrryx-rcq kode: 2021 https://www.aliyundrive.com/s/awpsbo8mcsp Kode: z2m0 | https://www.bilibili.com/video/bv1uh411b7ad/ | hanya berfungsi di bawah versi 0.0.1 |
Catatan: Vocoder memiliki sedikit perbedaan, jadi Anda mungkin tidak perlu melatih yang baru.
Preprocess data: python vocoder_preprocess.py <datasets_root> -m <synthesizer_model_path>
<datasets_root>Ganti dengan root dataset Anda ,<synthesizer_model_path>Ganti dengan direktori model sythensizer terlatih terbaik Anda, misalnya sythensizersaved_modexxx
Latih The Wavernn Vocoder: python vocoder_train.py mandarin <datasets_root>
Latih vocoder hifigan python vocoder_train.py mandarin <datasets_root> hifigan
Anda kemudian dapat mencoba menjalankan: python web.py dan membukanya di browser, default sebagai http://localhost:8080
Anda kemudian dapat mencoba The Toolbox: python demo_toolbox.py -d <datasets_root>
Anda kemudian dapat mencoba perintahnya: python gen_voice.py <text_file.txt> your_wav_file.wav Anda mungkin perlu menginstal cn2an dengan "pip instal cn2an" untuk hasil nomor digital yang lebih baik.
Repositori ini bercabang dari kloning voice-time-real-time yang hanya mendukung bahasa Inggris.
| Url | Penamaan | Judul | Sumber Implementasi |
|---|---|---|---|
| 1803.09017 | Globalstyletoken (synthesizer) | Token Gaya: Pemodelan Gaya Tanpa Dipersambut, Kontrol dan Transfer dalam Sintesis Ucapan Ujung Ujung | Repo ini |
| 2010.05646 | HiFi-Gan (Vocoder) | Jaringan permusuhan generatif untuk sintesis pidato kesetiaan yang efisien dan tinggi | Repo ini |
| 2106.02297 | FRE-GAN (VOCODER) | FRE-GAN: Sintesis audio frekuensi-konsisten permusuhan | Repo ini |
| 1806.04558 | SV2TTS | Transfer pembelajaran dari verifikasi speaker ke sintesis teks-ke-speech multispeaker | Repo ini |
| 1802.08435 | Wavernn (Vocoder) | Sintesis audio saraf yang efisien | Fatchord/Wavernn |
| 1703.10135 | Tacotron (synthesizer) | Tacotron: Menuju sintesis ucapan ujung ke ujung | Fatchord/Wavernn |
| 1710.10467 | Ge2e (encoder) | Kehilangan ujung ke ujung umum untuk verifikasi pembicara | Repo ini |
| Dataset | Sumber asli | Sumber alternatif |
|---|---|---|
| AIDATATANG_200ZH | Openslr | Google Drive |
| MagicData | Openslr | Google Drive (set dev) |
| Aishell3 | Openslr | Google Drive |
| data_aishell | Openslr |
Setelah unzip AIDATATANG_200ZH, Anda perlu membuka ritsleting semua file di bawah
aidatatang_200zhcorpustrain
<datasets_root> ? Jika jalur dataset adalah D:dataaidatatang_200zh , maka <datasets_root> adalah D:data
Latih synthesizer : Sesuaikan Batch_Size di synthesizer/hparams.py
//Before tts_schedule = [(2, 1e-3, 20_000, 12), # Progressive training schedule (2, 5e-4, 40_000, 12), # (r, lr, step, batch_size) (2, 2e-4, 80_000, 12), # (2, 1e-4, 160_000, 12), # r = reduction factor (# of mel frames (2, 3e-5, 320_000, 12), # synthesized for each decoder iteration) (2, 1e-5, 640_000, 12)], # lr = learning rate //After tts_schedule = [(2, 1e-3, 20_000, 8), # Progressive training schedule (2, 5e-4, 40_000, 8), # (r, lr, step, batch_size) (2, 2e-4, 80_000, 8), # (2, 1e-4, 160_000, 8), # r = reduction factor (# of mel frames (2, 3e-5, 320_000, 8), # synthesized for each decoder iteration) (2, 1e-5, 640_000, 8)], # lr = learning rate
Latih vokoder-preprocess data : Sesuaikan Batch_Size di synthesizer/hparams.py
//Before ### Data Preprocessing max_mel_frames = 900, rescale = True, rescaling_max = 0.9, synthesis_batch_size = 16, # For vocoder preprocessing and inference. //After ### Data Preprocessing max_mel_frames = 900, rescale = True, rescaling_max = 0.9, synthesis_batch_size = 8, # For vocoder preprocessing and inference.
Latih Vocoder-Train The Vocoder : Sesuaikan Batch_Size di vocoder/wavernn/hparams.py
//Before # Training voc_batch_size = 100 voc_lr = 1e-4 voc_gen_at_checkpoint = 5 voc_pad = 2 //After # Training voc_batch_size = 6 voc_lr = 1e-4 voc_gen_at_checkpoint = 5 voc_pad =2
RuntimeError: Error(s) in loading state_dict for Tacotron: size mismatch for encoder.embedding.weight: copying a param with shape torch.Size([70, 512]) from checkpoint, the shape in current model is torch.Size([75, 512]).Silakan merujuk ke Edisi #37
Sesuaikan Batch_Size yang sesuai untuk meningkatkan
the page file is too small to complete the operationSilakan merujuk ke video ini dan ubah memori virtual menjadi 100g (102400), misalnya: Ketika file ditempatkan di disk D, memori virtual dari disk D diubah.
FYI, perhatian saya datang setelah 18 ribu langkah dan kehilangan menjadi lebih rendah dari 0,4 setelah 50 ribu langkah.