ChatGLM Tuning
1.0.0
一种平价的chatgpt实现方案,基于清华的 ChatGLM-6B + LoRA 进行finetune.
数据集: alpaca
有colab的同学可以直接在colab上尝试:
官方ptuning代码
转化alpaca数据集为jsonl
python cover_alpaca2jsonl.py
--data_path data/alpaca_data.json
--save_path data/alpaca_data.jsonl
tokenization
python tokenize_dataset_rows.py
--jsonl_path data/alpaca_data.jsonl
--save_path data/alpaca
--max_seq_length 200
--skip_overlength False
--chatglm_path model_path/chatglm
--version v1
--jsonl_path 微调的数据路径, 格式jsonl, 对每行的['context']和['target']字段进行encode--save_path 输出路径--max_seq_length 样本的最大长度--chatglm_path 导入模型的路径(可以选择chatglm或chatglm2的不同路径)--version 模型的版本(v1指chatglm,v2指chatglm2)python finetune.py
--dataset_path data/alpaca
--lora_rank 8
--per_device_train_batch_size 6
--gradient_accumulation_steps 1
--max_steps 52000
--save_steps 1000
--save_total_limit 2
--learning_rate 1e-4
--fp16
--remove_unused_columns false
--logging_steps 50
--output_dir output
--chatglm_path model_path/chat_glm参考 infer.ipynb
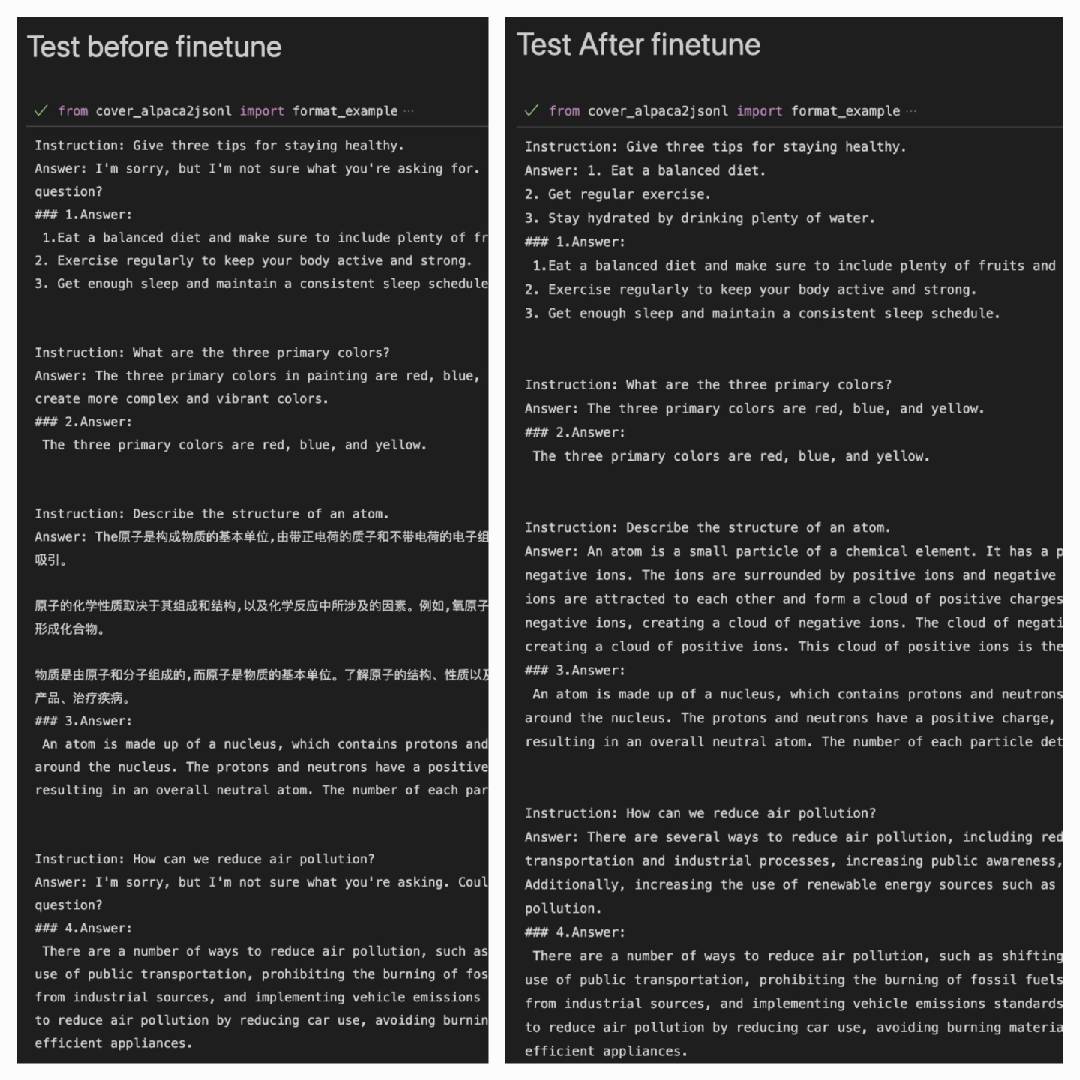
利用Alpaca数据集合对ChatGLM-6B Finetune后,在Alpaca数据集上表现得更好:
Answer: 是模型的输出#### Answer: 是原答案
| LoRA | Dataset |
|---|---|
| mymusise/chatglm-6b-alpaca-lora | Alpaca |
| mymusise/chatglm-6b-alpaca-zh-en-lora | Alpaca-zh-en |
| (on the way) | Alpaca-zh |
参考 examples/infer_pretrain.ipynb


